 夜雨聆风
夜雨聆风如果你已经把 Codex、Claude Code、Cursor 放进真实仓库,不再只是让它们写 demo,这个问题迟早会碰到。
红测试不吓人,错误摆在桌面上。更麻烦的一种 diff,是测试全绿,接口也能返回数据,往下翻才发现:控制器里直接拿了数据库客户端,自己拼了一段查询。项目原来所有数据访问都走数据访问层,那一层顺手做了租户隔离、软删除过滤和权限判断。agent 没改那里,它从旁边开了一条小路。
这一刻你很难说它“没完成任务”。接口确实通了,字段也有,短测也过。可你知道这段代码合进去以后,下一次改权限、改列表、改删除逻辑,都会多一个地方要记住。
后端 agent 最麻烦的地方就在这里:它可能没有写错答案,却沿着一条项目里本来不存在的路写出了答案。
最近有篇论文专门测了这类问题,里面有个任务很像这种 PR。论文把这种现象叫 constraint decay,可以粗略理解成“约束衰减”:项目规则变多以后,agent 会开始漏规则。漏掉的常常不是语法层面的东西,而是后端项目里那些靠目录、封装、框架习惯和团队约定撑起来的暗线。
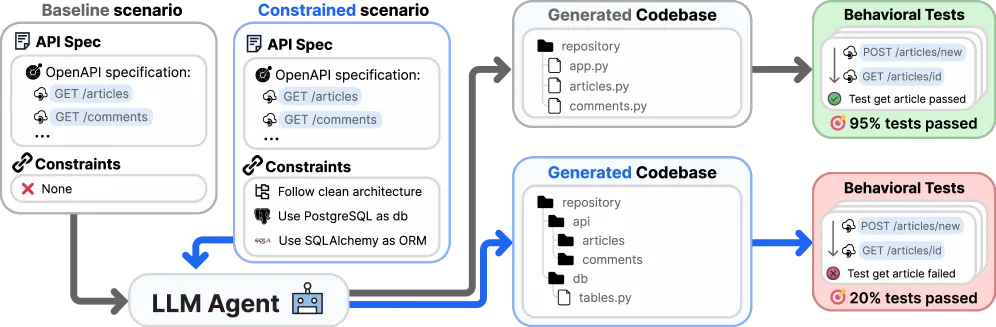
论文里的 constraint decay 示意:同一套 API 需求,加上结构约束后,agent 的通过率会明显下滑。
绿的是结果,不是路径
前面那个 diff 为什么能过测试?
因为很多测试只站在接口外面看。请求打过去,返回 200;列表里有数据;新增之后能查到;删掉以后再查不到。对一个 API 来说,这些都很重要,但它们只证明“外面看起来对”。
后端项目很多麻烦都藏在调用链里。请求进来以后,哪一层接住,哪一层查数据,哪一层判权限,事务在哪里打开,ORM 的封装有没有绕过去。人写久了会把这些当成手感,review 的时候一眼能闻出来哪里不对;agent 不一定闻得出来。
它看到的是“给我加一个评论接口”。为了尽快让接口返回正确 JSON,它可能直接在路由里写查询,或者绕过项目已有 helper,或者复制一段看起来差不多的代码再改几个字段。最顺的那条请求能跑通,问题就暂时藏住了。
藏住不等于不存在。租户过滤漏了,第一批测试数据也许刚好看不出来;软删除条件少了,等线上有旧数据才冒出来;ORM 关系加载方式不一样,今天只查一层没事,后面一加分页、一加权限、一加缓存,就开始互相咬。
看 agent 写后端,光问“它有没有把接口做出来”不够。还得问一句:它是从哪条路做出来的?
