 夜雨聆风
夜雨聆风今日热点解读
1。美国商务部通过《芯片与科学法案》向9家量子计算企业注资20.13亿美元并获取少数股权,其意图在于通过资本介入确立美国对量子计算供应链核心节点的监管权限,提升本土硬件产能并扩大与其他经济体的技术差距。
Andy解读:
资金向300mm晶圆专用量子代工厂集中,表明量子计算硬件正从实验室阶段的单体器件加工向兼容成熟半导体工艺的量产阶段过渡。
政府获取少数股权的投资模式建立了对关键知识产权与本土产能的直接管控机制,将加速全球计算基础设施供应链的分化。
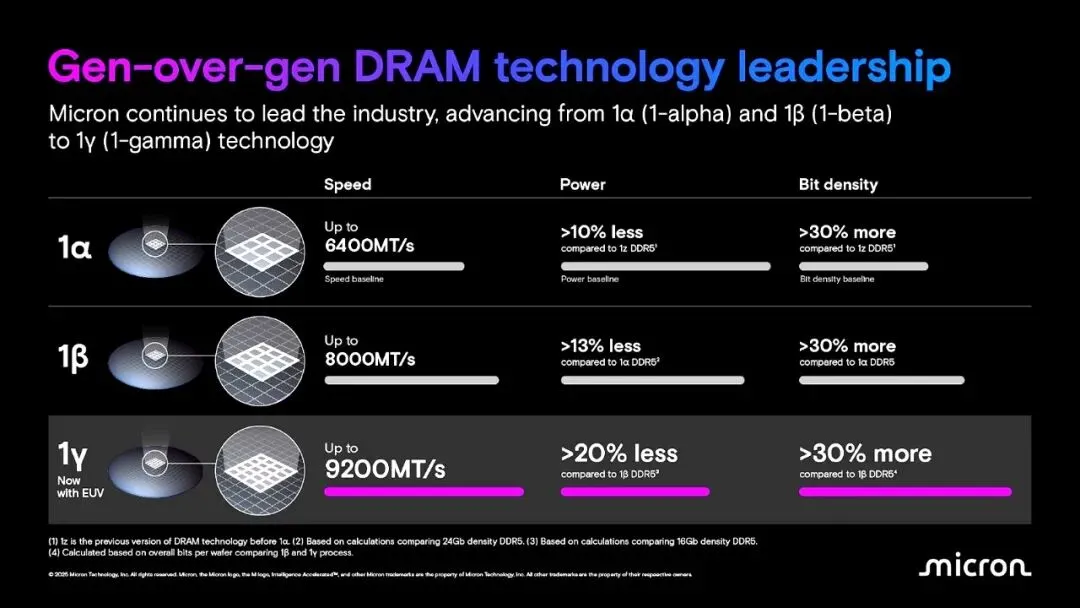
2.Micron宣布投资超20亿美元扩产弗吉尼亚州马纳萨斯工厂,启动1αnm工艺节点的DRAM(主要为DDR4和LPDDR4)量产,计划于2026年底出货。
Andy解读:
以次尖端成熟制程置换地缘合规红利,而非技术跨代演进。1αnm并非美光最尖端工艺(落后于现行的1β及研发中的1γ),但作为满足车规级、军工级长生命周期需求的稳定节点,扩产本质上是利用美国本土制造的溢价与政策补贴,承接对供应链安全敏感度高于技术先进度的存量高利润市场。
缓解地缘政治导致的供应链敞口风险,建立本土冗余产能。将DDR4晶圆供应量提升至四倍,直接改变了美光此前过度依赖亚洲(中国台湾、日本广岛等)晶圆厂提供先进内存的产能布局,为国防、航空航天及医疗等核心基础设施建构了物理隔离的本土交付闭环。
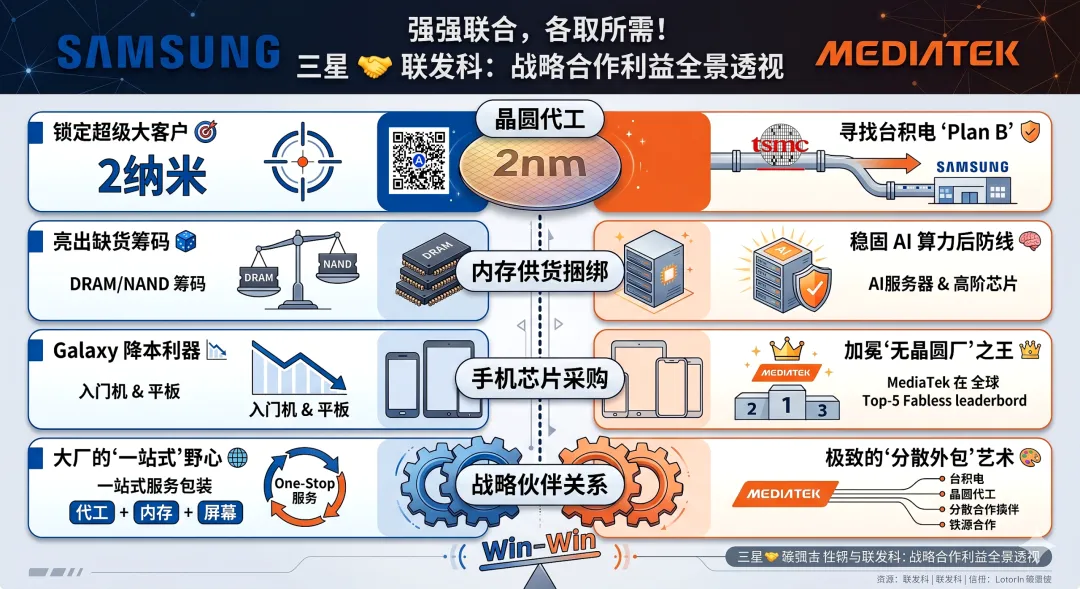
3.三星电子会长李在镕率团拜访联发科,三星试图利用自身在DRAM和NAND存储领域的垄断性产能优势作为商业筹码,通过“存储+晶圆代工”的跨业务捆绑销售策略,切入目前由台积电主导的联发科芯片代工供应链,以缓解自身晶圆代工业务的亏损压力。
Andy解读:
联发科引入三星作为晶圆代工的第二供应商,意在通过多元化供应商策略提升供应链抗风险能力,并增强对台积电的议价筹码。
双方的潜在合作从消费电子芯片延伸至车用及入门级移动平台,正在通过跨领域的业务交换来置换关键市场份额。
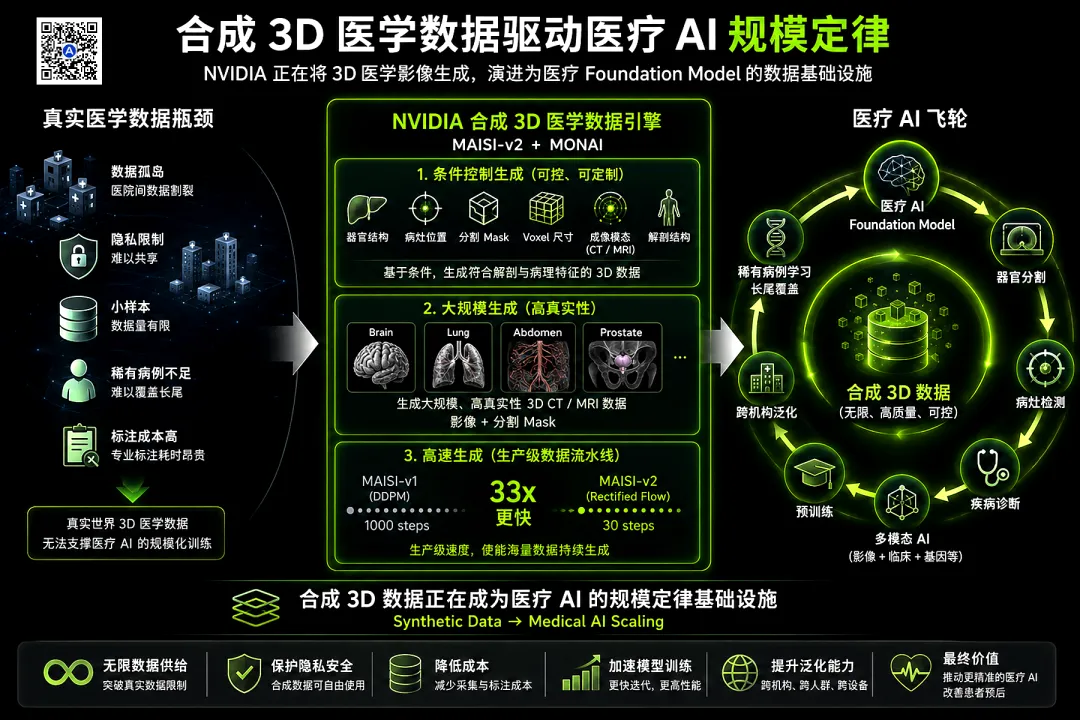
