 夜雨聆风
夜雨聆风本文是「用 AI 打造私人文献助手」系列第二篇,上篇回顾:用 AI 打造你的私人文献助手:基于 Claude Code 的论文阅读工作流 |
🔥 这套工作流支持 Claude Code/Codex 一键安装配置!不用再手动敲命令、复制文件、配置环境,直接把文末的 GitHub 仓库链接发给 AI,它会自动完成所有安装步骤,全程零代码,5 分钟就能上手使用。
上篇推文发出后,收到了多位科研同行的私信,大家问得最多的就是:
评分体系具体是怎么算的?
中文论文怎么自动搜索?
关键词自动链接是怎么实现的?
生成的笔记格式能不能自定义?
今天这篇就把所有核心细节一次性补全,从底层逻辑到使用方法,再到踩坑经验,让你看完就能搭出属于自己的自动化论文阅读工作流。
一、为什么我要迭代这个工作流?
做科研的人都懂,每天打开 arXiv 和期刊网站,面对几十上百篇新论文的无力感:
花 1 小时刷完列表,发现 90% 都和自己的研究无关
好不容易找到一篇相关的,读完才发现是水文
好论文的笔记散落在各个地方,想找的时候翻不到
不同论文之间的关联全靠脑子记,时间一长就断了
上篇分享的基础版工作流解决了 "找论文" 的问题,但还有很多痛点:
中文期刊论文完全缺失,对国内研究者不友好
搜索结果不够精准,经常出现不相关的论文
生成的笔记是孤立的,没有和已有知识关联
不支持双语,英文用户使用体验差
于是我花了一个月时间,把整个工作流重构了一遍,新增了 10 + 核心功能,现在它已经能完全替代我每天手动刷论文的工作了。
二、核心升级:5 大功能让效率再翻 3 倍
✅ 三源互补检索策略,不漏掉任何重要论文
不再是简单的关键词搜索,而是采用 "主 - 辅 - 补" 三层检索体系,覆盖中英文、预印本和正式期刊:
搜索源 | 优先级 | 覆盖范围 | 搜索策略 |
Semantic Scholar | 主 | 全球英文期刊 + 预印本 | 按领域查询模板精准搜索,覆盖近 365 天新论文 + 近 730 天高引论文 |
CNKI | 辅 | 中文核心期刊 | 浏览器自动化搜索,每日最多推荐 2 篇,严格匹配配置的期刊列表 |
arXiv | 补 | 最新预印本 | 关键词搜索,仅补充 Semantic Scholar 未覆盖的前沿工作 |
最关键的是:你可以在配置文件中自定义每个领域的查询模板,比如研究海洋热浪的可以设置 "marine heatwave detection deep learning"、"marine heatwave fishery impact climate change" 等精准查询,这样搜索出来的论文,相关性会比普通关键词搜索高一个量级。
✅ 四维评分体系全公开,精准筛选 Top10
搜索结果会经过严格的评分筛选,最终只保留综合评分最高的 10 篇。评分公式完全透明,你可以根据自己的需求调整权重:
Plain Text 最终推荐评分 = 相关性(40%) + 新近性(20%) + 热门度(30%) + 质量(10%) |
