 夜雨聆风
夜雨聆风作者: Rahul (@sairahul1)
日期: 2026年5月25日
来源:How to Build a Software Factory with Claude Code That Ships Features While You Sleep
有很长一段时间,我都以为自己在用 AI 写代码。
后来才想明白:我不过是打字打得更快了而已。
这两件事看着像,其实差得很远。今天我想把这中间的区别讲清楚,顺便讲讲那个让我彻底改观的「7 智能体系统」。
值得收藏,它大概能帮你少走好几个月的弯路。
先说一个没人愿意聊的问题
事情是这样的。有一种工作循环,看着特别高效,可你做久了就会发现,它其实是在原地打转:
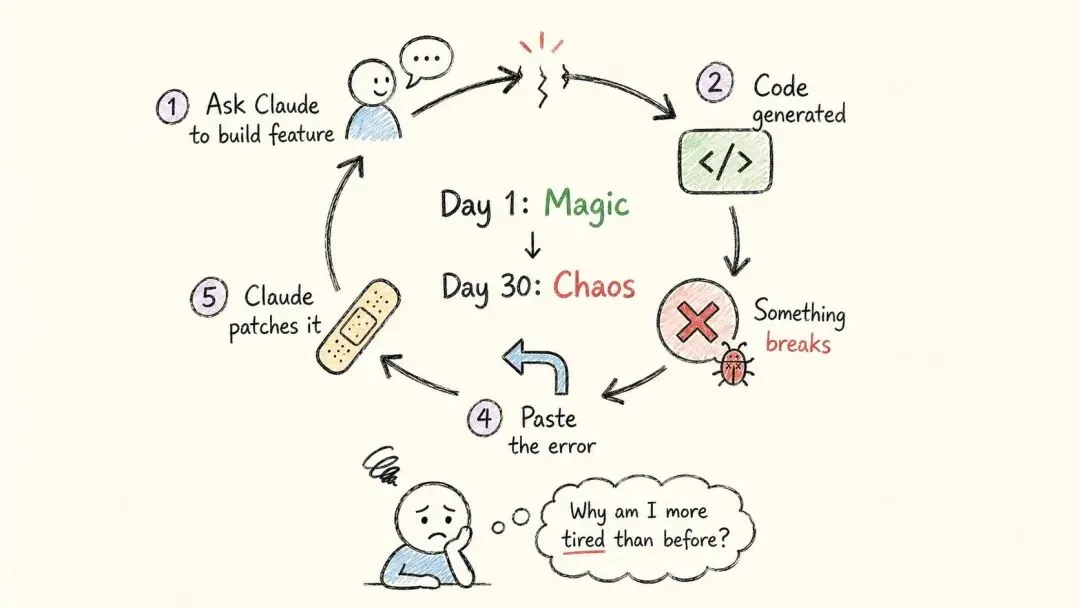
你让 Claude 做个功能,它生成一段代码;某处坏了,你把报错贴回去;它打个补丁,结果别处又坏了;你再问一遍……如此往复。
刚开始那天,这感觉简直像变魔术。
可到了第 30 天,你会发现一件让人有点泄气的事:盯着 AI 干活的时间,居然比当初自己动手写还多。
更糟的是那些细节。同一段逻辑,它在三个地方各写了一遍;两周前你定下的规矩,它早忘得一干二净;新功能一上,旧功能就跟着坏;测试要么没有,要么浅得跟没有一样。
直到某天你忽然回过神来——问题不在 AI。
问题在你的工作流。
说到底,这是个结构上的毛病。你在 Claude Code 里敲下「做这个功能」的时候,其实是在要求同一个 AI 会话,一个人同时干六个人的活:
产品分析师、架构师、后端工程师、前端工程师、测试工程师、代码评审——六个角色,全挤在同一个乱糟糟的对话里。
这就有意思了。你想想会发生什么:计划里有个错误假设,它就变成了错的数据库模型;错的模型,又变成了错的 API;错的 API,再变成错的界面。一环扣一环,等你终于察觉的时候,这个错已经悄悄铺满了整个项目。
这种干法,现在有个名字,叫 vibe coding——凭着感觉写代码。
它有个上限,你怎么使劲都顶不破。
真正的转折:从「凭感觉」到「开工厂」
那到底是什么改变了一切?是下面这个想法:
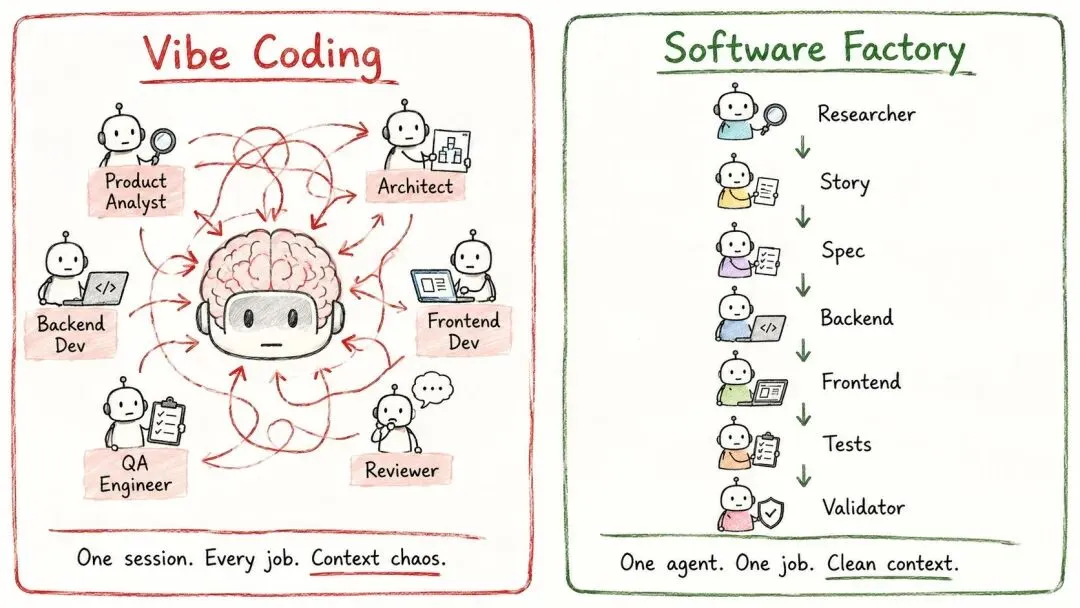
