 夜雨聆风
夜雨聆风🎯 1.本周技术风向标
核心变化:GitHub可用率跌破85%迫使技术人重新评估CI/CD依赖链,同时DeepSeek、阿里、智谱三巨头同步突破Agent长程执行能力,AI编程从“辅助补全”跃入“自主执行”时代。GitHub内部文化瓦解与安全投毒事件,直接动摇了开发者的基础设施信任;而Agent Harness(模型+编排层)成为新战场,AI编程工具链从IDE插件进化为自主执行体。
关键数据支撑
- 推理速度:
GLM-5.1高速版 400 token/s(vs Claude Opus 4.7的47秒任务耗时,提速5.6倍) - Agent长程:
Qwen3.7-Max连续运行86小时,上万次工具调用不掉线 - 稳定性滑坡:
GitHub 4月可用率低于85%,Merge Queue漏洞与RCE漏洞修复率仅12%
行动优先级
- GitHub避险:
扫描VS Code扩展来源,禁用非官方插件;配置webhook自动切换至备用仓库;评估自托管GitLab/Gitea迁移成本 - 避免CI/CD流水线中断,降低供应链攻击面 - 学习Harness/Agent编排框架(LangChain/AutoGPT/Claude Code Harness):
掌握AI自主执行的核心中间件技能 - 抓住Agent工程师薪资溢价(50-80万/年 vs 普通后端30-50万) - 关注GitHub Roadmap变更信号:
若功能更新持续停滞(当前已暂停新功能开发),启动完整平台迁移评估 - 避免被单一平台锁定
🔧 2.技术深潜
Qwen3.7-Max:86小时自主执行的Agent基座
架构亮点:长程Agent自主执行能力,核心解决工具调用链的“掉线”问题(上万次调用保持一致性)。在无文档芯片(平头哥真武M890)上自主优化算子实现10倍加速,验证了“模型+Harness=Agent”范式的工程可行性。技术栈依赖RL反馈与系统级容错,通过YC-Bench模拟创业验证营收能力。
实现成本:人力投入:高(需RL与系统优化) | 时间周期:API试用2周 | 技术门槛:中(需掌握工具调用编排与Harness适配)
适用场景:企业自动化监控、芯片优化外包、模拟创业运营、跨系统长周期任务(如86小时连续数据分析管线)
