夜雨聆风
夜雨聆风如需报告请联系客服或扫码获取更多报告

AI 技术突破驱动市场增长,商业化加速凸显投资价值
AI 技术实现关键突破,市场规模高速增长
全球人工智能技术已于 2025 年完成关键突破期的跨越式发展。语言基础模 型与推理模型实现双线并进,技术迭代速度与能力提升幅度均超出此前市场 预期。根据中国信通院数据,截至 2025 年 12 月,GPT-5.2、Gemini 3 Pro、 Grok-4、DeepSeek V3.2、Claude 4.5、Qwen3、Doubao-Seed-1.6、Kimi K2 Thinking、GLM4.5等头部语言大模型的综合能力较2024年底提升30%, 多模态理解能力提升幅度超过 50%,大模型基础能力实现了质的飞跃。
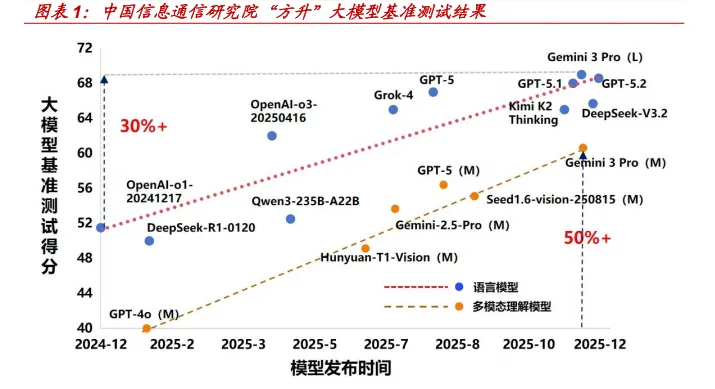
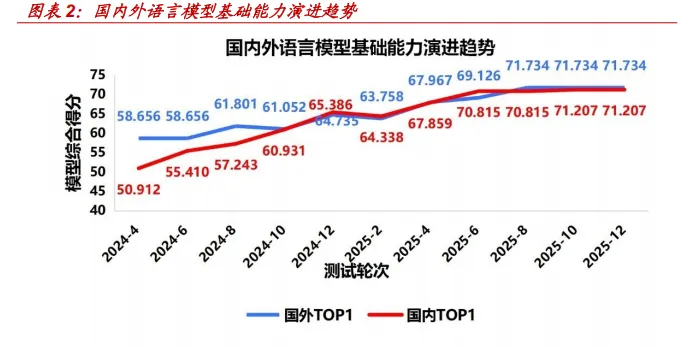
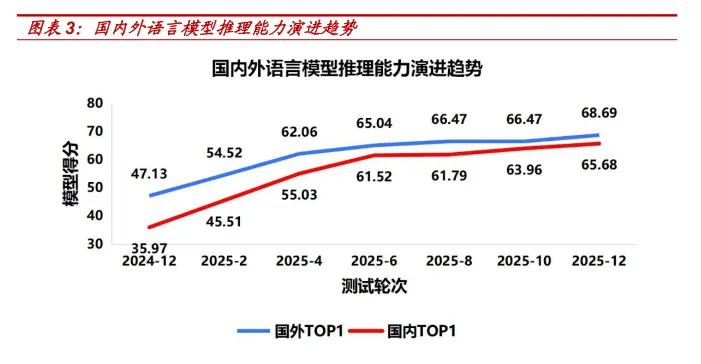
大模型评测体系的构建与模型训练的重要性已日趋等同。基准测试已深度 融入大模型 “建、用、管” 全生命周期,在指引学术研究、指导产品选型、 支撑行业应用、辅助监管治理、监测能力迭代等方面发挥关键作用。依托长 期、动态化的大模型基准测试,可搭建宏观决策的数据底座,实现产业政策 的精准制定与动态优化,例如精准量化国内外头部语言大模型在基础能力、 推理能力等维度的表现。从相关评测结果可见,国内头部语言大模型在基 础能力上已与国外水平不相上下,推理能力差距亦在持续收窄,成为推动 整体综合能力不断追赶的重要方向。
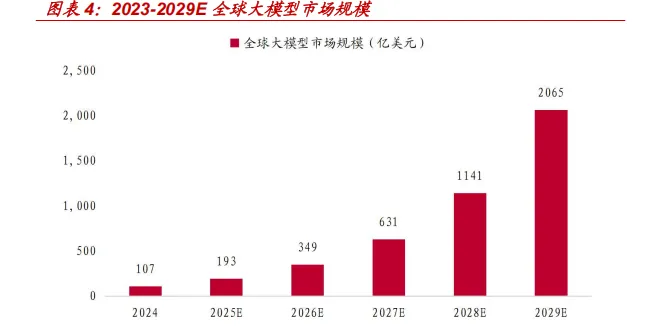
当前大模型技术仍处于快速迭代阶段。根据灼识咨询研究数据显示,伴随 技术成熟度提升与付费意愿持续释放,全球大模型市场规模预计将由 2024 年的 107 亿美元,快速增长至 2029 年的 2,065 亿美元,2024-2029 五年复 合增长率将达 80.7%。
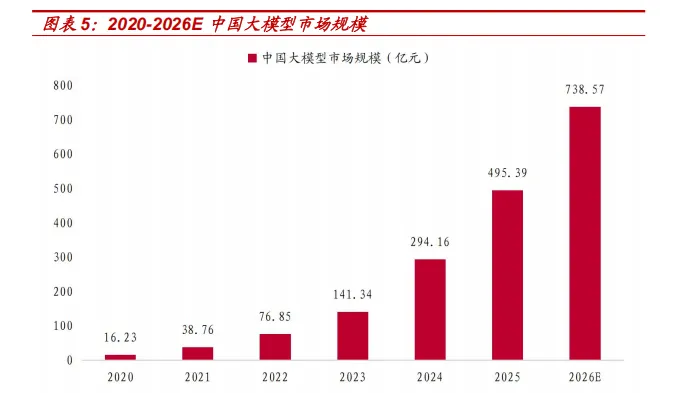