你回想一下真正的工程团队是怎么干活的——从来不是一群人挤在一个大对话里。而是各管各的:有人负责把用户的问题问清楚,有人琢磨架构,有人写 API,有人做界面,有人专门想那些边边角角的情况,还有人负责评审。
问题就在这里。你把这么多角色全压进一个 AI 会话,错误就会在你看不见的地方一点点累积。
那解法其实很朴素:把这些活,拆给一个个专门的智能体去做。
每个智能体,只拿到四样东西——一件聚焦的活,一块干净的、只属于它自己的上下文,它真正用得上的那几样工具,外加几条「什么绝对不能碰」的硬规矩。
这么一拆,你手里就有了一座软件工厂。
一个开发者,加上七个各司其职的智能体,凑成的就是一支配合默契的团队。
下面就把这七个智能体,一个一个讲给你听。
七个智能体
一号:代码库研究员
很多人用 AI,犯的第一个错误就是:上来就要代码。
AI 也不含糊,接过你的话,把不清楚的地方自己猜着补上,然后哗啦啦开始生成。坏设计,往往就是在这一刻混进来的。
代码库研究员,就是专门来治这个毛病的。
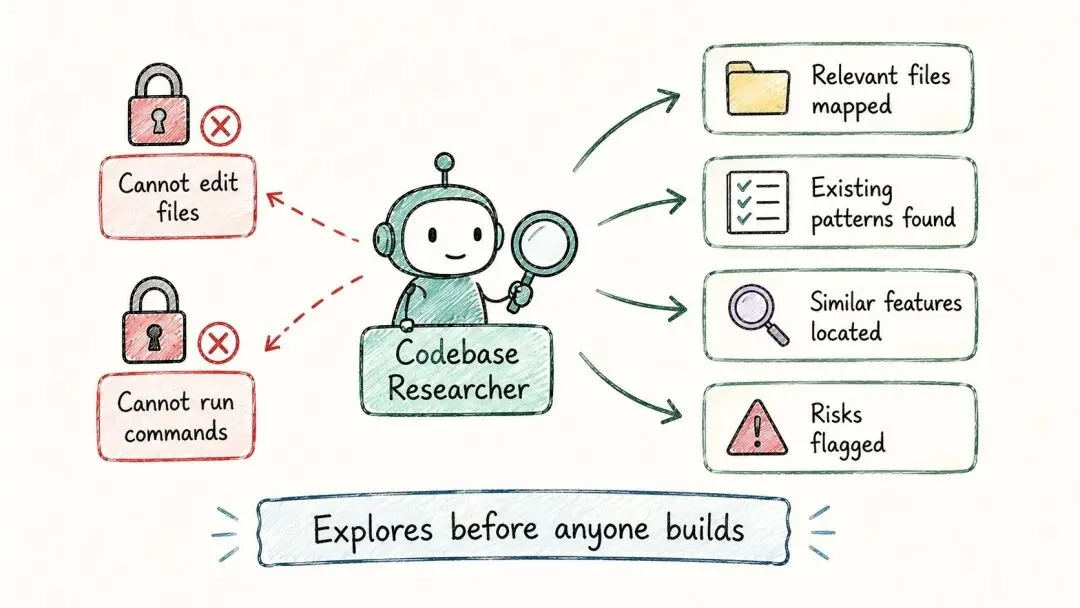
它只干一件事:在写下任何一行代码之前,先把现有的代码库摸清楚,把「现在是怎么运作的」讲明白。
具体来说,它会理清相关文件各自管什么、记下现在用的是哪套模式、翻出有没有做过的类似功能、标出有风险的地方(比如时区、多租户、重试逻辑),再列一份清单:哪些测试到时候得跟着改。
有几件事它是绝对不做的:不改文件(它只有只读权限),不跑任何会改动状态的命令,也不自己瞎猜——拿不准的,它会主动来问你。
它能用的工具,只有 Read、Grep、Glob 这三样。
规矩就一条:动手之前,先摸清楚,每一次都这样。
所以,研究员永远是第一个上场的。
二号:故事撰写员
大多数功能最后做砸了,其实不是代码写错了。
而是这个功能要解决的问题,从一开始就没讲清楚。
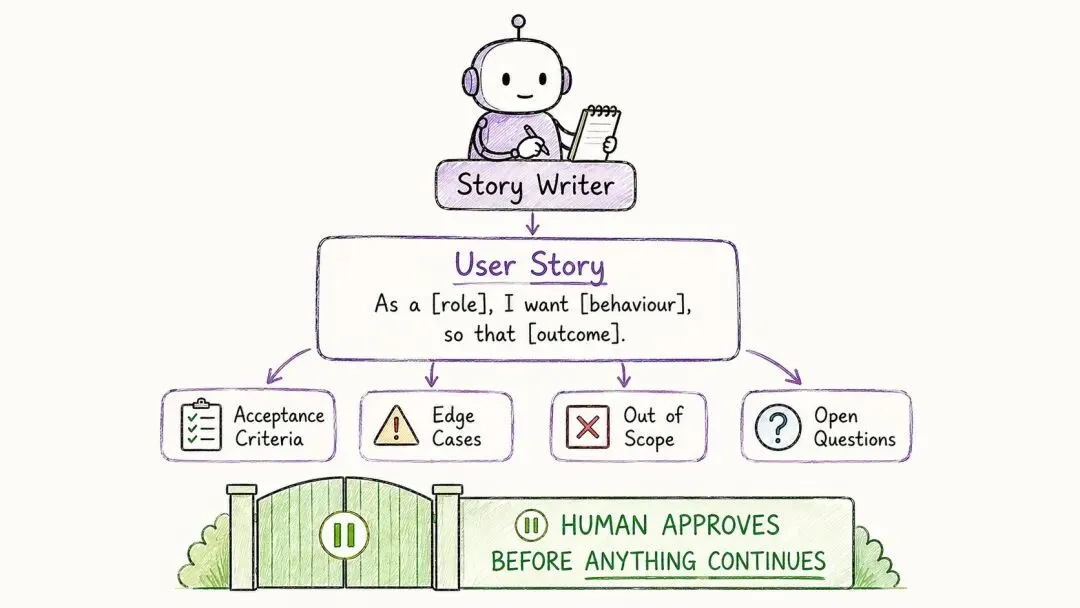
故事撰写员要做的,就是在任何技术决策之前,先把你那个还很粗糙的想法,变成一个真正说得清的用户故事。
它拿到的,是你那段随手写的功能描述,外加研究员的发现。然后它会交出几样东西:
一个用户故事,格式是「作为一个【角色】,我想要【做某件事】,好让【某个结果】发生」;一组验收标准,都是测试能直接拿去验证的那种话,正常情况、出错情况、业务规则,分得清清楚楚;一份边界情况,把边界、重试、多租户这些考量都摆出来;一份「不做什么」的清单,明确说清这次哪些是不碰的;最后还有一份待解问题——那些它确实不知道的事,它绝不替你拿主意。
