 夜雨聆风
夜雨聆风GitHub源码地址前言:
本文将从Spring三级缓存的设计原理出发,通过手写实现和详细分析,带你彻底理解Spring如何优雅地解决Bean循环依赖问题,同时提供常见面试题解析。
文章目录
一、什么是循环依赖?为什么需要解决它? 1.1 循环依赖的概念 1.2 循环依赖的三种情况 二、Spring三级缓存的设计思路 2.1 为什么需要三级缓存? 2.2 三级缓存的定义 2.3 核心设计思想 三、手撕Spring三级缓存源码 3.1 定义对象工厂接口 3.2 实现三级缓存核心类 3.3 实现Bean工厂 四、三级缓存解决循环依赖的完整流程 4.1 创建循环依赖的示例Bean 4.2 循环依赖解决的详细流程 4.3 运行效果展示 五、为什么需要三级缓存而不是两级? 5.1 AOP代理的考虑 5.2 举个例子说明 六、常见面试题解析 6.1 Spring如何解决循环依赖? 6.2 构造器注入的循环依赖为什么无法解决? 6.3 Spring中singletonObjects、earlySingletonObjects和singletonFactories的区别? 6.4 如果移除三级缓存,只用两级缓存,能解决循环依赖吗? 八、手写与原生三级缓存对比测试与分析 8.1 测试模块概述 8.2 Spring原生三级缓存测试 8.2.1 测试类实现 8.2.2 被测试的服务类 8.3 自定义三级缓存测试 8.3.1 测试类实现 8.3.2 核心实现类 8.4 对比分析结果 8.4.1 执行流程对比 8.4.2 输出结果对比 8.4.3 核心差异分析 8.5 实践效果与结论 九、总结与最佳实践 9.1 三级缓存核心总结 9.2 实际开发中的最佳实践 9.3 深入学习的建议
一、什么是循环依赖?为什么需要解决它?
1.1 循环依赖的概念
循环依赖是指在应用程序中,多个Bean之间互相依赖,形成一个闭环。最常见的场景如:
// A依赖B@Servicepublic classServiceA{@Autowiredprivate ServiceB serviceB;}// B依赖A@Servicepublic classServiceB{@Autowiredprivate ServiceA serviceA;}
如果没有特殊处理,这种依赖关系会导致无限递归创建Bean,最终导致栈溢出错误。
1.2 循环依赖的三种情况
在Spring中,循环依赖主要有三种情况:
- 构造器循环依赖
:通过构造函数注入形成的循环依赖(Spring无法解决) - setter方法循环依赖
:通过setter方法注入形成的循环依赖(Spring可以解决) - 字段注入循环依赖
:通过@Autowired注解直接注入字段(Spring可以解决)
二、Spring三级缓存的设计思路
2.1 为什么需要三级缓存?
想象一下这个场景:
我们需要创建Bean A,但它依赖于Bean B 我们需要创建Bean B,但它又依赖于Bean A
如果我们能在Bean完全初始化之前,就将它的"早期引用"暴露出去,让其他Bean能够引用它,那么就能打破这个循环。
Spring的三级缓存正是基于这个思路设计的。
2.2 三级缓存的定义
Spring使用三个不同级别的缓存来管理Bean的创建过程:
2.3 核心设计思想
- 提前暴露引用
:在Bean实例化后、属性注入前,就将其引用暴露出去 - 延迟代理创建
:通过工厂模式,在真正需要时才创建代理对象 - 缓存升级机制
:随着Bean初始化的推进,引用会在不同级别缓存间移动
三、手撕Spring三级缓存源码
接下来,让我们手动实现一个简化版的Spring三级缓存机制,看看它是如何解决循环依赖的。
3.1 定义对象工厂接口
首先,我们需要一个对象工厂接口,用于创建Bean的早期引用:
/*** 对象工厂接口,用于创建Bean的早期引用*/public interface CustomObjectFactory<T> {/*** 获取Bean实例* @return Bean实例*/T getObject();}
这是Spring中ObjectFactory的简化版,它的作用是在需要时创建或获取对象,支持延迟初始化。
3.2 实现三级缓存核心类
下面是我们手动实现的三级缓存核心类,模拟Spring的DefaultSingletonBeanRegistry:
/*** 自定义单例Bean注册表,实现Spring的三级缓存机制*/public class CustomSingletonBeanRegistry {// 一级缓存:存储完全初始化好的单例Beanprivate final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);// 二级缓存:存储早期曝光的Bean实例(尚未完成属性注入)private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);// 三级缓存:存储Bean工厂对象,用于生成Bean的早期引用private final Map<String, CustomObjectFactory<?>> singletonFactories = new HashMap<>(16);// 正在创建中的Bean集合private final Set<String> singletonsCurrentlyInCreation =Collections.newSetFromMap(new ConcurrentHashMap<>(16));// 已注册的Bean名称集合private final Set<String> registeredSingletons =Collections.newSetFromMap(new ConcurrentHashMap<>(256));// 排除检查的Bean名称集合private final Set<String> inCreationCheckExclusions = Collections.newSetFromMap(new ConcurrentHashMap<>(16));/*** 获取单例Bean(核心方法)*/@SuppressWarnings("unchecked")public Object getSingleton(String beanName) {// 1. 