中国大模型市场大致可划分为三个阶段。2020 年至 2022 年为技术积累期, 以学术研究和头部企业探索为主,市场体量有限但基础能力逐步夯实,三年 累计增量不足 100 亿元。2023 年至 2024 年为爆发式增长期,技术突破与 资本热潮形成共振,市场进入跑马圈地阶段。2025 年起进入应用深化期, 虽然增速随基数扩大而自然回落,但应用场景持续拓宽,商业模式逐步清 晰。据艾媒咨询数据,2024 年中国大模型市场规模已达到人民币 294.16 亿元,预计到 2026 年将增至人民币 738.57 亿元,2024 年至 2026 年预计 复合年增长率为 58.5%。
2025 年多模态技术持续成熟,2026 年仍为主流发展趋势
回顾 2025 年,多模态大模型持续深化技术布局,理解与生成能力实现深度 融合,原生多模态架构逐步走向成熟。2025 上半年,OpenAI-o3 模型与 Gemini 2.5 Pro 模型率先实现视觉与语言信息的同步处理,支持图像关键细 节的自动调优,成功将语言大模型的深度思考能力迁移至多模态场景,赋予 其复杂视觉任务的高阶推理内核;同期,GPT-Image-1 与 Gemini 2.0 Flash 模型通过原生架构融合自回归与扩散模型,突破长上下文图像生成与编辑的 技术瓶颈,为多模态技术从实验室走向规模化商业应用筑牢了基础。下半年, 行业迭代节奏进一步加快,谷歌推出 Gemini-2.5-flash-image-preview (nano banana) 文生图模型,OpenAI 则发布 Sora 2 文生视频模型,双方 向均实现内容质量与场景适配性的显著提升,多模态生态的完整性与落地广 度持续拓展。
基于 2025 年的技术演进轨迹,我们预计多模态化仍将是 2026 年人工智能 领域的核心发展趋势。该趋势将围绕能力边界拓展与落地场景渗透两大维 度持续深化:一方面,头部模型将持续推进多模态能力的通用化,突破文 本、图像、视频、音频等单一模态的界限,实现跨模态信息的无缝转换与 深度联动,推动模型在复杂逻辑推理、多轮内容创作等场景的实用性跃升; 另一方面,原生多模态架构将进一步渗透至垂直领域,结合行业需求完成 轻量化适配,降低企业落地门槛,同时 AI 生成内容的版权合规机制、内容 安全管控体系将逐步完善,为多模态技术的规模化商用提供更具确定性的发 展环境。
大模型能力迭代,运行机制、架构与训练方法三维革新
传统 LLM 模型以文本为核心构建了强大的语言理解与生成能力,核心聚焦 自然语言处理,仅处理文本模态的理解与生成任务。能力范围包括文本分类、 问答、摘要、文本生成等纯语言。因此输入仅接受文本输入,输出也仅限于 文本形式。
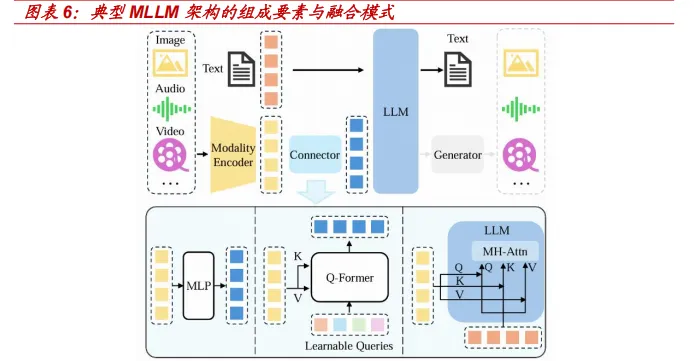
