夜雨聆风
夜雨聆风橡树岭国家实验室融合量子、经典HPC与AI系统堆栈
美国橡树岭国家实验室(Oak Ridge National Laboratory)正在深入研究如何将量子计算、经典超级计算机(HPC)和人工智能(AI)系统结合起来。实验室的科学家们正致力于探索如何实现这些系统之间的无缝协作,这涵盖了硬件连接、算法设计、软件开发以及AI在整个系统堆栈中的关键作用。橡树岭国家实验室拥有美国首个exascale级系统Frontier,并且正在积极开发量子计算用户项目,旨在支持前沿量子研究。科学家们正在通过创建量子测试平台和高速网络来连接经典的HPC系统和量子系统。此外,他们还在深入探索AI在量子错误纠正和优化量子电路中的应用,以及量子计算机在机器学习和AI领域的潜在用途。
(橡树岭国家实验室 Oak Ridge National Laboratory:美国能源部下属的多学科科学和技术国家实验室,致力于科学发现和创新解决方案。)

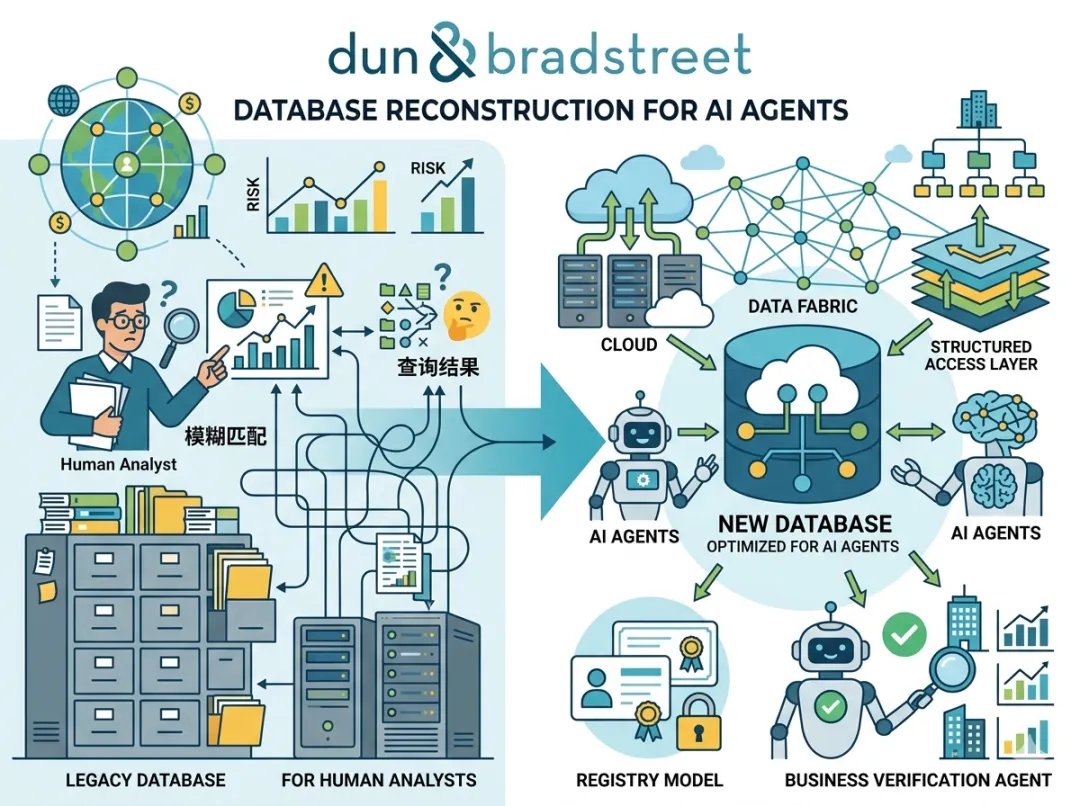
Dun & Bradstreet重构数据库,以适应AI代理需求
Dun & Bradstreet(D&B,邓白氏)为了适应人工智能代理的需求,对其庞大的商业数据库进行了重建。这个覆盖6.42亿家企业及其关系、层级和风险概况的数据库,最初是为人类分析师设计的。由于传统设计使AI代理在处理查询结果和模糊实体匹配时遇到困难,D&B决定对其数据库进行重构,以更好地支持机器处理。