 夜雨聆风
夜雨聆风
一个真实的故事
不少团队都有过这样的经历:花费一个月时间开发出AI驱动的应用,完成上线时满怀期待。
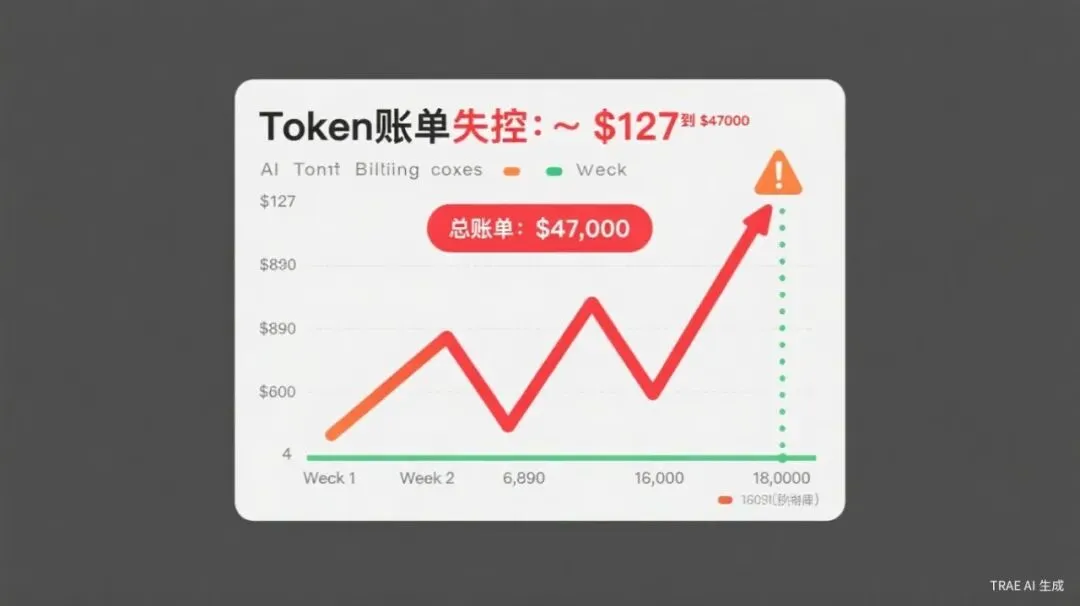
第一周,账单127美元。嗯,还好。
第二周,890美元。眉头一皱。
第三周,6000美元。心跳加速。
第四周,18000美元。冷汗直冒。
月底一看总账——47000美元。而你们最初的预算只有600美元。
这种事儿真不是编的,好多行业里的团队都实实在在碰到过。而且,类似的故事正在行业内不断上演,只是很少有人愿意公开谈论。
更让人震惊的是,有报道称Uber在某个年度中,到4月份就把全年AI预算花光了。不是因为做了什么特别的事,纯粹是因为没有人预料到实际用量会这么大。
如果你今年要把AI放到生产环境中,这篇文章值得你认真读完。
什么是"Token税"?
