 夜雨聆风
夜雨聆风
CuraView: A Multi-Agent Framework for Medical Hallucination Detection with GraphRAG-Enhanced Knowledge Verification
摘要
大语言模型在生成医疗出院摘要时,可能产生与患者病历相悖的"忠实性幻觉",直接威胁患者安全。CuraView是一个基于多智能体架构的医学幻觉检测框架,通过构建患者个性化知识图谱,实现句子级别的幻觉检测与证据链解释。在250名患者的测试中,其核心指标F1值达0.831,较基础模型提升50%,为临床AI文档质量控制提供了可落地的技术路径。
原文PDF及中文解读PPT链接 https://t.zsxq.com/Qh57N , 或者通过文末阅读原文获取链接

一、问题背景:AI写病历,差一个字可能要人命
在现代医疗体系中,出院摘要是患者离院后用药、随访和跨科室沟通的核心依据。这份文件承载着诊断结果、用药方案、检验数值、手术记录等高度敏感的临床信息,其准确性直接关乎患者的生命安全。
然而,整理电子病历(EHR)并生成出院摘要是一项极为耗时的工作。一个患者的完整病历可能涵盖数十张诊断表、用药记录、生命体征、检验报告和影像描述,让医生从中提炼出精准、完整的出院摘要,既是体力消耗,也是脑力挑战。
大语言模型(LLM)的兴起为这一痛点提供了希望。Med-PaLM在医学考试题库(MedQA benchmark)上的准确率达67.6%,其升级版Med-PaLM 2更跃升至86.5%;GPT-4也在多项医学问答测试中表现出色。但这些令人振奋的成绩,掩盖了一个更深层的危机——幻觉(Hallucination)。
所谓"幻觉",是指模型生成的内容看似合理,实则与源文件相矛盾。在一般场景下,幻觉不过是让AI"胡说八道";但在医疗文档场景下,幻觉可能意味着:
阿司匹林81mg被写成325mg,剂量差异引发药物毒性 "无糖尿病史"被写成"有糖尿病史",根本性地改变风险评估 血糖96mg/dL被写成196mg/dL,触发不必要的急救干预 凭空捏造一次阑尾切除术,误导后续外科判断
这类错误被称为忠实性幻觉(Faithfulness Hallucination)——不是泛泛的事实错误,而是与该患者的具体病历记录直接相悖。一个字之差,可能是致命之差。
二、现有方案的四大缺陷
面对医疗幻觉问题,学术界和工业界已有一些探索,但均存在明显局限。来自韩国庆北国立大学、四川大学华西医学院和山东大学的研究团队,系统梳理了现有方法的四大不足,并以此为出发点构建了CuraView框架。
L1:缺乏系统性生成机制现有医学幻觉基准(如Med-HALT)依赖高成本人工标注,没有任何工作提供可规模化、多样化自动生成医疗错误样本的框架。