4.NVIDIA开源了基于MAISI-v2架构的3D医学图像合成框架NV-Generate-CTMR以及基于MR-RATE数据集训练的NV-Generate-MR-Brain模型。通过开源核心模型权重与全套推理流水线,确立其在医疗合成数据底座的实际主导权,借此强化其从云端训练到终端推理的软硬件生态绑定。
Andy解读:
MAISI-v2架构的核心在于引入潜在整流流模型,绕过了传统3D扩散模型在高维体素空间迭代时巨大的算力开销,在保持解剖学像素级分割精度的前提下,将3D体积数据合成的推理速度提升33倍。
依托包含8.3万名患者、70万个数据卷的MR-RATE数据集进行预训练,该开源模型输出的3D影像具备极高的生物学保真度,可作为标准化资产直接注入医疗AI的训练流水线,旨在解决医疗领域样本稀缺与隐私合规带来的长尾效应。
该框架支持在消费级RTX GPU上直接执行推理与微调,这一工程设计将高解像度3D影像生成的门槛从集群级降至工作站级,通过释放长尾开发者的生产力,巩固英伟达全栈基础设施的软件粘性。
目录
2.存储半导体
Micron在弗吉尼亚州扩产1α DRAM,并大幅提升晶圆美国国内供应能力
Micron预计2027年联合TSMC量产HBM4E,产能紧缺或将持续至2028年
Samsung高管团队拜访联发科,拟通过存储与代工捆绑策略争夺晶圆代工订单
Kioxia计划于2026财年量产332层第10代BiCS NAND闪存
3.AI数据平台
Azure NetApp Files突破云端EDA存储扩展瓶颈,支持大规模并发工作负载
Commvault发布数字主权准备情况报告,提出数字主权四大支柱与最小可行主权框架
4.AI数据中心
Marvell推出业界首款260通道PCIe 6.0 Switch优化AI Scale-Up网络架构
美国政府通过芯片与科学法案向量子计算生态注资20亿美元重点支持代工与硬件产能建设
5.AI模型与应用
NVIDIA开源发布NV-Generate-CTMR与NV-Generate-MR-Brain,大幅提升3D医学图像合成效率
[正文内容]

2.存储半导体
美光 Micron
2026-05-22:Micron在弗吉尼亚州扩产1α DRAM,并大幅提升晶圆美国国内供应能力