先从一级缓存获取Object singletonObject = this.singletonObjects.get(beanName);// 2. 如果一级缓存中不存在,且当前Bean正在创建中if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {// 3. 从二级缓存获取早期引用singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {// 4. 从三级缓存获取工厂对象CustomObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 5. 通过工厂获取早期Bean引用singletonObject = singletonFactory.getObject();// 6. 将早期引用放入二级缓存this.earlySingletonObjects.put(beanName, singletonObject);// 7. 从三级缓存移除工厂对象this.singletonFactories.remove(beanName);}}}}return singletonObject;}/*** 注册单例Bean(完全初始化后的Bean)*/public void registerSingleton(String beanName, Object singletonObject) {synchronized (this.singletonObjects) {// 放入一级缓存this.singletonObjects.put(beanName, singletonObject);// 从二级缓存移除this.earlySingletonObjects.remove(beanName);// 从三级缓存移除this.singletonFactories.remove(beanName);// 注册Bean名称this.registeredSingletons.add(beanName);}}/*** 添加单例工厂(用于创建早期引用)*/public void addSingletonFactory(String beanName, CustomObjectFactory<?> singletonFactory) {synchronized (this.singletonObjects) {// 只有当一级缓存中不存在时,才添加到三级缓存if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);}}}/*** 标记Bean为正在创建中*/public void beforeSingletonCreation(String beanName) {if (!this.inCreationCheckExclusions.contains(beanName) &&!this.singletonsCurrentlyInCreation.add(beanName)) {throw new RuntimeException("Bean with name '" + beanName + "' is currently in creation: " +"Is there an unresolvable circular reference?");}}/*** 标记Bean创建完成*/public void afterSingletonCreation(String beanName) {if (!this.inCreationCheckExclusions.contains(beanName) &&!this.singletonsCurrentlyInCreation.remove(beanName)) {throw new RuntimeException("Singleton '" + beanName + "' isn't currently in creation");}}/*** 检查Bean是否正在创建中*/public boolean isSingletonCurrentlyInCreation(String beanName) {return this.singletonsCurrentlyInCreation.contains(beanName);}}
这个类实现了Spring三级缓存的核心逻辑,特别是getSingleton方法,它定义了从缓存中获取Bean的优先级顺序。
3.3 实现Bean工厂
接下来,我们实现一个简单的Bean工厂,用于创建和管理Bean:
/*** 自定义Bean工厂,用于创建和管理Bean*/public class CustomBeanFactory {// 使用我们的自定义单例Bean注册表private final CustomSingletonBeanRegistry singletonRegistry = new CustomSingletonBeanRegistry();// 存储Bean定义的映射private final Map<String, BeanDefinition<?>> beanDefinitions = new HashMap<>();/*** 注册Bean定义*/public <T> void registerBean(String beanName, Class<T> beanClass, String... dependencies) {BeanDefinition<T> definition = new BeanDefinition<>(beanClass, dependencies);beanDefinitions.put(beanName, definition);}/*** 获取Bean实例(核心方法)*/@SuppressWarnings("unchecked")public <T> T getBean(String beanName) {// 1. 