把评论接口当成一场 review
那篇论文用一个博客 API 做测试,里面有用户、文章、评论、个人资料、标签,项目名叫 RealWorld Conduit。一个 Express 任务里,评论功能被拿掉了:路由注册、控制器、Prisma schema、校验中间件等,总共 245 行,散在 10 个文件里。
现在 agent 交回来一个 PR。你打 /articles/:slug/comments,能发评论,返回 200。这个时候还不能停。
打开路由文件,先找那条新增的评论路径。它挂在原来的认证中间件后面,还是自己新注册了一条看起来能用的路径?
翻到控制器,留意有没有直接出现数据库客户端、ORM model、裸 SQL。项目原来如果有服务层和数据访问层,控制器里直接查库就该停一下。
再看 schema。评论和文章、用户的关系有没有补回去?删文章、删用户、软删除这些状态,会不会留下孤儿数据?
最后看校验。参数校验和权限检查有没有走原来的中间件?没登录的人、没权限的人、文章不存在的人,会不会因为新代码少走了一层而混过去?
这几步都很朴素,刚好也是论文要测的东西。它没有只看评论接口能不能返回,而是把登录、权限、删除、异常状态都打了一遍;整套检查有 32 个请求、291 条断言。另一边,代码也要看有没有绕过分层、数据库和 ORM 的要求。从“只给少量约束”到“把项目规则补全”以后,表现较好的 agent 配置,断言通过率平均少了约 30 个点。作者还做了对照:就算不把“结构没守住”直接判成零分,只看接口行为,下降幅度也差不多。
结构不是表面风格。评论接口接错了位置,后面查列表、换身份、删文章时,功能也会开始漏。
坏账常藏在数据层
论文的失败分析里,约 71% 是逻辑错误。服务能启动,路由也注册了,请求真的打进去以后,行为不对。
评论接口里,最该盯的是数据层。常见问题并不玄:查询条件写错,关联查询写错,该过滤的没过滤,数据库方言里的操作符用错;有的看起来思路没错,运行时撞在 ORM API 或 session 规则上;还有认证头解析、状态写入后读不出来、框架默认行为没处理。
回到评论接口,少返回一个字段通常很快就能补。更烦的是它查评论时没带文章状态,删掉的文章还能继续收评论;它查列表时没带租户条件,测试库里看不出来;它新写了一条查询,没有走项目原来封装过的权限过滤。
这些 bug 都很日常。最拖慢人的,是代码位置乱了。人犯这种错时,reviewer 常常能顺着项目习惯追过去;agent 犯这种错时,它会把代码散落到一条新路径上,让 reviewer 多花一轮时间确认它到底绕过了什么。
agent 当然可以写后端。用它写后端时,最该盯的是数据流和权限流有没有按原项目的路走。它要是只在接口表面答对,后面的维护成本会悄悄转嫁给人。
旧路烂,也要单独处理
有些 PR 不值得这么重地查。
一次性脚本、内部小工具、原型 demo,只要测试覆盖了主要输入输出,后面也没有长期维护,就别把验收做得太重。工具本来就是为了省时间,不能每次都把人拖回手工审判。
还有一种灰区更烦:项目里的旧路本来就烂。比如评论本来该走 commentRepository,但这个文件里已经塞满了文章、通知、审核状态和历史兼容;helper 名字叫 findVisibleComments,实际只过滤了软删除,没过滤权限。agent 绕开它新写查询,不算好代码,但它暴露出来的可能是项目债。
这时不能只靠一句“必须走旧路”拍死。要么把这次改动收回旧路里,并补上会漏的测试;要么承认旧路需要重构,把它当成一次单独的重构,别混在“加评论接口”这个小任务里偷偷合掉。
论文里不同 Web 框架的结果可以留个心眼,但别读成框架排名。在这篇论文的这组任务里,Express、Koa、Flask 排得靠前,Django、FastAPI、Hono 掉得更明显。review 时更该问具体一点:这个项目的路由、校验、ORM、自动发现,哪些地方靠约定在工作?agent 有没有接到这些约定上?