它不会做这些:不自己编业务规则,不写任何代码或技术设计,碰到真没搞清楚的地方,也绝不硬着头皮往前走。
它能用的工具,只有 Read。
规矩是:你先把这个故事读一遍、点头,后面的事才会开始。
别小看这一步。这是个把关点,能帮你省掉后面一大堆麻烦。
三号:规格撰写员
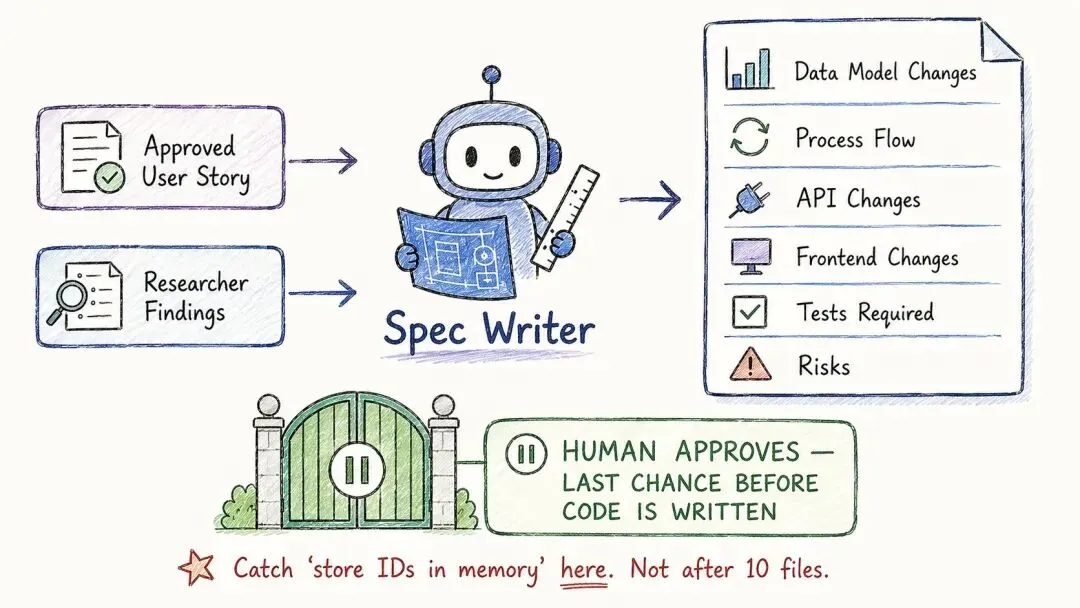
故事一旦批准,规格撰写员就接手,把它变成一份技术简报。
这份简报,就是后面每个动手干活的智能体都要照着来的图纸。
它拿到三样东西:你批准过的用户故事、研究员的发现,还有你项目里的 CLAUDE.md 规则。然后它会写清楚:数据模型要怎么改(字段、类型、迁移),后台流程是怎么走的,API 要动哪些地方(端点、请求和响应长什么样),前端要改哪些(组件、页面、hooks),需要补哪些测试(成功的、失败的、边界的),有哪些风险和没解决的问题,以及——每一个将要被改动的文件。
它同样有几条不能越的线:不改任何文件;要是发现得新造点基础设施,它会明明白白指出来,而不是自己上手;租户隔离、时区这类事,它不会跳过;问题,它也不会留着不回答。
工具还是只有 Read、Grep、Glob。
规矩是:这份简报,是第二个把关点。你读过、批准了,才会有第一个文件被碰。
这一步特别关键。打个比方,要是你在简报里看到「把 ID 存在内存里」这种话——那就是个危险信号,当场就得拦下来。别等十个文件都照着它改完了,你才发现不对。
四号:后端构建员
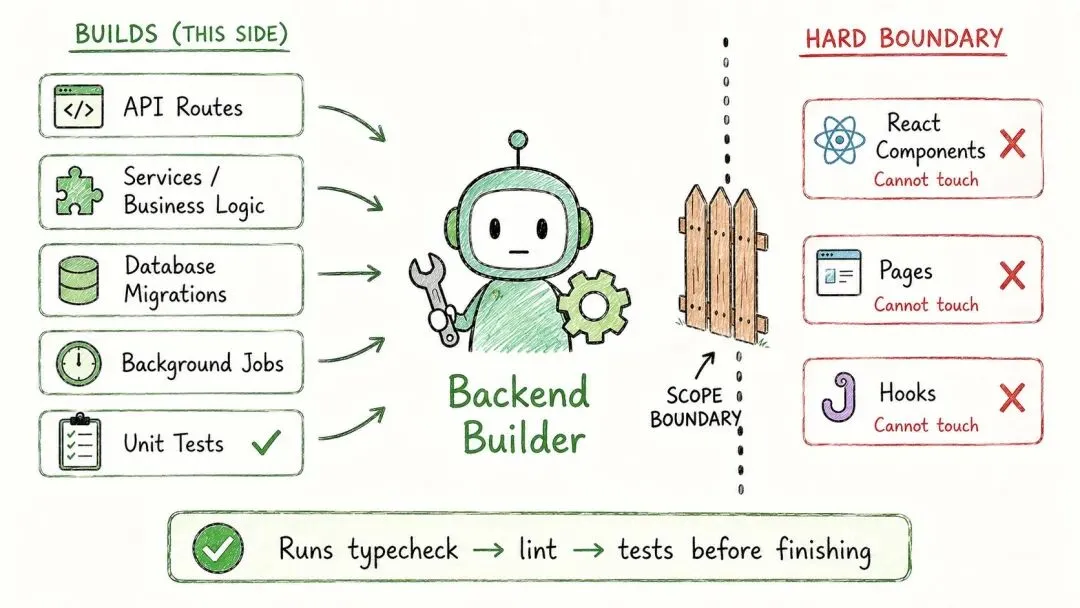
到这儿,才算真正开始动手。
后端构建员,负责把功能的后端那一半做出来——注意,只做后端那一半。
它拿到批准过的简报、研究员的发现,还有你的 CLAUDE.md,然后开始写:API 路由、服务和业务逻辑、数据库访问和迁移、后台任务,而且它写的每一样东西,都配上单元测试。
它绝不去碰这些:React 组件、页面、客户端的 hooks(那是五号的活);没指示就自己加新依赖;约定范围之外的文件;还有——不跑完类型检查、lint 和测试套件,它不许停手。
