当前时间: 2026-05-26 09:54:46
分类:办公文件
评论(0)
用 Codex 写论文,真正该安装什么插件?这两天我一直在折腾一件事,就是用 Codex 改论文。一开始的想法很简单。既然 Codex 能直接进入文件夹,能读取 Word、Markdown、图片、表格和代码文件,也能按照指令批量修改文件,那能不能把论文初稿、投稿模板、项目申请书、参考文献和期刊要求一起放进去,让它帮我把论文改成一个相对完整的投稿版本?Codex 确实很好用。它不是普通对话式 AI 那种你复制一段、它改一段的模式,而是可以直接在项目文件夹中工作。你把论文初稿、模板文章、参考资料、图片、表格、参考文献都放在一个文件夹里,它可以同时读取多个文件,理解文件之间的关系,并且直接生成新的文档、修改原文件、输出修改说明。对于论文写作来说,这一点非常重要,因为论文不是一段文字,而是一组材料之间的重新组织。说过白了,codex就是一个小龙虾。我是真的很兴奋,它极大提高了我的工作效率,所以这几天我都不怎么想睡觉,没日没夜地用codex。更方便的是,Codex 可以承担很多重复性工作。比如检查参考文献和正文引文是否一致,统一标题层级,压缩字数,整理图表编号,生成修改说明,检查是否遗漏基金项目,按照模板改写摘要和关键词。这些工作不难,但很耗时间。过去我们可能要一页一页查,现在可以交给 Codex 先做一轮。它最适合做繁琐、明确、可检查的工作,却不一定擅长做真正的学术判断。比如它可以帮你把一篇文章改得更像论文,但不一定能判断你的中心论点是否成立。它可以模仿期刊模板的结构,但不一定知道这个结构背后的学术逻辑。它可以把段落写得很长,但长不等于有深度。它可以重画图表,但图表是否真正解释了文章的机制,仍然需要作者自己判断。所以,Codex 写论文的关键不是让它“替我写”,而是让它“替我处理材料”。它不是导师,不是审稿人,也不是论文作者。它更像一个效率很高的科研助理,适合做初筛、整理、格式统一和机械修改。真正决定论文质量的,还是人的问题意识、理论判断、研究设计和学术表达能力。一、为什么Codex适合论文写作?
Codex 的好用之处,首先在于它可以直接处理文件。很多时候,我们写论文不是从零开始,而是面对一堆材料。比如一份论文初稿,一份项目申请书,一份已经录用的参考模板,一批政策文件,一组参考文献,还有期刊投稿要求。普通 AI 对话工具往往只能处理局部文本,而 Codex 更适合进入一个完整项目,把这些材料当成一个工作区来处理。第一类是格式性工作。比如统一标题格式,压缩字数,调整摘要,检查关键词,整理参考文献,调整图表编号,生成 Word 文档。这类工作要求细,但创造性不强,很适合交给 Codex。第二类是结构性工作。比如要求它先读初稿,再读模板,再判断两者差距,最后重新设计论文结构。它可以帮助我们发现文章哪里像工作总结,哪里像政策宣传,哪里缺少文献综述,哪里没有形成问题意识。第三类是材料性工作。比如让它根据项目申请书提取课题名称、编号、成员信息,再把这些内容放入论文基金项目标注中。又比如让它根据参考文献生成文献综述表,或者检查正文中引用过的文献是否都出现在参考文献列表中。但它也有一个问题,就是容易把“完成任务”误认为“完成论文”。你让它改论文,它确实会改。你让它扩写,它也确实会扩。可是很多时候,它扩出来的内容只是更完整的空话。原来一段话不够学术,它可能改成三段看似学术的表达,但里面仍然没有真正的研究问题。原来图表不够好,它可能换成更漂亮的图,但图和正文的关系仍然不紧密。原来 Findings 只有两部分,它可以扩成四部分,但四部分之间未必有内在逻辑。所以,Codex 的价值不是直接产生高水平论文,而是把低效率劳动交给机器,把高判断劳动留给人。二、写论文真正需要安装哪些插件?