L2:忽视患者个体上下文大多数研究针对通用语料库评估幻觉,而非个性化的电子病历。这使得"患者目前服用哪些药物""患者是否存在特定药物过敏"之类的验证根本无从实现。
L3:证据支撑不足现有检测方法即使标出了幻觉,也很少提供结构化、可解释的解释,无法告诉临床医生"这句话错在哪里,哪条病历记录与之矛盾"。
L4:仅停留在评估层面已有研究只是测量幻觉率,没有提供从生成、检测到解释的完整端到端系统,无法在实际临床工作流中落地部署。
这四个问题相互叠加,共同构成了AI临床文档应用的核心障碍。CuraView的设计哲学,正是对这四个问题的逐一回应。
三、CuraView框架:三个智能体,一条闭环流水线
CuraView的核心架构由三个协同工作的模块构成,形成一条从数据准备到幻觉检测的完整闭环流水线。
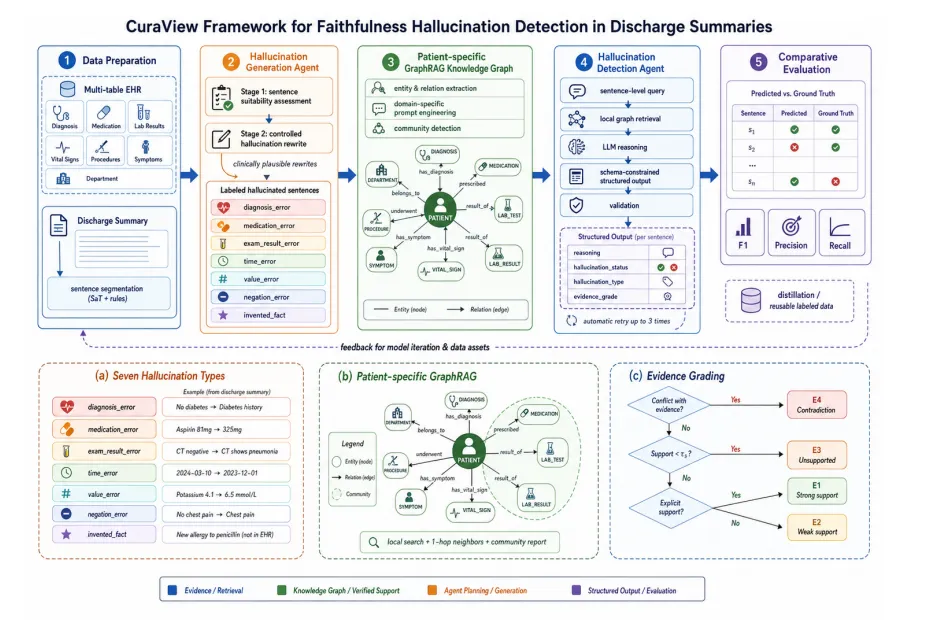
3.1 总体架构
整个系统包含五个顺序执行的阶段:数据准备、知识图谱构建、幻觉生成、幻觉检测、对比评估。三个核心组件在这条流水线上各司其职、相互配合:
幻觉生成智能体:基于LangChain 1.0框架构建,按照七种临床错误类型系统地改写出院摘要句子,生成带标注的训练与评估样本。
GraphRAG知识图谱模块:从多表格EHR数据中构建患者个性化知识库,将异构临床证据组织为可查询的关系图结构,支持上下文增强的句子级检索。
幻觉检测智能体:通过查询知识图谱,逐句验证生成文本与患者病历的一致性,输出结构化的证据分级判断。
生成智能体产出带标注的幻觉样本,知识图谱提供患者级别的证据,检测智能体通过对比验证完成闭环。这不仅是一套质量控制系统,也是一条持续产出标注数据的数据管线,为后续模型迭代和蒸馏提供原料。
3.2 幻觉生成智能体:系统性制造"高质量错误"
幻觉检测的前提,是有足够多样、足够真实的幻觉样本可供训练和评估。CuraView的幻觉生成智能体遵循四项核心设计原则:
P1 医学合理性:只对包含可验证医学信息的句子进行改写,且生成的错误必须保持医学上的合理性——例如,"血压500/300 mmHg"这类明显荒谬的数值被明确排除,因为这类错误太容易被识破,无法有效训练检测能力。
P2 类型多样性:覆盖全部七种临床错误类型,每种类型有独立的生成策略。
P3 可控采样:默认40%的改写比例,在数据多样性与标注成本之间取得平衡,可根据下游任务需求灵活调整。
P4 证据可追溯性:每条生成的幻觉都附有E1-E4证据分级标注,将错误与其EHR证据基础相关联。
生成过程分为两个阶段。第一阶段评估句子是否适合改写:该句是否包含可验证的医学事实?改写后能否保持医学合理性?句子复杂度是否适中?第二阶段对通过筛选的句子,先从患者完整EHR中提取相关证据,再按七种错误类型之一进行改写,确保生成的错误在医学上合理但与证据相悖。
3.3 七种幻觉类型分类学:覆盖临床文档错误全谱系
