 夜雨聆风
夜雨聆风
CiteVQA: Benchmarking Evidence Attribution for Trustworthy
Document Intelligence
报告原文地址:https://arxiv.org/pdf/2605.12882
报告概述
上海人工智能实验室于2026年5月发布CiteVQA基准,首次将文档理解评测从单纯的答案准确率推向“答案+视觉证据”联合验证的新阶段。通过对20个主流多模态大模型(MLLM)的测试,报告揭示了普遍存在的“归因幻觉”:模型虽能输出正确答案,却常引用错误的文档区域。当前最优模型Gemini-3.1-Pro的严格归因准确率(SAA)仅为76.0%,而最强开源模型仅为22.5%,暴露出文档智能在高风险场景下的可靠性缺口。
核心洞察
“伪可信”风险:答案正确不再等同于系统可靠。在法律、金融等领域,模型若依据错误条文得出正确结论,其危害可能比直接答错更大,因为错误更难被察觉。
闭源与开源的断层:闭源模型在证据归因上占据绝对优势,但即便是最顶尖的模型也远未达到完美。开源模型则集体遭遇“归因悬崖”,SAA普遍低于25%,难以支撑严肃的商业部署。
检索是推理的前提:实验表明,当人为缩小搜索范围(提供正确页码或文档)时,模型表现显著提升。这说明目前的模型瓶颈往往不在于逻辑运算,而在于第一步的“找证据”就出了错。
一、为什么我们需要“看得懂证据”的AI?
长期以来,文档视觉问答(Doc-VQA)的评测就像只看考试分数的老师,只关心模型给出的答案对不对,却不管它是真学会了还是蒙对的。但在现实世界里,这种“黑盒”模式风险极高。
想象一下,一个医疗AI诊断患者患有某种疾病,答案是对的,但它引用的依据是病历里的无关段落,而不是关键的化验单。这种“归因幻觉”会导致医生无法复核,甚至产生误判。
为了解决这一问题,上海AI实验室推出了CiteVQA。与传统基准不同,它强制模型在回答时必须附带元素级(Element-level)的边界框(Bounding-box)引用,明确指出答案来自文档的哪个具体段落、表格或图片。
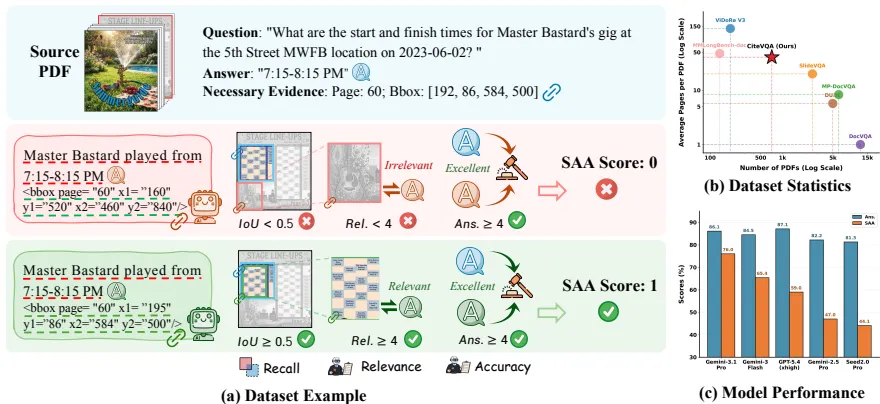
CiteVQA包含711份PDF文档,平均长度40.6页,覆盖7大领域。它填补了传统评测仅关注单页、缺乏细粒度证据标注的空白。
二、如何定义“靠谱”?