干完之后,它会交一份摘要给你:加了或改了哪些文件,复用了哪些现成的东西,以及——哪条 CLAUDE.md 规则本来能帮上忙。
工具是 Read、Edit、Write、Bash,但只限后端那几个文件夹。
把前后端这么分开,正是这套办法的精髓。这样一来,后端构建员就绝不可能一不留神把前端弄坏。一次都不会。
五号:前端构建员
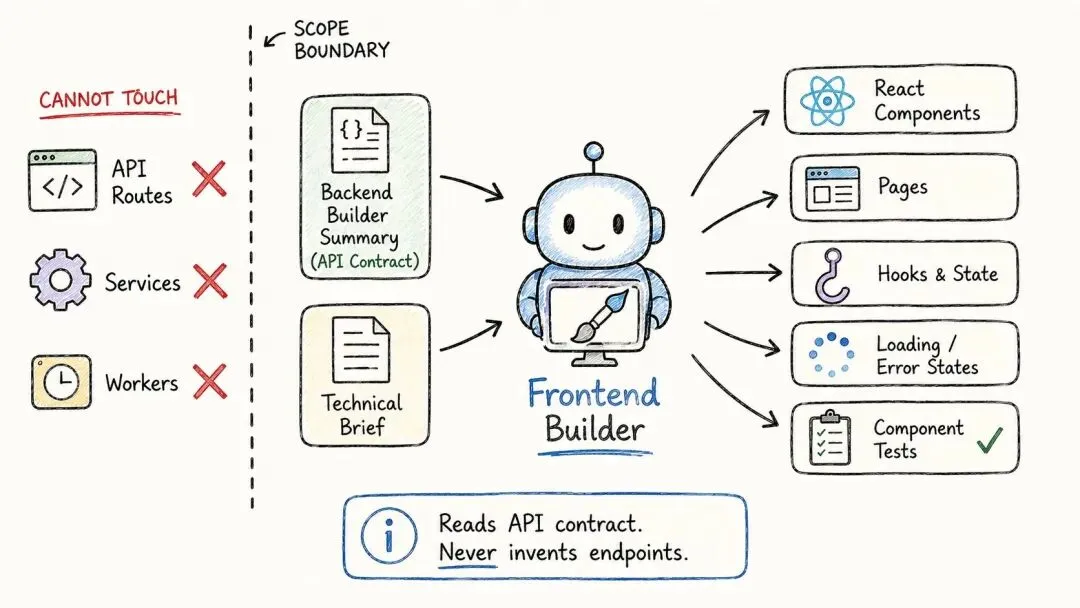
前端构建员,负责界面那一半——同样,只做界面那一半。
它干活之前,会先读后端构建员留下的那份摘要。这一步很重要。
为什么重要?因为后端的 API 长什么样,它就照着什么样去用,绝不自己另造一个端点出来。万一 API 的结构拿到界面这边不合适,它也不会偷偷打个补丁糊弄过去,而是把这个对不上的地方直接反馈出来。
它拿到的,是批准过的简报、研究员的发现,再加上后端那份摘要——也就是双方说好的 API 契约。然后它做这些:React 组件和页面、客户端的 hooks 和状态、加载和报错时的界面,以及给每一样东西配上的测试。
它不碰的,正好和四号反过来:服务、API 路由、worker、迁移,这些是后端的地盘;它也不自己编端点或响应结构,不擅自加依赖,同样要跑完全部检查才能停。
工具一样是那四个,但只限前端文件夹。
你看,两个构建员,两块互不相干的干净上下文。谁也别想把对方的活弄坏。
六号:测试验证员
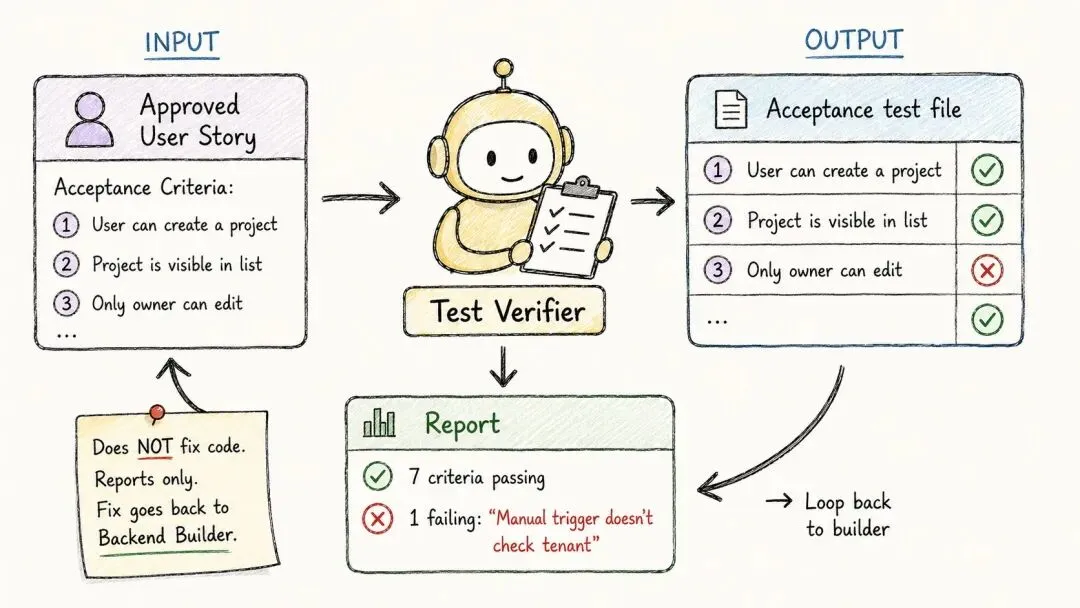
两个构建员,都给自己写的代码配了单元测试。
可光有这个,还不够。
测试验证员只认一件事:这个功能,到底有没有真的做到用户故事里说它该做的那些事。
它写的是验收测试。不是单元测试,是验收测试。这两者的区别在于:验收测试是从外面检验这个功能——就照着一个真实用户实际用起来的样子去测。
它拿到批准过的用户故事(连同每一条验收标准)、批准过的简报,还有两个构建员的摘要,然后交出两样东西:一个验收测试文件,把每一条标准都覆盖到;一份报告,说清楚哪些过了、哪些没过、哪些实在没法干净地测。
它有自己的底线:不改任何后端或前端代码;碰到没法测的标准,不替你编一套变通办法;某条标准其实没覆盖到,它绝不昧着良心标成「已覆盖」。
要是有测试没过,那就说明:这个功能还不满足故事。它会准确告诉你是哪一条没过,但它自己不动手改,而是把这条退回给对应的构建员。
