 夜雨聆风
夜雨聆风Literature
Interpretation
2026
AI如何读懂医院里那些被忽略的安全报告?
一项发表于《BMJ Quality & Safety》的混合方法研究
本期解读文章

英文标题:AI-driven analysis of patient safety reports using large language models: an exploratory multiple methods study

中文标题:利用大型语言模型对患者安全报告进行人工智能驱动的分析:一项探索性多方法研究。
来源期刊

医疗系统每年收到数以千计的患者安全报告,其中99.9%是“未遂事件”或“前期安全事件”。传统人工分析耗时费力且标准不一,大量数据中的风险信号被埋没。大语言模型能否成为破局者?斯坦福大学医学院团队对此进行了系统评估。
研究背景
Background
传统患者安全报告长期面临三大困境:
低伤害事件被忽视
医疗机构每年收到大量安全报告,其中绝大多数为“未遂事件”或“前期安全事件”,仅有0.1%为严重安全事件会触发深入调查,大量风险信号被埋没。
人工分析效率低
依赖记忆和经验,耗时且主观,近半数伤害事件可能被漏掉。
传统自动化工具能力有限
难以处理复杂、非结构化的自由文本。
大语言模型提供了新机遇,但存在研究空白
LLM在临床文档、摘要生成等方面已展现能力。然而,在患者安全领域:
有研究验证了LLM能按主题分类报告;
但尚无研究使用LLM根据本地数据定制分类法;
也尚无研究从实施科学角度评估质量安全团队实际采用LLM解决方案的可行性。
研究目标
开发一种使用LLM分析患者安全趋势的新方法;
通过专家验证评估并完善LLM的准确性;
探索一线质量安全专业人员实施和采用LLM生成输出的促进因素与障碍。

研究方法
METHODS
01
数据来源与工具