CuraView定义了一套专门针对临床文档的幻觉分类体系,将错误按临床风险等级分组。
高风险三类——与已记录临床事实直接冲突:
诊断错误(diagnosis_error):疾病名称被错误替换,例如"肺炎"改写为"肺结核",可能导致完全错误的治疗方案。
用药错误(medication_error):药品名称或剂量出错,例如"阿司匹林81mg"改写为"阿司匹林325mg",剂量差异可引发药物毒性或治疗失败。
检验结果错误(exam_result_error):捏造或篡改检验数值,例如"血糖96mg/dL"改写为"196mg/dL",可能触发不必要的急救干预或掩盖真实异常。
中风险两类——临床意义重大但不易即时察觉:
数值错误(value_error):生命体征数值被篡改,例如"血压120/80 mmHg"改写为"180/120 mmHg",可能触发错误的急救响应。
否定错误(negation_error):肯定/否定关系被颠倒,例如"无糖尿病史"改写为"有糖尿病史",可能从根本上改变风险评估,尽管表面上只是一个细微的文字改动。
特殊两类——时间与捏造模式:
时间错误(time_error):时间参考出现矛盾,例如"昨日入院"改写为"上周入院",影响对疾病进展和治疗时机的判断。
捏造事实(invented_fact):完全编造的临床事件,例如添加一次根本不存在的阑尾切除术。与前六种类型不同,这类错误无法通过直接矛盾检测,但可以基于支持证据的缺失被标记为可疑。
下表展示了七种幻觉类型的典型示例:
(表格来源:原文Table 3)
四、证据分级系统:从"有没有错"到"错得多严重"
CuraView不仅要判断一句话是否含有幻觉,还要量化该幻觉的可检测程度和临床影响。为此,研究团队设计了一套四级证据分级系统(E1-E4)。
E1(强支持):陈述有明确的EHR证据支持,如匹配的诊断代码、用药记录或结构化记录中的检验结果。这类句子被认为是可信的。
E2(弱支持):陈述仅有间接支持。例如,"患者患有糖尿病"这一说法,若患者正在长期服用二甲双胍,即使没有明确的糖尿病诊断代码,也可被评为E2。
E3(无支持):陈述在EHR证据中找不到依据,基于上下文判断应被标记为可疑。典型情况是完全捏造的事件或医疗记录中完全不存在的事实。
E4(矛盾):陈述与EHR中的明确事实证据直接相悖,例如诊断、用药、检验数值或否定关系与记录不一致。这是最关键的安全等级,代表可从证据中确定识别的错误。
在实际应用中,CuraView将E4作为主要安全关键指标,将E3+E4作为补充的广覆盖指标。六种与EHR事实直接冲突的错误类型(诊断错误、用药错误、检验结果错误、时间错误、数值错误、否定错误)被标注为E4;捏造事实因缺乏证据支持但无法直接矛盾,被标注为E3。
