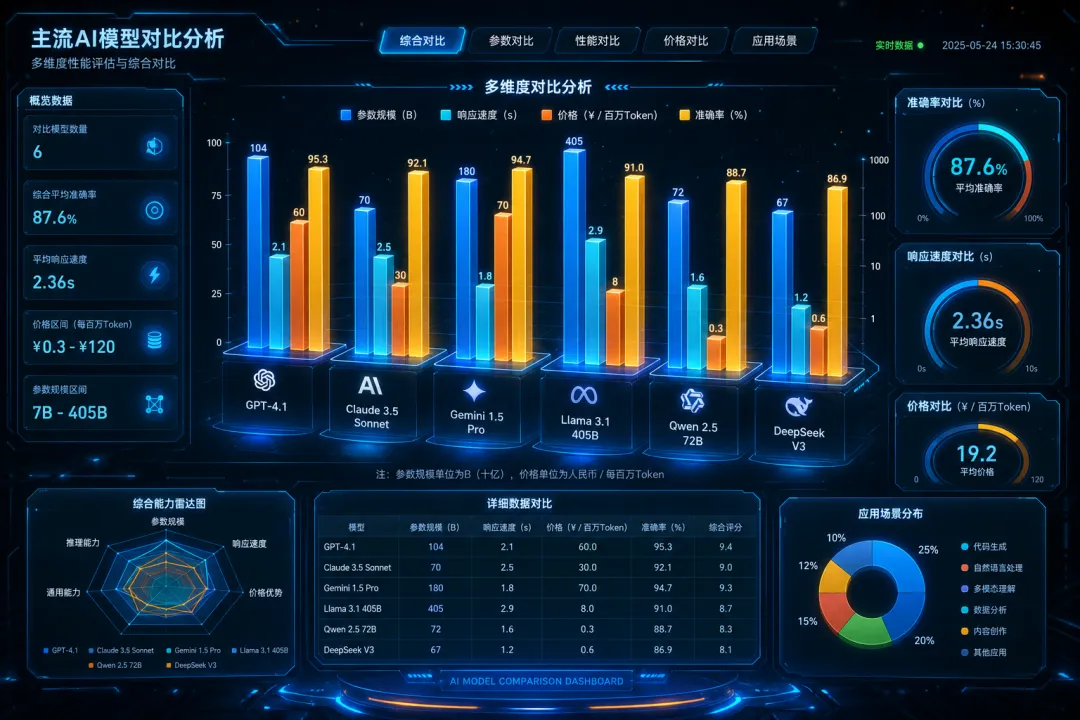
AI模型界的“大众点评”在GitHub爆火——当开发者拒绝再当定价黑箱的人肉韭菜点击上方蓝字关注我们📌 导读Models.dev在GitHub上发布了一个开源AI模型规格与定价数据库,由anomalyco团队维护,旨在聚合不同厂商模型的参数、能力和API成本信息,让开发者摆脱厂商营销话术的迷宫。 2026年5月,AI开发者社区陷入了一种集体性焦虑。一边是OpenAI据传即将启动史上最大规模的AI公司IPO,估值数字在投行报告里不断刷新天花板;另一边,谷歌I/O大会上,开发者们对迟迟未发布的Gemini新模型发出一片叹息。模型迭代的速度已经快到让人眩晕——今天还在调试Claude 4的提示词,明天HuggingFace上又冒出一个下载量破270万次的开源新秀。 但真正让一线工程师夜不能寐的,不是模型不够多,而是模型太多、太乱、太不透明了。你打开三家云厂商的定价页面,同一个“Llama系列模型”,A厂按每百万token计费,B厂按每小时实例收费,C厂则捆绑了一堆你根本不需要的增值服务。你想对比一下上下文窗口?抱歉,有的标128K,有的写“最大支持200K”,还有的只在技术白皮书第47页的脚注里提了一句“实际可用窗口受限于RoPE插值策略”。这根本不是技术选型,这是一场规格迷宫里的饥饿游戏。而Models.dev,一个悄然在GitHub上生长的开源数据库,正试图用一套完全不同的逻辑打破这场信息壁垒——把模型世界的“黑盒”拆开,让参数、定价、性能赤裸裸地摊在阳光下。 01架构解析:当数据库本身成为开源武器 Models.dev的技术骨架,从一开始就与传统封闭式模型市场划清了界限。据其GitHub仓库显示,这个项目本质上是一个社区驱动的结构化数据仓库,所有模型信息以标准化格式存储在开放目录中。这意味着任何人——不仅是anomalyco团队,也包括你和我——都可以通过提交PR来新增模型条目、修正过时参数,甚至质疑某个厂商宣称的“推理速度”是否真实。 这种开源协作模式在技术架构上催生了两个关键特性。首先,数据采集机制是分布式的。不同于某个中心化爬虫定期抓取API文档,Models.dev依赖全球开发者贡献第一手实测数据。比如,有人发现某模型在特定并发量下延迟会暴增3倍,这种信息根本无法从官方规格表获得,却能在社区里被迅速记录。 其次,模型规格字段被高度标准化——参数规模、上下文窗口长度、训练数据截止日期、支持的语言列表、输入输出格式,每个字段都有明确的类型定义和验证规则。这听起来平淡无奇,但如果你曾试图在不同厂商的文档里对齐“模型尺寸”这个最基本的概念,就会明白标准化本身就是一场微型革命。 更深层地看,Models.dev的API接口开放性才是其真正锋利的刀刃。数据库不仅提供网页浏览,还开放了结构化数据导出,允许开发者直接在自己的工具链中集成模型对比功能。