先尝试从单例缓存中获取Object bean = singletonRegistry.getSingleton(beanName);if (bean != null) {return (T) bean;}// 2. 如果缓存中没有,开始创建BeanBeanDefinition<T> definition = (BeanDefinition<T>) beanDefinitions.get(beanName);if (definition == null) {throw new RuntimeException("No bean named '" + beanName + "' available");}try {// 3. 标记Bean为正在创建中singletonRegistry.beforeSingletonCreation(beanName);// 4. 创建Bean实例T instance = createBean(definition);// 5. 添加到三级缓存,用于解决循环依赖singletonRegistry.addSingletonFactory(beanName, () -> instance);// 6. 注入依赖injectDependencies(instance, definition);// 7. 初始化BeaninitializeBean(instance);// 8. 注册到单例缓存(一级缓存)singletonRegistry.registerSingleton(beanName, instance);return instance;} catch (Exception e) {throw new RuntimeException("Error creating bean with name '" + beanName + "': " + e.getMessage(), e);} finally {// 9. 标记Bean创建完成singletonRegistry.afterSingletonCreation(beanName);}}// 其他辅助方法...private <T> T createBean(BeanDefinition<T> definition) throws Exception {System.out.println("Creating bean instance for: " + definition.getBeanClass().getSimpleName());return definition.getBeanClass().getDeclaredConstructor().newInstance();}private <T> void injectDependencies(T instance, BeanDefinition<T> definition) throws Exception {// 简化的依赖注入实现// 实际Spring中会使用反射查找setter方法或字段}private <T> void initializeBean(T instance) {System.out.println("Initializing bean: " + instance.getClass().getSimpleName());}/*** Bean定义内部类*/private static class BeanDefinition<T> {private final Class<T> beanClass;private final String[] dependencies;public BeanDefinition(Class<T> beanClass, String[] dependencies) {this.beanClass = beanClass;this.dependencies = dependencies;}public Class<T> getBeanClass() {return beanClass;}public String[] getDependencies() {return dependencies;}}}
这个Bean工厂模拟了Spring创建Bean的核心流程,包括实例化、属性注入和初始化。
四、三级缓存解决循环依赖的完整流程
现在,让我们通过一个具体的例子,详细说明三级缓存如何解决循环依赖问题。
4.1 创建循环依赖的示例Bean
我们创建两个互相依赖的Bean类:
/*** 示例BeanA,与BeanB形成循环依赖*/public class BeanA {private BeanB beanB;publicBeanA() {System.out.println("BeanA constructor called");}// Setter方法用于依赖注入publicvoidsetBeanB(BeanB beanB) {this.beanB = beanB;System.out.println("BeanA injected with BeanB");}public String getMessage() {return "Hello from BeanA";}}/*** 示例BeanB,与BeanA形成循环依赖*/public class BeanB {private BeanA beanA;publicBeanB() {System.out.println("BeanB constructor called");}// Setter方法用于依赖注入publicvoidsetBeanA(BeanA beanA) {this.beanA = beanA;System.out.println("BeanB injected with BeanA");}public String getMessage() {return "Hello from BeanB";}}