多模态大语言模型 MLLM:以 LLM 为基础骨干,通过扩展架构、引入多模 态编码/解码模块,实现跨模态(文本、图像、视频、音频等)的理解与生 成。不仅覆盖 LLM 的全部文本任务,还新增跨模态任务(如图像描述、文 本到图像生成、视频问答、多模态推理等)。支持文本与非文本模态的混合 输入(如 “描述这张图片并生成相似场景的视频”),输出可包含文本、图 像、视频等多种形式。
多模态大型语言模型的典型架构,核心是输入模态(含图像(Image)、文 本(Text)、音频(Audio)、视频(Video)等)先经模态编码器(ModalityEncoder)转成特征,再通过模态连接器(Connector)转换为大型语言模 型(LLM)可理解的格式:
投影型连接器(Projection-based Connector):把模态编码器输出的 特征(图中黄色块)输入 MLP,通过线性变换将其投影到大型语言模 型的词嵌入空间,最终转换成 LLM 能识别的 token 格式(蓝色块)。
查询型连接器(Query-based Connector):先通过“可学习查询向 量(Learnable Queries)”(图中彩色块)向模态特征(黄色块)发 起查询,借助 Q-Former 提取关键信息,最终压缩成少量核心 token(蓝 色块),再输入 LLM。
融合型连接器(Fusion-based Connector):直接在 LLM 的注意力 模块中,让文本 token(黄色块)和非文本特征(橙色块)在多头注意力层(MH-Attn)进行跨模态注意力交互(通过 Q/K/V 向量的传递), 实现特征层面的深度融合。
最后由 LLM 完成推理后输出文本,或通过模态生成器(Generator)生成 其他模态结果。
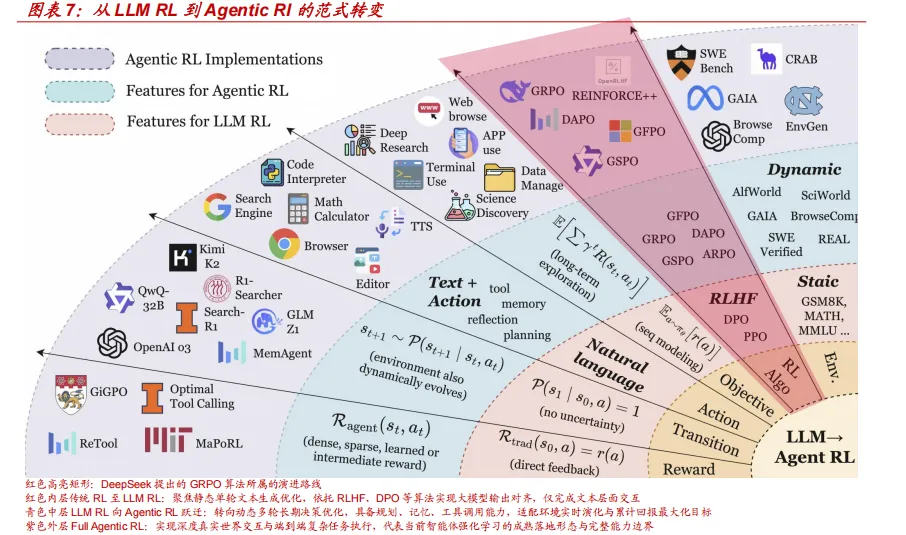
语言及多模态模型的能力跃迁,正驱动于运行机制、基础架构与训练方法的三维革新:
在运行机制层面,单纯依赖参数规模(Scaling)已难以实现能力的质变, 精细化的机制优化成为当前核心破局点。尽管月之暗的 KimiK2、阿里的 Qwen3-Max-Preview 等模型参数量已达万亿级别,但其能力突破仍未达到 OpenAI o1 级别的跃迁效应。