 夜雨聆风
夜雨聆风从“金鱼的记忆”说起
你是否熟悉这个场景——用Claude Code花了两小时调优,把项目架构、技术栈、命名规范全都对齐,AI状态绝佳,配合得天衣无缝。第二天新开对话,第一句话:“你好!我是Claude,请问你有什么需要帮助的?”
你不得不重新开始:这是个 monorepo,用 pnpm,后端 Fastify,前端 Next.js,数据库用 Drizzle ORM……每次都要把这些背景重新喂一遍。
这不是个例,而是每个 AI 编码工具用户的日常。它揭示了一个被广泛忽视却极其根本的痛点:
AI Agent 没有长期记忆。
传统的解决方案——CLAUDE.md、.cursorrules 这类静态文件,本质上是“头痛医头”的无奈之举。200 行软上限、全量加载进上下文、搜索靠 grep、跨 Agent 无法共享——这些先天缺陷让它注定成为过渡方案。更关键的是,即便你把全部上下文粘进去,年化 Token 消耗也高达 1950 万以上,远远超出合理的成本边界。
这就是 agentmemory 要解决的核心命题。
这个 2026 年初横空出世的 GitHub 热门开源项目,在三个月内从 0 暴涨到近 15,000 Stars,凭借的是一套彻底不同的技术路径——为 AI Agent 构建持久化、可检索、跨工具共享的记忆系统。与其让 AI 每次重新学,不如让它真正“记住”。
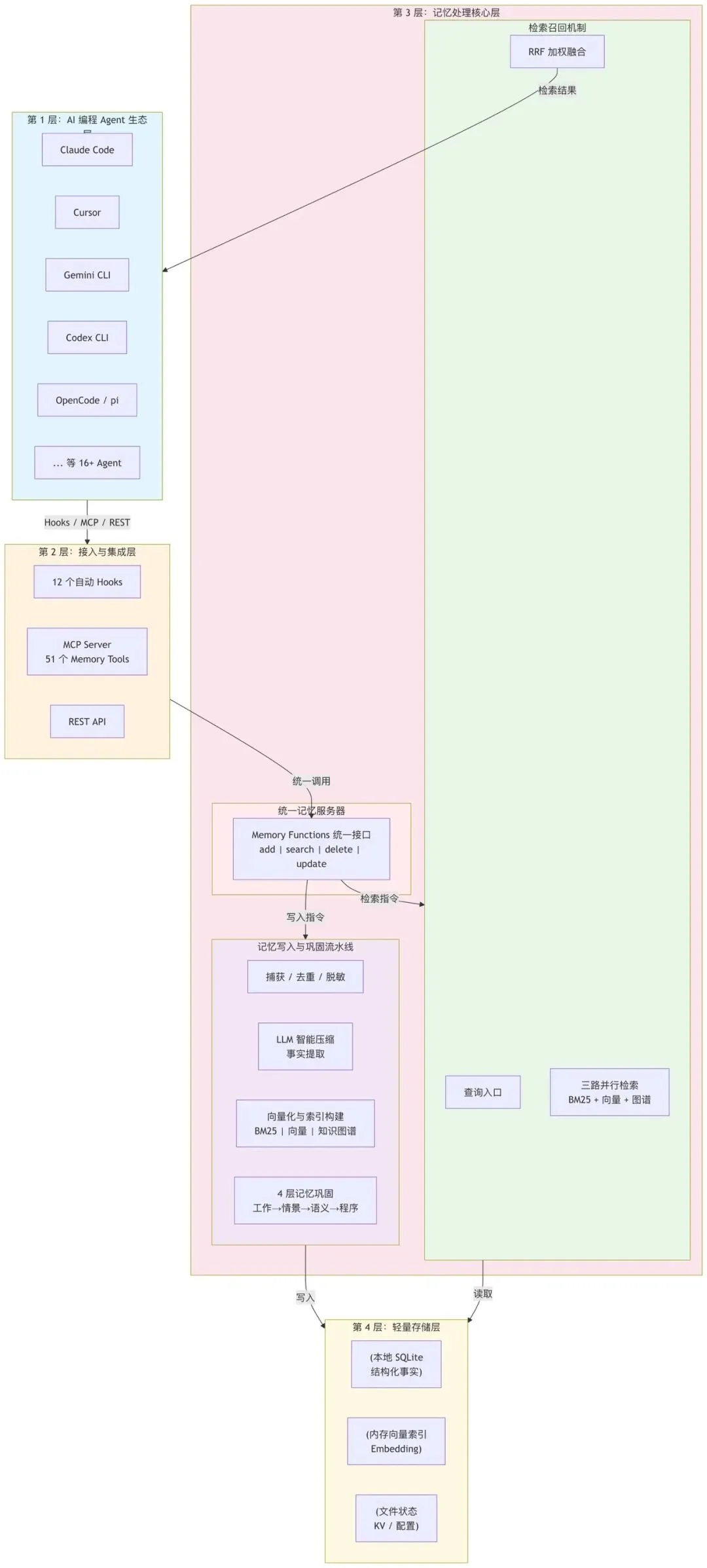
一个引擎,三层抽象
技术圈常有一个误区:做个记忆系统无非就是搭个向量数据库再加个 RAG 检索。但 agentmemory 的设计团队显然不这么认为。
它的核心选择是:不重复造轮子,而是站在 iii engine 的肩膀上。iii engine 是一个用 Rust 编写的轻量级事件驱动运行时,提供了三个最基础的原语——Worker、Function、Trigger。agentmemory 正是通过 registerFunction、registerTrigger 以及 sdk.trigger(),把所有能力都接入引擎。
这样做的好处很直接。
首先,代码量非常精简——核心逻辑仅约 21,800 LOC
