 夜雨聆风
夜雨聆风摘要:GenericAgent 的重点不是“陪你聊天”,而是让大模型在本地电脑上读文件、跑命令、操作浏览器,并把任务过程沉淀成可复用技能。它很适合工程师做个人自动化和 Agent 研究,但也对环境、安全边界和使用者判断力提出了更高要求。
过去一年,AI 工具越来越像一个分水岭。
一类工具停留在聊天框里,负责回答、生成、解释;另一类工具开始进入本地电脑,尝试读取文件、执行命令、操作浏览器,把任务真的往前推进。
GenericAgent 属于后面这一类。
它的定位很直接:Generic Agent,简称 GA,不是一个聊天机器人,而是一个能替你执行任务的本地 AI 助手框架。它可以读取代码、操作文件、调用工具、连接平台,目标是把事情做完。
看完它的项目实现后,最关注的不是“又一个 Agent 框架”,而是它背后的工程取舍:self-evolving、skill tree、system control、token efficient。项目 README 里反复强调:约 3K 行 seed code、9 个原子工具、约 100 行 Agent Loop。
这几个词放在一起,其实能看出它的取舍。
GenericAgent 不是想做一个大而全的 AI 应用,也不是预置一堆复杂插件。它更像是给大模型一个很小但很关键的执行底座:文件、命令、浏览器、记忆、人类确认。剩下的能力,让 Agent 在使用过程中自己探索、固化、复用。
这里不做宣传式介绍,我更想从工程使用角度聊三个问题:
- 1. GenericAgent 到底是什么?
- 2. 它的优势和风险分别在哪里?
- 3. 如果想试用,应该怎么安装和使用,哪些坑要提前避开?
一、GenericAgent 解决的不是聊天问题,而是执行问题
过去很多 AI 工具的核心入口是对话框。
你问问题,它回答;你让它写代码,它给你一段代码;你让它分析日志,它给你一段判断。这个模式已经很有价值,但在真实工作里,经常会卡在最后一公里。
比如:
- • 它能告诉你某个脚本应该怎么写,但不会自动放到正确目录里执行。
- • 它能帮你分析一个报错,但不会自己去读取项目文件、安装缺失依赖、跑一遍验证。
- • 它能告诉你浏览器里该点哪里,但不会真正基于你的登录态操作页面。
- • 它能总结 SOP,但下次遇到类似任务,还需要你重新把背景喂给它。
GenericAgent 想补的就是这一段。
它把大模型接到本地环境里,让模型可以通过少量工具做真实动作。README 里列了 9 个原子工具:
- •
code_run:执行 Python 或 Shell / PowerShell 代码 - •
file_read:读取文件 - •
file_write:写入文件 - •
file_patch:修改文件 - •
web_scan:读取浏览器页面内容 - •
web_execute_js:执行浏览器 JavaScript 操作 - •
ask_user:向用户确认 - •
update_working_checkpoint:更新短期工作记忆 - •
start_long_term_update:触发长期记忆沉淀
注意,这些工具并不复杂,甚至看起来有点朴素。
但从工程角度看,这种朴素反而是重点。因为大多数自动化任务,底层都可以拆成:看环境、读文件、写文件、执行命令、观察结果、必要时问人、最后把经验记下来。
这也是 GenericAgent 和普通聊天机器人的区别。
普通聊天机器人更像一个“顾问”,GenericAgent 更像一个“可以动手的实习工程师”。它不一定每次都做得对,但它会尝试把任务往前推进。
二、它的几个优势