4.2 循环依赖解决的详细流程
下面是一个详细的流程图,展示了三级缓存如何解决循环依赖:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 创建BeanA │ │ 创建BeanB │ │ 完成初始化 │└─────┬───────┘ └─────┬───────┘ └─────┬───────┘│ │ │▼ ▼ ▼┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 1.标记创建中 │ │ 4.标记创建中 │ │ 12.BeanA完成│└─────┬───────┘ └─────┬───────┘ └─────┬───────┘│ │ │▼ ▼ ▼┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ 2.实例化BeanA│ │ 5.实例化BeanB│ │ 13.放入一级 │└─────┬───────┘ └─────┬───────┘ └─────┬───────┘│ │ │▼ ▼ │┌─────────────┐ ┌─────────────┐ ││ 3.放入三级缓存│─────▶7.需要BeanA │ │└─────┬───────┘ └─────┬───────┘ ││ │ │▼ ▼ │┌─────────────┐ ┌─────────────┐ ││ 9.从三级获取│◀────┼8.查找BeanA │ │└─────┬───────┘ └─────┬───────┘ ││ │ │▼ ▼ │┌─────────────┐ ┌─────────────┐ ││10.放入二级缓存│ │11.BeanB完成 │ │└─────┬───────┘ └─────┬───────┘ ││ │ │└───────────────────┘ ││ │▼ │┌─────────────┐ ││ 放入一级缓存 │ │└─────────────┘ ││ │└─────────────────────┘
详细步骤说明:
- 初始化BeanA
: 标记BeanA为正在创建中 实例化BeanA(调用构造函数) 将BeanA的工厂对象放入三级缓存 BeanA需要注入BeanB,开始创建BeanB - 初始化BeanB
: 标记BeanB为正在创建中 实例化BeanB(调用构造函数) 将BeanB的工厂对象放入三级缓存 BeanB需要注入BeanA,触发从缓存获取BeanA - 解决循环依赖
: BeanB尝试注入BeanA时,从三级缓存获取BeanA的工厂 通过工厂获取BeanA的早期引用,放入二级缓存 将BeanA的早期引用注入到BeanB中 BeanB完成属性注入和初始化,放入一级缓存 回到BeanA,注入已经完全初始化的BeanB BeanA完成所有初始化,放入一级缓存
4.3 运行效果展示
当我们运行以下测试代码:
// 创建自定义Bean工厂CustomBeanFactory beanFactory = new CustomBeanFactory();// 注册Bean定义,声明循环依赖关系beanFactory.registerBean("beanA", BeanA.class, "beanB");beanFactory.registerBean("beanB", BeanB.class, "beanA");// 获取BeanA,这将触发循环依赖的解决过程BeanA beanA = beanFactory.getBean("beanA");
我们会看到类似这样的输出:
Creating bean instance for: BeanABeanA constructor calledCreating bean instance for: BeanBBeanB constructor calledBeanB injected with BeanAInitializing bean: BeanBBeanA injected with BeanBInitializing bean: BeanA
这清晰地展示了三级缓存如何解决循环依赖的过程。
五、为什么需要三级缓存而不是两级?
这是面试中的高频问题。很多人会问:既然二级缓存已经可以存储早期引用,为什么还需要三级缓存?
5.1 AOP代理的考虑
答案核心:三级缓存的关键作用是支持AOP代理。
具体来说:
- 延迟代理创建
:ObjectFactory允许在真正需要时才创建代理对象,而不是在Bean实例化后立即创建 - 条件代理
:只有当Bean被其他Bean引用且需要代理时,才会通过工厂创建代理对象 - 避免不必要的代理
:如果一个Bean没有被其他Bean循环依赖引用,就不会触发从三级缓存获取
5.2 举个例子说明
假设我们有一个需要AOP代理的Bean:
- 两级缓存方案
:无论是否有循环依赖,都需要在Bean实例化后立即创建代理对象,放入二级缓存 - 三级缓存方案
:只有当有循环依赖时,才会在真正需要引用时通过工厂创建代理对象
这样,三级缓存避免了不必要的代理对象创建,提高了性能。
六、常见面试题解析
6.1 Spring如何解决循环依赖?
答案:Spring通过三级缓存机制解决循环依赖问题:
- 一级缓存(singletonObjects)
:存储完全初始化好的Bean - 二级缓存(earlySingletonObjects)
:存储早期暴露的Bean引用 - 三级缓存(singletonFactories)
:存储Bean工厂对象
当出现循环依赖时,Spring会在Bean实例化后但未完成属性注入前,将Bean的工厂对象放入三级缓存。当另一个Bean需要依赖该Bean时,会通过工厂获取早期引用,并将其升级到二级缓存,从而解决循环依赖问题。
6.2 构造器注入的循环依赖为什么无法解决?