反观技术演进方向,其一,路由机制(MoE, Mixture of Experts)成为效率核心引擎,如 GPT-5,MiniMax M 模型等通 过动态调度专家模块,实现了“思考”与“非思考”能力的智能切换,显著提升 推理与生成效率;其二,扩散语言模型(Diffusion-based LM)如 LLaDA、 Dream7B 等借助并行计算逻辑,突破了传统自回归模型的累积误差瓶颈, 在语义连贯性上表现优异。虽然目前扩散模型在综合能力上仍逊于传统架构, 但其在生成速度上已确立绝对优势,例如谷歌 Gemini Diffusion 可在 12 秒 内高效生成万级 tokens,为实时交互场景提供了坚实基础。
在基础架构维度,Transformer 架构的性能优化依旧是现阶段技术攻坚的核 心赛道。其中,以 DeepSeek 的 NSA(Nested Sparse Attention)、月之 暗面的 MoBA(Mixture of Bounded Attention)及面壁智能的 InfLLM-V2 为代表的稀疏注意力机制,已成为行业实现模型“降本增效”的标准化方案,在控制计算成本的同时,显著提升了长序列任务的处理效率。尽管Mamba3、 RWKV-8 等非 Transformer 新型架构在理论上具备独特优势,但目前仍处于 早期探索阶段,尚未形成成熟的工程化生态。当前业界更倾向于采用“混合架构”策略,通过融合 Transformer 与新型架构的特性,实现优势互补。代 表案例包括 Qwen3-Next、Hunyuan-TurboS、MiniMax M1、英伟达 Nemotron-H 等模型,它们兼具了 Transformer 的并行计算优势与线性注 意力的长序列建模能力,已在商业场景中取得了广泛成功。
在训练方法上,大模型的研发范式正经历根本性变革,即从“人类数据时 代”向“经验智能时代”加速过渡。这一变革的核心在于,模型不再局限 于依赖人工标注的静态数据集进行被动学习,而是转向通过与真实环境的动 态交互、任务试错迭代与自我反思优化,来积累系统性经验。这种“学习范 式”的升级,使大模型具备了三大核心能力跃升:
一是跨场景规律的自主提炼,能从有限经验中泛化出通用知识;
二是认知偏差的动态修正,通过反馈闭环持续优化决策逻辑;
三是知识边界的突破式创新,能够生成超越初始训练数据范畴的全新解决方案。最终,推动大模型能力从“复刻已知”走向“探索未知”。