1. 架构足够小,理解成本相对可控
GenericAgent 一个很重要的特点,是它没有一开始就堆很多抽象。
从代码看,agent_loop.py 的核心逻辑很清晰:模型输出工具调用,Handler 分发工具,工具结果再回填给模型,然后进入下一轮。这个循环并不神秘,但它正是 Agent 能持续执行任务的基础。
很多 Agent 框架的问题是,第一天看起来能力很强,第二天你想改一个行为,发现要理解一堆规划器、执行器、插件协议、消息总线和状态机。
GenericAgent 的路线更接近“先把最小闭环跑通”。
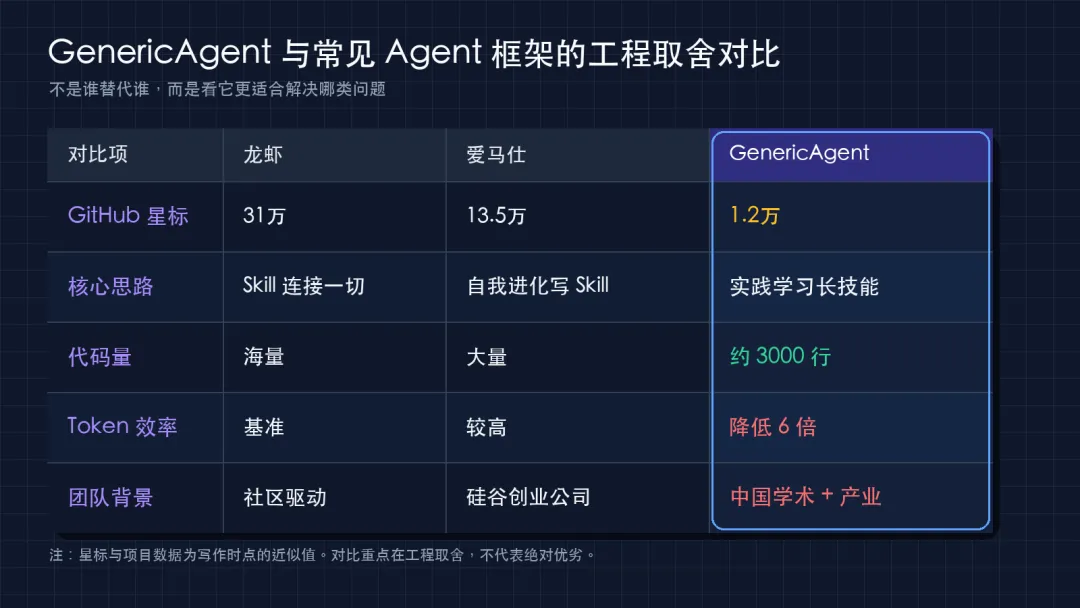
这张图可以辅助理解 GenericAgent 的位置:它不是要在功能数量上和大而全的 Agent 框架硬拼,而是用更少的代码、更少的上下文消耗,换取一个可以在本地持续学习和沉淀技能的执行闭环。
对工程师来说,这个优势很实际:你可以更快判断它为什么做了某个动作,也更容易在需要时改代码、加 Hook、扩展前端或排查问题。
2. 本地运行,适合个人工作流沉淀
GA 是一个本地运行的 AI 助手框架。这个点很重要。
本地运行并不代表数据绝对安全,因为你仍然要把任务上下文发给模型 API。但至少文件操作、脚本执行、浏览器控制、记忆存储都发生在你自己的机器上,可控性比纯云端工具更高。
更关键的是,本地 Agent 更容易接入个人工作流。
比如工程师日常会有很多重复动作:
- • 整理某个项目目录里的文档和脚本
- • 对比配置文件差异
- • 根据日志初步定位故障
- • 把一段排查过程整理成 SOP
- • 从网页后台导出数据并生成汇总
- • 在知识库里按固定格式新建项目记录
这些事情不一定值得专门开发一个产品,但很适合让本地 Agent 辅助完成。
你让它第一次摸索,过程中安装依赖、写脚本、验证结果;如果做得不错,再把过程沉淀成技能或 SOP。下次遇到类似任务,就不用从零开始。
这对个人知识库、自动化脚本库、工作 SOP 的积累很有帮助。
3. 多模型和多前端支持比较灵活
从 mykey_template.py 看,GenericAgent 对模型接入做得很开放。
它支持 OpenAI 兼容接口,也支持 Anthropic Claude 原生接口,还支持 Native 工具调用、Mixin 故障转移、本地模型、各种中转接口。常见的 Claude、GPT、DeepSeek、智谱、Kimi、MiniMax、Ollama、LM Studio 等,都可以按不同方式接入。
这带来两个好处。
第一,用户不被单一模型绑定。你可以用一个强模型做主力,再配置一个便宜或稳定的模型兜底。
第二,Agent 场景本来就对模型稳定性要求高。长任务过程中,一次 429、超时或接口抖动,都可能让体验变差。Mixin 这种自动切换模型的设计,实际使用里很有意义。
前端也类似。仓库里有 Streamlit、TUI、桌面端、Telegram、微信、QQ、飞书、企业微信、钉钉等入口。
这说明它不是只想做一个命令行工具,而是希望 Agent 能进入不同工作场景:电脑前用 TUI 或桌面端,移动场景通过 IM 触发任务,团队场景接企业微信或飞书。
4. “自我进化”这个方向值得关注
GenericAgent 最有辨识度的卖点,是 self-evolving。
我更愿意把它理解为:Agent 在完成任务后,把有效的执行路径、脚本、经验和注意事项沉淀成 Skill / SOP / Memory,下次遇到类似任务可以直接复用。
这不是科幻意义上的“自己变聪明”,而是工程意义上的“把经验固化下来”。
这个方向我很认同。