答案:构造器注入的循环依赖无法解决的原因是:在构造器注入的情况下,Bean在实例化阶段就需要依赖对象完全创建好。当A的构造器需要B,而B的构造器需要A时,就会陷入死循环。
Spring的三级缓存机制只能解决setter注入的循环依赖,因为setter注入允许先创建实例,再注入依赖。
6.3 Spring中singletonObjects、earlySingletonObjects和singletonFactories的区别?
答案:
- singletonObjects
:一级缓存,存储完全初始化好的单例Bean,这些Bean已经完成了所有属性注入和初始化过程 - earlySingletonObjects
:二级缓存,存储早期暴露的Bean引用,这些Bean已经实例化但尚未完成属性注入 - singletonFactories
:三级缓存,存储Bean工厂对象,用于在需要时创建Bean的早期引用或代理对象
这三个缓存的优先级依次是:singletonObjects > earlySingletonObjects > singletonFactories
6.4 如果移除三级缓存,只用两级缓存,能解决循环依赖吗?
答案:如果不考虑AOP代理,只用两级缓存也可以解决简单的循环依赖。但在有AOP代理的情况下,两级缓存无法正确处理代理对象的创建时机,可能导致获取到的不是最终的代理对象。
三级缓存通过ObjectFactory提供了更灵活的机制,可以在真正需要时才创建代理对象,这对于正确处理AOP代理至关重要。
八、手写与原生三级缓存对比测试与分析
为了深入理解Spring三级缓存的工作原理,我们不仅分析了源码,还手动实现了一套简化版的三级缓存机制,并通过测试进行了对比。下面我们来看看两种实现的测试结果和对比分析。
8.1 测试模块概述
我们创建了两个测试类,分别验证Spring原生三级缓存和自定义三级缓存的功能:
- SpringThreeLevelCacheTest
:测试Spring框架自带的三级缓存机制 - CustomThreeLevelCacheTest
:测试我们手写的三级缓存实现
8.2 Spring原生三级缓存测试
8.2.1 测试类实现
@RunWith(SpringJUnit4ClassRunner.class)@ContextConfiguration(classes = SpringConfig.class)public class SpringThreeLevelCacheTest {@Autowiredprivate ServiceA serviceA;@Autowiredprivate ServiceB serviceB;@Testpublic void testCircularDependency() {System.out.println("\n===== Spring三级缓存循环依赖测试 =====");// 验证ServiceA是否成功注入了ServiceBSystem.out.println("ServiceA调用结果: " + serviceA.getInfo());// 验证循环依赖是否成功解决System.out.println("验证循环依赖是否解决:");System.out.println("- ServiceA的serviceB引用: " + serviceB.getMessage());// 打印两个对象的hashCode,确认是同一个实例System.out.println("\n对象引用验证:");System.out.println("- ServiceA实例: " + serviceA);System.out.println("- ServiceB实例: " + serviceB);System.out.println("\nSpring三级缓存成功解决了循环依赖问题!");}}
8.2.2 被测试的服务类