CiteVQA构建了包含1897个问题的数据集,并设计了一套严苛的评分体系。其核心指标是严格归因准确率(Strict Attributed Accuracy, SAA)。
SAA要求模型必须同时满足两个条件才算得分:答案正确且证据引用正确(IoU阈值≥0.5,或相关性评分≥4)。这就好比不仅要答对题,还要把解题步骤写对。
此外,评测还引入了召回率(Rec.)和相关性(Rel.)作为辅助指标,分别衡量模型能否找到关键证据,以及引用的证据是否真的能支持答案。
表1展示了CiteVQA与前代基准的对比。可以看出,它在证据粒度(细化到元素级)和联合评测机制上具有显著优势。
基准名称 | 文档数量 | 平均页数 | 证据粒度 | 联合评测 |
|---|---|---|---|---|
DocVQA | 12,767 | 1.0 | 页面级 | ✗ |
MP-DocVQA | 6,000 | 8.3 | 页面级 | ✗ |
MMLongBench-Doc | 135 | 47.5 | 页面级 | ✗ |
CiteVQA (Ours) | 711 | 40.6 | 元素级 | ✓ |
表1:CiteVQA与代表性Doc-VQA基准对比。传统基准多停留在页面级检索,而CiteVQA要求精确到具体的表格单元格或段落。
三、残酷的真相:20个模型的“大考”
研究团队测试了包括Gemini、GPT-5、Qwen-VL在内的20个主流模型。结果揭示了当前技术的真实水位。
1. 归因幻觉普遍存在
几乎所有模型都表现出“高分低能”的特征:答案准确率(Ans.)很高,但SAA得分大幅跳水。例如GPT-5.4的答案准确率达到87.1,但SAA仅为59.0。这意味着近三分之一的情况下,模型是在“瞎编”引用。
2. 闭源领跑,开源掉队
Gemini-3.1-Pro以76.0的SAA位居榜首,显示出其在长文档理解和空间定位上的优势。相比之下,即使是参数量巨大的开源模型(如Qwen3-VL-235B),SAA也仅为22.5,且小模型几乎全军覆没(SAA多低于10)。
3. 多文档是“拦路虎”
随着任务复杂度增加(从单文档到多文档多答案),所有模型的归因能力均出现断崖式下跌。这表明跨文档的证据关联和去重,是目前模型最大的短板。
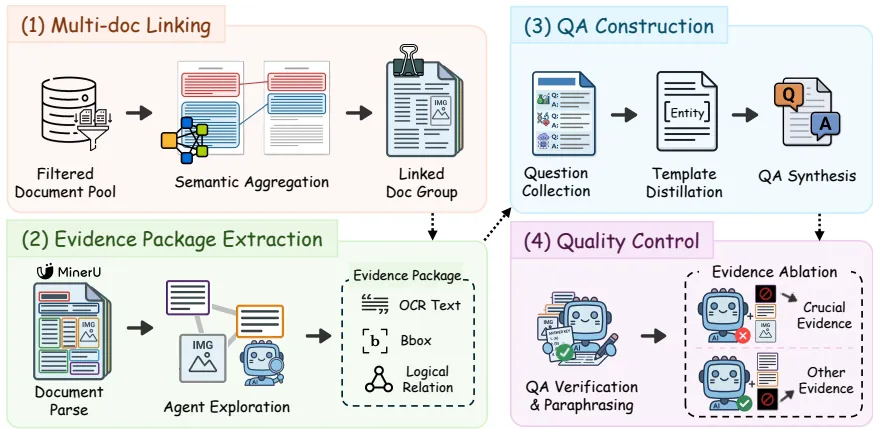
图1c:主流模型在CiteVQA上的SAA得分。即便是顶尖模型,在需要精确引用证据的场景下,表现也远不如单纯的问答任务。
表3详细列出了各模型在不同场景下的表现。数据清晰地显示,开源模型在召回率(Rec.)上尤其薄弱,说明它们经常连正确的证据页都找不到。
模型 | 单文档 SAA | 多文档(1金标) SAA | 多文档(N金标) SAA | 总体 SAA |
|---|---|---|---|---|
Gemini-3.1-Pro-Preview | 76.0 | 79.7 | 71.6 | 76.0 |
Gemini-3-Flash-Preview | 69.3 | 61.8 | 60.5 | 65.4 |
GPT-5.4 | 61.7 | 56.9 | 55.1 | 59.0 |
Qwen3-VL-235B-A22B | 25.0 | 21.6 | 17.8 | 22.5 |
Qwen3-VL-8B | 8.8 | 6.8 | 5.2 | 7.5 |
表3:部分代表性模型在CiteVQA上的综合表现(节选)。分数均已归一化为百分制。SAA是衡量模型可信度的核心指标。
四、案例剖析:差之毫厘,谬以千里
通过具体案例,我们可以直观看到归因幻觉的危害。
在一个查询药品NDC编码的任务中,Qwen3-VL-235B虽然给出了完全正确的答案(Ans.=5),但其引用的截图要么是空白,要么是不相关的段落。按照SAA标准,这次预测得分为0。
而Gemini-3.1-Pro虽然引用略有偏移,但核心证据精准,获得了满分。

图7:案例对比。左侧模型答对了但引用错了(SAA=0);右侧模型不仅答对了,引用也精准(SAA=1)。
五、局限与启示
尽管CiteVQA构建了一个自动化的高质量数据集,但仍存在局限。例如,极度专业的垂直领域(如特定法律条款解释)可能需要更精细的定义。此外,自动化评测的计算成本较高,限制了大规模复现。
对于行业而言,这一发现敲响了警钟。在金融审计、法律文书审查等对溯源要求极高的场景中,单纯依赖模型的答案是危险的。未来的应用架构可能需要引入“人工复核回路”,或者专门训练针对证据归因的增强模块。
结语:信任始于溯源
CiteVQA的价值不在于给模型排名,而在于重新定义了什么是“可信的AI”。答案正确只是表象,证据确凿才是本质。 对于开发者和企业来说,在追求更高准确率的同时,必须同步关注模型的归因能力。毕竟,在关键决策面前,一个能告诉你“我从哪里看到这个”的AI,远比一个只会自信回答的AI更有价值。
