 夜雨聆风
夜雨聆风你可能已经有过这种体验。
同一个项目里,你每天都要让 AI 做几件差不多的事:
• 看看最近 24 小时有没有影响某个模块的提交; • 检查 CI 失败是不是同一类问题; • 扫一遍昨天自己改过的文件,找可能遗漏的测试; • 把同一套调研、写作、审校、发布流程再跑一遍; • 根据最近几次会话里反复踩的坑,提醒你要不要更新项目规则。
一开始,这些任务靠手动 prompt 就够了。你复制一段指令,发给 Codex,等它跑完,再看结果。
但重复到第三天,问题就出现了:你不是在“使用 AI”,你是在“记得让 AI 去干活”。
真正浪费时间的,不是那一次 prompt 的几秒钟,而是每次都要重新想一遍:
• 这个任务要在哪个项目里跑? • 要不要新开 worktree? • 需要读哪些文件? • 有结果时怎么报告? • 没结果时要不要打扰我? • 出现风险时什么时候停下来?
这就是 Codex Automations 要解决的问题。
根据 OpenAI Codex Automations 文档[1],Automations 可以让 Codex 在后台执行 recurring tasks,把有发现的结果放进 Triage 收件箱;如果没什么重要内容,也可以自动归档。它还能和 Skills、plugins、worktree、sandbox 设置组合起来。
这听起来像“给 AI 加了定时任务”。
但如果只把它理解成 cron job,就低估了它。更准确地说:
Codex Automations 是把稳定 Agent 工作流变成后台节奏的系统。

注意这里有两个关键词:稳定,节奏。
还不稳定的流程,不该直接自动化。没有节奏的流程,也很难持续产生价值。
很多人第一次看到 Automations,会立刻想到:“那我是不是可以让 AI 每天自动写代码?”
可以,但这不是最好的起点。
自动化最适合的不是“巨大、模糊、开放”的任务,而是那些你已经跑过几次、边界清楚、结果可检查、失败也不会造成大损失的流程。
OpenAI 的最佳实践[2]给了一个很好的判断句:Skills 定义方法,Automations 定义调度。
这句话非常重要。
Skill 解决的是“这件事应该怎么做”。比如代码审查要看哪些风险,内容生产要经历哪些步骤,发布前要跑什么检查。
Automation 解决的是“什么时候、在哪个环境、用什么上下文去重复做”。它不应该替代方法本身。
所以我会用一个简单标准判断一个任务能不能自动化:
换句话说,Automations 不是拿来承接混乱的。它是拿来放大稳定性的。
如果一个流程还需要你每次手动提醒“不要乱改文件”“先跑测试”“记得写来源”“别动未提交改动”,那它还没到自动化阶段。
先把这些要求写进 AGENTS.md、Skill、脚本、测试和 hooks 里,再让 Automation 接手。
三种形态:后台任务、项目任务、线程心跳
Codex Automations 容易混淆,是因为它不是单一形态。
从使用方式看,至少要分三类。
第一类是独立或项目级自动化。
它每次按计划启动一次新运行,结果进入 Triage。适合“今天也要检查一下”的任务,比如:
• 每天早上总结某个目录最近 24 小时的提交; • 每个工作日扫描最近改动里的潜在 bug; • 每周起草 release notes; • 定期检查某类文档是否过期。