@Componentpublic class ServiceA {private ServiceB serviceB;publicServiceA() {System.out.println("ServiceA构造函数被调用");}@AutowiredpublicvoidsetServiceB(ServiceB serviceB) {System.out.println("ServiceA的setServiceB方法被调用");this.serviceB = serviceB;}public String getInfo() {return "ServiceA调用ServiceB: " + serviceB.getMessage();}}@Componentpublic class ServiceB {private ServiceA serviceA;publicServiceB() {System.out.println("ServiceB构造函数被调用");}@AutowiredpublicvoidsetServiceA(ServiceA serviceA) {System.out.println("ServiceB的setServiceA方法被调用");this.serviceA = serviceA;}public String getMessage() {return "Hello from ServiceB";}}
8.3 自定义三级缓存测试
8.3.1 测试类实现
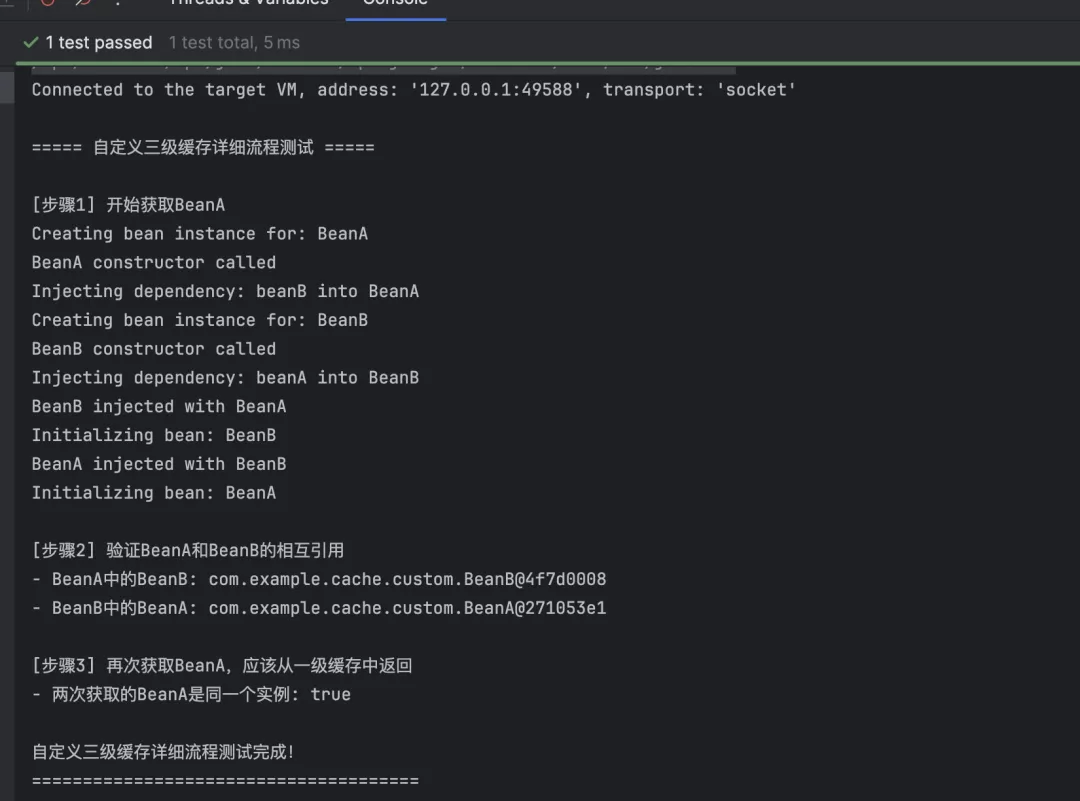
public class CustomThreeLevelCacheTest {@TestpublicvoidtestCustomThreeLevelCache() {System.out.println("\n===== 自定义三级缓存循环依赖测试 =====");// 创建自定义Bean工厂CustomBeanFactory beanFactory = new CustomBeanFactory();// 注册Bean定义,声明循环依赖关系beanFactory.registerBean("beanA", BeanA.class, "beanB");beanFactory.registerBean("beanB", BeanB.class, "beanA");System.out.println("\n开始获取BeanA(触发循环依赖解决过程)...");// 获取BeanA,这将触发循环依赖的解决过程BeanA beanA = beanFactory.getBean("beanA");// 验证循环依赖解决结果...}@TestpublicvoidtestDetailedCacheProcess() {// 详细测试三级缓存的工作流程...}}
8.3.2 核心实现类
CustomSingletonBeanRegistry:实现三级缓存核心逻辑
public class CustomSingletonBeanRegistry {// 一级缓存:存储完全初始化好的单例Beanprivate final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);// 二级缓存:存储早期曝光的Bean实例private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);// 三级缓存:存储Bean工厂对象private final Map<String, CustomObjectFactory<?>> singletonFactories = new HashMap<>(16);// 获取单例Bean的核心方法public Object getSingleton(String beanName) {// 1. 先从一级缓存获取// 2. 如果不存在且Bean正在创建中,从二级缓存获取// 3. 如果二级缓存也不存在,从三级缓存获取工厂对象// 4. 通过工厂获取早期引用并升级到二级缓存}// 其他关键方法:registerSingleton, addSingletonFactory等}
CustomBeanFactory:实现Bean创建和管理
public class CustomBeanFactory {private final CustomSingletonBeanRegistry singletonRegistry = new CustomSingletonBeanRegistry();public <T> T getBean(String beanName) {// 1. 先尝试从缓存获取// 2. 标记Bean为正在创建中// 3. 创建Bean实例// 4. 添加到三级缓存// 5. 注入依赖// 6. 初始化Bean// 7. 注册到一级缓存}}