因为工程效率的提升,很多时候不是来自某一次惊艳的生成,而是来自持续沉淀:
- • 常用命令沉淀下来
- • 排障路径沉淀下来
- • 发布检查清单沉淀下来
- • 项目上下文沉淀下来
- • 失败经验沉淀下来
人是这样成长的,Agent 也应该这样工作。
如果一个本地 Agent 能把“这次怎么做成的”持续记录下来,它就不只是一个消耗 token 的聊天窗口,而会慢慢变成你的个人自动化资产。
三、它的劣势和风险也要看清楚
1. 权限越大,安全边界越重要
GenericAgent 的优势是能动手,风险也来自这里。
它可以执行代码、写文件、修改文件、操作浏览器。这些能力一旦接到真实电脑环境,就不再是“回答错了改一下”这么简单。
可能出现的问题包括:
- • 误删或覆盖文件
- • 安装不必要甚至不可信的依赖
- • 在浏览器登录态下误操作
- • 把敏感文件内容发给模型
- • 长任务中执行了你没有充分理解的脚本
所以使用这类 Agent,我建议先给它一个边界清晰的工作区。
不要一上来就让它操作整个主目录、公司资料目录或生产环境凭证。更稳妥的方式是:准备一个测试目录,把可公开或低敏的数据放进去;涉及删除、移动、大规模修改、登录态操作时,要求它先列计划,再确认执行。
Agent 可以帮我们更快到达答案附近,但最后一公里仍然要靠工程经验验证。
2. 安装配置对新手不算低
虽然官方文档已经给了比较完整的新手安装说明,但从实际配置看,GenericAgent 仍然不是那种“下载即用、无需理解”的消费级工具。
主要门槛在几个地方:
- • Python 版本要注意,官方推荐 3.11 或 3.12,
pyproject.toml也限制了<3.14。 - •
mykey.py配置项很多,变量名还会影响使用哪种 Session 类型。 - • 如果走 Claude 反代、OpenAI 兼容接口、本地模型,
apibase、模型名、工具调用协议都要配置正确。 - • 图形界面、TUI、浏览器插件、IM 机器人,各自还有平台兼容问题。
这不是缺点,而是定位问题。
GenericAgent 更适合愿意折腾工具链的工程师、研究者和重度 AI 用户。如果只是想要一个稳定聊天工具,它可能会显得太复杂。
3. 项目还在快速演进,稳定性需要自己评估
GitHub API 显示,这个仓库 2026 年 1 月创建,到 2026 年 5 月 25 日已经有 12057 个 Star、1390 个 Fork、107 个 Open Issues,最近一次 push 也在当天。
这说明项目很活跃,也说明它还在高速变化。
从 issues 看,TUI 渲染、Windows 兼容、上下文过长、子 Agent、命令路径等问题都有人反馈。对开源项目来说这很正常,但如果你要把它接到日常关键流程里,就要有预期:版本升级可能带来行为变化,某些前端可能比核心能力更不稳定,遇到问题需要自己排查。
我的建议是:
- • 先用于个人非关键任务
- • 固定一个可用版本
- • 重要任务前备份工作目录
- • 让它输出计划和变更列表
- • 修改文件后用 Git diff 或文件对比工具检查
不要把一个快速演进的 Agent 框架,直接当成生产自动化系统使用。
4. “自我进化”不能替代人的判断
自我进化听起来很强,但也容易被误解。
如果一次任务的执行路径本身是错的,它沉淀下来的 Skill 也可能是错的。如果一次网页操作依赖临时 UI,它下次复用时也可能失效。如果某个脚本没有处理异常,它只是被记住了,不代表变可靠了。
所以真正重要的不是“让 Agent 自己记”,而是让它记正确的东西。
这就需要人参与评审:
- • 这个 SOP 是否真的可复用?