工具是 Read、Edit、Write(只限测试文件)和 Bash。
规矩很硬:验收测试没全过之前,你这个功能,就还不算做完。
七号:实现校验员
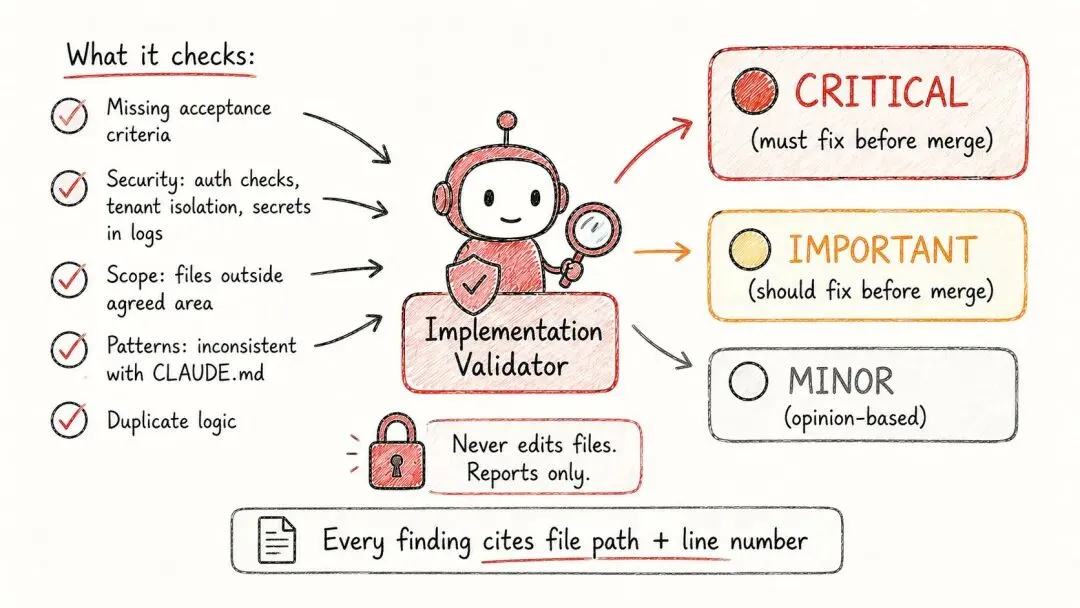
这最后一个,是专门来抓别人全都漏掉的东西的。
校验员做的事,是把当前的实现,拿去跟批准过的故事和简报对照一遍,然后把对不上的地方报出来。
它从不动手修任何东西。它只负责一件事:说真话。
它每一次都会跑一整套检查:故事里还没实现的验收标准、没人写测试的失败路径、各种安全问题(少了鉴权、租户隔离有缺口、日志里出现了密钥、原始报错被直接甩给了客户端)、改到了约定范围之外的文件、跟 CLAUDE.md 或现有代码对不上的写法、本该复用现成代码却又重写了一遍的逻辑,还有简报里写过、却被悄悄跳过的时区或多租户考量。
它给你的结果,永远按轻重分好组:严重的,合并前必须修;重要的,合并前应该修;次要的,见仁见智,你自己拿主意。每一条,都给你标上文件路径和行号。要是真没问题,它也直说没问题,绝不为了显得自己查得仔细,硬编几个出来。
工具,只有 Read、Grep、Glob。
说到底,正是这个智能体,让整座工厂值得你信任。
道理其实很朴素:一份自己给自己打分的卷子,是一文不值的。而一个只看磁盘上写了什么、根本不管这代码当初是怎么写出来的校验员,反倒是诚实的。
这条链,到底是怎么跑起来的
完整的流程,其实一句提示词就能带起来:
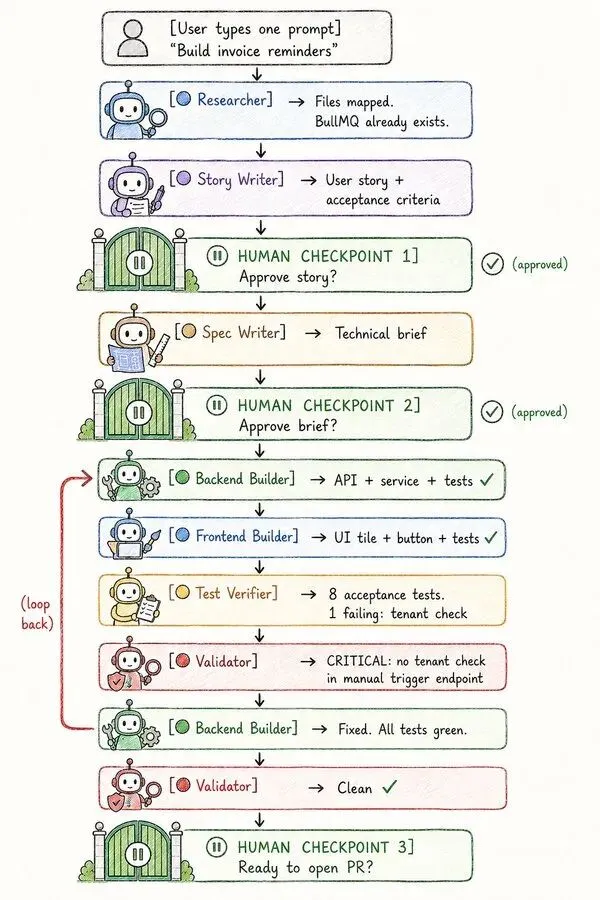
你打开 Claude Code,敲下这么一句:「给逾期未付超过 7 天的发票,做一个发票提醒功能。」
接下来,你一个字都不用再多打,下面这些就会自己一步步发生:
第一步,研究员把你的发票、支付、邮件相关的代码摸清楚,返回相关文件、现有模式和风险。
第二步,故事撰写员产出用户故事和验收标准。这里停一下——你读一遍,批准这个故事。
第三步,规格撰写员把故事变成技术简报。这里再停一下——你读一遍,批准它。(前面说的那个「把 ID 存在内存里」的坑,就在这一步抓住。)
第四步,后端构建员动手,把服务、API 路由、BullMQ 任务和单元测试都做出来,返回:改了哪些文件、复用了哪些模式、所有测试全绿。
第五步,前端构建员读完后端那份 API 摘要,做出管理后台的界面卡片和提醒按钮,写好组件测试,测试也全绿。