想象一下,你的CI/CD流水线里跑着一个自动化脚本,在每次部署前实时拉取最新的模型定价和性能数据,然后根据预算和延迟要求动态选择最优API——这不是科幻,这是Models.dev正在铺设的基础设施轨道。 02规格透明化:把“上下文窗口”从营销话术还原成工程参数 模型规格的标准化对比,是Models.dev最直接的价值锚点。数据库将不同厂商的模型拉到同一个平面上,用统一的度量衡进行横向比较——参数规模、推理速度、上下文窗口、支持的语言、知识截止日期,每一项都成为可排序、可筛选的字段。这不是简单的信息聚合,而是一种认知框架的重构。 以开发者最头疼的“上下文窗口”为例。厂商A声称支持200K tokens,但实际测试发现,当输入超过64K tokens时,模型对开头部分信息的召回率会断崖式下跌到50%以下——这种“有效窗口”与“标称窗口”的差距,在Models.dev的社区注释中被明确标注。再比如推理速度,厂商B宣称“每秒生成100 tokens”,但在并发请求超过10个时,实际吞吐量会骤降至不到30 tokens/秒。这些数据不是来自任何官方基准测试,而是来自社区开发者的真实踩坑记录。 讽刺的是,正是这些“非官方”数据,构成了模型选型中最具决策价值的硬通货。Models.dev还尝试集成基准测试分数,但做法相当克制。它没有试图构建一个“大一统”的评分体系——这种尝试在AI评测领域已经失败过太多次——而是将MMLU、HumanEval等主流基准的实测结果作为参考字段列出,同时标注评测条件和数据来源。 这种“只呈现、不评判”的姿态,反而赋予了数据库一种难得的可信度。对于一线开发者而言,决策效率的提升是立竿见影的:过去需要三天才能完成的模型选型调研,现在可能压缩到三小时,而且结论更可靠。 03定价经济学:当每个token的成本都暴露在阳光下 如果说规格透明化解决的是“选什么”的问题,那么定价透明化直面的就是“花多少钱”的终局拷问。Models.dev对模型定价数据的处理,堪称一场对云厂商定价部门的精确狙击。数据库统一展示了按token计费、按请求计费、按时间计费等多种模式,并将它们折算成可比的单位成本。 这种透明化揭示了一个行业里心照不宣的秘密:隐藏成本无处不在。有些模型虽然每百万token价格极低,但输入和输出token的计费比例悬殊——输入便宜得近乎免费,输出却贵得惊人。如果你构建的是一个输出密集型应用,比如生成长篇报告或代码,最终账单会远超预期。 还有些厂商在API调用中捆绑了“网络请求费”“并发实例费”等隐性项目,这些费用在官方定价页上根本找不到,却在Models.dev的社区贡献条目里被一一拆解。更微妙的是,不同云平台对同一个开源模型的托管定价差异巨大——同样运行Llama 3.1-405B,平台X的价格可能是平台Y的2.5倍,而性能完全一致。 这种信息对称化对市场格局的冲击是深层的。当开发者可以轻易对比不同厂商的性价比,云厂商的定价策略就不得不从“信息套利”转向“价值竞争”。