- • 脚本是否有边界判断?
- • 是否包含敏感路径或 Key?
- • 失败时有没有回滚方式?
- • 下次执行前是否需要重新确认环境?
Agent 的记忆系统可以提升复用率,但不能替代工程治理。
四、如何安装和启动 GenericAgent
如果只是试用,我建议先按官方文档走最小路径,不要一上来配置所有前端和所有模型。
1. 环境要求
推荐环境:
- • Windows 10/11、macOS 12+ 或现代 Linux
- • Python 3.11 或 3.12
- • Git
- • 一个可用的 LLM API Key
注意:不要使用 Python 3.14。官方文档明确提醒,它与 pywebview 等依赖存在兼容问题。
2. 一键安装方式
官方 README 给的一键安装命令如下。
Windows PowerShell:
powershell -ExecutionPolicy Bypass -c "irm http://fudankw.cn:9000/files/ga_install.ps1 | iex"Linux / macOS:
curl -fsSL http://fudankw.cn:9000/files/ga_install.sh | bash这条路径适合新手,因为脚本会准备隔离环境、下载项目、安装核心依赖。
但从安全角度,我仍然建议你先打开脚本 URL 看一眼内容,确认来源,再执行。任何 curl | bash 或 irm | iex 的安装方式,本质上都是把远程脚本交给本机执行,不能盲目复制。
3. 开发者安装方式
如果你习惯自己管理代码,建议用源码安装:
git clone https://github.com/lsdefine/GenericAgent.git
cd GenericAgent
uv venv
uv pip install -e ".[ui]"
cp mykey_template.py mykey.py
python launch.pyw如果没有 uv,也可以先用普通 Python 虚拟环境,但要保证 Python 版本合适。
比如:
python3.12 -m venv .venv
source .venv/bin/activate
pip install -e ".[ui]"
cp mykey_template.py mykey.py
python launch.pywWindows 下激活虚拟环境的命令不同,可以使用:
python -m venv .venv
.\.venv\Scripts\activate
pip install -e ".[ui]"
copy mykey_template.py mykey.py
python launch.pyw4. 配置 mykey.py
GenericAgent 通过 mykey.py 读取模型配置。
基本步骤是:
- 1. 复制
mykey_template.py为mykey.py - 2. 打开
mykey.py - 3. 填入你的
apikey、apibase、model - 4. 保存后启动 GA
这里有一个容易踩坑的点:变量名会影响 GenericAgent 选择哪种接口协议。
简单理解:
- • 变量名包含
native和claude:走 Claude 原生工具调用 - • 变量名包含
native和oai:走 OpenAI 原生工具调用 - • 变量名包含
mixin:走多模型故障转移 - • 变量名只包含
oai或claude:可能走旧的文本协议
新手可以先选一种官方模板里最接近自己模型服务商的配置,不要同时打开太多配置。能跑通一个,再考虑主备切换。
如果只是 OpenAI 兼容接口,可以参考这个最小结构:
native_oai_config = {
"name": "gpt-native",
"apikey": "sk-你的密钥",
"apibase": "https://api.openai.com/v1",
"model": "你的模型名",
"max_retries": 3,