Arthur Hickens(网名CodeCummudgeon,Parasoft公司资深专家)在一篇文章中提出了一个很形象的概念——"Token税"(Token Tax)。这玩意儿算不上真的税,就是一笔你压根没料到的开销。传统的软件开发,成本大多是 upfront 的:你花10万买服务器,花5万雇开发,系统上线后主要就是维护费用。你可以提前预算,心里有数。
但AI不一样。
每一次你把数据传给大模型,你要付费。模型返回结果,你要付费。你让Agent在后台帮你搜索、分析、生成,全程都在烧钱。个人用户大多用的是20美元/月的固定套餐,根本感觉不到用Token要花多少钱;可一旦把AI功能放到生产环境、给真实用户用,就得按实际用了多少Token收费,这时候得搞清楚Token到底是啥、会用多少,成本才能控得住。
Token成本失控的三大元凶
🔥 元凶一:用量预估严重不足
这是最常见的问题。大多数团队在开发阶段用的是免费账号或固定套餐,对实际生产环境的Token消耗量毫无概念。这就跟平时家里用水似的,水费看着没几个钱;可真要开工厂,一天几千吨水用下去,那水费能高到让你怀疑人生。AI应用也是如此。开发时测试几次觉得"还好",一旦上线面对真实流量,Token消耗可能呈指数级增长。
🔥 元凶二:Agent陷入无限循环
这是最隐蔽、也最危险的问题。Agent运行时最坑的一点是,它不会直接告诉你任务做不了,反倒会悄无声息地反复尝试执行,你完全没察觉,在后台循环运行数小时甚至数天,持续消耗Token。
有一个案例中,两个Agent之间竟然互相对话了11个小时,在所有人睡觉的时候安静地烧钱。
为什么会这样?因为Agent的工作方式本质上就是一个循环:接收任务→尝试执行→检查结果→如果没完成就继续。如果没有合理的终止条件,这个循环就不会停。
🔥 元凶三:安全漏洞被恶意利用
AI应用还面临一个容易被忽视的风险:安全攻击。
有人入侵了一个AI系统后,不是窃取数据,而是疯狂调用API,把你的Token额度榨干。有一个案例中,攻击者在5分钟内通过被盗账户消费了7000美元。
如果你的AI应用没有做好速率限制(Rate Limiting)和用量监控,一旦被恶意利用,损失可能非常惨重。
一个被忽视的真相:AI公司自己也在亏钱
你可能会想:Token价格一直在降,未来应该越来越便宜吧?
确实,过去两年Token价格下降了90%以上。但这里有一个被忽视的事实:AI提供商目前几乎都不赚钱。
这些AI厂商现在都是「亏本赚吆喝」的路子,跟早年手机运营商推流量套餐的玩法差不多。电信公司知道有些用户用得少、有些用得多,通过固定套餐可以平衡成本。但AI的用量模式更加极端,这种模式能否持续,是个大大的问号。
Arthur打了一个很精准的比方:他以前在相机店打工时,老板常说一句话——"我们每卖一台都亏钱,但靠走量弥补。"
这恰恰是当前AI行业的写照。
所以,不要指望Token价格会一直降下去。AI公司不可能永远亏本运营。一旦资本退潮,价格回调几乎是必然的。
五个实战策略,防止Token账单失控