Micron宣布在其弗吉尼亚州马纳萨斯工厂正式启动1α DRAM的生产,这是美国本土制造的最先进存储技术。该节点主要用于支持关键应用的长生命周期内存,涵盖DDR4和LPDDR4产品。此次扩产项目投资总额超过20亿美元,将使该公司在马纳萨斯工厂的DDR4晶圆供应量提升至原来的四倍,主要面向汽车、国防、航空航天、工业、网络以及医疗设备等行业。作为Micron约2000亿美元美国投资计划的重要组成部分。Micron预计,马纳萨斯工厂将于2026年底生产出合格的1α DRAM。此外,纽约基地的地面准备工作已提前启动,而位于爱达荷州的第一家晶圆厂则预计于2027年中期实现初始晶圆量产。
2026-05-22:Micron预计2027年联合TSMC量产HBM4E,产能紧缺或将持续至2028年
Micron确认首款HBM4E将是JEDEC标准产品,计划于2027年量产。预计在HBM4E时代将过渡到1-gamma DRAM,其标准和定制HBM4E的逻辑芯片预计将由TSMC制造。AI生态系统正从人类交互转向智能体甚至机器对机器的工作流程,推理需求不断扩大,预计HBM、DRAM和NAND的产能紧缺状况将持续到2026年之后,甚至可能延续至2028年。此外,基于需求旺盛,Micron位于印度古吉拉特邦Sanand的全部内存产能已被预订满,在满负荷运转下可占Micron全球产量的10%。同时,爱达荷1号工厂的晶圆生产时间表也从2027年下半年提前至2027年中期。
三星 Samsung
2026-05-23:Samsung高管团队拜访联发科,拟通过存储与代工捆绑策略争夺晶圆代工订单
Samsung会长李在镕率领高层团队于5月21日前往中国台湾拜会联发科执行长蔡力行及管理层,主要目标是争取联发科的晶圆代工订单。目前联发科的生产主要外包给TSMC,但由于AI热潮导致TSMC产线接近饱和及代工成本攀升,Samsung试图利用产能缺口,通过自身在内存市场供不应求的优势作为谈判筹码,提出将DRAM或NAND存储器供应与晶圆代工合约相捆绑的合作模式。此外,双方的潜在合作还可能涉及Tesla等车用芯片与电子应用的供应链深度讨论,以及Samsung在Galaxy智能手机和平板电脑的入门机型中扩大采用联发科天玑系列应用处理器。Samsung此前已获得Tesla的长期合约,并正积极向AMD推销其2nm制程,意图通过向客户推广第二供应商策略,扭转其代工事业持续亏损的局面。