"read_timeout": 120,
}如果使用的是第三方兼容接口,把 apibase 和 model 改成服务商要求的值。
不要把 API Key 写进截图、公开仓库、聊天记录或任何会外传的内容里。
五、第一次使用建议
安装完成后,不要急着让它做复杂任务。
先从低风险任务开始验证:
请在当前目录创建一个 hello-ga.txt,内容是 Hello GenericAgent,然后读出来确认。然后测试文件读取:
请读取当前目录的 README.md,总结这个项目的启动方式,不要修改任何文件。再测试依赖安装和环境检查:
请查看你的代码,列出运行 UI 需要的 Python 依赖。先只列计划,不要安装。确认行为符合预期后,再让它安装依赖:
请查看你的代码,安装所有用得上的 Python 依赖。安装前先说明会执行哪些命令。如果你想让它建立 Git 连接,可以用这个提示词:
请帮我建立 git 连接,方便以后更新代码。如果你想创建快捷方式:
请帮我在桌面创建一个 launch.pyw 的快捷方式。如果要启用浏览器能力,可以先让它解释方案:
请查看 web setup SOP,告诉我启用浏览器控制能力需要哪些步骤。先不要执行。这类工具的正确打开方式,不是“我说一句你立刻执行”,而是“先计划、再确认、再执行、最后验证”。
六、适合谁,不适合谁
我认为 GenericAgent 适合这几类人:
- 1. 运维开发、平台工程、后端工程师
经常处理脚本、日志、配置、文档、项目目录,能判断 Agent 的输出是否靠谱。 - 2. AI 工具重度用户
不满足于聊天问答,希望把 AI 接入本地文件、浏览器、命令行和个人工作流。 - 3. 想研究 Agent 架构的人
它的最小工具集、Agent Loop、记忆分层、自举能力,都值得拆开看。 - 4. 愿意沉淀个人 SOP 的人
如果你有知识库、脚本库、项目复盘习惯,GA 的 Skill / Memory 思路会比较契合。
不太适合这几类场景:
- 1. 完全不想折腾环境的普通用户
模型配置、Python 环境、前端选择、插件启用,都可能成为门槛。 - 2. 高敏感数据或生产环境直接操作
除非你已经建立权限隔离、审计、备份和确认机制,否则不要让 Agent 直接碰核心资产。 - 3. 要求强稳定性的企业级流程
目前更适合试验和个人自动化,不适合未经治理就接入关键链路。 - 4. 只想要一个聊天助手的人
如果需求只是问答、写作、翻译,直接用成熟聊天产品更省心。
七、我的使用原则
如果我自己试 GenericAgent,会按这几个原则来:
第一,先放在单独目录里跑,不给全盘权限。
第二,所有写文件、删文件、移动文件、执行安装命令的动作,都要求先列计划。
第三,重要目录必须有 Git 或备份。让 Agent 修改后,用 diff 检查。
第四,不把公司密钥、生产凭证、私有客户数据直接交给它处理。
第五,把它当作“能执行的助手”,不是“可以放任的自动驾驶”。
第六,真正有价值的任务,要让它沉淀成 SOP,但沉淀前要人工审一遍。
做到这些,GenericAgent 的价值会更容易发挥出来,风险也更可控。
结尾
GenericAgent 让我感兴趣的地方,不是它又接了多少模型,也不是它能控制多少平台,而是它把一个问题重新摆在工程师面前:
AI 工具到底应该停留在回答层,还是进入执行层?
如果进入执行层,我们就不能只关注模型聪不聪明,还要关注权限、环境、验证、回滚、记忆和 SOP。
GenericAgent 给了一个很轻量的答案:用少量原子工具打通本地执行闭环,再让能力在真实任务中沉淀出来。
这个方向值得关注。
但它不是银弹。它更像一把锋利的工程工具。用得好,可以帮你把重复工作变成自动化资产;用得草率,也可能把本地环境搞乱。
所以我的建议是:可以试,但别神化。先在低风险场景里跑起来,观察它怎么计划、怎么执行、怎么验证,再决定要不要把它接入更重要的工作流。
AI 可以帮我们更快地动手,但工程师仍然要负责判断:哪些事情可以交给 Agent,哪些事情必须自己把关。