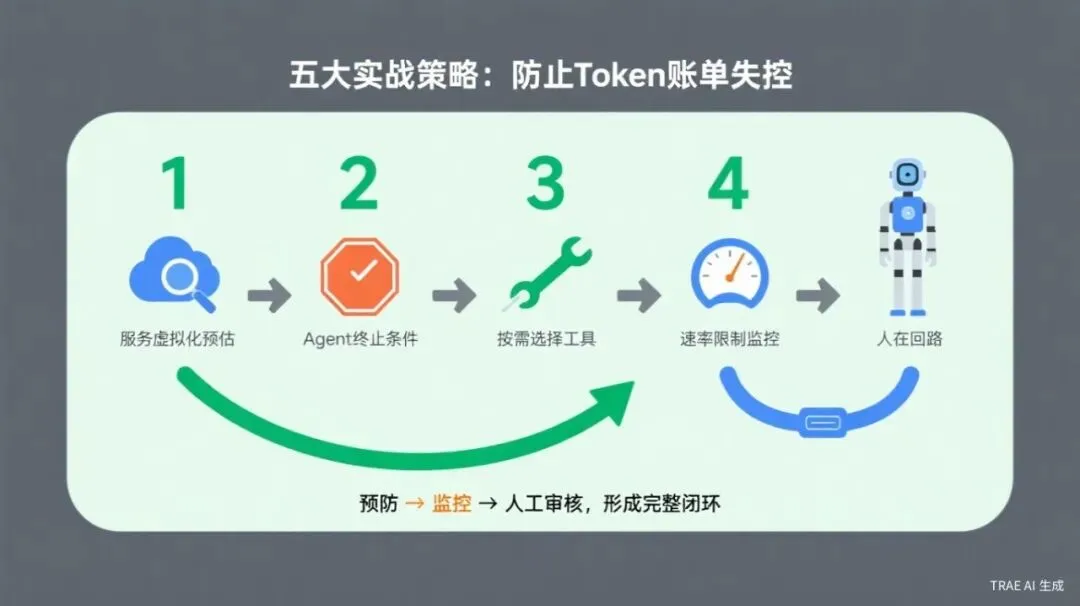
💡 策略一:用服务虚拟化做成本预估
在把AI应用推向生产之前,用服务虚拟化(Service Virtualization)技术模拟LLM的响应。
具体做法是:先收集真实的请求-响应数据,然后用虚拟服务模拟LLM的行为。这样你可以在不产生实际费用的情况下,模拟高并发场景,预估Token消耗量。
如果发现一个月可能消耗百万级Token,你就能提前做好预算,而不是等到月底被账单吓到。
💡 策略二:给Agent设置硬性终止条件
永远不要让Agent无限制地运行。必须设置明确的终止条件:
• 最大迭代次数:比如最多尝试10次 • 最大Token预算:单次任务不超过多少Token • 超时机制:运行超过一定时间自动终止 • 费用告警:当消耗达到阈值时立即通知
这就像给信用卡设置消费限额一样简单,但很多团队就是忘了做。
💡 策略三:不是所有问题都需要LLM
这是一个容易被忽略的关键点。
如果你的问题是确定性的(比如数据格式转换、简单计算、规则匹配),你根本不需要用LLM这种非确定性的工具。
LLM擅长的是理解自然语言、处理模糊问题、生成创意内容。对于明确的、规则化的任务,传统代码方案更快、更准、更便宜。
Arthur在访谈中举了一个很好的例子:用LLM生成单元测试,在复杂代码上的分支覆盖率平均只有30%,多次尝试后最多到40%。这意味着你花了大量Token,但大部分代码仍然没有被测试到。
正确的做法是:让AI做它擅长的事,然后用传统工具或人工补充剩下的部分。而不是反过来——先人工做简单的,把难的留给AI(AI同样会做不好,还会浪费更多Token)。
💡 策略四:做好速率限制和监控
这是安全防护的基本功:
• API速率限制:限制每个用户/每分钟的调用次数 • 用量监控仪表盘:实时展示Token消耗趋势 • 异常检测:当用量突然飙升时自动告警 • 费用上限:设置月度预算上限,达到后自动暂停服务
这些措施不需要多高深的技术,但能帮你避免最坏的情况。
💡 策略五:不要忽视"人在回路"
当前阶段,AI还不能完全自主运行。你需要保持人类在回路(Human in the Loop)。
这意味着:
• AI生成的代码需要人工审查(LLM可能把断言逻辑写反) • AI的测试结果需要人工验证 • AI的决策需要人工确认
这听起来像是增加了成本,但实际上是在帮你省钱。因为一个没有被发现的质量问题,后续修复的成本远高于预防的成本。
写在最后
AI正在深刻改变软件开发的方式,这是不可逆转的趋势。但与此同时,Token成本失控的风险也是真实存在的。
AI技术现在越来越普及,没必要因为怕成本超支就不用AI,反倒该好好树立起管控AI成本的意识。在做技术决策时,不仅要问"AI能不能做",还要问"AI做这个的成本是多少"、"有没有更经济的替代方案"。
记住Arthur的那句话:AI是一个"任性的天才"——它会让你惊叹于它的聪明,然后在你最意想不到的时候,做出让你目瞪口呆的蠢事。
保持敬畏,保持监控,保持人在回路。这是当前阶段使用AI最务实的态度。