铠侠 Kioxia
2026-05-23:Kioxia计划于2026财年量产332层第10代BiCS NAND闪存
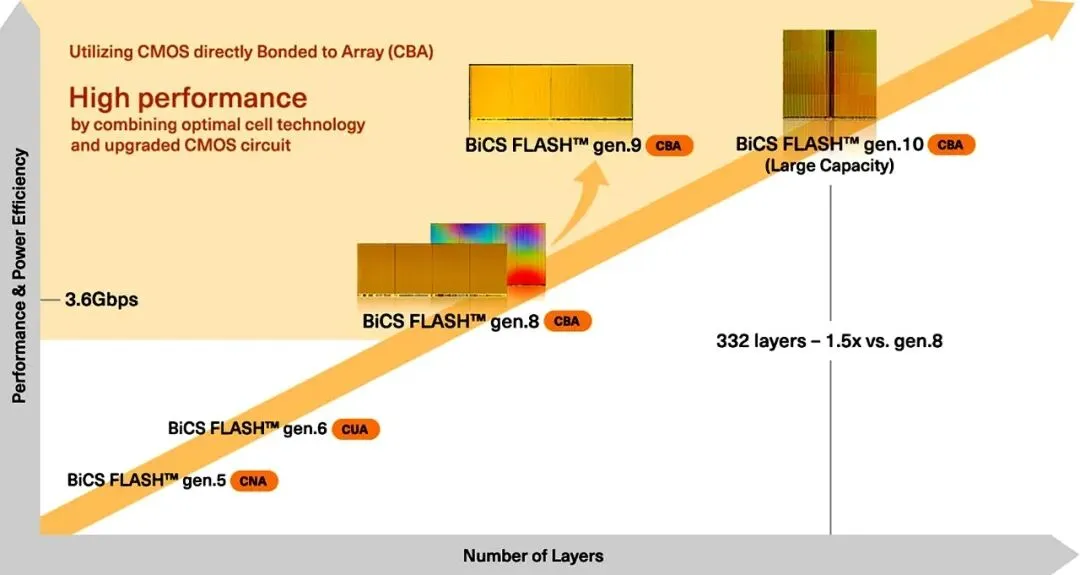
Kioxia宣布将量产下一代NAND作为核心优先战略,计划在2026财年推出并量产第10代BiCS NAND闪存。该代NAND应用了Kioxia专有的BiCS三维堆叠技术,共堆叠332层,相较于上一代218层产品,单位面积数据容量提升了59%,数据传输速度提升了33%。Kioxia近期的设施投资主要集中在第8代和第10代NAND。此举被业界视为在Samsung和SK Hynix推迟下一代NAND商业化的背景下,Kioxia旨在快速缩小与头部企业技术差距的关键策略。根据相关数据,Kioxia去年第四季度在全球NAND市场排名第三。
3.AI数据平台
NetApp
2026-05-22:Azure NetApp Files突破云端EDA存储扩展瓶颈,支持大规模并发工作负载
Microsoft Azure利用Azure NetApp Files提升了云端EDA工作负载的存储性能。现代半导体设计需要数千个并发作业连续运行,对共享文件系统在高并发、低延迟和密集共享数据访问模式等方面提出了极高要求。过去,随着并发规模增加,存储系统往往成为限制系统整体效率的瓶颈。
Azure NetApp Files专为高度并行和共享工作负载设计,实现计算与存储的独立扩展,使EDA集群在不产生存储层热点的前提下实现平滑扩容。其原生支持大规模并发元数据操作,并通过大容量卷与大容量突破模式等技术创新,支持数千个并行作业共享单个存储环境,并在持续负载下保持稳定延迟。
在独立的SPECstorage Solution 2020 EDA_BLENDED行业标准基准测试中,Azure NetApp Files大容量突破模式配置达到了17280个并发作业,总体响应时间仅为0.60毫秒(ms)。测试结果证明,其能够承载极高并发的EDA工作负载,在负载下保持极低响应时间,并随并发规模呈线性扩展,无需资源超配。目前,AMD与ASML等半导体领先企业已在生产环境中运行基于Azure NetApp Files的EDA和高性能设计工作负载。
