 夜雨聆风
夜雨聆风——CareerPilot 调用链路全流程解析:从文件上传到 OCR 识别结果返回
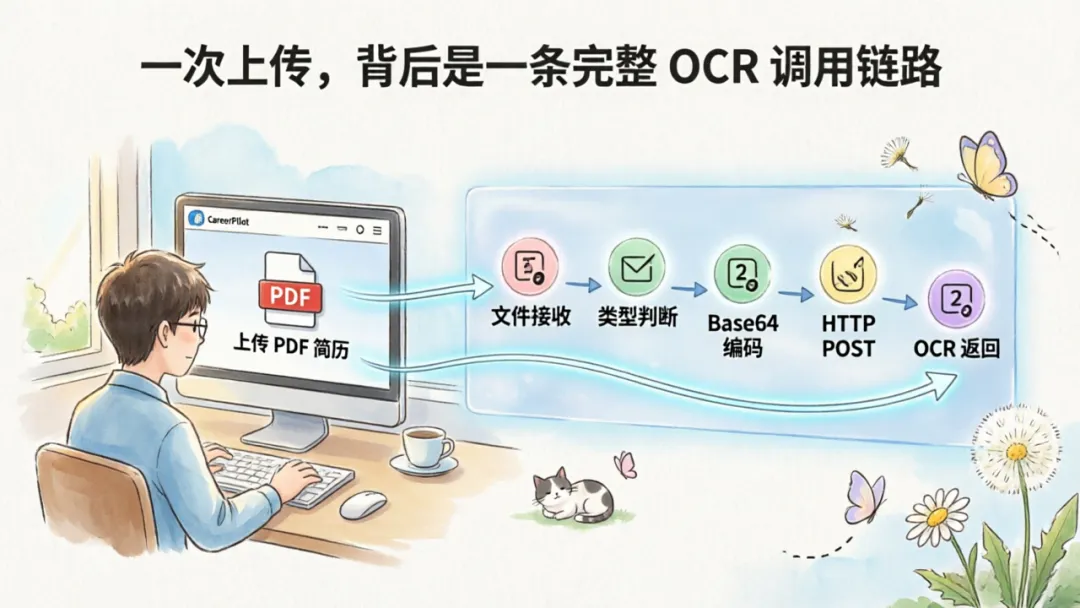
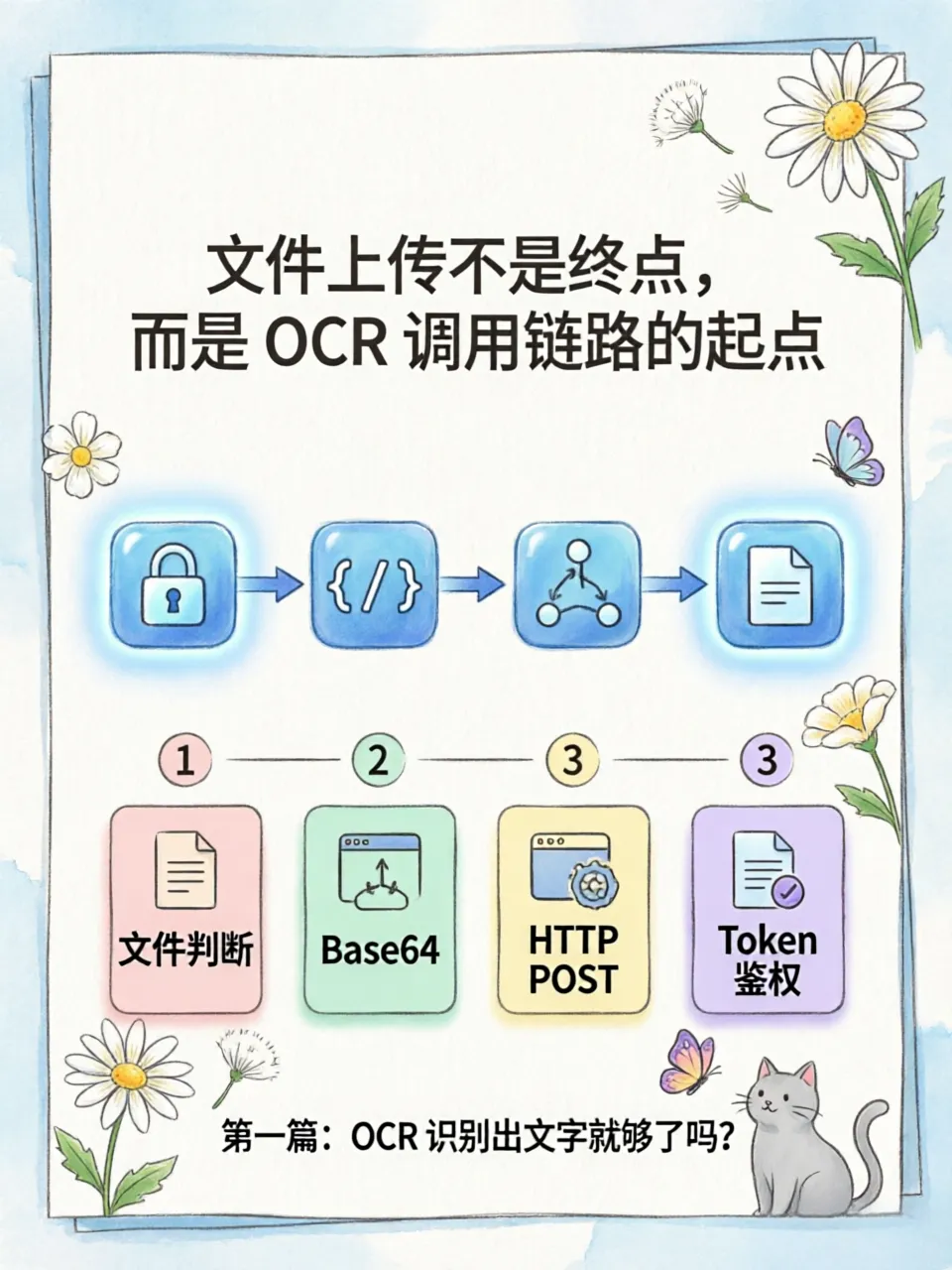
用户看到的只是"上传一份 PDF 简历",但在 CareerPilot 后端,这个动作会触发一整条材料解析链路。系统不是简单保存文件,而是要把文件变成 PaddleOCR 服务能够识别的请求,再把 OCR 返回结果传给后续画像模块。
💡 Tips:CareerPilot(职路领航)我们的项目已在 GitHub 里开源,欢迎大家的共建!🔗 点击下方链接直达仓库:👉 https://github.com/Thalia325/careerpilot