Review 先抓路径
项目文档、AGENTS.md、CLAUDE.md 这些文件,别只写“保持风格一致”。这句话对人都嫌空,对 agent 更空。
可以写得土一点:新增接口要从路由进服务层,再到数据访问层;路由层不能直接 import 数据库连接;新增查询必须使用已有 ORM helper;交付时说明这次改动碰过哪些层,有没有绕过原来的数据访问方式。
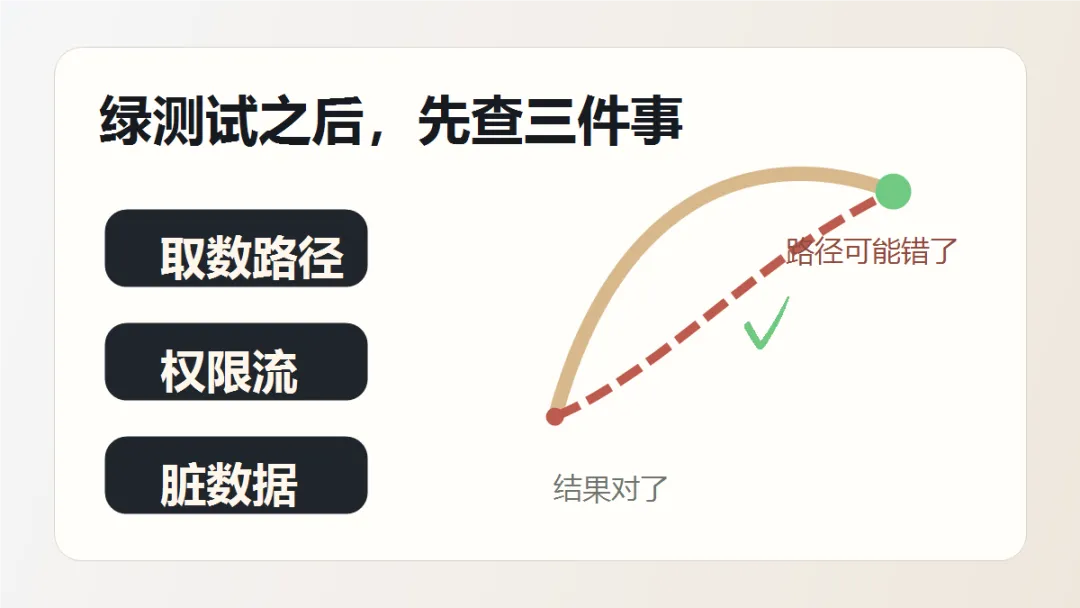
绿测试之后,先查取数路径、权限流和脏数据。
到 review 时,我会先打开改动文件看 import。路由或控制器里如果直接出现数据库连接、ORM model、裸 SQL,就先停一下。再去找项目里相邻功能怎么写,评论看文章接口,新增看删除接口,列表看详情接口。agent 写出的新路径,得和旧路径对得上。
然后用脏一点的数据补测试:另一个租户、一条软删除记录、一个没权限的用户、一个已经删除的父文章。只用干净数据验出来的绿色,最容易骗过人。
最后别急着问 agent “完成了吗”。先让它把取数路径说清楚:数据从哪里来,中间经过哪几层,有没有绕过旧封装;再让它说这个需求下周变复杂时,哪一段最先坏。
测试绿了,只说明接口表面答对了一次。后端代码还要看它沿着哪条路答对。路错了,答案越绿,后面越麻烦。
参考材料:
Francesco Dente, Dario Satriani, Paolo Papotti, Constraint Decay: The Fragility of LLM Agents in Backend Code Generation: https://arxiv.org/abs/2605.06445EURECOM publication page: https://www.eurecom.fr/en/publication/8745 Andreas Rau, Agentic Coding Paper of the Day - May 13, 2026: https://andreasrau.tech/writing/agentic-coding-paper-2026-05-13