Commvault
2026-05-22:Commvault发布数字主权准备情况报告,提出数字主权四大支柱与最小可行主权框架
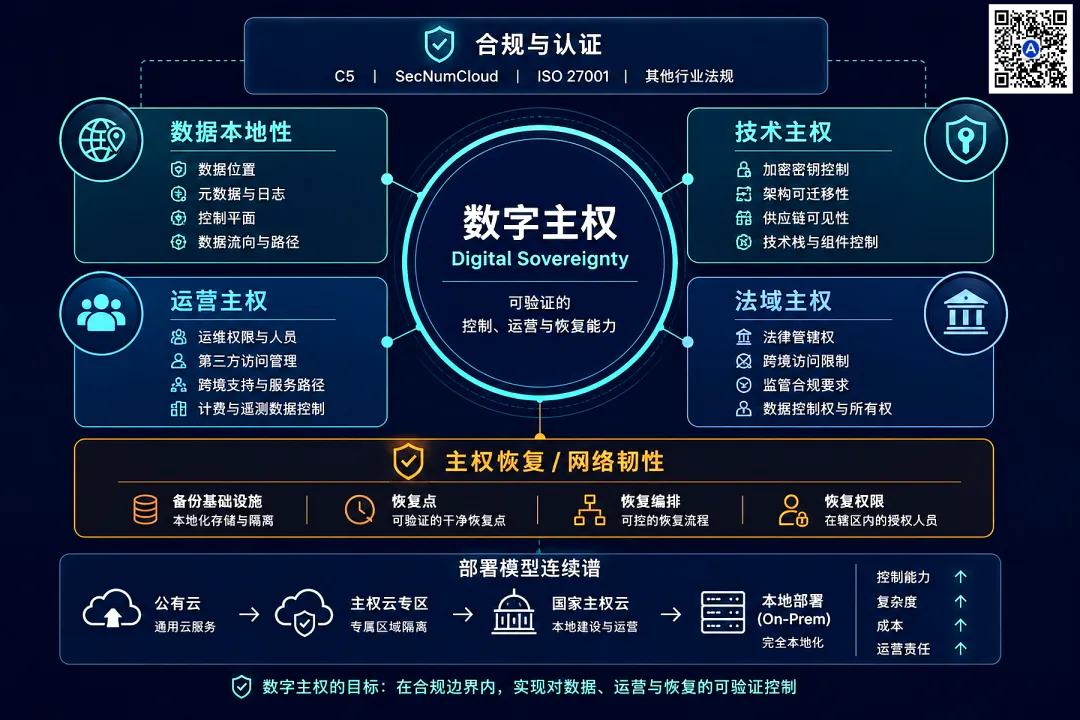
Commvault发布《数字主权准备情况报告》,指出多数企业易混淆数据驻留与数字主权概念。数据驻留仅解决数据物理存储位置问题,而完整的数字主权态势则取决于四大支柱:数据本地化、技术主权、运营主权和管辖主权。
报告强调,运营主权往往是企业主权合规计划中最薄弱且审计覆盖最少的部分。运营主权不仅关乎数据存储位置,更涉及系统访问人员身份及其所处的司法管辖区,涵盖第三方供应商访问、遥测流程、计费和控制面流量。即便原始数据未跨越管辖范围,此类控制面数据流仍可能跨越边界,带来潜在的合规风险。
此外,在数据恢复方面,大部分主权架构优先考虑访问控制与审计,而非实际的事件恢复准备。在遭遇勒索软件攻击时,若恢复人员位于主权边界外,或者备份基础设施和密钥保管模型缺乏与主环境一致的管控,将导致主权失效。具备主权就绪的网络韧性要求企业在真实场景下开展演练,并完成干净数据恢复验证,确保恢复点未受损害。
为解决跨混合环境的治理难题,Commvault提出了最小可行主权(MVS)原则,旨在对不同工作负载实施合适强度的管控,规避不必要的复杂性或防护缺位。该框架将企业划分为真正主权、受监管和混合多云三种配置画像。最小可行主权的落地实施包含三个步骤:首先根据每个支柱的实际需求对工作负载进行分类;其次将工作负载映射至满足对应要求的部署层级;最后在整个混合环境中实现一致的管控、审计证据与恢复能力管理。
4.AI数据中心
Marvell
2026-05-22:Marvell推出业界首款260通道PCIe 6.0 Switch优化AI Scale-Up网络架构