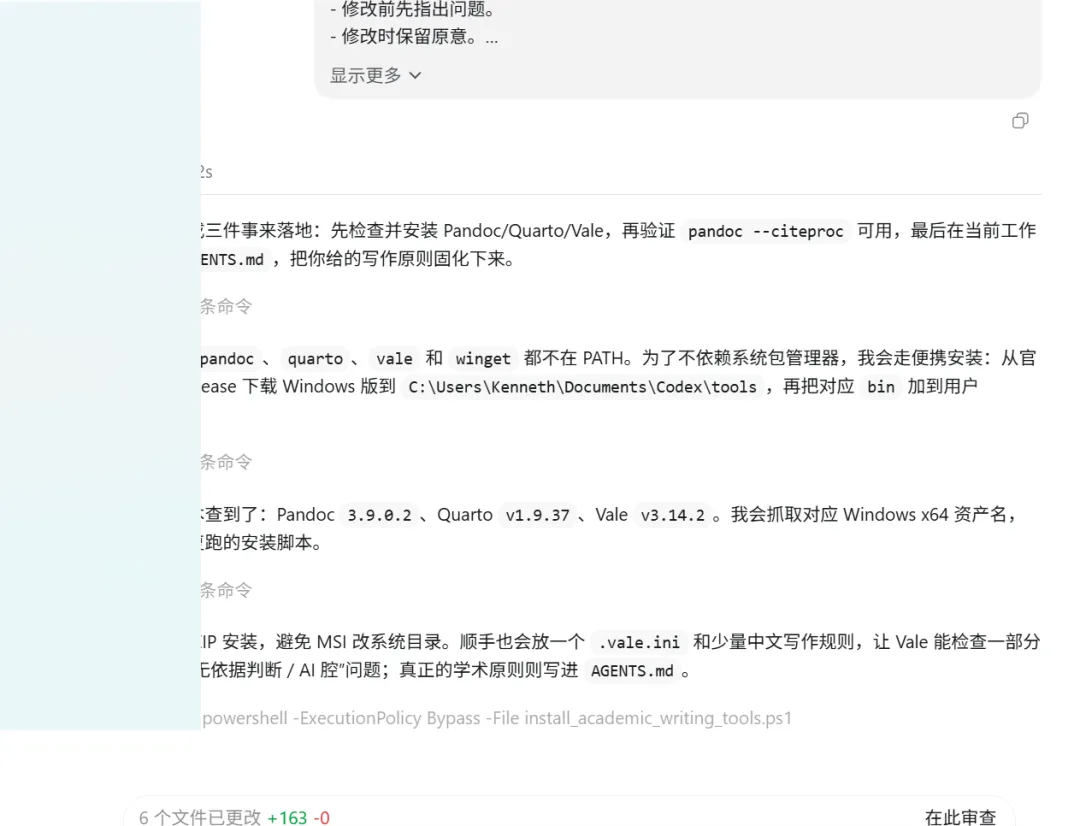
如果只是让 Codex 改一个 Word 文档,它当然可以做。但如果想让它在论文写作中发挥更大作用,就需要给它接入一些工具。论文写作最怕的不是语言不够漂亮,而是文献不真实、引用不准确、参考文献和正文对不上。Zotero是文献管理工具,如果能通过 MCP 或相关方式让 Codex 读取 Zotero 文献库,那么它就可以围绕真实文献进行整理。比如检索某个文件夹里的文献,提取每篇文章的研究对象、方法、结论和不足,再帮助你生成文献综述框架。这类工具的意义在于给 Codex 加上一道“文献边界”。没有文献库的时候,它可能会凭语言习惯写出看似合理的综述。有了 Zotero 以后,你可以明确要求它只能使用文献库里的文献,不能编造作者、年份、题名和 DOI。Better BibTeX 的作用主要是稳定生成 citation key。对于英文论文、LaTeX 写作、Markdown 写作和跨软件写作来说,这一点很重要。一个稳定的 citekey,可以避免同一篇文献在不同版本里出现不同引用标识。尤其是论文反复修改时,文献管理的稳定性比表面上的语言润色更重要。第三个工具,是 Semantic Scholar 相关 MCP。它适合做文献发现和研究脉络梳理。Zotero 更像自己的文献仓库,Semantic Scholar 更像外部学术地图。它可以帮助我们发现某个主题下有哪些代表文献,哪些文章被引用较多,哪些作者之间形成研究网络,哪些方向最近几年讨论得比较多。但是要注意,这类工具更适合“发现线索”,不适合直接“生成定论”。检索出来的文献仍然需要人工判断。尤其是中文论文,很多选题和材料并不完全依赖英文数据库,所以不能把 Semantic Scholar 当成唯一来源。如果你的方向涉及人工智能、计算机、工程、数学、物理、统计等领域,arXiv 会很有用。它可以帮助你追踪最新预印本,了解一个技术方向正在发生什么变化。但它也有明显限制。arXiv 上很多文章是预印本,不等于正式发表论文,也不一定经过同行评议。因此,写论文时可以用它了解前沿,但不能无条件把它当成权威结论。第五个工具,是 Google Drive 或本地文件插件。如果你的论文材料存在 Google Drive、Google Docs、Sheets 或 Slides 中,那么相关插件可以提高协同效率。比如项目申请书在 Google Docs,数据表在 Sheets,论文图在 Slides,Codex 读取这些材料后,就可以帮你统一整理。但如果你主要用本地 Word 和 WPS,其实本地文件夹工作流也够用。这两个工具不是传统意义上的论文插件,但非常适合学术写作。它们可以把 Markdown、BibTeX、CSL 样式和 Word、PDF 等格式连接起来。对于需要反复改格式、改引用、改版本的论文来说,这类工具可以减少大量重复劳动。第七个工具,是 LanguageTool 或 Vale。它们适合做语言检查。英文论文可以用 LanguageTool 检查拼写、语法和部分表达问题。Vale 更适合设定自己的写作规范,比如不使用某些模板化表达,不使用过度宣传性的词语,不使用某些不符合期刊风格的表达。中文论文虽然不能完全依赖这些工具,但也可以把它们当成辅助检查器。最后,还有一个比插件更重要的东西,叫 AGENTS.md。它不是普通插件,而是给 Codex 看的项目规则。你可以在论文文件夹里放一个 AGENTS.md,写清楚这个项目的写作规范。比如不得编造文献,不得新增无法核实的数据,所有引用必须和参考文献对应,段落不能只有一句话,不能使用明显 AI 腔,修改前必须先生成诊断报告。这样,每次 Codex 进入这个项目,它都会先读这些规则,再开始工作。真正会用 Codex 的人,不是每次都重新写一大段指令,而是把稳定规则沉淀到项目文件里。三、可以直接复制给Codex的安装和配置指令