新数据库通过采用云基础设施、数据fabric层和结构化访问层进行优化,提供了更高效的数据检索和实体验证功能。此外,D&B还构建了一个新的注册模型来确保代理的身份验证,并嵌入业务验证代理以解决工作流程中的实体一致性问题。
(邓白氏公司 Dun & Bradstreet:一家全球领先的商业决策数据和分析提供商,提供企业信用报告、商业信息和洞察。)
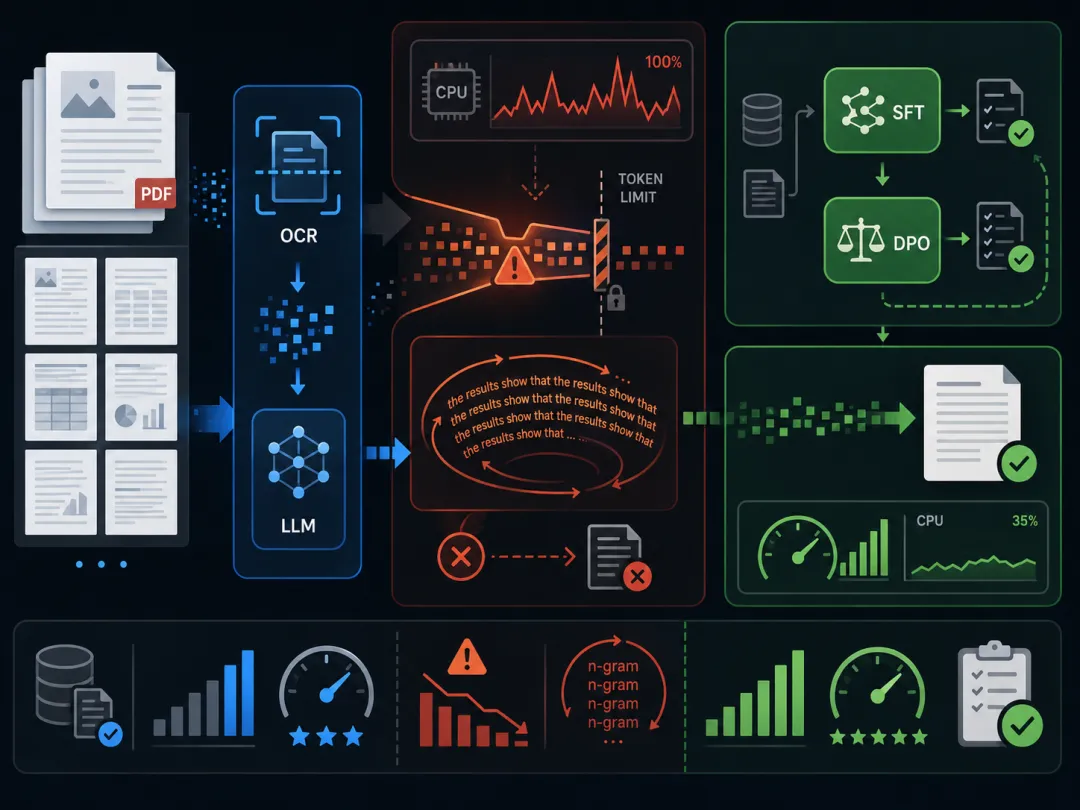
文本退化:大多数基准测试未追踪的生产故障模式
在特定领域OCR(光学字符识别)的小型语言模型(LLMs)应用中,研究人员发现了一种被称为“文本退化”(Text Degeneration)的生产故障模式。这种故障模式表现为,在现实世界的PDF文档OCR场景中,不到3%的页面却消耗了近一半的总CPU时间。其主要原因是请求达到最大令牌限制后,模型出现n-gram重复模式,导致无法生成完整的输出。研究将文本退化定义为自回归生成的自我强化失败现象,且目前大多数基准测试并未对其进行跟踪和评估。为解决此问题,研究者提出了一种两阶段训练流程,结合监督微调(Supervised Fine-tuning)和直接偏好优化(Direct Preference Optimization),有效降低了退化率并提高了系统吞吐量。文章强调,文本退化率应成为评估自回归生成系统性能的关键指标。