LLM:OpenAI‘s ChatGPT-4o,部署在符合HIPAA的内部平台,保障数据安全
训练数据集:2022-2023年,共9,357份患者安全报
验证数据集:2024年1-5月,共2,065份患者安全报
可视化工具:Tableau仪表板
02
五阶段分析流程

03
定量验证方法
从验证数据集中进行两项抽样验证:
问题提取验证:随机抽取 100 份报告(LLM 从中提取出 158 个问题),由专家评价提取是否准确。
分类验证:另随机抽取 219 个由 LLM 生成的问题,由专家评价父/子类别是否正确。
两项验证均由 2 名患者安全专家独立评价。
04
定性访谈方法
对10名一线专业人员(质量改进顾问、感染控制专家、临床护士专家、临床实践质量专家等)进行半结构化访谈,基于实施科学框架评估三个核心实施结果:适当性、可接受性、采纳性。
研究结果
RESULTS
一、全局概况:问题提取与类别生成规模
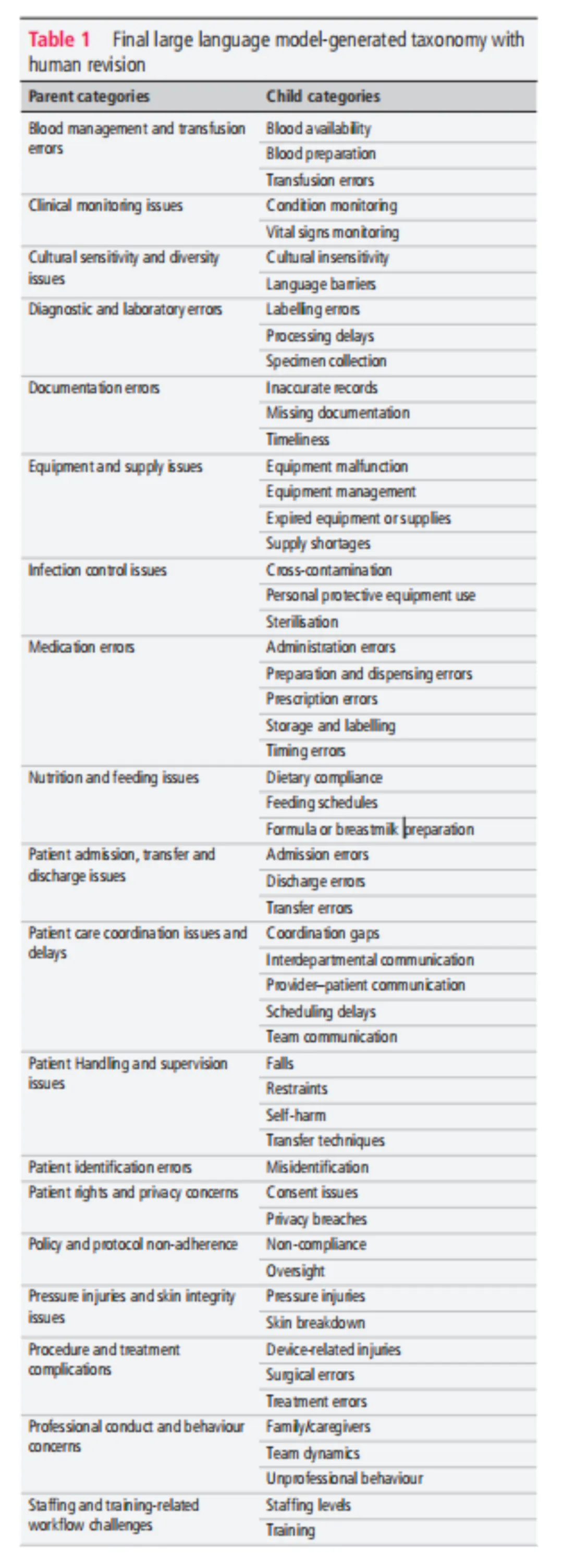
在LLM提取出所有问题后,研究者采用扎根理论方法,让模型在没有预设分类的情况下自主归纳主题类别,再经人类专家修订,最终形成了19个父类别和53个子类别的分类体系(表1)。下表展示了这一分类法的全貌。
二、数据可视化:仪表板展示
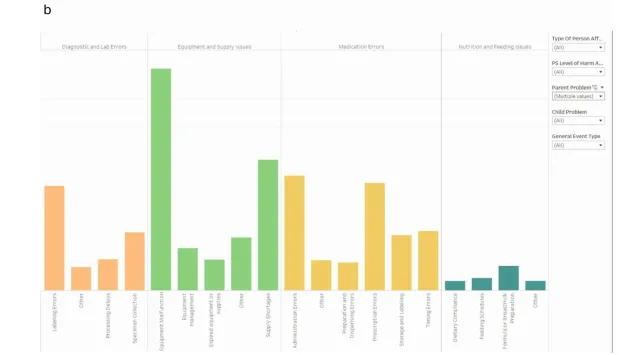
图1a展示了一个仪表板视图,揭示了患者安全报告的多维性质——每份报告可能存在多个问题。图1b展示了医院某个单元内问题的发生率,按“父”和“子”类别标签进行排序。
Figure 1 Snapshot of dashboards visualising large language model-generated output
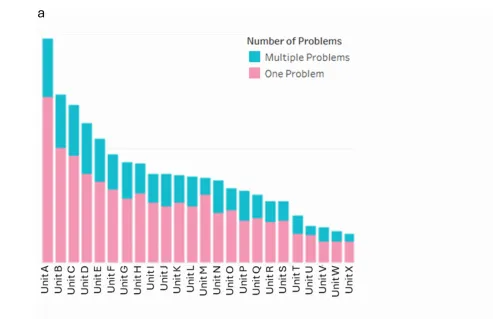