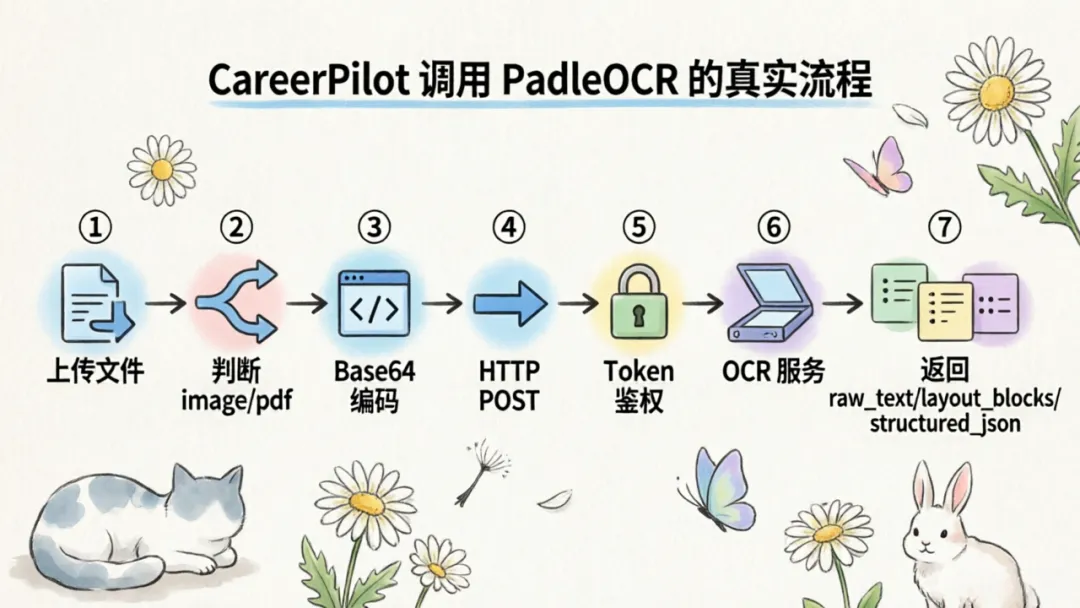
CareerPilot 调用 PaddleOCR 的流程可以概括为:
• 学生上传材料 → 后端接收文件
• 判断文件类型 → 读取文件内容
• 转为 Base64 字符串 → 构造 HTTP POST 请求
• Authorization: token <api_key> 鉴权
• 调用 OCR 服务 → 接收 OCR 返回结果
• 进入后续结构化处理
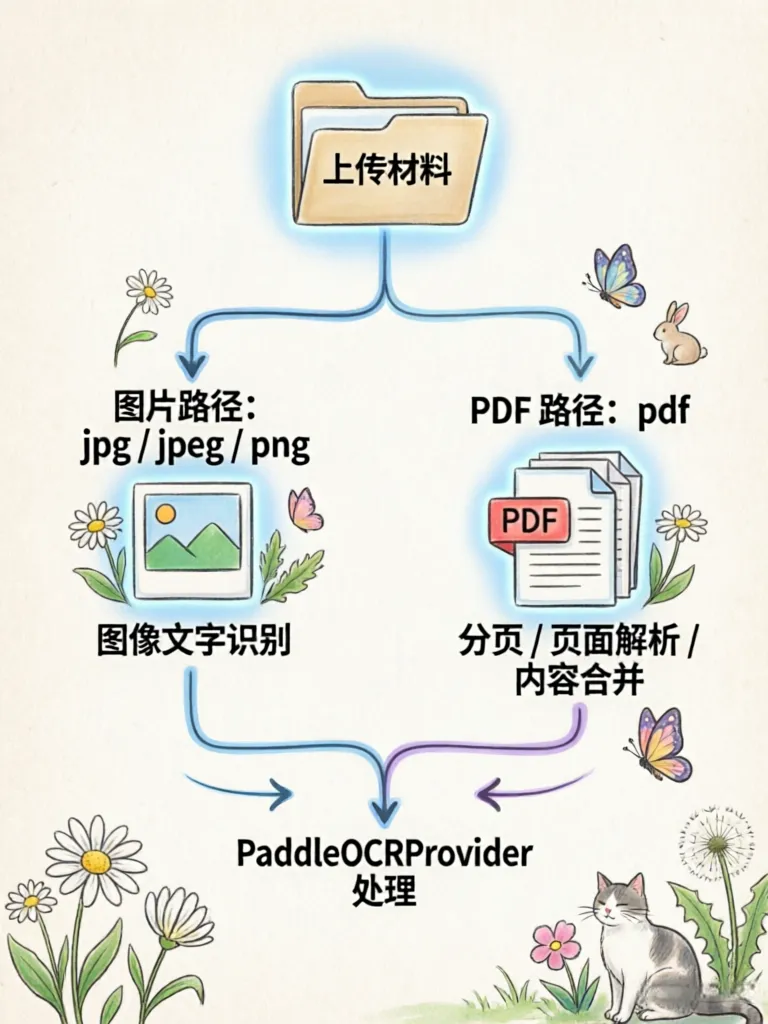
