 夜雨聆风
夜雨聆风扣子编程让普通人10分钟造出AI应用,华为韬定律让芯片绕过摩尔定律的墙,DeepSeek V4则把这两个故事焊在了一起。
一、一个不会写代码的人,10分钟做了个AI助手
2025年12月,字节跳动旗下扣子(Coze)上线了一个叫"氛围编程"(Vibe Coding)的功能。
你不用写一行代码,不用懂什么API、什么工作流,只需要用中文说:
"帮我做一个竞品监控助手,每天自动搜索行业新闻,整理成SWOT分析,推送到飞书群。"
扣子就能自动生成一个完整的AI智能体——搜索、分析、排版、推送,全链路打通。

这不是PPT演示,是真实可用的产品。
扣子的2026年版本已经集成了1000+插件,支持AgentPlan意图驱动编程、AgentSkills模块化能力封装,做好的智能体一键发布到微信、飞书、抖音、小程序。个人用户免费额度足够日常使用,企业版支持私有化部署。
从"人人可用AI"到"人人可造AI"——这个门槛的降低速度,比大多数人想象的要快得多。
智联招聘的数据:2026年春节后,AI智能体相关职位数同比增速455%,初级智能体开发工程师年薪40-60万。
当编程不再是程序员的专利,AI的能力需求就会呈指数级膨胀。 每一个"10分钟做出来的AI助手"背后,都是百万级Token的消耗、是大模型的实时推理、是对算力的无底洞般的渴求。
于是问题来了:算力从哪来?
二、摩尔定律走到尽头,谁来接棒?
过去60年,半导体产业只做一件事:把晶体管做小。
1965年,戈登·摩尔提出那条著名的定律——芯片上的晶体管数量大约每两年翻一倍。从90nm到28nm,从7nm到3nm,"几何缩微"的路线跑了半个世纪,把人类从打字机送到了ChatGPT。
但这条路,快走不通了。
物理极限:到了2nm、1nm,一个原子就是一个台阶。量子隧穿效应让电子"穿墙漏电",漏电流越来越大,功耗散热成了噩梦。
经济极限:一座3nm晶圆厂动辄200亿美元,全球玩得起的玩家从几十家缩到三四家。先进节点的每晶体管成本不再下降,甚至开始上升。
供应链极限:对中国企业来说,还有一层——先进光刻设备获取受限。继续假设"下一个节点会解决问题",已经不现实了。
一边是AI对算力指数级的饥渴,一边是芯片微缩的边际收益急剧递减。这个剪刀差,就是整个行业必须回答的根本问题。
2026年5月25日,华为给出了自己的答案。
三、韬(τ)定律:不再死磕"几纳米",而是让信号跑得更快
在上海举行的IEEE国际电路与系统研讨会(ISCAS 2026)上,华为董事、半导体业务部总裁何庭波发表主旨演讲,正式提出"韬(τ)定律"。
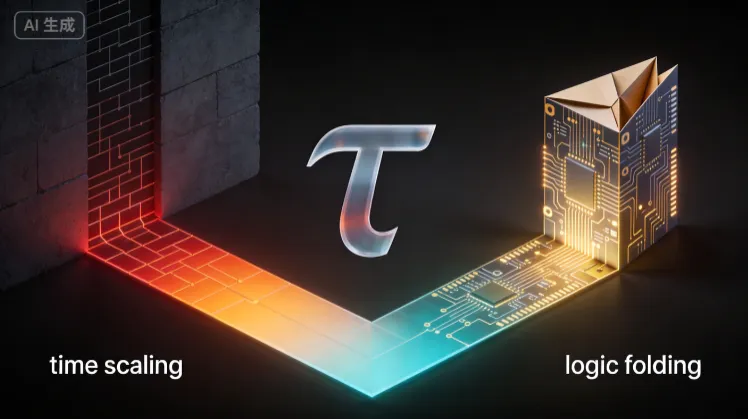
这是中国在全球半导体领域首次提出指导产业发展的新原则。
"韬"不是某个人的名字,而是电路理论中的时间常数τ(希腊字母tau)。
简单说:τ = 电阻 × 电容。它代表信号在芯片里从0变到1(或从1变到0)所需的切换时间。τ越小,芯片越快。
过去50年,降低τ的方法是缩小晶体管——晶体管小了,电阻电容跟着小,τ自然降。但到了3nm以下,晶体管自己的延迟已经极小,反而是连接晶体管的导线被迫做得越来越细,内阻反而升高,τ反而变大。
摩尔定律赖以运行的底层逻辑——"做小就能变快"——失效了。
韬定律的核心转变是:以"时间缩微"替代"几何缩微" 。不再死盯着把晶体管做更小,而是通过系统性地压缩信号传播时延,来实现同等的性能提升。
打个比方:不是扩建马路(几何缩微),而是优化红绿灯、修高架桥、设置潮汐车道,让交通流更顺畅(时间缩微)。
实现这个目标的关键技术,叫逻辑折叠(Logic Folding) 。
传统芯片的电路布局是二维平面的,信号在平面上绕来绕去。逻辑折叠把电路从"一层楼"扩展成"多层楼",把原本需要长距离横向走线的关键路径"折"起来,纵向叠放,大幅缩短信号传播的物理距离。
而逻辑折叠只是韬定律四层级体系中的一环。华为构建了贯穿器件→电路→芯片→系统的协同优化体系:
- 器件层
:优化晶体管和互连的电阻、寄生电容 - 电路层
:逻辑折叠突破平面布局的物理边界 - 芯片层
:全栈"软件+架构+芯片"协同设计 - 系统层