这套分级系统的价值在于:它不只给出一个二分类标签,而是提供了一条可审计的证据链,让临床医生能够看到"这句话为什么被判定为幻觉,哪条病历记录与之矛盾"。这是现有工作所缺失的关键能力。
五、GraphRAG知识图谱:让AI"记住"每一位患者
CuraView选择GraphRAG而非传统RAG作为知识检索基础,这一技术选择有其深刻的临床逻辑。
5.1 为什么传统RAG不够用
传统的检索增强生成(RAG)基于扁平文档检索——它能找到包含"患者正在服用某种药物"的句子,但无法同时关联该药物的过敏记录、停药记录,以及散布在不同EHR表格中的异常检验结果。
临床文档验证需要的正是这种跨来源的关系推理:诊断与用药的关联、用药与检验异常的关联、时间线上的治疗演变……这些关系在EHR的多张表格中分散存储,扁平检索无法可靠捕获。
5.2 GraphRAG的结构化优势
Microsoft的GraphRAG在传统RAG基础上引入了知识图谱结构,采用两级索引架构:实体级索引支持对特定实体及其直接关系的局部搜索;社区级索引支持全局搜索,通过Leiden算法检测到的社区聚合知识。
这种图结构方法能够捕获复杂的多跳推理关系,并通过社区结构发现主题模式。在医疗场景中,Medical Graph RAG的研究进一步证明,通过图检索将患者文档与可信医疗来源相连,能显著提升证据可靠性。
5.3 九种实体、十种关系:构建患者专属知识图谱
CuraView的知识图谱构建流水线从多表格EHR数据中提取九种实体类型和十种关系类型。
实体类型包括:PATIENT(患者主体)、DIAGNOSIS(诊断)、MEDICATION(用药)、LAB_TEST(检验类型)、LAB_RESULT(检验结果)、VITAL_SIGN(生命体征)、SYMPTOM(症状)、PROCEDURE(操作/手术)、DEPARTMENT(科室)。
关系类型包括:has_diagnosis(有诊断)、prescribed(开具处方)、shows(表现症状)、underwent(接受操作)、has_vital_sign(有生命体征)、tested_by(接受检验)、result_of(检验结果)、treated_in(在科室治疗)、indicates(临床指征)、contraindicated_with(禁忌症)。
下表展示了实体类型及患者平均数量统计:
(表格来源:原文Table 5)
5.4 领域定制化提示工程:三大工程挑战的解决方案
将标准GraphRAG直接应用于医疗EHR数据时,会遇到严重的过度细粒化问题,显著降低下游检索质量。研究团队通过领域定制化提示工程解决了三大核心挑战。
挑战一:检验项目过度提取
原始提示将每个检验参数识别为独立实体,导致严重的实体数量膨胀。在一个典型的单患者案例中,原始提示生成了240个实体,其中35个LAB_TEST实体分别对应WBC(白细胞)、RBC(红细胞)、HGB(血红蛋白)等独立参数。