技术评估:相比Claude Opus-4.6,HLE得分41.4 vs 40.0,Terminal Bench 2.0得分69.7,推理与编程全面超越。但需注意阿里云百炼API定价尚未公开,自建GPU集群成本高昂,建议先通过API验证长程一致性。
GLM-5.1高速版:旗舰模型推理提速5.6倍
架构亮点:TileRT推理引擎重写核心推理路径,优化动态批处理与KV缓存调度,将8卡H200服务器利用率大幅提升。旗舰模型首次实现400 token/s,打破“小模型才能快”惯例。上下文窗口当前200K,1M版本即将发布。
实现成本:人力投入:低(直接调用API) | 时间周期:1小时集成 | 技术门槛:低
适用场景:实时编码、网页生成、Agent任务加速(Agent任务从2小时缩至11分钟)
技术评估:头脑风暴与代码生成场景质量甚至优于GLM-5.1标准版,但API成本未知。建议立即申请测试,与Claude Opus 4.7对比任务耗时和成本效益。
💰 3.商机落地
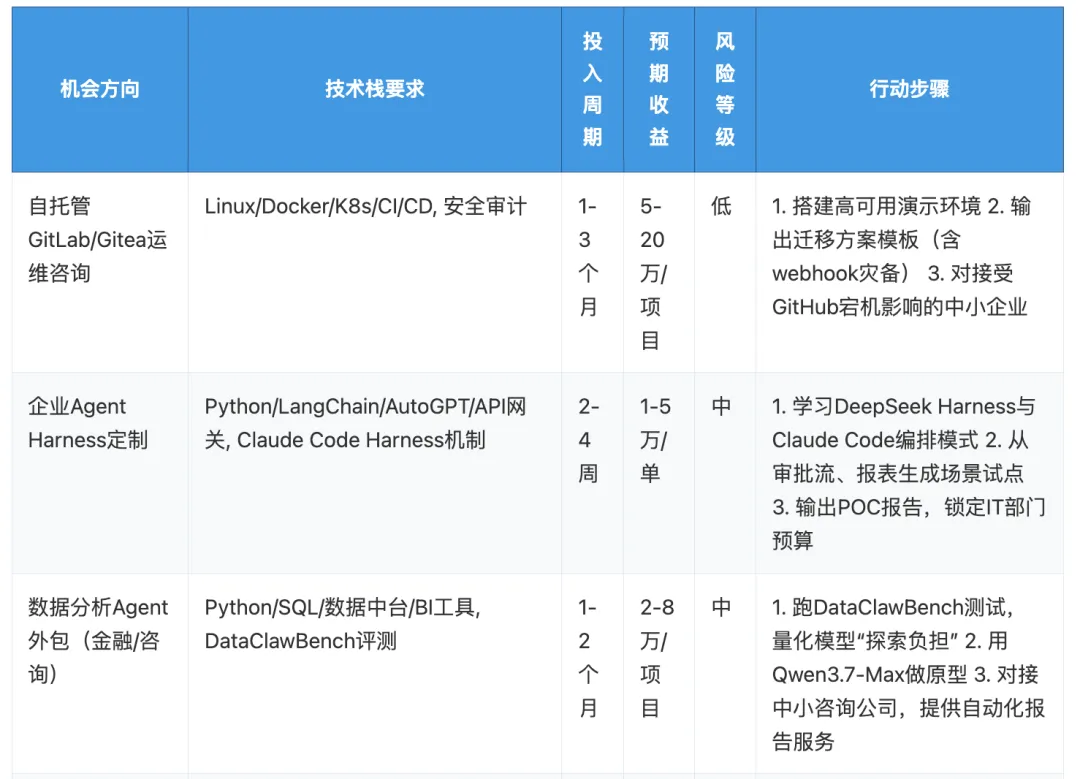

风险提示:自托管方案需应对GitLab自身安全漏洞(曾出现严重RCE),建议搭配WAF与定期补丁;Agent Harness定制可能面临模型API定价波动或断供风险,优先选择多模型兼容架构(如LangChain);数据分析Agent在“脏数据”场景下效果可能不及预期,需设置人工审核环节。
🛠️ 4.工具实战
SkillsUI:企业旧系统AI调度中间件
效率提升:减少30%+跨系统操作时间(如报销、发货、工单处理) | 学习成本:1天(模拟环境集成)
集成指南:注册官网获取API Key → 用REST API连接ERP/OA系统(需提供接口文档) → 配置自然语言指令映射(如“报销上个月差旅费”→调用费控系统) → 从报销、审批等高频场景灰度测试。关键参数:注意旧系统接口鉴权方式(OAuth2.0 vs 静态Token),建议先用沙箱环境验证。
避坑指南:旧系统API响应慢可能导致超时,需设置异步回调机制;中文自然语言歧义需配置领域词典(如“发货”可能指向不同系统)。