其次,MCP、REST、Hooks 看起来是三种接入方式,实际都落到了同一组核心 memory functions 上,架构的一致性非常好。
更重要的是,这套设计使其几乎不需要任何外部数据库,直接复用 iii 内置的 KV 状态模块和内存向量索引,部署时一条命令就能完整启动,复杂度大幅降低。
在架构上,agentmemory 呈现为清晰的三层结构:
· Agent 层:Claude Code、Cursor、Gemini CLI、Codex CLI、OpenCode、Cline、Goose 等十六余种主流编码助手
· 集成层:12 个自动 Hooks + MCP Server(51 个工具)+ REST API
· 存储层:基于 iii-engine 的本地 SQLite / 文件状态,零外部数据库
记忆流水线:从原始事件到结构化知识
如果说架构决定了系统的可扩展性,那么记忆处理流水线则直接决定了智能能力的上限。agentmemory 的处理链条值得深入理解:
第一步:捕获。
通过 12 个生命周期钩子(SessionStart、UserPromptSubmit、PreToolUse、PostToolUse 等),无缝捕获 Agent 的每一次工具调用、文件变更和错误上下文。这个过程对用户透明,无需手动干预。
第二步:去重。
用 SHA-256 对每条观察记录做哈希,5 分钟滑动窗口内相同操作不重复存储,避免记忆膨胀。
第三步:隐私过滤。
正则表达式自动剥离 API Key、Token、
第四步:智能压缩。
第五步:向量化与索引构建。
这套流程最值得称道的一点是:它对用户完全透明。唯一需要配置的是一个 .env 文件(或者干脆完全使用本地模型),Agent 就能在后台自动积累“经验”。
四层记忆巩固:模拟人脑的遗忘与强化机制
agentmemory 并没有把所有记忆一视同仁。它借鉴认知科学的“海马体-皮层”记忆分层模型,设计了一套四层记忆巩固体系:
层级 :存储内容 更新频率
工作记忆: 每次工具调用的原始观察结果 最高
情景记忆: 每个会话的压缩摘要 中
语义记忆: 跨会话的事实与模式 低
程序性记忆 :工作流与决策模式 最低
这套分层体系不是静态的。
三种信号,一次融合
记忆的存储只是一半的工作,另一半是“如何精准召回”。