目前,DeepSeek 提出的 GRPO(Group Relative Policy Optimization)算 法因其高效与稳健性,已成为大模型对齐策略的行业事实标准。在此基础上, DAPO、VAPO、SRPO、GFPO 等一系列优化变体应运而生,显著提升了 模型在复杂任务环节中的泛化能力与决策稳定性。与此同时,以 ToolRL、 Agent Lightning、Verlog 为代表的 AgenticRL 技术通过真实动态环境的多 轮交互式训练,赋予模型自主规划、调用工具、因果推断的能力,进而提升 其真实应用场景表现。
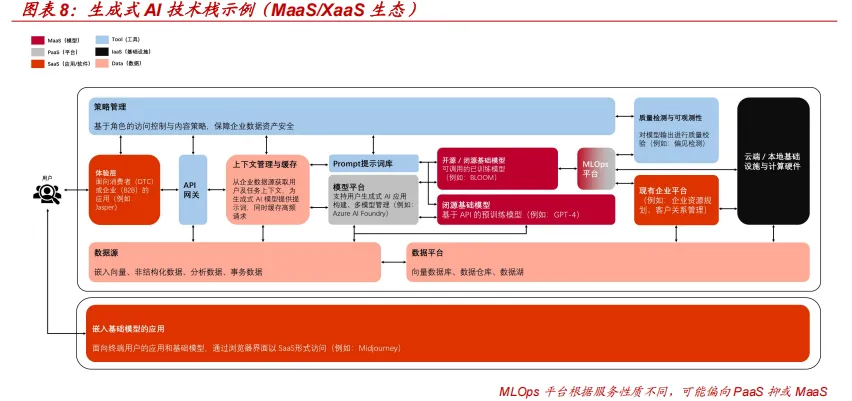
MaaS/XaaS 生态为 AI 商业化落地提供核心支撑
模型即服务(MaaS)作为聚焦 AI 模型部署与调用的新型服务模式,与软 件即服务(SaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)共同 构成的主流的 XaaS 生态,正成为推动 AI 技术赋能千行百业的核心支撑。
模型即服务(MaaS)是 AI 领域新型服务与商业模型,以云计算为支撑, 将 AI 和 ML(Machine Learning,机器学习)模型及相关基础设施作为服 务提供给开发者和企业。核心优势在于用户可通过简单接口、API 或 SDK等方式,直接调用预训练的 AI/ML 模型,无需自行训练和维护复杂模型, 也无需具备深厚的专业知识和庞大的基础设施,其聚焦 AI 和 ML 模型的训 练、部署与调用,能提供专业化、定制化服务,通过简化工具和友好操作界 面降低 AI 使用门槛。
软件即服务(SaaS)即通过互联网以在线订阅方式为用户提供应用程序, 用户无需本地安装软件,仅需进行人机交互即可使用,百度网盘、Dropbox、 Gmail 均是典型示例。
平台即服务(PaaS)是为程序开发者提供稳定的应用构建、测试与部署一 体化云计算平台,谷歌 App Engine 和微软 Azure 应用服务是经典代表。
基础设施即服务(IaaS)在云计算服务中是指通过网络服务提供虚拟化计 算资源,用户可按需租用服务器、网络、存储等基础设施,并通过 API 进 行使用。谷歌 Compute Engine、DigitalOcean、亚马逊弹性计算云均是成 熟的 IaaS 平台,且主要面向开发团队提供服务。
生成式 AI 的技术栈,可以按以下分层:
IaaS:云端/本地基础设施与计算硬件;
SaaS:嵌入基础模型的应用、面向消费者或企业的应用;
PaaS:支持用户生成式 AI 应用构建、多模型管理的模型平台(如 Azure AI Foundr);
MaaS:开源/闭源的基础模型