如果你想让 Codex 帮你配置一个适合论文写作的环境,可以直接给它下面这段指令。请根据当前电脑环境,为我的论文写作项目配置 Codex 工作流。目标不是让 Codex 替我代写论文,而是让它成为文献整理、论文修改、格式统一和质量检查的科研助理。请先检查当前系统是否已经安装 Node.js、Python、Git、Zotero、Pandoc 和 Quarto。不要盲目安装重复软件。安装前先列出检查结果和建议方案。第一,配置 Zotero 相关 MCP 或可用的 Zotero 连接方式,使 Codex 能够读取我的 Zotero 文献库、文献条目、笔记、PDF 批注和 citation key。配置完成后,请生成一个测试任务,验证 Codex 是否能读取 Zotero 中指定文件夹的文献信息。注意,任何文献综述都必须基于真实文献,不得编造作者、年份、题名、期刊和 DOI。第二,检查 Zotero 是否安装 Better BibTeX。如果没有,请提示我手动安装,并说明它的作用是稳定生成 citation key,便于 Markdown、LaTeX、Word 和 BibTeX 工作流使用。请不要自行编造 citation key 规则,而是根据 Better BibTeX 的实际配置生成建议。第三,配置 Semantic Scholar 相关 MCP,用于文献发现、引用网络分析和研究主题扩展。请说明该工具只用于发现文献线索,不能直接替代人工阅读和文献真实性核查。第四,若我的研究方向涉及人工智能、计算机、工程、数学、统计或相关前沿技术,请配置arXiv 相关 MCP,用于检索和阅读预印本文献。请在配置说明中提醒我,arXiv 文献不等同于正式同行评议论文,引用时需要谨慎。第五,检查是否已经安装 Pandoc 或 Quarto。如果没有,请根据系统环境给出安装建议。配置目标是支持 Markdown、BibTeX、CSL、Word 和 PDF 之间的转换,方便论文格式统一和参考文献生成。第六,检查是否可以使用 LanguageTool 或 Vale 做语言检查。英文论文优先配置 LanguageTool,中文论文则重点通过 Codex 项目规则进行风格约束。请不要把语言检查等同于学术质量检查。第七,在当前论文项目根目录生成 AGENTS.md。该文件必须包含以下规则。不得编造文献。不得编造数据。不得编造项目名称、课题编号和成员信息。修改论文前必须先生成诊断报告。正文修改必须保持原研究主题,不得随意换题。参考文献必须和正文引文一一对应。图表必须与正文内容一致。不得把论文写成政策宣传稿、工作总结或 AI 式空话。每个主体段落一般不少于三句。涉及期刊投稿时,必须先读取投稿模板和期刊要求。setup_report.md,说明已经检查和配置了哪些工具。paper_workflow.md,说明以后我如何使用 Codex 完成文献综述、论文修改、参考文献核查、图表整理和投稿格式检查。AGENTS.md,作为当前论文项目的固定写作规范。如果某个工具无法安装或需要我手动授权,请不要跳过,也不要假装完成,而是在setup_report.md 中明确写出原因和下一步操作。这段指令的关键,是让 Codex 先检查,再安装,再输出说明。不要上来就让它安装一堆东西。论文写作环境最怕“工具很多,规则没有”。真正有用的配置,一定是服务于具体论文流程的。四、未来应该怎样用Codex写论文?
