 夜雨聆风
夜雨聆风

摘要:本文深入解析4飞焦级全光开关技术突破,揭秘激子极化激元如何破解光子交互难题,对比CMOS、存算一体等主流技术性能差异,分析该技术如何将AI芯片能效提升2000倍,为全光AI芯片、量子计算落地铺平道路,探讨光子计算如何破解当前AI的功耗墙困局。
引言:AI算力扩张下的能效困局
随着生成式AI的爆发,大语言模型、多模态模型的参数规模以指数级增长,这给底层硬件带来了前所未有的压力。根据行业数据,当前训练一个万亿参数的大模型,需要消耗超过300MWh的电能,而全球AI数据中心的能耗已经占到全球电力消耗的2%以上,并且仍在快速增长。
传统的电子芯片正在逼近物理极限:摩尔定律的放缓使得晶体管微缩的红利逐渐消失,而冯・诺依曼架构下,数据在计算单元与存储单元之间的频繁搬运,消耗了系统90%以上的能量,这就是所谓的“内存墙”与“功耗墙”。
为了突破这一瓶颈,业界将目光投向了光子计算——用光而非电子来处理信息。光子的传播速度更快、发热更少,理论上可以实现比电子芯片高几个数量级的能效与速度。但长期以来,全光计算面临一个核心难题:光子之间几乎不会发生相互作用,这使得我们很难用光来控制光,实现类似电子开关的逻辑操作,这也成为了全光芯片实用化的最大障碍。
近日,来自宾夕法尼亚大学与蒙大拿州立大学的研究团队在《PhysicalReviewLetters》上发表了一项突破性研究,他们基于二维材料与纳米光腔,实现了能耗仅为4飞焦(fJ)的全光开关,将全光开关的能耗门槛降到了前所未有的水平,为大规模全光AI芯片的落地铺平了道路。
一、核心技术分析:半光半物质的激子极化激元,破解光子交互难题
要实现全光计算,最核心的组件就是全光开关:它能让一个光信号控制另一个光信号的通断,就像电子开关控制电流一样,这是实现所有逻辑运算与信号处理的基础。
但光子的“冷漠”是最大的阻碍:在常规条件下,光子之间不会发生相互作用,一个光子的传播不会影响另一个光子。为了让光子能够“互动”,研究团队引入了一种特殊的准粒子——激子极化激元(ExcitonPolaritons)。
1. 半光半物质的准粒子,继承两者优势
激子极化激元是一种“半光半物质”的混合粒子:当光子和半导体中的激子(电子-空穴对)发生强耦合时,就会形成这种新的准粒子。它同时继承了光子与激子的优势:
作为“光”的部分,它可以以光速传播,信号延迟极低,带宽极大;
作为“物质”的部分,它可以通过其中的激子部分实现粒子间的强相互作用,这就间接让光子之间产生了交互能力。
为了实现这种强耦合,研究团队选择了单层二硒化钼(MoSe₂)——一种典型的二维半导体材料。这种原子级厚度的材料有着极高的激子结合能,能够在室温下稳定存在激子,不需要复杂的低温环境,这为器件的实用化打下了基础。
2. 纳米光腔:把光“锁”在纳米空间,放大相互作用
仅仅有二维材料还不够,为了进一步增强光子与激子的耦合强度,研究团队将MoSe₂单层与光子晶体纳米腔集成在了一起。
这种纳米腔是一种纳米级的“光陷阱”,它可以把光紧紧地限制在亚波长的极小空间里,让光子和MoSe₂中的激子有更长的相互作用时间,从而极大地增强了两者的耦合效率,也放大了粒子间的相互作用强度。
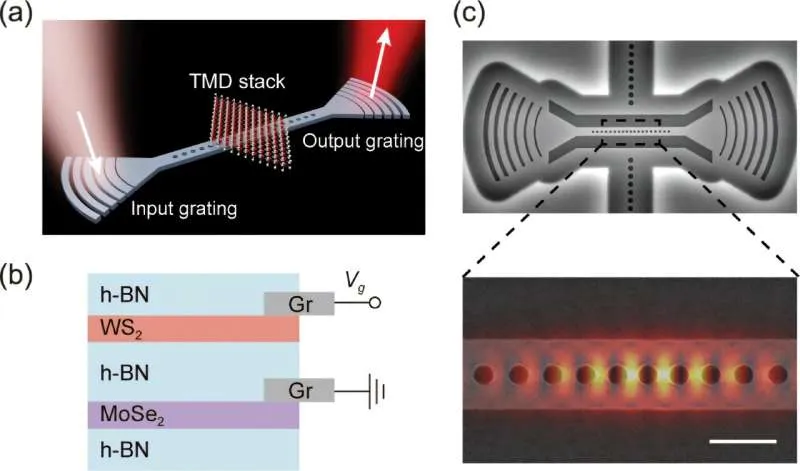
图1:研究团队设计的器件结构,入射光进入氮化硅纳米梁腔后,与单层MoSe₂中的激子发生强耦合,形成激子极化激元,从而实现光子间的有效交互。
通过这种设计,研究团队成功将全光开关的能耗降到了4飞焦(4×10⁻¹⁵J),这是目前全光开关领域的最新纪录,比传统的硅基全光开关的能耗低了两个数量级以上。
“我们的设计把极化激元限制在亚波长的极小空间里,这极大地增强了粒子间的相互作用强度,让我们得以在创纪录的低功率下实现开关操作,只需要消耗大约4飞焦的能量。”该研究的资深作者、蒙大拿州立大学的LiHe助理教授解释道。
二、深度对比:全光开关与传统技术的性能鸿沟
这项研究的突破,不仅仅是一个数字的提升,它让全光开关的性能第一次具备了和主流电子芯片技术竞争的能力,甚至在很多维度上实现了超越。我们将这项技术与当前主流的计算开关技术做了横向对比:
技术类型 | 典型开关能耗 | 工作带宽 | 集成兼容性 | 核心优势 | 核心短板 |
7nmCMOS电子开关 | ~1-10aJ | ~1-10GHz | 完全成熟 | 工艺成熟、成本低 | 带宽有限、传输能耗高 |
传统硅基全光开关 | ~1-10pJ | ~100GHz+ | 中等 | 速度快、光信号兼容 | 能耗过高,难以大规模集成 |
