 夜雨聆风
夜雨聆风
5月20号前后,中美两大厂前后脚扔出新模型。
阿里在阿里云峰会把Qwen 3.7-Max拍桌上,Google I/O把Gemini 3.5 Flash捧上主舞台。按理说这俩该各自霸占头条,结果舆情完全不对等——Qwen这边是"卧槽真猛",Gemini那边却是"就这?"
反差有点大,咱们分头说一说。
Qwen 3.7-Max:新官上任首秀
自林俊旸离职后,关键接棒人之一就是谷歌来的周浩(参考Qwen团队地震,一些流传的消息)。千问新班子备受关注。
qwen3.6虽然是离职事件发生后发布,却与林难以分割。从某种意义上来说,qwen3.7算是新班子的首秀。
战绩还是可以的。
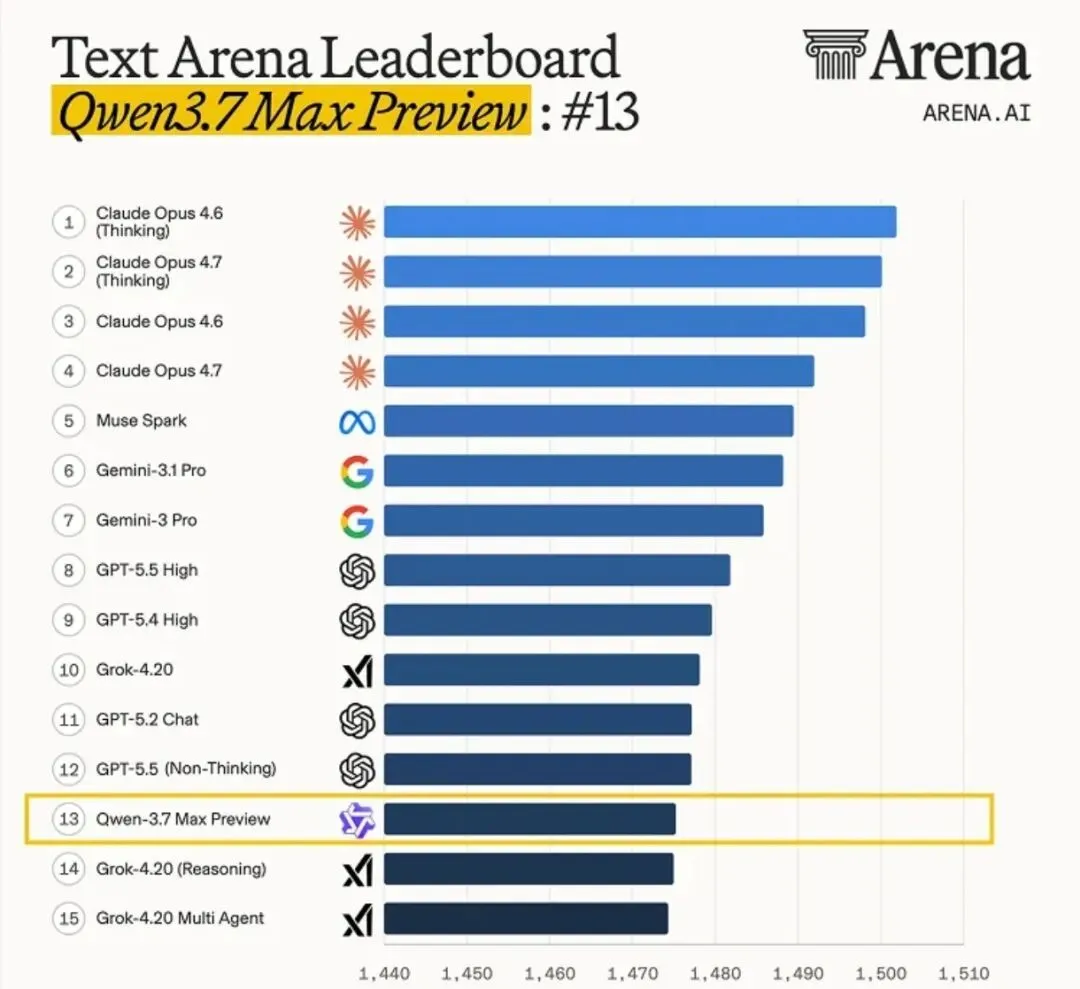
Qwen 3.7-Max-Preview上线之后,Arena AI盲测里直接杀到国产第一。
各种实测都指向它比较能打。本脑自己测的感受是,数学能力有明显提升,前端编码可靠了不少。
值得一提的是"35小时自主进化"的案例。在一个完全没接触过的芯片平台上,Qwen 3.7-Max从零开始,没文档没示例,自己写内核、编译、测性能、迭代优化,干了35小时,1158次工具调用,432次内核评估,最后把推理速度干上去10倍。
这是真的能干活了。
新班子的痕迹:思考过程"吞"了,一股谷歌味儿
有一个细节大家容易忽略:思考方式。
以前Qwen思考,会把完整的思维链摊开来给你看,模型怎么纠结、怎么自查,全透明。这次3.7-Max-Preview变了,只给你看一个"思维链总结",真实推理过程藏起来了。
而且长的跟Gemini非常像。
今年3月,Qwen原后训练负责人郁博文离职,接手的叫周浩,前DeepMind高级资深研究员,直接参与过Gemini系列的工作。
这事逻辑线条非常明确。如果能追上谷歌,这波人士震动阿里的决策能算的上成功?拭目以待吧。
Gemini 3.5 Flash:谷歌的"快",成了最大的遮羞布
说到谷歌,最近模型届无大事,谷歌这个3.5版本就颇受瞩目。

Gemini 3.5 Flash在I/O大会上占尽了C位,主舞台、默认模型、核心产品全接入。谷歌给的叙事很完美:速度是竞品的4倍,Agent能力碾压自家上一代旗舰3.1 Pro,价格还便宜。
但发布会一结束,社区情绪直接分叉。
Reddit和Linux.do上,早期用户分成两派。一派承认"快得离谱",另一派直接开喷:"快是快,但不够聪明。"有人算了一笔账:"3.5 Flash唯一的强处就是快,也就是能够更快地消耗token,完成同样任务反而比3.1 Pro还贵,真绝了。"
更扎心的是实测。Linux.do社区对比发现,复杂人文讨论里,3.5 Flash即便开最高思考模式,深度和细腻度明显不如上一代3.1 Pro,被评价为"过于机械和生硬"。

Benchmark也藏不住尴尬。在HLE(极高难度学术推理)测试里,3.5 Flash只拿了40.2%,不仅全场垫底,还比自家上一代3.0 Flash的43.5%更低——代际更新反而退步,这在AI圈相当罕见。
想当初Gemini 3.1 Pro出来那会儿,网上一片"谷歌终于睡醒了"的欢呼。这次3.5 ,甚至有人直呼美版豆包,言外之意几乎溢出屏幕。
一句话总结
模型马拉松的后半场,大厂着实吃力了。可能是带着包袱赛跑的缘故。
不过作为持票者,本脑说句公道话,还是很看好两位的,加油。
关注我(公众号『正电子脑』),获取更多ai洞察。