图1b

图1a
三、定量验证:准确率
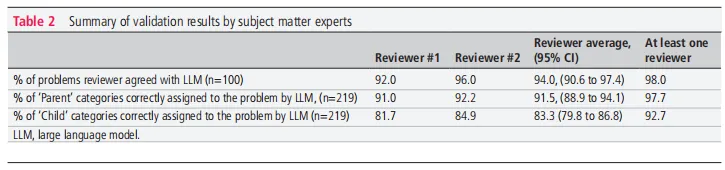
问题提取准确率: 平均94.0%(95% CI 90.6–97.4),至少一名评审员认同的比例高达98%。
分类准确率: 父类别平均91.5%(95% CI 88.9–94.1),子类别平均83.3%(95% CI 79.8–86.8)。
“其他”类别占比:父类<0.2%、子类<0.4%,说明分类法覆盖度良好
四、定性访谈:用户高度认可
为了解一线质量安全专业人员对LLM工具的真实看法,研究团队对10名相关工作者进行了半结构化访谈。受访者背景如下:
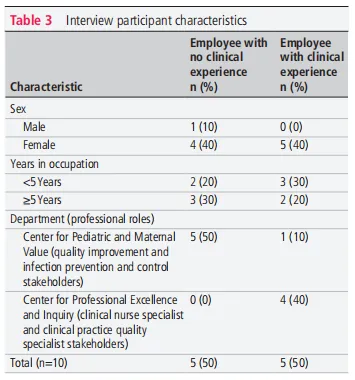
受访者涵盖了质量改进、感染预防、临床护理等关键岗位。其中一半有临床背景,一半来自管理岗。所有受访者均直接参与安全报告的分析与改进工作,是LLM工具的潜在核心用户。
访谈围绕三个维度:适当性(是否适配工作)、可接受性(是否满意)、采纳性(是否愿意使用)。整体反馈积极,认为LLM输出清晰、有价值、易于整合。
五、核心发现:按实施结果分类的主题与引文
下表汇总了受访者在三个维度的主要观点和代表性原话:
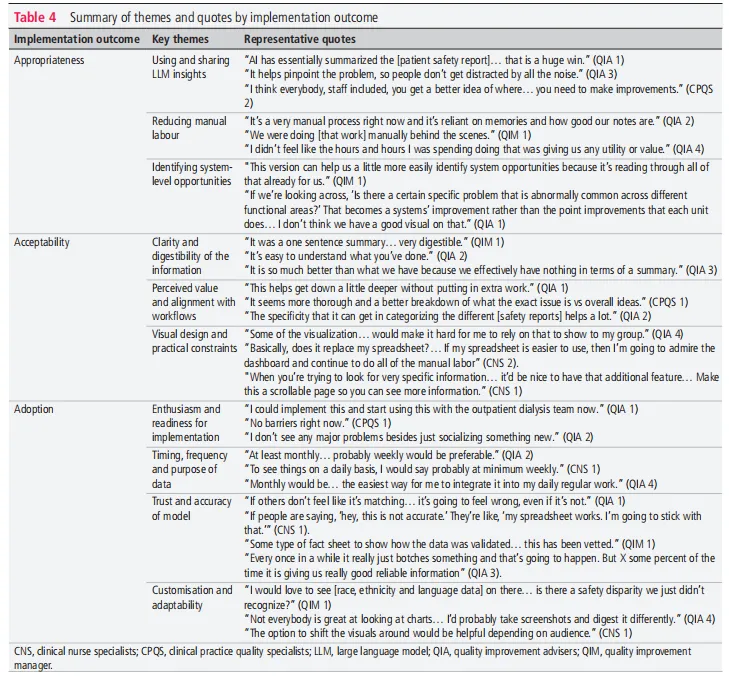
适当性方面,受访者认为LLM摘要能精准定位问题、减少噪音,节省时间,还能发现跨部门、系统级风险。
可接受性方面,用户满意输出的简洁性和价值,明显优于现有“几乎没有总结”的流程。但对仪表板的可视化设计提出改进建议(如更灵活、可滚动)。
采纳性方面,一线人员热情高,有人表示“现在就能用”。但强调信任需要验证说明(如准确率清单),希望数据至少每周更新一次。
值得一提的是,没有一位受访者表示“完全不想用”,为实际落地打下良好基础。
讨 论
DISCUSSION
AI不是取代人,而是解放人
从被动响应到主动预防
LLM能从大量低伤害事件中提前识别系统性风险信号,推动医疗机构从“严重事件发生→根因分析”的被动模式转向主动预防。
把人从“搬砖”中解放出来
原本用于手动分类、阅读、标注的人力可重新投入到质量改进项目中。受访者表示该工具“极大地减少了手动翻阅、依赖记忆的负担”。
系统级视野
过去各科室只看自己的问题,LLM实现了跨部门、系统级的视野,可揭示同一问题在不同功能区域是否普遍存在,从而指导系统性改进而非局部修补。
多维优势
传统人工分类通常只能为一份报告打一个标签,而LLM能识别出多个问题,更真实地反映了事件的多维性。
局限性
Limitations
局限性
确认偏差:专家在验证时能看到模型输出,可能下意识倾向于同意
验证样本较小:仅占数据集的≥1%,未必覆盖所有罕见错误类型
单中心 + 单一模型(ChatGPT-4o) :结论推广需谨慎,不同LLM表现可能有差异
幻觉与模型漂移风险:需要持续人工监督
研究团队强调:AI 的价值在于增强而非替代人类判断,将人力从繁重的信息筛选中解放出来,聚焦于真正的质量改进工作。
结 论
CONCLUSION
本研究基于2022-2024年间共计11,422份患者安全报告,系统评估了ChatGPT-4o在患者安全事件分析中的可行性与落地效果。
主要结论
技术性能可靠:问题提取准确率94.0%,父类别分类91.5%,子类别分类83.3%。绝大多数错误源于分类优先级差异,而非模型幻觉。
多维化演进:LLM能从一份报告中识别多个问题,突破传统单一标签限制,有助于发现跨部门系统性风险。
用户接受度高:10名一线专业人员普遍认可输出的适当性、可接受性和采纳性。
填补研究空白:首个使用LLM根据本地数据定制分类法并评估实施可行性的研究。
最终结论: 大语言模型能够有效支持患者安全领域从被动响应向主动预防的转变。其价值不在于替代人类判断,而在于将人力从繁重的信息搬运中解放出来,聚焦于真正的质量改进工作。
使用说明
文章链接:https://pubmed.ncbi.nlm.nih.gov/41617612/
DOI: 10.1136/bmjqs-2025-019495
声明:本文为学术文献解读,仅供学习交流,不构成管理建议。内容基于原文客观梳理,版权归原作者及期刊所有。
END
文案撰写/排版:黄西贝

成都中医药大学管理学院市场营销2024级学生,2024–2025学年获评“优秀学生”、综合奖学金二等奖及科研创新奖。科研实践上,主持校级科研实践创新课题1项,并以核心成员身份参与省级大学生创新创业训练计划项目及另一项校级科研实践创新课题。竞赛方面,曾获“五粮液杯”四川省大学生酒类创新创意大赛省级二等奖、数智运筹AI应用创新大赛省级三等奖、四川省大学生营销策划大赛省级三等奖等十余项校级以上荣誉。
审核人:赵大仁、曹勍
下期精彩继续