第六步,测试验证员对着全部六条验收标准写验收测试,报告:7 条通过,1 条没过——手动触发那条,忘了检查租户所有权。
第七步,校验员把这个问题揪了出来,标成「严重」,附上文件路径和行号。
于是流程退回到后端构建员,补上修复,8 条验收测试这下全过了。校验员再跑一遍,干净。最后停一下——你审一遍,开 PR。
你数数看,整个过程里,只有三个地方需要你停下来把关。
剩下的一切,全是它自己在跑。
地基:智能体能干活之前,你得先有这个
有个东西叫 CLAUDE.md,可以理解成一份能在每个会话里都活下来的记忆:
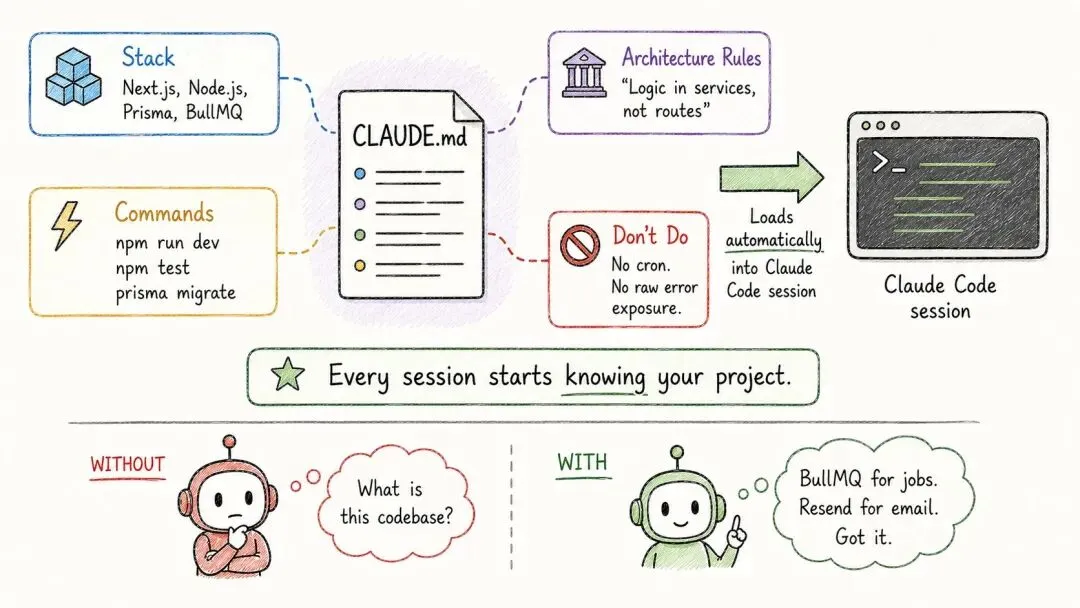
事情是这样的:每次你打开 Claude Code,它都是从一片空白、零记忆开始的。
CLAUDE.md 解决的就是这个。它是放在你仓库根目录下的一个 Markdown 文件,每个会话都会自动加载进来。
项目里那些长期不变的事实,就都写在这里:你的技术栈(比如 Next.js App Router、Node.js、Prisma、BullMQ、Resend)、你常用的命令(npm run dev、npm test、npx prisma migrate dev)、几条架构规则(比如「业务逻辑放在服务里,API 路由保持很薄」)、几条明确的禁令(比如「别加 cron,用 BullMQ」「别把原始的支付数据记进日志」),还有几个指向更详细文档的链接。
篇幅上,控制在 100 到 300 行就好。
有个习惯特别值得养成:每次 AI 犯了一个让你意外的错误,就问自己一句——要是 CLAUDE.md 里早有这么一条规则,是不是就能拦住它?要是能,就把这条规则补进去。
这么坚持几周,你的 CLAUDE.md 就慢慢变成了一份记录——记下 AI 曾经搞错的每一个假设。而你也会明显感觉到,会话一次比一次顺。
还有一件事得提防,那就是上下文漂移——一个沉默的杀手。
多数 Claude Code 会话,并不是「砰」一下崩掉的。
它们是慢慢漂走的。
一开始,只是一个错误假设悄悄钻进了上下文。然后模型就一直在这个错的基础上,接着往上盖。
举个例子。你让 Claude 做订阅管理,它顺手设计成「用户拥有订阅」。可你心里清楚:订阅其实是属于公司的,不属于某个用户。