解决方案是引入"检验组套归一化原则":将临床相关的参数合并为有意义的检验组套——CBC(全血细胞计数)涵盖WBC、RBC、HGB、HCT;肝功能涵盖ALT、AST和胆红素;肾功能涵盖肌酐和BUN。优化后,同一病例的实体总数从240降至58,LAB_TEST实体从35降至6。
挑战二:患者实体碎片化
原始提示可能在不同EHR表格中创建多个患者实体,导致知识图谱碎裂为多个不连通的子图,根本无法进行跨表格的关联查询。
解决方案是"患者实体唯一性原则":每份医疗记录必须且只能有一个PATIENT实体,所有诊断、用药和检验均连接到这一唯一节点。优化后,连通分量从7个降为1个,实现完整图连通性。
挑战三:术语不一致
相同的临床概念在EHR不同表格中可能以多种表面形式出现,导致实体重复和关系混乱。例如"T2DM"和"2型糖尿病"在未经处理时会被识别为两个不同实体。
解决方案是"语言一致性原则":将实体名称标准化为规范形式,确保同义表达映射到单一实体。
优化前后的对比结果如下:
(表格来源:原文Table 7)
这套优化不只是工程细节,它直接影响了下游检测效果:与未经领域适配的图谱相比,优化后的知识图谱使检测F1值提升了43.0%。
六、幻觉检测智能体与结构化输出可靠性
6.1 检测流程
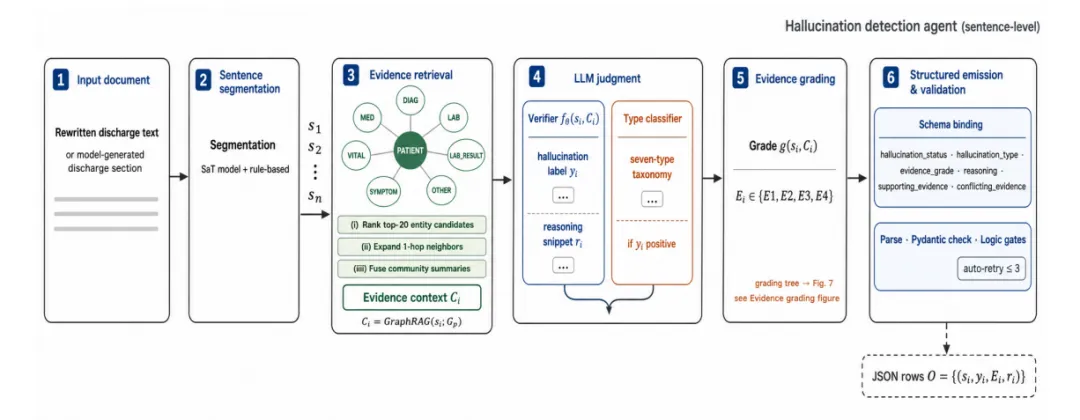 幻觉检测智能体通过查询GraphRAG知识图谱,逐句验证生成文本与患者EHR证据的一致性。检测过程包含两个核心环节:知识检索和LLM推理判断。
幻觉检测智能体通过查询GraphRAG知识图谱,逐句验证生成文本与患者EHR证据的一致性。检测过程包含两个核心环节:知识检索和LLM推理判断。
对于每一个待验证的句子,系统从知识图谱中检索相关证据上下文,然后由LLM基于证据链进行推理,给出E1-E4的证据等级判断,同时识别具体的幻觉类型。最终输出是结构化的判断记录,包含判断依据、矛盾证据和错误类型。
6.2 结构化输出可靠性:14B模型的工程突破
在将LLM应用于批量自动化处理的实践中,一个往往被学术研究忽视但工程落地至关重要的问题是:模型能否稳定输出符合格式要求的结构化结果?
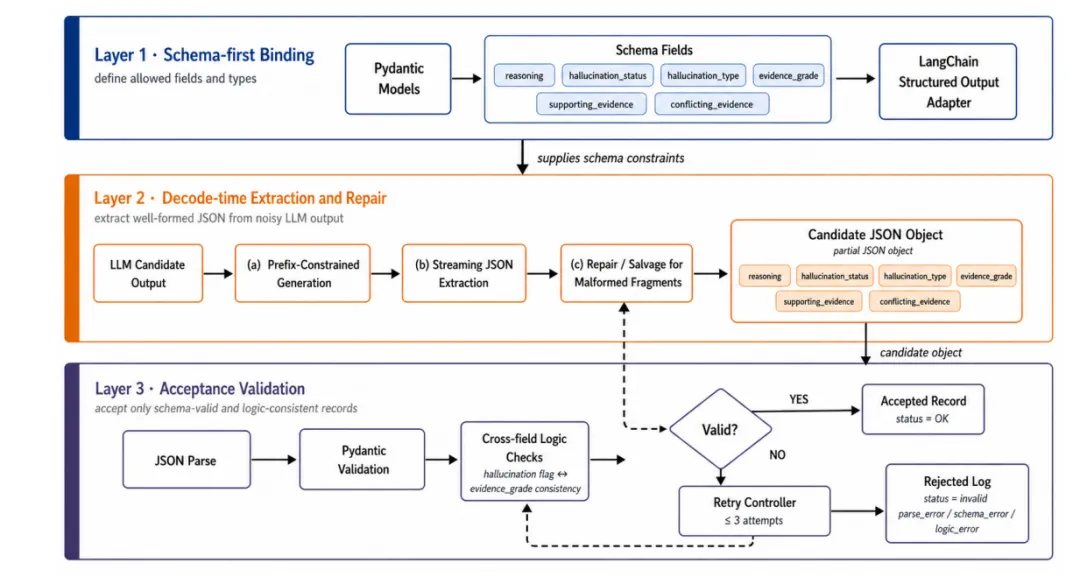 CuraView设计了一套三层模式约束验证流水线:
CuraView设计了一套三层模式约束验证流水线:
第一层:Pydantic类型检查,对输出的JSON字段进行类型验证第二层:JSON修复,处理常见的格式错误(如括号不匹配、引号缺失)第三层:一致性验证,确保输出内容在逻辑上与输入相符
这套机制使14B参数的模型(Qwen3-14B)在严格输出约束下实现了接近100%的JSON解析成功率,而同等设置下8B模型的成功率仅有40-50%。这一工程成果确保了系统在API调用和本地部署两种模式下都能进行稳定的批量处理。