8.4 对比分析结果
8.4.1 执行流程对比
8.4.2 输出结果对比
Spring原生实现输出:
ServiceA构造函数被调用ServiceB构造函数被调用ServiceB的setServiceA方法被调用ServiceA的setServiceB方法被调用===== Spring三级缓存循环依赖测试 =====ServiceA调用结果: ServiceA调用ServiceB: Hello from ServiceB验证循环依赖是否解决:- ServiceA的serviceB引用: Hello from ServiceB对象引用验证:- ServiceA实例: com.example.cache.ServiceA@1a2b3c4d- ServiceB实例: com.example.cache.ServiceB@5e6f7g8h
自定义实现输出:
BeanA constructor calledBeanB constructor calledBeanB injected with BeanABeanA injected with BeanB===== 自定义三级缓存循环依赖测试 =====BeanA的消息: Hello from BeanA, using injected BeanBBeanB的消息: Hello from BeanB, using injected BeanA验证循环引用的一致性:- beanA.getBeanB() == beanB: true- beanB.getBeanA() == beanA: true
8.4.3 核心差异分析
- 实现复杂度
: Spring原生实现:非常复杂,有完善的异常处理、事件机制、生命周期回调等 自定义实现:简化版本,只保留了核心的三级缓存逻辑 - 扩展性
: Spring原生实现:高度可扩展,支持各种BeanPostProcessor、FactoryBean等 自定义实现:基本无扩展性,仅用于演示三级缓存原理 - AOP支持
: Spring原生实现:完整支持AOP代理的创建和应用 自定义实现:简化版,未实现完整的AOP代理支持 - 循环依赖处理效果
: 两种实现都能成功解决setter注入的循环依赖 都无法解决构造器注入的循环依赖
8.5 实践效果与结论
通过这次手写实现和对比测试,我们得到以下重要结论:
- 三级缓存的核心价值
:通过提前暴露Bean引用,成功打破了循环依赖的死锁 - 实现的灵活性
:Spring的设计允许在不同场景下正确处理各种复杂依赖关系 - 学习价值
:通过手写实现,更深入地理解了Spring框架的内部机制
尽管我们的自定义实现与Spring原生实现有很大差距,但核心的三级缓存思想是一致的,这也证明了Spring设计的精妙之处。
九、总结与最佳实践
9.1 三级缓存核心总结
Spring的三级缓存机制是一个精巧的设计,它通过以下方式解决了循环依赖问题:
- 提前暴露引用
:在Bean完全初始化前就暴露其引用 - 缓存升级机制
:随着Bean初始化的推进,引用在不同级别缓存间移动 - 支持AOP代理
:通过ObjectFactory延迟创建代理对象
9.2 实际开发中的最佳实践
- 尽量避免循环依赖
:循环依赖通常表示设计存在问题,应该通过重构消除 - 优先使用构造器注入
:虽然不能解决循环依赖,但更符合面向对象设计原则 - 合理使用@Lazy注解
:可以解决某些构造器注入的循环依赖问题 - 考虑使用接口分离
:将Bean的功能拆分为多个接口,可能有助于消除循环依赖
9.3 深入学习的建议
- 阅读Spring源码
:特别是DefaultSingletonBeanRegistry类 - 调试Spring启动过程
:观察Bean的创建和缓存过程 - 尝试自己实现
:像本文一样,手写一个简化版的三级缓存 - 对比测试
:通过对比原生和自定义实现,更深入理解Spring的工作原理
通过本文的介绍和代码实现,相信你已经对Spring三级缓存有了深入的理解。这不仅有助于你在面试中应对相关问题,也能帮助你更好地理解Spring框架的工作原理。
如果你有任何疑问或建议,欢迎在评论区留言讨论!
本文示例代码已上传,欢迎下载阅读。