这时候,要是你只随口说一句「不对,订阅属于公司」——Claude 多半就只是打个补丁应付过去。结果呢?你手上同时飘着 user.subscriptionId 和 company.subscriptionId 两个东西,怎么看怎么别扭。
所以这里有条规矩,挺管用的:要只是个小拼写错误,就地改掉就行;可要是连架构假设都错了,那就别补了——干脆把这整段对话扔掉,重开一个,一开始就把正确的前提,直接写进第一条提示词里。
一个从头就想对了的干净会话,每次都赢过一个东补一块、西补一块的会话。
结果:到底有什么不一样
我们来对比一下。
用工厂之前,日子大概是这样的:你陷在 vibe coding 的循环里——提示、生成、报错、打补丁、再来一遍;会话的上下文越来越满,全是噪声;错误假设越积越多,最后攒成几个坏掉的功能;一个工程师一次只能干一件事;每个功能,都得排队等那个对的人有空。
用工厂之后,画面就换了:活儿走的是一条结构化的链——研究、故事、简报、构建、验证、校验,一步接一步;每个智能体手里都有一块干净的上下文,里头只放它需要的东西;错误假设在简报批准那一步就被拦下,而不是等十个文件改完之后;一个工程师,自己就能交付一个完整的纵向切片,后端、前端、测试、校验全包了;更重要的是,团队里最好的知识,沉淀在了智能体里,而不再困在某个人的脑子里。
最后这一点,才是真正的转变。
你想想看:支付方面的专家,做了一个支付集成智能体。从那以后,团队里随便哪个工程师,都能交付一个跟账单沾边的功能——不用排队等,也不用谁交接给谁。
同样地,前端负责人的那套组件写法,沉淀进了前端构建员;DevOps 工程师的那套 CI 检查,沉淀进了一个 hook;QA 负责人能想到的那些边界情况,沉淀进了测试验证员的规则。
说到底,专家的本事,就这样以智能体的形式分享了出去——不再取决于某个人当天有没有空。
这个周末,你就能把自己的工厂搭起来
下面是一份 8 步的清单:

1. 装上 Claude Code(code.claude.com)。 2. 把文件夹结构建好:.claude/agents/、.claude/skills/feature-factory/、.claude/skills/build-with-tests/、.claude/hooks/。 3. 写你的 CLAUDE.md,100 到 300 行:技术栈、命令、架构规则、不要做清单。 