 夜雨聆风
夜雨聆风5 月,阶跃星辰发布了 StepAudio 2.5 Realtime,一个端到端实时语音大模型。
官方同时甩出了一份覆盖 5 个维度的 benchmark 评测报告——5 项全部第一。对手是谁?GPT-Realtime-1.5、Gemini Live、豆包 Realtime。
"中国语音 AI 碾压硅谷巨头"的标题满屏飞。但我们把原始数据拆开看完,发现故事比排名复杂得多。
本文给你三样东西:① 5 维度评测到底赢了什么、输了什么 ② 四家定价横向对比 ③ 如果你现在要接入语音 AI,怎么选。
一、StepAudio 2.5 是个什么东西?
简单说,这是一个能跟你实时语音聊天的 AI,主打三个字——活人感。
它不只是听懂你说什么,还能听出你怎么说的:语速快了是着急、尾音下沉是失落、中间那声轻笑是真的觉得好笑还是在敷衍。
它还允许你通过 API 自定义 AI 的"人设"——性格、口癖、说话风格、情绪边界、什么话题能聊什么不能聊——精细化到"这个角色会说'哈哈哈'但不说'笑死'"的程度。
定位很清晰:不是做工具型语音助手("打开空调""播放音乐"),而是做有灵魂的聊天搭子。
 图:StepAudio 2.5 Realtime 官网体验中心,支持中英文实时语音对话
图:StepAudio 2.5 Realtime 官网体验中心,支持中英文实时语音对话
二、5 维度评测,拆开看
以下是 StepAudio 2.5 官方放出的横向对比数据(2026 年 4 月测试)。
先看一张全景雷达图——这是 Step-Audio 2 开源技术报告中的多模型对比,StepAudio 在最外层,全面领先:
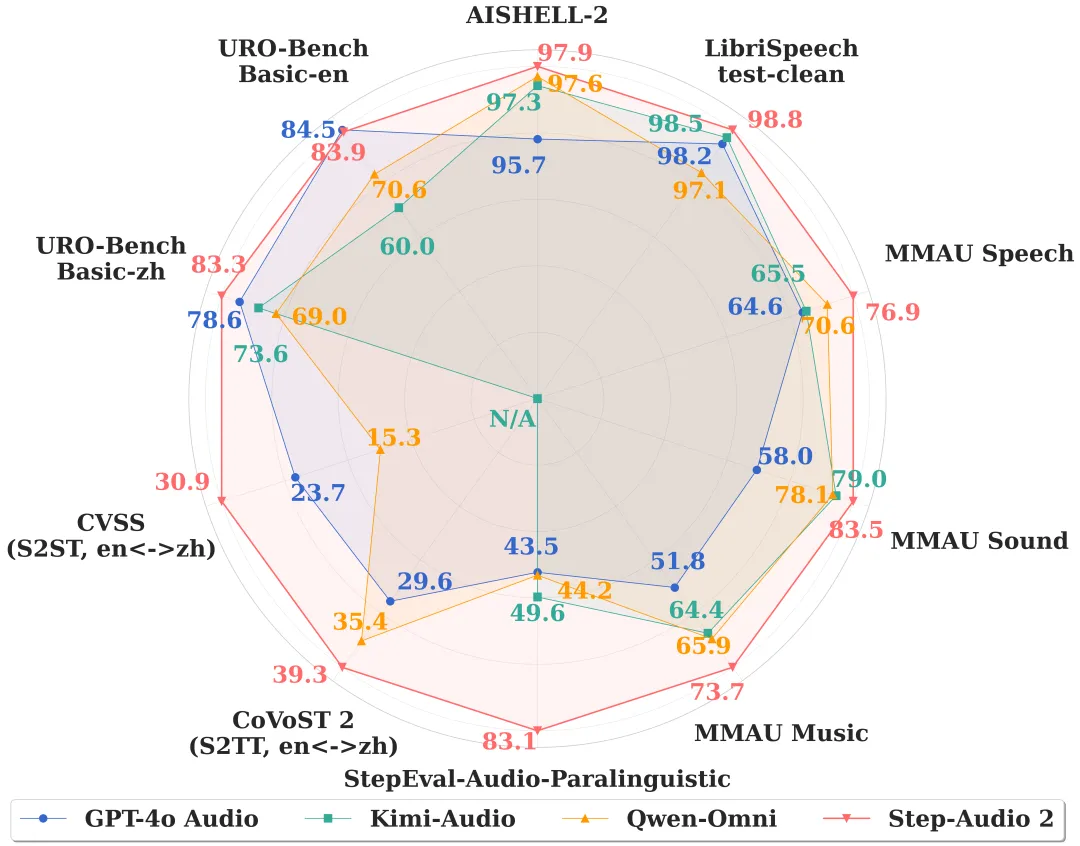 图:Step-Audio 2 在多项音频理解基准上的表现(雷达图越靠外越强),来源:GitHub stepfun-ai/Step-Audio2
图:Step-Audio 2 在多项音频理解基准上的表现(雷达图越靠外越强),来源:GitHub stepfun-ai/Step-Audio2
主观评测:80.41 vs GPT 68.01(+18%)
这是五个维度里最值钱的一个——因为它是真人用手机 APP 真实对话后打的分,最能反映实际用户体验。
| 80.41 | |
80.41 什么意思?大概就是"聊着聊着忘了对面是个 AI"的水平。GPT 和 Gemini 的 67-68 分大概属于"知道它不是真人,但能聊下去"的水平。
差距 12 分,在主观评测里是非常显著的领先。
副语言理解:82.18 vs 豆包 16.09
这是整份报告里最让人意外的一组数据。
所谓"副语言",就是话里话外那些不是字面意思的信息——语调、语速、停顿、叹气、轻笑、哽咽、撒娇、不耐烦。
 图:StepAudio 2.5 能精准捕捉对话中的语调、情绪和言外之意
图:StepAudio 2.5 能精准捕捉对话中的语调、情绪和言外之意
| 82.18 | |
| 16.09 |
⚡ 豆包 16.09 暴露了一个关键事实
**听起来自然 ≠ 真正听懂了**。豆包的"好听"来自 TTS 层的表现力,但深层语义理解——用户是在撒娇还是在抱怨、"好"是真心还是敷衍——差距是指数级的。
换句话说:豆包是个好"捧哏",但不是个好"知音"。
语音问答:79.80 vs GPT 53.20(+50%)
语音问答测试的不是"聊天",而是听懂一段音频,然后回答关于这段音频的问题——涉及的 11 种任务包括音色识别、场景判断、情绪推理、内容摘要等。
GPT 在这个维度只有 53.20,比 StepAudio 低了 50%。这说明 GPT 的语音能力目前更偏向"转录+文本推理"的 pipeline 模式,而非端到端的音频理解。遇到需要从声音本身(而非文字内容)推断信息的任务,差距就很明显。
通用对话和车载场景:领先但非碾压
为了在手机上看得清,把原来挤在一起的五列大表拆成两张:
通用对话(客观评测)
| 86.36 | |
车载场景(客观评测)
| 84.80 | |
这两个维度 StepAudio 确实领先,但差距在 4-6 分之间,属于"好一点"而非"碾压级"。车载场景尤其值得关注——涉及导航、车控、信息查询等任务型对话,StepAudio 依然保持第一,说明它在"干活"层面也不虚。