Marvell推出业界首款260通道的PCIe 6.0 Switch,即Structera S PCIe Switch,为AI Scale-Up网络确立了新的性能标准。PCIe技术广泛应用于共享系统中芯片之间的互连,在确保低延迟的同时,非常适合部署在Scale-Up领域。作为人工智能数据中心基础的系统常跨机架延伸,拥有数百个处理器,对低延迟 and 高带宽的互连有着极高要求。Structera S配备256个用于数据流量的通道以及4个用于管理的通道,是目前业界基数最高的PCIe Switch。传统的PCIe Switch架构需要多个设备进行扩展,增加了系统的复杂性与成本。通过Marvell的这款Switch,能够使网络架构更加扁平化,从而省去了在大型扩展系统中使用多个小型Switch的设计。
行业动态
2026-05-23:美国政府通过芯片与科学法案向量子计算生态注资20亿美元重点支持代工与硬件产能建设
美国商务部宣布将通过《芯片与科学法案》向9家量子计算生态公司提供总计20.13亿美元的联邦拨款激励,并获取上述公司的直接少数股权。这是美国将量子计算视作战略性基础设施的一项产业政策,旨在重点支持代工厂、硬件平台以及不同竞争架构的量子能力建设。在资金分配中,IBM将获得最大份额的10亿美元赠款,用于支持一家名为Anderon的新独立公司。该公司将在纽约州奥尔巴尼运营美国首家专门建造、基于300mm晶圆的量子代工厂,IBM也将为其注入10亿美元现金和资产。GlobalFoundries将获得3.75亿美元,用于支持量子平台的半导体制造。此外,D-Wave Quantum、Rigetti Computing、Infleqtion、Atom Computing、PsiQuantum和Quantinuum等六家公司将各获得1亿美元,初创公司Diraq可能获得最高3800万美元。D-Wave确认将利用资金加速其超导退火系统和门模型系统的开发,目标是推出具备1万0个量子比特的退火系统和1万个物理量子比特的门模型系统。这笔巨额注资引发了欧洲科技行业的警觉。业界警告,欧洲目前缺乏后续的商业层和大规模私人资本,美欧在深度科技项目上的风险投资差距已达100:1,建议欧洲组建联合实体以抗衡美国。行业专家指出,尽管硬件产能获得了大规模投资,但目前的量子生态依然缺乏应用层与算法层的支持。Zapata Quantum首席执行官Sumit Kapur强调,行业已经证明了量子优势,但下一个真正的考验是实现规模化的量子实用性,即在化学、药物发现、材料、密码学、机器学习等高价值领域创造现实世界的实际价值。