4. 用 Claude Code 里的 /agents 命令,把这 7 个智能体创建出来。你只要把每个智能体是干什么的描述清楚,Claude 来写文件,你来审、来提交。 5. 创建一个叫 feature-factory 的编排 skill。让 Claude 来写就行——它会读你那 7 个智能体文件,自己把整条链接起来。 6. 再创建一个 build-with-tests skill,把你团队的干活习惯讲清楚:照着现有模式来,代码和测试一起写,最后跑一遍类型检查。 7. 加一个 pre-commit hook,挡住任何带着 .env、.key、.pem 或 secrets.json 的提交。这一步花不了 5 分钟,却能帮你防一场灾难。 8. 最后,拿一个真实功能,从头到尾走完整条链。挑个小的,看它在哪儿磕磕绊绊,然后顺手把规则补上。这座工厂,会自己越调越好。
整个搭建过程,2 到 3 个小时就够了。
搭完之后,多跑几个功能。跑过三四个,工厂基本就摸清你的代码库了。到那时候,你盯活儿的时间会越来越少,而花在「下一个该做什么」上的时间,会越来越多。
七个智能体,一张速查表
• 研究员——动手之前,先把代码摸清楚(只读) • 故事撰写员——把想法变成带验收标准的用户故事(只读) • 规格撰写员——把故事变成技术简报(只读) • 后端构建员——做 API、服务、任务、单元测试(只限后端文件夹) • 前端构建员——做组件、页面、hooks、界面测试(只限前端文件夹) • 测试验证员——对着用户故事写验收测试(只限测试文件) • 校验员——把实现跟故事和简报对照,报出差距(只读)
需要你亲自把关的,就三个地方:批准故事、批准简报、批准 PR。
剩下的,全自己跑。
说到底,今天大多数用 Claude Code 的人,还停在 vibe coding 上——提示、生成、打补丁、然后祈祷。
这么干其实也没什么错。只是,它有个上限,你怎么使劲都顶不破。
而工厂这套办法,不是要把你从流程里赶出去。它只是把你从那些根本不需要你的环节里解放出来,让你能专心待在真正用得上你判断力的地方:
这是不是对的问题?这是不是对的设计?这东西,发出去到底安不安全?
至于这之间的一切——交给智能体去办就好。
这,就是把 AI 当成一个更快的键盘,和把 AI 当成一支配合默契的团队,两者之间的区别。