:定义"灵衢总线",重构互联协议,实现超节点统一内存编址
何庭波透露:过去六年,华为已基于韬定律设计并量产了381款芯片。今年秋季,新一代麒麟芯片将完整采用逻辑折叠技术,预计到2031年,基于韬定律的高端芯片晶体管密度将达到1.4纳米制程的同等水平。
这意味着:不完全依赖EUV极紫外光刻机,也有机会达到国际先进性能。
何庭波的原话是:"我们的解决方案走得通,走得远。我们新芯片的性能完全可以持续对标另外一条路径。"
四、DeepSeek V4:国产算力不是"备胎",而是"另一条路"
韬定律画出了芯片演进的蓝图,但蓝图需要验证。

2026年4月24日,DeepSeek V4给出了第一份答卷。
V4发布时,最让产业界紧张的,不是1.6万亿参数的V4-Pro,不是100万Token的标配上下文,而是技术报告里一句话—— "我们验证了细粒度EP方案在英伟达GPU和华为昇腾NPU双平台上的表现。"
这是全球顶级大模型首次将华为昇腾芯片与英伟达GPU并列写入硬件验证清单。
这不是象征性的"兼容"勾选。DeepSeek团队为此投入了约30人年的工程量,重写了200多个核心CUDA算子,跑了10万多个测试用例做精度对齐,产品发布推迟两个多月专门完成移植。最初移植版本性能只有目标的1/35,最终优化到持平。
结果:
昇腾950PR单卡推理性能达到英伟达H20的2.87倍 推理延迟较前代降低35% 单机算力成本较英伟达方案下降40% V4-Flash后训练在昇腾上完成,证明昇腾具备承接主流大模型后训练任务的能力 V4-Pro API价格永久降至原价的1/4,输入最低0.025元/百万Token
V4采用的FP4精度格式,恰好是昇腾950芯片原生支持的精度。昇腾950的FP4算力1.56P,卡间互联带宽2TB/s——V4在昇腾上的运行不是"勉强能跑",而是原生友好。
发布24小时内,寒武纪、海光、摩尔线程等8家国产芯片厂商完成推理适配。华为云、腾讯云同步上线昇腾版V4 API服务。
5月22日,国家发改委正式发声:将指导国产大模型加大力度适配国产算力芯片。
英伟达CEO黄仁勋在近期播客中说了一句话:"如果顶尖的AI模型被优化在华为芯片上运行,对美国而言将是'可怕的后果'。"
他担心的,正是这件事。
当然,清醒地看,差距仍在:预训练仍依赖英伟达H800/H100,CANN算子覆盖率约92%,多卡互联带宽仍落后于NVLink。从"能推理"到"能训练"到"能全面替代",还有路要走。
但方向已经验证:国产算力不是退而求其次的备胎,而是另一条可行的路。
五、三个故事,一条线
回到开头——
扣子编程降低了AI应用的创造门槛,普通人10分钟能造出AI助手。但这意味着千行百业对算力的需求将从涓涓细流变成洪流。
华为韬定律打开了芯片演进的新路径:不依赖无限缩小晶体管,而是让信号跑得更快。预计到2031年达到1.4nm等效水平。
DeepSeek V4则把"新路径"和"新需求"焊在了一起:全球顶级大模型在国产芯片上跑通了,而且跑得还不错。
三个故事,一条逻辑线:
AI能力爆发 → 算力需求爆炸 → 摩尔定律见顶 → 韬定律开新路 → "国模+国芯"闭环验证
这不是三个孤立的热点,而是中国AI产业在2026年同时突破"软件"和"硬件"两个瓶颈的集中体现。
何庭波说:"未来一定属于开放合作。"
黄仁勋说:"如果顶尖模型在华为芯片上跑得更好,那将是可怕的后果。"
两种立场,指向同一个事实:这场关于算力的竞争,格局已经变了。
参考资料:
- 华为正式发表半导体领域新定律,人民日报客户端,2026.05.25
- 华为提出「韬定律」,寻找国产芯片自己的进化方向,36氪,2026.05.25
- DeepSeek-V4 旗舰模型技术深度报告,CSDN,2026.05.22
- DeepSeek-V4+昇腾——国产AI基础设施的破局之战,CSDN,2026.05.23
- DeepSeek V4验证华为昇腾950:国产AI芯片的供应链大考,网易新闻,2026.05.21
- DeepSeek V4 × 华为昇腾:国产AI算力推理适配的实质性进展,51CTO,2026.05.19
- DeepSeek V4发布后没人统计过的那一栏数字,风远科技,2026.05.24