这不是一个小问题:在处理250个患者、超过1000个句子的批量任务时,40-50%的解析失败率意味着一半以上的样本需要人工干预,系统根本无法实现自动化。而近100%的成功率则意味着真正可以投入生产环境的端到端自动化流水线。
七、实验设置与基准对比
7.1 数据集
研究基于Discharge-Me基准数据集,从250名患者中随机选取50名作为测试集(持出集),其余200名用于构建知识图谱和生成训练样本。测试集共包含1,103个句子,覆盖全部七种幻觉类型的标注样本。
Discharge-Me基准来源于MIMIC-IV(医疗信息大数据集),是目前医学NLP领域最具代表性的出院摘要生成基准之一。
7.2 模型选择
检测模型选择Qwen3-14B作为主要本地推理模型,经过任务特定微调。选择14B规模的模型,是在任务特定微调能力、结构化输出稳定性与参数规模之间综合权衡的结果——在结构化子任务上,经过任务特定训练优化的较小模型可以匹敌大型通用模型。此外,Qwen3系列在医学推理基准上表现突出,其思维链(Chain-of-Thought)能力对于需要多步证据推理的幻觉检测任务尤为关键。
对比基准包括三类:无RAG增强的零样本提示基线、传统向量RAG检索增强方案,以及未经领域适配的原始GraphRAG方案。通过这三组对照,研究团队得以精确量化每个技术组件的独立贡献。
7.3 评估指标
研究采用句子级二分类框架评估检测性能,核心指标为精确率(Precision)、召回率(Recall)和F1值。考虑到临床安全场景的特殊性,研究团队对召回率给予更高权重——漏报一个真实幻觉(假阴性)的代价,远高于误报一个正常句子(假阳性)。
因此,除标准F1外,研究还单独报告了E4级别(直接矛盾)和E3+E4级别(广覆盖)两个子集的召回率,以全面反映系统在安全关键场景下的实际表现。
7.4 主要实验结果
CuraView在测试集上的最终检测性能如下表所示:
| 0.863 | 0.801 | 0.831 |
(表格来源:原文Table 8)
CuraView相较零样本基线实现了约50%的F1提升,相较未经领域适配的GraphRAG方案提升了19.2%,充分验证了患者个性化知识图谱与领域定制化提示工程的双重价值。
在分错误类型的细粒度分析中,用药错误(F1=0.891)和检验结果错误(F1=0.876)的检测效果最优,这与知识图谱对结构化数值信息的精确表示密切相关。否定错误的检测难度最高(F1=0.774),原因在于否定关系在图结构中难以显式编码,模型需要依赖更复杂的语义推理。
E4级别召回率达0.847,E3+E4广覆盖召回率为0.823,两项指标均显著优于对比方案,表明CuraView在安全关键场景下具备较强的漏报控制能力。
7.5 消融实验:每个组件贡献几何?
