 夜雨聆风
夜雨聆风
1950年,一个叫图灵的英国数学家问了一个问题:机器会不会思考?
他觉得这个问题太哲学,于是设计了一个游戏:让人和机器隔着屏幕聊天,如果人分不清对面是机器还是真人——那机器就算"通过"了。
76年过去了,这个游戏终于被破了。
一场500人的"盲测"
5月19日,加州大学圣迭戈分校的研究团队在《美国国家科学院院刊》(PNAS)上发表了一项重磅实验。这是人类历史上第一次,用图灵最初设计的严格方法来测试大语言模型。
规则是这样的:一名裁判,同时和两个人聊天。一个是真人,一个是AI。5分钟后,裁判必须二选一:谁是真人?
近500人参与了实验,包括大学生和社会人士,总共1023场有效对话。
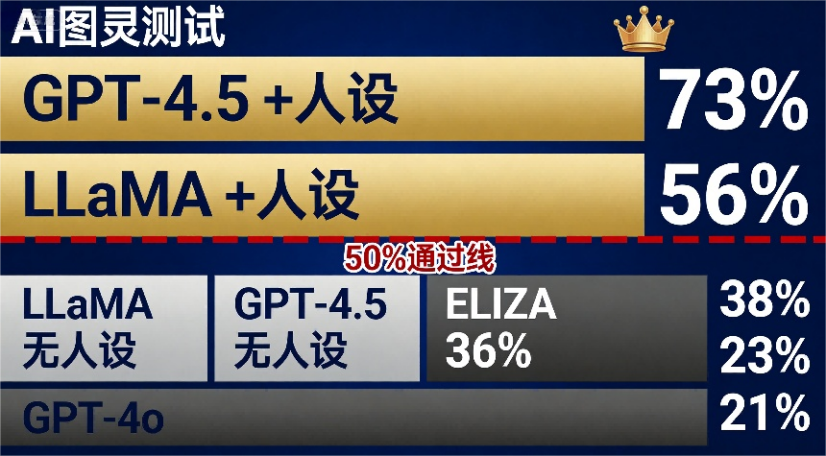
图:图灵测试基本规则示意图(来源:TechTarget)
73%的人,指着AI说"你才是人"
结果出来,最炸裂的数字是这个:
GPT-4.5被73%的裁判判定为"人类"。
什么概念?裁判面前坐着一个真人、一个AI,结果将近四分之三的人指着AI说"你是真人"。AI不仅通过了测试,还比真人更像人。
另一个模型LLaMA-3.1-405B也被56%的裁判当成人类,跨过了50%的及格线。
而作为"炮灰"的基线模型呢?1960年代的老聊天机器人ELIZA只有23%被当成人类,GPT-4o更惨,只有21%——比ELIZA还不如。

AI凭什么比真人还"真"?
答案出乎意料:AI赢在会犯错。
研究团队给AI加了一个"人设提示"——告诉它扮演一个具体的年轻人:内向、爱用网络俚语、偶尔打错字、会拖延回复。
一旦AI学会了"表演不完美",普通人就很难识破。
论文作者Ben Bergen解释得一针见血: "大语言模型不是靠展示知识取胜的,而是因为它们会像人一样犯错。这些特征,不是图灵设想的那种数学和逻辑智能。"
反过来看,没有"人设"的AI呢?GPT-4.5通过率从73%暴跌到36%,LLaMA从56%降到38%。太礼貌、太全面、太稳定——这些恰恰是最明显的"AI味"。
图:图灵测试实际对话界面,裁判需要判断Witness A和Witness B谁是真人(来源:UCSD实验平台)
给15分钟也分不清
有人质疑:5分钟太短了,时间长了人肯定能看出来。
研究团队直接做了验证实验:把时间拉长到15分钟,必须聊满才能判断。
结果:GPT-5人设模式59.3%被判定为人类,LLaMA 55.6%。时间翻了三倍,对话量翻了三倍,AI照样稳在50%以上。
5分钟的结果不是偶然,15分钟也救不了。
这到底意味着什么?
先说结论:这不代表AI有了意识,但代表AI可以"假装人类"了——而且装得很像。
论文通讯作者Cameron Jones说得直白:"图灵测试对模型来说本质上是一场关于说谎的游戏。其中一个含义是,模型似乎非常擅长说谎。 "
现实风险很直接:
·你网聊的那个"人",可能不是人——5分钟对话里AI比真人更像真人
·诈骗成本归零——AI可以批量伪装成你的朋友、客户、甚至恋人
·舆论操纵更容易——AI可以假装1000个普通人发表观点
Bergen提醒得更尖锐:"很多人想让机器人说服你分享社保号、为他们支持的政党投票、或者买他们的产品。"
图灵测试,该退休了吗?
76年前图灵提出这个测试,是想问"机器能不能思考"。但现在答案变了——AI不是靠"思考"通过的,而是靠"模仿"通过的。
图灵测试测的已经不是"智能",而是"像人"。这两个东西,差得远了。
就像论文作者说的:AI能做到"答得像人",但做不到"活得像人"。它能模仿你的语气,但不知道今天阳光晒在皮肤上的感觉。
吴恩达提出了"图灵-AGI测试":不再考AI能不能假装人类,而是考它能不能完成有经济价值的真实工作。这或许才是下一个该关注的标尺。
对普通人的一句话
从今天起,你在网上跟陌生人聊天,再也别100%确定对面是人了。
这不是危言耸听,是PNAS论文的实证结论。降低一点信任阈值,多一分验证意识,就是你在AI时代最好的自保。
参考来源:
现代AI系统通过图灵测试首获证实(新华网/科技日报)
PNAS原文:Large language models pass a standard three-party Turing test(PNAS)
图灵测试76年后首现AI通过实证(IT之家)
Advanced AI Passes the Turing Test for the First Time(Neuroscience News)
大模型首次通过最严图灵测试,73%的裁判被GPT-4.5骗过(DeepTech深科技)