未来用 Codex 写论文,最重要的不是学会更多插件,而是重新理解人机协同。过去我们写论文,很多时间花在低价值环节。比如改格式,调编号,查参考文献,压缩字数,重排标题,整理表格。这些事情很重要,但不构成真正的学术创造。Codex 的价值,首先是把这些工作自动化,让作者从琐碎劳动中解放出来。选题为什么重要,问题从哪里来,文献之间的争论是什么,案例能够说明什么,方法是否支撑结论,图表有没有解释力,这些都不是插件能自动解决的。AI 可以生成一份看起来很完整的论文,但它不一定知道这篇论文为什么值得发表。它可以让文章更顺,但不能替你建立真正的问题意识。所以,比较合理的人机协同方式,是把论文写作分成四层。第一层是材料层。让 Codex 整理文件、读取模板、提取项目资料、检查参考文献、生成表格。这一层可以大胆交给机器,因为结果容易核查。第二层是结构层。让 Codex 提出结构方案、比较不同框架、指出逻辑断裂、合并重复部分。这一层可以让机器先做,但作者必须判断。第三层是表达层。让 Codex 改写摘要、优化段落、压缩字数、统一学术风格。这一层可以让机器辅助,但不能让机器完全决定文章语气。尤其是中文论文,最怕改成整齐但空洞的 AI 腔。第四层是思想层。研究问题、理论贡献、核心判断、结论边界,必须由作者负责。AI 可以讨论,可以质疑,可以提供备选表达,但不能替代作者的判断。用 Codex 写论文,真正成熟的方式不是问它“帮我写一篇论文”,而是给它非常具体的工作任务。比如:请把 Findings 从两部分扩展成三部分,但每部分必须回应研究问题。未来的论文写作能力,不只是会不会写文章,而是能不能把一个复杂写作任务拆解成可执行、可核查、可迭代的步骤。Codex 最擅长的,正是执行这些步骤。它可以同时处理文件,可以反复修改,可以输出报告,可以帮你做大量繁琐的版本管理。Codex 可以把论文从混乱改到整齐,但不能保证它从平庸变得深刻。它可以让文章更像论文,但不能保证文章真的有学术贡献。它可以降低写作成本,却不能替代研究本身。所以,用 Codex 写论文,最好的状态不是让人退场,而是让人回到真正重要的地方。人机协同的本质,不是把论文交给机器,而是让机器把我们从低水平重复劳动里释放出来,让我们有更多时间去想清楚:这篇文章到底想解决什么问题,又凭什么值得被发表。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-05-27 20:42:35 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/664356.html
- 运行时间 : 0.182632s [ 吞吐率:5.48req/s ] 内存消耗:4,717.64kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=8551618b8c9940ec730159795714716e
- CONNECT:[ UseTime:0.000936s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.001529s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000597s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000574s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001240s ]
- SELECT * FROM `set` [ RunTime:0.000444s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001488s ]
- SELECT * FROM `article` WHERE `id` = 664356 LIMIT 1 [ RunTime:0.001101s ]
- UPDATE `article` SET `lasttime` = 1779885755 WHERE `id` = 664356 [ RunTime:0.002185s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000530s ]
- SELECT * FROM `article` WHERE `id` < 664356 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000994s ]
- SELECT * FROM `article` WHERE `id` > 664356 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000921s ]
- SELECT * FROM `article` WHERE `id` < 664356 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.001687s ]
- SELECT * FROM `article` WHERE `id` < 664356 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.001741s ]
- SELECT * FROM `article` WHERE `id` < 664356 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.002112s ]

0.185975s

 夜雨聆风
夜雨聆风