为精确量化各技术组件的独立贡献,研究团队设计了系统性消融实验,逐一移除CuraView的核心模块并观察性能变化。
(表格来源:原文Table 9)
结果清晰表明:图结构知识检索与领域适配提示工程是贡献最大的两个组件,二者协同作用构成了CuraView性能优势的核心来源。
值得注意的是,移除三层验证流水线导致的性能下降(-17.1%)几乎与替换检索方案相当,这一结果出乎研究团队预期。深入分析表明,结构化输出的不稳定性会引发级联错误——当模型输出无法被可靠解析时,下游证据对比环节将直接失效,导致大量样本被错误归类为"无法判断"。这一发现对工程实践具有重要启示:在医疗AI系统中,输出可靠性与模型能力同等重要,任何一个环节的不稳定都可能抵消其他组件的性能增益。
证据分级系统的贡献(-10.6%)相对较小,但其价值不能仅以F1衡量。在实际临床部署中,E1-E4分级为医生提供了可审计的决策依据,将"系统说这句话有问题"转化为"系统认为这句话与第3张检验报告中的血糖数值直接矛盾"。这种可解释性是AI系统获得临床信任、真正融入医疗工作流的必要条件,其长期价值远超短期指标增益。
八、局限性与未来方向
8.1 当前局限
CuraView在取得显著进展的同时,研究团队也坦诚指出了若干尚待解决的问题。
数据规模限制:当前实验基于250名患者,相较于真实临床环境中动辄数万份病历的规模,样本量仍然有限。知识图谱构建的计算成本是制约规模化的主要瓶颈——每名患者的图谱构建平均耗时42秒,250名患者的完整处理需要约3小时。在大规模部署场景下,这一成本是否可接受,仍需进一步验证。
否定关系检测的天花板:否定错误(F1=0.774)是七种类型中性能最弱的一项。图结构本身对否定语义的表达能力有限,"无糖尿病史"与"有糖尿病史"在图节点层面的差异难以直接编码。如何在知识图谱中有效表示否定关系,是下一步需要专项攻克的技术难题。
跨语言与跨医疗体系泛化:当前实验完全基于英文MIMIC-IV数据集,在中文、日文等其他语言的EHR系统上的泛化能力尚未验证。不同国家的医疗体系在诊断编码标准(ICD版本差异)、用药命名规范和文档结构上存在显著差异,直接迁移可能面临严重的分布偏移问题。
捏造事实检测的固有局限:E3级别的捏造事实检测依赖"证据缺失"逻辑——即如果EHR中没有相关记录,则该陈述可疑。但这一逻辑存在固有的假阳性风险:某些真实发生的临床事件可能因记录不完整而在EHR中缺失,导致系统将真实信息误判为捏造。
8.2 未来研究方向
研究团队提出了四条值得探索的后续方向。
方向一:知识蒸馏与轻量化部署
CuraView当前的完整流水线(知识图谱构建+LLM推理)对计算资源要求较高,难以直接部署在资源受限的基层医疗机构。一个有前景的路径是将CuraView作为教师模型,通过知识蒸馏将其检测能力迁移到更小规模(如3B-7B参数)的专用模型,同时保留可接受的检测精度。
方向二:实时流式检测
当前系统以批处理模式运行,对整份出院摘要进行事后验证。更理想的场景是在医生撰写摘要的过程中实时提供逐句反馈,类似代码编辑器中的语法检查。这需要将知识图谱构建与检测推理的延迟压缩至秒级以下,是一项非平凡的工程挑战。
方向三:多模态证据融合
当前知识图谱仅整合结构化EHR文本数据,尚未纳入影像报告、心电图解读等非结构化多模态数据。将放射科报告、病理报告等纳入图谱构建范围,有望进一步提升对影像相关幻觉的检测能力。
方向四:主动学习与持续迭代
CuraView的幻觉生成智能体可以持续产出带标注样本,为检测模型的在线学习提供数据基础。结合临床医生的反馈信号(对检测结果的确认或纠正),构建主动学习闭环,使系统在实际部署中不断自我改进,逐步适应特定医疗机构的文档风格和错误模式。