详细评分细则:
1 相关性评分 (40%):最核心的维度
标题关键词匹配:每个 + 0.5 分
摘要关键词匹配:每个 + 0.3 分
研究领域匹配:+1.0 分
最高分:~3.0 分
2 新近性评分 (20%):鼓励关注最新研究
最近 30 天内发表:+3 分
30-90 天:+2 分
90-180 天:+1 分
180 天以上:0 分
3 热门度评分 (30%):参考学术界认可度
引用数 > 100:+3 分
引用数 50-100:+2 分
引用数 < 50:+1 分
无引用数据的 7 天内新论文:+2 分(默认热门)
4质量评分 (10%):AI 自动评估论文质量
显著创新(提出新方法 / 新数据集):+3 分
明确方法改进:+2 分
一般性工作:+1 分
✅ 双语自适应系统,中英文用户都能用
现在工作流支持中英文双语输出,只需要在配置文件中修改语言设置即可。系统会自动生成对应语言的笔记:
文件名:2026-05-25论文推荐.md / 2026-05-25-paper-recommendations.md
所有标题、标签、说明文字都会自动切换语言
甚至连今日概览的总结内容也会用对应语言生成
✅ 智能知识关联,让笔记形成网络
生成的推荐笔记不再是孤立的文档,而是会自动和你已有的笔记关联起来:
系统会先扫描你论文笔记/目录下的所有文件
提取每篇笔记的标题和标签,构建关键词索引
生成推荐笔记时,自动将文本中的关键词替换为 wikilink
比如:这篇论文使用了BLIP作为基线方法 → 这篇论文使用了[[BLIP]]作为基线方法
智能保护机制:
不会替换已经存在的 wikilink
不会替换代码块和行内代码中的内容
会自动过滤 "the"、"and"、"model" 等通用词
忽略大小写,中英文都支持
✅ 前 3 篇论文深度处理,一键生成图文笔记
对于评分最高的 3 篇论文,系统会自动进行深度处理:
尝试从 arXiv 下载 PDF 和源码包
调用extract-paper-images提取论文中的关键图片(优先从源码包获取原始图片)
调用paper-analyze生成结构化的深度分析笔记
在推荐笔记中自动插入图片和深度笔记的 wikilink
这样你打开推荐笔记,就能直接看到论文的核心架构图和实验结果,不用再手动下载 PDF 了。
三、手把手配置:5 分钟搭好你的私人文献助手
第一步:准备基础工具
安装 Claude Code(推荐)或 Codex
安装 Obsidian(用于管理笔记)
安装 Anaconda(用于创建 Python 环境,AI 会自动配置)
第二步:一键安装工作流
强烈推荐使用 AI 一键安装:直接把文末的 GitHub 仓库链接发给 Claude Code 或 Codex,输入指令 "帮我安装这个学术阅读工作流",AI 会自动完成克隆仓库、复制技能文件、安装 Python 依赖等所有步骤。
第三步:创建并编辑研究兴趣配置文件