三、说完性能,聊聊钱
语音 AI 的商业化,性能是一半,成本是另一半。我们把四家定价拉出来:
| 10 | 70 | ||
几个关键信息:
如果你是一个要做语音 AI 产品的团队,成本排序大概是 StepAudio ≈ Gemini < 豆包 < GPT-Realtime。在中文场景下,StepAudio 的综合性价比目前没有直接对手。
四、三个"但是"——评测数据不会告诉你的事
评测报告看完,让人兴奋。但真正要做判断,下面三个"但是"必须写清楚。
但是一:这是官方自测,不是第三方独立评测
5 个维度的测试由阶跃星辰自行设计、自行执行、自行报告。这在行业里是常见操作(OpenAI、Google 的模型卡也是自测),但自测数据永远应该带着"信任但需验证"的态度来看。
尤其是主观评测——通过手机 APP 对话打分——StepAudio 的原生 APP 体验可能给自家产品带来了额外的体验加成,而竞品通过 API 接入的体验可能打了折扣。
但是二:对比的 GPT-Realtime-1.5 不是最新版
OpenAI 在 2026 年 5 月初发布了 GPT-Realtime-2,具备 GPT-5 级别的推理能力。而这次 benchmark 测试的是 GPT-Realtime-1.5。
"我用新款打你旧款赢了",这在传播上很有效,但在技术评估上需要打一个折扣。GPT-Realtime-2 的真实水平如何,目前缺少可比的评测数据。
但是三:豆包案例告诉我们,用户感知 ≠ 技术能力
豆包主观评分 70.70(第二),但副语言理解只有 16.09(垫底)。这个分裂的数据揭示了一个重要的产品逻辑:
对大多数 C 端用户来说,"好听"比"听懂"更重要。
一个音色甜美、语气自然、会说"好的呢~"的 AI,用户就是会觉得体验不错——哪怕它其实没搞懂你刚才那句话是要安慰还是开玩笑。
这对 StepAudio 有一个隐含挑战:如果"副语言顶级理解"这种深度能力不能直接转化为用户可感知的体验差异,那这个技术优势的商业转化率是存疑的。
五、如果你现在要接入语音 AI,怎么选?
没有完美的模型,只有适合你场景的模型。
💡 场景化选型指南
- **中文为主 + 情感陪伴/角色扮演/面试训练** → 闭眼选 StepAudio 2.5。性能和成本都是最优解。 - **多语言支持 + 全球部署** → 选 GPT-Realtime-2。贵,但覆盖面广,全球延迟可控。 - **原型验证,预算有限** → 选 Gemini 2.5 Pro Live。定价最低,但注意 15 分钟会话限制。 - **已在字节/火山引擎生态** → 豆包可以用,但别用在需要"深度共情"的场景。闲聊和客服没问题,面试模拟和心理咨询类产品要慎重。
六、语音 AI 的赛点不在"说话"
StepAudio 2.5 这个产品最重要的信号,不是它拿了五个第一,而是它证明了中国 AI 公司在语音这个垂直赛道上,有能力做出全球领先水平的产品。
但语音 AI 的下半场,比的不是谁说话更像人——那是入场券。
真正的赛点是:谁能把"听懂"和"做对事"连起来。
阶跃官方在 Model Card 里写了一段话,我觉得很诚实:"一个真正完整的 Agent,其人情味与行动力必然是有机统一的整体。"他们自己也承认这一版只是"让角色初步有了形态"。
如果你是个开发者,我建议你去试试它的 API(platform.stepfun.com),30 分钟就能跑通,体验一下"活人感"到底是不是真的。如果你想先看别人测,网上已经有几篇第三方的初评可以参考。
如果你是一个普通用户——直接去 stepfun.com/studio/audio 体验,选个预设人设聊几句。AI 语音发展到这个程度,不亲自试一下,很难理解"活人感"到底是什么感觉。
数据来源:StepAudio 2.5 Realtime Model Card、阶跃星辰开放平台 API 文档、ai-bot.cn 产品评测、AI Market Watch 行业分析、GitHub stepfun-ai/Step-Audio2 技术报告、火山引擎豆包语音计费文档