5.AI模型与应用
NVIDIA
2026-05-23:NVIDIA开源发布NV-Generate-CTMR与NV-Generate-MR-Brain,大幅提升3D医学图像合成效率
NVIDIA推出NV-Generate-MR-Brain并开源NV-Generate-CTMR端到端框架,旨在通过大规模合成逼真的3DCT与MRI数据及像素级解剖分割,解决3D医学成像领域面临的数据稀缺、隐私限制和专家标注成本高昂等瓶颈。该框架基于合成成像医学AI(MAISI)架构构建,包含基于潜在去噪扩散概率模型(DDPM)的MAISI-v1和基于潜在整流流的MAISI-v2两种模型架构。与此前的医学图像生成方法相比,MAISI-v2的推理速度提升了33倍,且生成的图像质量更高。
NV-Generate-CTMR是首个在单一模型内实现灵活的体素分辨率、可变的影像容积尺寸和全身覆盖的开源医学图像生成框架。研究人员无需为每种临床设置重新训练单独的模型,即可直接合成与真实临床方案相匹配的数据。最新发布的NV-Generate-MR-Brain专为高保真脑部MRI合成设计,基于全新发布的多模态MR-RATE数据集训练。MR-RATE是目前全球最大的开源多模态MRI数据集,包含来自83000多名患者的10万项脑部MRI研究,总计约70万个数据卷,并配有去标识化的放射学报告与元数据。
NV-Generate-MR-Brain能够实现高达512×512×256的高分辨率体积合成,涵盖T1w、T2w、FLAIR和SWI等多种序列,并提供ControlNet模块以生成指定的解剖结构或进行跨序列合成。为推动医学人工智能开发,NVIDIA开源了包括端到端推理代码、预训练权重和训练配置在内的完整要素,绝大多数模型采用NVIDIA开放模型许可证发布。用户可在NVIDIA RTX GPU上直接运行这些模型进行推理,在自有数据集上微调模型或生成合成数据,这显著降低了技术与计算门槛,且合成数据可直接集成至训练流水线中。
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)