替代方案:开源RPA框架(UiPath社区版)+ LangChain调度链,或自建API网关+向量数据库实现指令路由。
DataClawBench:数据分析Agent过程级评测
效率提升:识别模型在“数据探索”阶段的瓶颈,避免盲目选型 | 学习成本:2小时跑Leaderboard
集成指南:下载HuggingFace数据集(492个未清洗智库任务) → 用自有模型跑任务,对比Claude/GPT-4过程级差异 → 重点关注“探索负担”指标(量化模型在未清洗数据上的表现)。配置参数:建议设置单任务超时时间5分钟,避免长尾任务卡死。
避坑指南:该基准仅适用于金融/咨询等复杂报表场景,通用型Agent(如客服)无需采用。若模型在“探索负担”得分低,说明需要增加数据感知模块(如schema推理、数据质量检测)。
替代方案:GAIA基准(通用Agent)、SWE-bench(编程Agent),但DataClawBench更贴近真实脏数据场景。
📊 5.数据决策
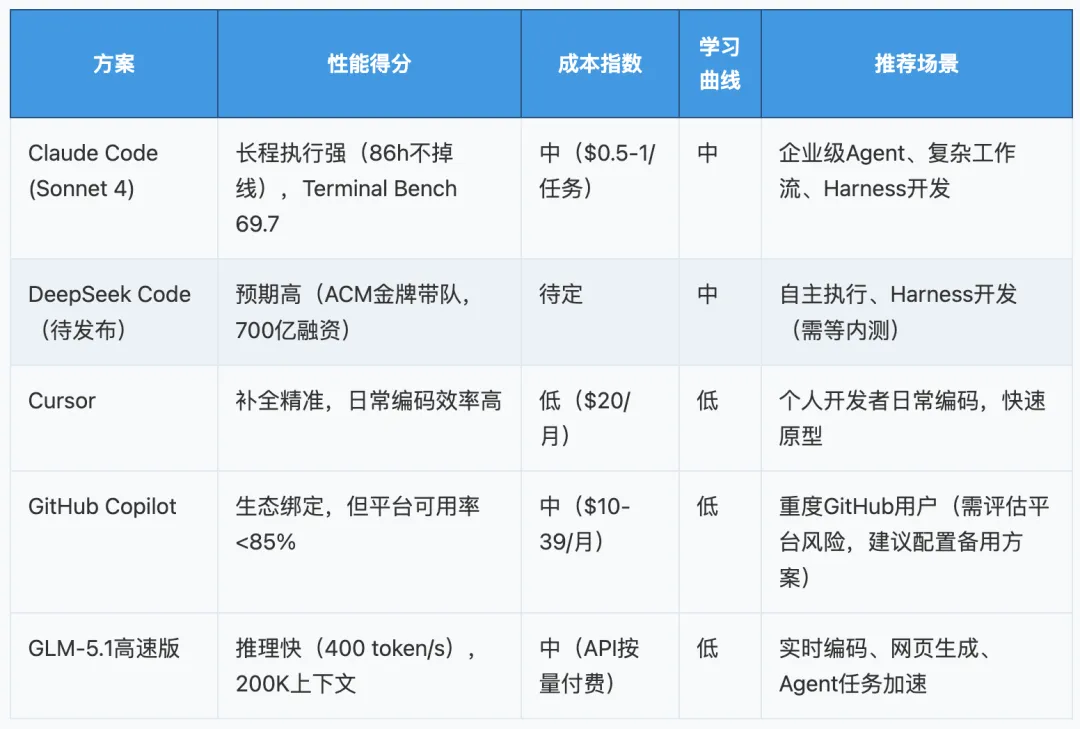
技术选型矩阵:AI编程工具
市场信号与薪资变化
- 招聘趋势:
Agent编排工程师(需求+300%)、AI工具链运维(+150%)、Harness开发(新岗位) - 薪资变化:
Agent工程师 50-80万/年 vs 普通后端 30-50万/年 - 机会窗口:
GitHub危机 + Agent爆发 = 3-6个月黄金期,自托管方案和Harness开发是短期套利点 - 风险指标:
GitHub功能更新停滞(暂停新功能),建议每周检查GitHub Roadmap;DeepSeek Code不确定性大,但Harness技能可迁移至Claude/Cursor生态
💎 总结:技术人的下周行动清单
- GitHub避险:
扫描VS Code扩展来源,禁用非官方插件;配置webhook自动切换至备用仓库(如自托管Gitea);评估自托管GitLab迁移成本(参考商机落地表) - Agent技能储备:
申请GLM-5.1高速版和Qwen3.7-Max API测试,跑DataClawBench对比过程级能力;学习LangChain/AutoGPT编排框架,重点关注工具调用链的错误恢复机制