· BM25 词法流:处理关键词匹配、词干提取与同义词扩展,始终可用,零延迟
· 向量语义流:基于密集嵌入的相似度匹配,理解同义表达和隐含语义
· 知识图谱流:在检测到实体时触发,通过实体关系遍历找回拓扑相关记忆
三种检索信号通过 RRF(Reciprocal Rank Fusion,k=60)算法加权融合,最终输出 Top-K 最相关的记忆片段。
这就是 agentmemory 能够将 Token 开销压缩到极致的原因——不是把整段历史粗暴塞回上下文,而是在海量记忆中只取最相关的几块注入。
基准测试:不止是概念验证
在 ICLR 2025 发布的 LongMemEval-S 基准(500 道问题)上:
系统 :R@5 R@10 MRR 来源
agentmemory: 95.2% 98.6% 88.2% 官方
mem0 : 68.5% — — mem0 论文
Letta / MemGPT :83.2% — — Letta 文档
95.2% 的 R@5 召回精度意味着:在真实编码场景中,agentmemory 的前 5 个检索结果里有超过 95% 的概率覆盖用户真正需要的记忆。
Token 消耗的对比更具说服力。240 条观察记录下,CLAUDE.md 的方案需注入约 22,000 tokens,而 agentmemory 仅需约 1,900 tokens——直接节省 92%。年化推算的差距更为惊人:
· 直接粘贴完整上下文:年化约 1950 万 tokens
· LLM 摘要方案:年化约 65 万 tokens
· agentmemory:年化约 17 万 tokens,换算下来年成本不足 10 美元
这意味着:即便你不自托管而完全依赖云端服务,agentmemory 也能让你在主流 AI 工具的免费额度内,实现超过一年的跨会话持续记忆。对比而言,其他方案要么直接把预算烧光,要么根本撑不过一个复杂项目的开发周期。
agentmemory 在设计哲学上有一条清晰的路线:不是功能罗列,而是基于真实基准驱动优化。这个定位让它与其他记忆框架形成了本质区别。
零依赖部署与跨工具集成
agentmemory 还有一个在很多技术选型中被低估但实际极其重要的特性:零外部数据库依赖。
无需 Redis、无需 PostgreSQL、无需 Qdrant。