历史上,类似的故事在云计算的其他领域已经上演过——AWS的EC2定价透明度提升后,整个IaaS市场的溢价空间被大幅压缩。Models.dev正在AI模型服务市场复制这一剧本。 04社区驱动与生态博弈:维基百科,还是大厂的收编目标? Models.dev的长期生命力,取决于一个根本性的张力:它能否在社区驱动和商业收编之间,找到一条可持续的第三条道路。目前,项目完全依赖开源贡献者的无偿劳动来维持数据鲜活度。这种模式的优势在于中立性和敏捷性——社区成员没有厂商立场,更新速度往往快于官方文档。 但劣势同样致命:数据偏差、更新滞后、覆盖不全,这些开源数据库的通病,Models.dev一个也没躲开。活跃贡献者往往来自特定技术栈或地域,导致某些模型(尤其是英文主流模型)的信息极其详尽,而另一些(比如中文垂域模型或新兴市场的本地化模型)则近乎空白。更新滞后则源于“贡献疲劳”——当模型迭代速度以周为单位,志愿者的热情却遵循人类精力的自然曲线。 更现实的挑战是商业可持续性。GitHub仓库和静态网页的运维成本或许不高,但如果数据库要进化到提供实时API、自动化测试、基准验证等高级功能,服务器成本和人力投入将指数级增长。谁来买单?生态博弈的维度更加复杂。Models.dev的定位是成为AI生态中的“中立的维基百科”,但它的数据价值对于大厂而言是一块肥肉。 一个可能的演化路径是:某家云巨头将Models.dev整合进自己的开发者工具套件,注入资源但稀释中立性。另一个可能是:社区通过某种治理机制维持独立性,但必须在数据质量上与商业竞品正面竞争。无论哪种路径,Models.dev的终极考验不是技术,而是信任——当开发者打开这个数据库,他们必须确信看到的是事实,而不是某个厂商精心编排的营销橱窗。 05结语:开源数据库不是答案,而是提问的方式 Models.dev的出现,标志着AI基础设施的民主化进程又向前迈了一步——不是通过训练更强大的模型,而是通过让现有模型的真相变得触手可及。它像一面镜子,照出了这个行业在疯狂奔跑中试图掩盖的混乱与不透明。当每一个token的成本、每一毫秒的延迟、每一个百分点的召回率都被记录在案,模型厂商还能靠PPT和新闻稿讲故事吗?当社区贡献者的实测数据比官方基准更受信赖,评测体系的权力中心是否会从实验室转移到GitHub的Issue区?这些问题的答案,不取决于Models.dev本身,而取决于我们——每一个在选型迷宫中挣扎过的开发者——是否愿意花十分钟,把踩过的坑记录成一条数据,把验证过的真相提交成一个PR。 讨论话题:你在选型AI模型时,踩过最深的“定价坑”或“规格坑”是什么?是某个厂商的隐藏费用,还是一个在实际应用中完全失效的标称参数?评论区聊聊你的真实经历~END往期推荐:字节跳动开源Lance,3B参数端侧多模态模型——当128张GPU掀翻云端军备竞赛Vite 8.0用Rust把构建压进2秒——前端工具链的“铁锈革命”烧到了谁?商汤把办公AI开源了——当你的Excel终于等来一个“懂行”的AI助手
 夜雨聆风
夜雨聆风