CareerPilot 会根据文件后缀判断处理路径:
• .jpg / .jpeg / .png → image
• .pdf → pdf
图片材料通常走图像文字识别流程;PDF 材料可能涉及分页、页面解析或内容合并。因此,文件类型判断是决定后续 OCR 处理路径的第一步。
PaddleOCRProvider 的载荷特点是把文件内容转成 Base64 字符串:
{ "file": "base64字符串" }
这样做方便放入 JSON 请求体,统一图片和 PDF 的传输方式,便于接口标准化,也降低 multipart 处理复杂度。
但也要注意:Base64 编码后文件体积会变大,因此正式部署时要关注上传大小限制和请求超时。
OCR 请求需要传输文件内容,数据量可能较大,所以 CareerPilot 使用 HTTP POST 调用 OCR 服务。这一步可以理解为:
• CareerPilot 后端构造 OCR 请求 • POST 到 PaddleOCR 服务 URL • OCR 服务解析文件,再返回识别结果
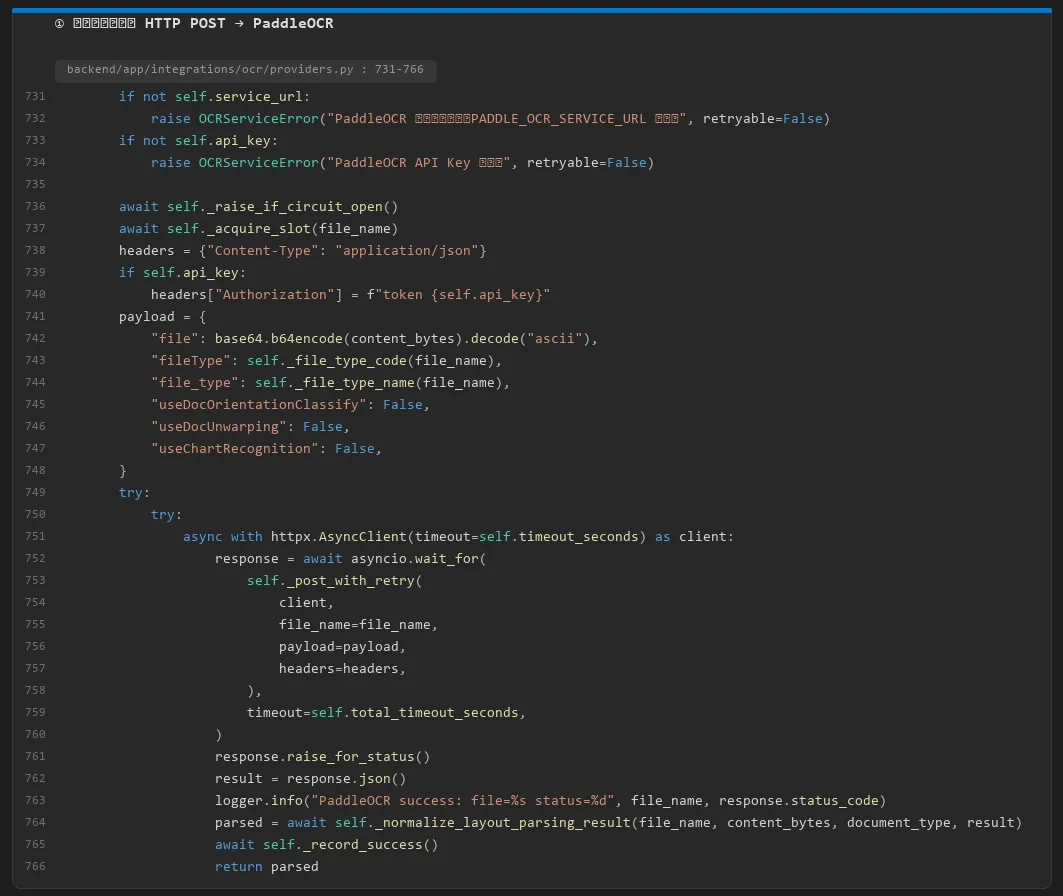
构造请求并发送 HTTP_POST 到 PaddleOCR
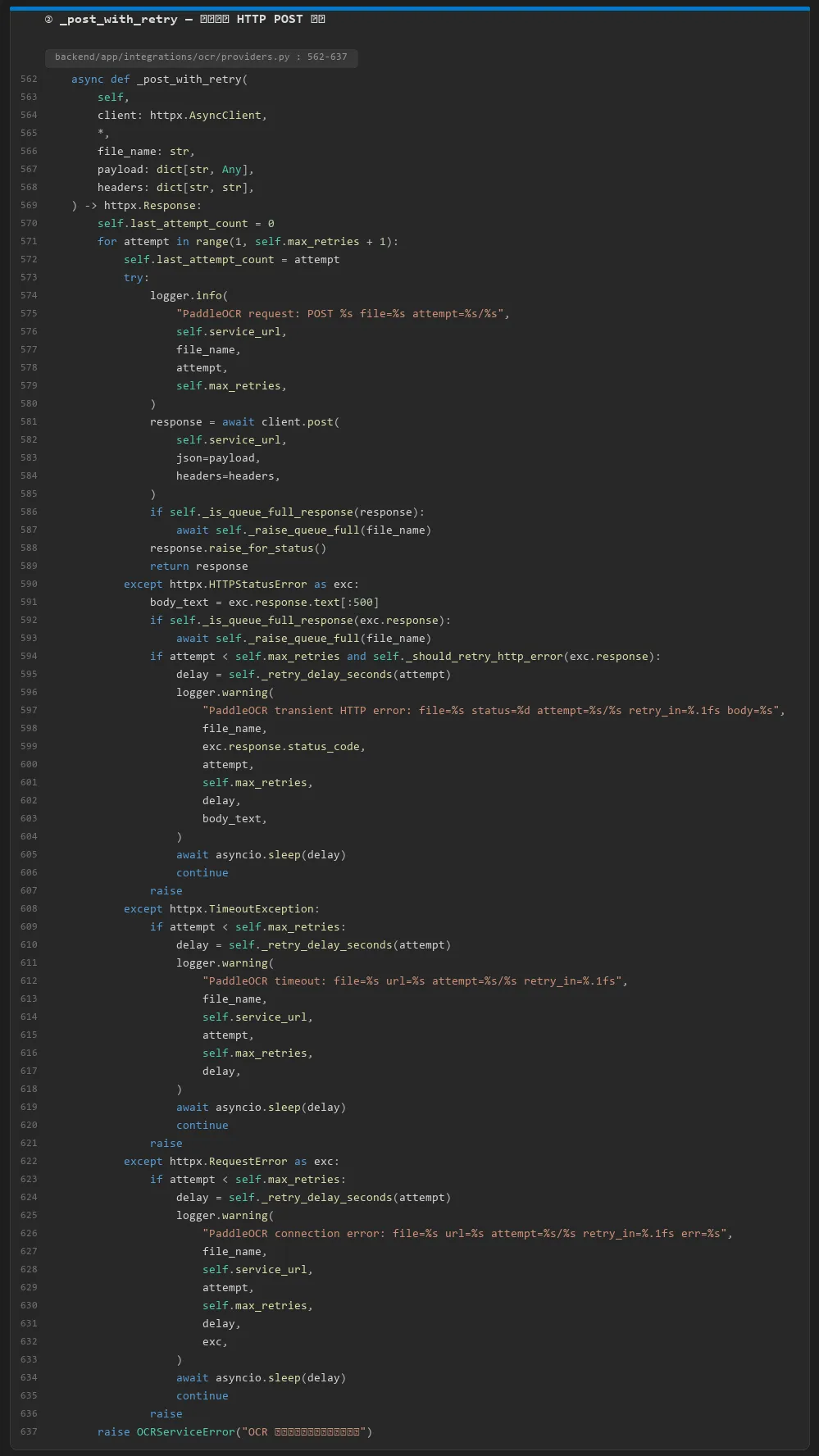
post_with_retry:带重试的 HTTP_POST 调用
请求头中使用 Authorization: token <api_key>。这说明 CareerPilot 调用 OCR 服务时不是裸调接口,而是通过 API Key 完成认证。
这样可以:
• 防止未授权调用
• 控制 OCR 服务访问权限
• 支持调用限流和安全审计
• 避免 OCR 服务被滥用
CareerPilot 不是把学生文件直接交给大模型,而是先通过 PaddleOCRProvider 完成标准化识别调用,再把结果交给后续模块。
💬 互动:你觉得文件上传链路里最容易出问题的是哪一步:文件格式、网络调用,还是接口鉴权?欢迎评论区讨论!
🌟 Star 我们的项目:👉 https://github.com/Thalia325/careerpilot