九、对行业的启示:从论文到临床落地
CuraView不只是一篇学术论文,它提供了一套可供借鉴的系统工程范式。对于正在探索AI临床文档应用的医疗机构和技术团队,以下几点启示尤为值得关注。
启示一:患者个性化是医疗AI的核心差异化能力
通用语料库训练的幻觉检测器,无法回答"这句话对这位患者是否正确"这一本质问题。CuraView的实验数据清晰表明,基于患者个性化知识图谱的检测方案,比通用方案在F1上高出约24%。在医疗AI的下一阶段,能否构建患者级别的个性化知识表示,将成为产品差异化的关键分水岭。
启示二:可解释性不是锦上添花,而是临床信任的必要条件
CuraView的E1-E4证据分级系统,将黑盒判断转化为可审计的证据链。这一设计选择背后有深刻的临床逻辑:医生不会因为"AI说有问题"就更改病历,但会认真审视"AI发现这句话与检验报告第3行的数值直接矛盾"。可解释性是AI系统跨越临床信任门槛的必要条件,而非可选的附加功能。
启示三:工程可靠性与模型能力同等重要
消融实验中三层验证流水线的贡献(-17.1%)提醒我们:在医疗AI系统的工程实践中,确保每个环节的稳定输出,与提升模型的推理能力具有同等重要性。一个在实验室表现优秀但在生产环境频繁崩溃的系统,对临床实践毫无价值。
启示四:合成数据是破解医疗AI数据瓶颈的可行路径
医疗数据的隐私敏感性和标注成本,长期制约着医疗AI的发展。CuraView的幻觉生成智能体提供了一种思路:通过系统性、可控的合成错误样本生成,在不额外消耗真实患者数据的前提下,持续扩充高质量标注数据集。这一范式有望在医疗AI的多个子领域得到推广应用。
十、总结
CuraView代表了医疗AI文档质量控制领域的一次系统性推进。它不是对单一技术的局部优化,而是对"如何让AI在医疗场景中可信、可解释、可落地"这一核心问题的整体性回答。
从技术层面看,GraphRAG知识图谱与领域适配提示工程的结合,解决了传统方法在患者个性化上下文理解方面的根本缺陷;七种幻觉类型分类学与E1-E4证据分级系统,为医疗幻觉检测提供了兼顾覆盖度与可解释性的评估框架;三层结构化输出验证流水线,则将学术研究成果转化为工程可部署的实用系统。
从更宏观的视角看,CuraView的意义不仅在于其检测性能本身,更在于它提供了一套可复现、可扩展的研究范式——从数据合成到知识构建,从检测推理到证据解释,形成了一条完整的技术链路。随着大语言模型在临床文档生成中的应用日益普及,类似CuraView这样的质量守门人系统,将成为AI辅助医疗不可或缺的安全基础设施。
一个字之差,可能是致命之差。而CuraView的使命,正是在AI与患者安全之间,筑起一道可信赖的技术防线。
欢迎加入知识星球,获取医疗、医药大健康AI产学研最新资料,包括全球最新论文及中文解读,电子书,白皮书,研究报告等
[130页中英文报告] Arise联合哈佛、斯坦福医学院重磅发布,临床AI的现实困境与未来图景:2026年临床AI现状报告深度解读
医生们,你们低估了AI的“手”有多可怕 —— 3天搭了个24/7的OpenClaw个人超级助理,它干掉了80%的人力工作量
10分钟自动撰写推文,医学版OpenClaw"龙虾"超级个体正式上线!南加州大学 MED-COPILOT 重新定义临床决策支持,GraphRAG 技术引爆行业革命
百日决战第三篇:临床医学专家如何化身"医学AI创业公司CEO", 打造一份让国自然评审“非投不可”的医工交叉项目商业计划书