在你的 Obsidian 仓库中创建research_interests.yaml的配置文件,这是整个工作流的核心,用于定义你的研究兴趣和搜索偏好。根据自己的路径修改源码。
你只需要告诉 AI 你的研究方向(比如 "海洋热浪"、"计算机视觉与自动驾驶"),AI 会自动生成基础的配置模板,你再根据自己的具体研究内容调整关键词和优先级即可。
第四步:开始使用
打开 Claude Code,输入:
bash /start-my-day |
如果想生成指定日期的推荐:
bash /start-my-day 2026-05-20 |
等待 5-10 分钟,系统就会在你的 Obsidian 仓库的Daily_paper/目录下生成今日论文推荐笔记。
四、实际效果展示
这是我今天生成的推荐笔记的部分内容:

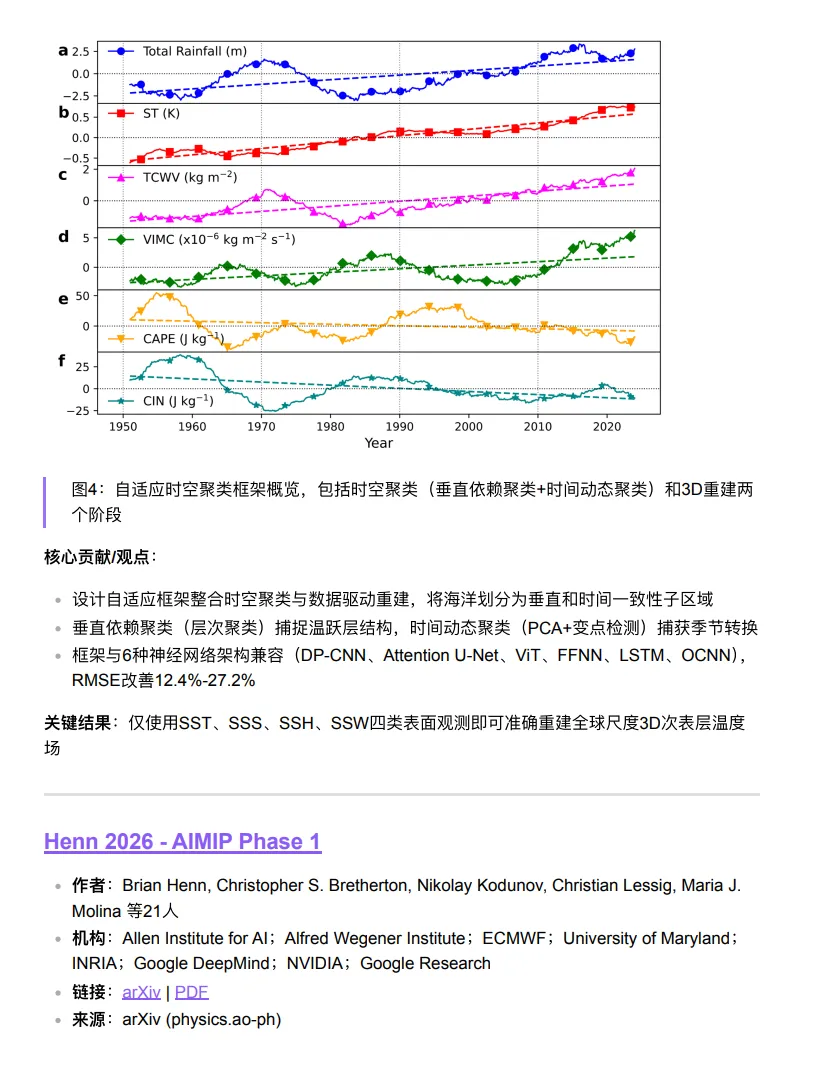
五、常见问题解答
Q1:没有 CNKI 权限怎么办?
A1:CNKI 搜索是可选功能,如果没有权限,可以在配置文件的搜索策略中去掉 CNKI,系统会自动跳过中文搜索,不影响其他功能使用。
Q2:付费墙论文怎么处理?
A2:对于无法下载 PDF 的付费论文,系统会自动跳过图片提取和深度分析,只显示基本信息。你可以手动下载 PDF 后,再调用/paper-analyze [论文ID]生成详细笔记。
Q3:怎么调整评分权重?
A3:目前评分权重可以在search_arxiv.py脚本中修改,后续版本会支持在配置文件中自定义权重。你也可以告诉 AI 你的偏好,让它帮你调整对应的参数。
Q4:生成的笔记不满意怎么办?
A4:你可以:
调整配置文件中的关键词和优先级
增加或减少搜索的论文数量
手动修改生成的笔记内容,系统不会覆盖已有的笔记
六、写在最后
很多人问我,AI 会不会取代科研工作者?我的答案是:不会。但会用 AI 的科研工作者,会取代不会用 AI 的。
这个工作流的核心不是让 AI 替你读论文,而是把那些机械、重复、耗时的工作交给 AI:刷论文列表、筛选相关性、整理基本信息、提取图片。把你有限的精力,留给真正需要人类智慧的地方:理解论文的核心思想、质疑方法的局限性、思考新的研究方向。
目前这个工作流已经在 GitHub 上开源,地址是:https://github.com/ProMonkey-LU/academic-reading-workflow
如果你在使用过程中遇到任何问题,或者有好的改进建议,欢迎在 GitHub 上提 Issue,也欢迎 Star 和 Fork 项目,一起完善这个工作流。
科研的道路漫长而孤独,但好的工具能让我们走得更远。 |
欢迎点赞转发关注,后续会继续更新新的科研工具分享以及读研读博的新的感悟。
愿每一个有趣的灵魂都有处可栖,且挨过三冬四夏,暂受些此痛苦,雪尽后再看梅花。
#科研效率 #论文阅读 #Obsidian #ClaudeCode #自动化工作流 #学术研究