忆阻器(存算一体) | ~10-100fJ | ~1-100GHz | 中等 | 解决内存墙、边缘AI友好 | 速度有限、可靠性待提升 |
本研究:2D材料激子极化激元光开关 | 4fJ | ~THz级 | 中等(兼容标准制造工艺) | 超低能耗、超高带宽、光原生 | 尚处于实验室验证阶段 |
从对比中我们可以看到:
能耗的跨越式进步:和传统的硅基全光开关相比,这项技术把能耗从皮焦(pJ)级降到了飞焦(fJ)级,降低了超过100倍,这意味着同样的能耗下,全光芯片可以处理超过100倍的计算任务。
速度的代际优势:光开关的工作带宽可以达到THz级别,这是传统电子开关的100倍以上,这对于AI大模型所需要的超高带宽数据处理来说,是不可替代的优势——比如处理Transformer中的注意力机制,超高带宽可以极大地缩短处理延迟。
量产的可行性:和很多实验室里的新奇器件不同,这项技术的制造工艺是兼容现有的半导体标准制造技术的,这意味着它可以大规模集成,在一个芯片上制造数千个这样的光开关,组成复杂的光计算电路,而不需要重新搭建全新的产线。
三、对未来AI硬件的重构:从能效到架构的全面升级
这项全光开关的突破,不仅仅是一个组件的进步,它将从根本上重构未来AI硬件的架构,解决当前AI芯片面临的核心痛点。
1. 破解AI的功耗困局,实现千倍能效提升
当前的AI芯片,不管是GPU还是NPU,最大的痛点就是能耗:数据在计算单元和内存之间的搬运,占了整个系统90%以上的能耗。而全光计算架构下,光信号可以在芯片内直接传输,不需要进行光电转换,也不需要长距离的电信号互连,这就从根本上消除了数据搬运的能耗。
根据研究团队的测算,基于这种开关的全光AI系统,在特定的AI任务中,能效可以达到传统电子芯片的2000倍以上,这和之前的存算一体技术的提升幅度相当,但速度却要快得多。这意味着,未来训练一个大模型,只需要消耗现在1/2000的电能,这将彻底解决AI的能耗危机,让大模型可以在边缘设备上运行,而不需要依赖云端的数据中心。
2. 为神经形态光子芯片提供核心组件
这种全光开关非常适合神经形态(Neuromorphic)计算架构:它的非线性响应特性,和生物神经元的激活函数非常相似,而且可以实现超低能耗的脉冲信号处理。这意味着我们可以用光子来模拟大脑的神经网络,实现比电子神经形态芯片更快、更高效的脑启发计算。
3. 同时支撑量子计算的未来
更有意思的是,这项技术的潜力不止于经典计算。研究团队表示,他们接下来的目标是把开关的能耗再降低几个数量级,做到单光子级别——也就是一个光子就可以控制另一个光子。这正是量子计算所需要的核心组件:量子逻辑门。
如果实现了单光子的全光开关,那么这个平台就可以同时支撑经典的全光AI计算和量子计算,这将为未来的融合计算架构打下基础。
四、挑战与未来:从实验室到量产的最后一公里
当然,这项技术目前还处于早期的实验室验证阶段,要真正实现大规模的商用全光AI芯片,还有不少挑战需要解决:
规模化集成的验证:目前研究团队只验证了单个开关的性能,接下来需要把多个开关集成在一起,组成复杂的光电路,验证大规模集成后的性能与可靠性。
进一步降低能耗:虽然4飞焦已经是纪录,但研究团队认为这还不是物理极限,他们还有明确的路径把能耗再降低几个数量级,做到单光子的量子regime,这需要进一步优化纳米结构的设计。
良率与成本的优化:虽然工艺兼容标准制造,但二维材料的转移、纳米腔的加工良率,还需要进一步优化,才能满足大规模量产的成本要求。
不过,研究团队对此非常乐观:“我们的平台是为大规模量产设计的,通过使用标准制造技术可以加工的材料和结构,我们证明了这些二维材料器件可以集成到大规模的集成光子电路中,这为包含数千个交互光学组件的芯片打开了大门。”LiHe教授表示。
结语
这项飞焦级全光开关的突破,标志着全光计算从实验室的概念,真正走向了实用化的前夜。它不仅为解决AI的能耗危机提供了一个全新的路径,也为未来的光子AI芯片、量子计算芯片打下了核心的技术基础。
随着这项技术的进一步成熟,我们或许很快就能看到,新一代的全光AI芯片,把大模型的能耗降到现在的千分之一,让AI不再是“电老虎”,而是真正走进我们的手机、手表,甚至是更小的边缘设备,开启一个全新的高效AI时代。
参考资料:
ZhiWangetal,StronglyNonlinearNanocavityExcitonPolaritonsinGate-TunableMonolayerSemiconductors,PhysicalReviewLetters(2026).DOI:10.1103/gc15-qsvf.
 点击“阅读原文”查看更多
点击“阅读原文”查看更多