同时,agentmemory 并不止于本地部署。它支持通过 MCP 或 REST API 接入,可以部署在 Railway 等云平台上作为共享记忆服务,团队内所有成员的多种 Agent 可共享同一个记忆池。
在工具生态方面,它的兼容性覆盖非常广泛。
未来展望:记忆系统将成为 Agent 的基础设施
回顾整个 AI Agent 领域的发展历程
agentmemory 正是这一趋势的最佳注脚。它不是另一个炫技的模型或框架,而是一个生产就绪、轻量可扩展的基础设施组件,服务于 AI Agent 最基础的需求——记住过去,理解现在,预见未来。
如果你正被“每次对话都要重新介绍项目结构”这件事困扰,也许可以花 30 秒体验一下:
```bash
# 一行命令,无痛体验
npx @agentmemory/agentmemory demo
```
这 30 秒过后,你将亲身体验到语义检索的威力——搜索“数据库性能优化”,能召回“修复 N+1 查询”的上次会话。
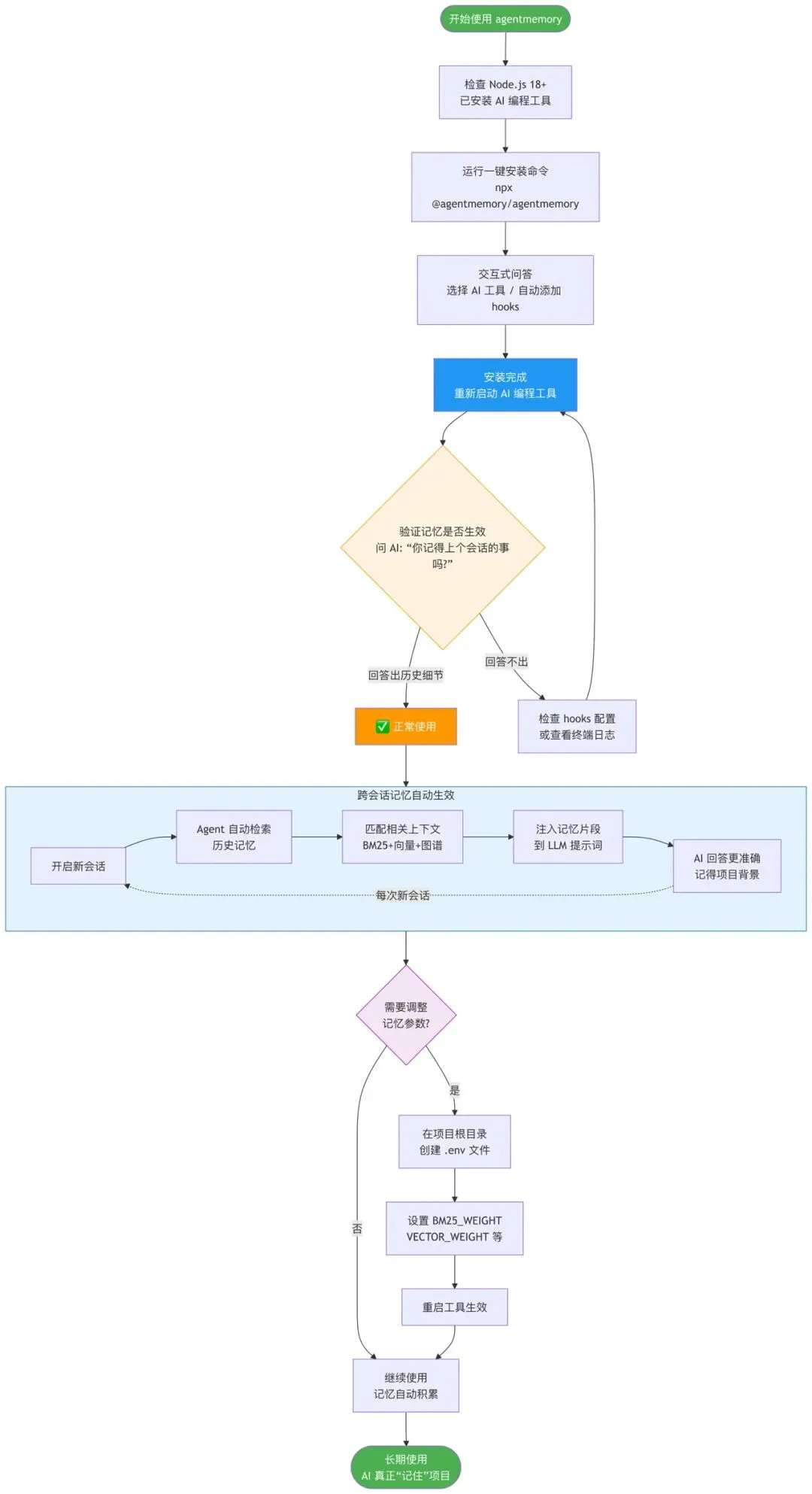
📌 附:小白上手指南
1. 项目主页
· GitHub 仓库:
官方文档:https://agent-memory.dev
2. 安装前提
· 电脑上已安装 Node.js 18+
· 使用 Claude Code、Cursor、Gemini CLI 等任意一款 AI 编程工具(没有的话选 Cursor 免费版就行)
3. 一键安装
打开终端
```bash
npx @agentmemory/agentmemory
```
系统会自动下载并运行安装向导。
· 你用的是哪个 AI 工具?
· 是否自动添加 hooks 配置?(选 Y)
4. 验证是否成功
安装完成后,重新打开你的 AI 编程工具
如果 AI 回答出了你之前聊过的技术细节,说明记忆系统已经生效 🎉
5. 可选:让记忆更聪明
如果你想调整记忆强度(比如让 AI 更依赖历史经验)
```ini
BM25_WEIGHT=0.4
VECTOR_WEIGHT=0.6
MEMORY_RETURN_LIMIT=3
```
保存后重启 AI 工具即可。
现在,就让你的 AI 编程助手拥有“过目不忘”的超能力吧!