这种任务的特点是:每次运行彼此独立。今天的结果不需要和昨天在同一个对话里继续推理。
第二类是跨项目自动化。
官方文档提到,同一个 automation 可以在多个项目上运行。这个能力很适合做横向检查,比如团队里多个仓库都需要:
• 检查 README 与实际脚本是否一致; • 查找重复出现的 CI 失败; • 生成周报材料; • 扫描 AGENTS.md 是否缺少新的团队约定。
这里的关键不是“AI 能不能读多个项目”,而是输出必须可比较。你要让它用同一套结构报告,而不是每个仓库写成一篇散文。
第三类是 thread automation。
官方文档[3]把它描述成 attached to the current thread 的 recurring wake-up call。也就是说,它不是每次新开一个任务,而是让同一个线程按节奏醒来。
这适合持续跟进:
• 一个长命令还在跑,每 5 分钟检查一次; • 一个 PR review loop 需要持续处理新反馈; • 一个线上问题排查线程需要保留上下文; • 一个研究任务要在同一个对话里继续补资料。
简单判断:
这张表能避免很多误用。
如果你只是想“明天提醒我继续看这个 PR”,thread automation 很合适。如果你想“每天生成一份仓库健康报告”,standalone 或 project automation 更合适。如果你想“合并前必须阻止不合格代码”,那应该用 CI、pre-commit、type checker 或 hook,而不是只靠 Automation。
Worktree 是自动化的安全垫
无人值守任务最危险的地方,不是 AI 写错了几行代码,而是它在你还没看见的时候,改了你正在工作的地方。
Codex Automations 在 Git 仓库里可以选择两种运行位置:local project 或 dedicated worktree。官方文档也说得很直白:worktree 可以把自动化改动和未完成的本地工作隔离开;local mode 会直接在你正在编辑的 checkout 里工作。
这不是小细节,而是自动化设计里的第一道安全边界。
我的建议很简单:
你可以把 worktree 理解成“让 AI 在隔离办公桌上干活”。它可以写、可以试、可以留下 diff,但不会直接把你的主桌面弄乱。
这也解释了为什么 Automations 不应该直接替代工程流程。
如果它发现 bug,可以开一个隔离 diff;如果它起草 release notes,可以生成草稿;如果它发现 AGENTS.md 需要更新,可以给出建议。真正合并、发布、替换生产配置,仍然应该经过人的确认和现有检查。
自动化的好状态不是“AI 悄悄把事情都做了”,而是:
AI 把重复劳动推进到可复查状态,人只处理判断和授权。
Durable prompt:自动化 prompt 要经得起明天再跑
普通聊天 prompt 可以写得很随意。你人在现场,可以随时补一句“不是这个意思”。
Automation prompt 不行。
它明天、后天、下周还会自己跑。那时你不在旁边,它也不该靠猜。
官方文档特别提醒 thread automation 要 make the prompt durable。这个原则同样适用于所有自动化。
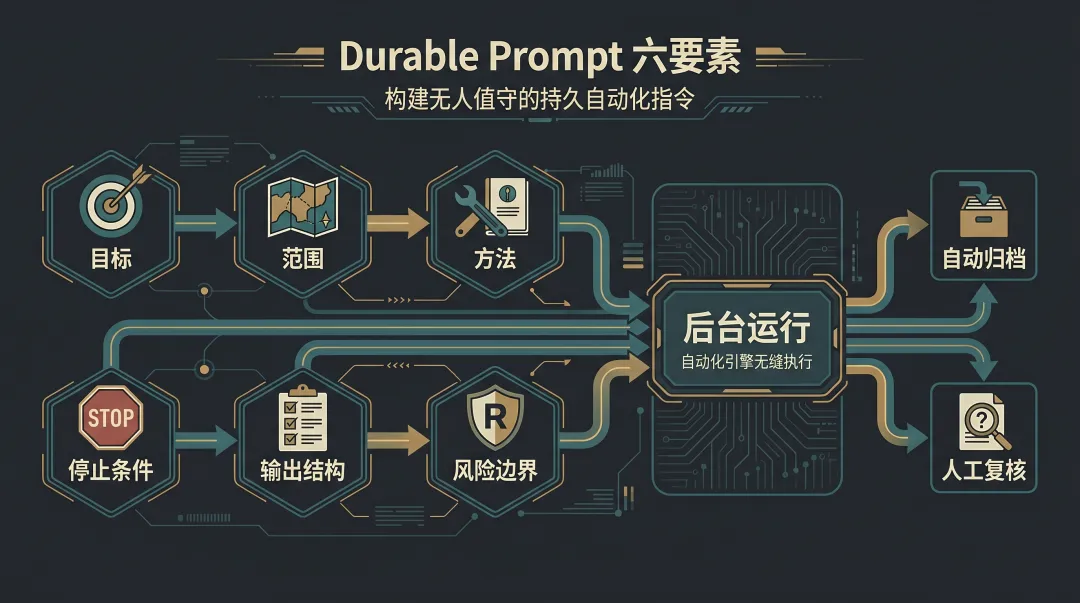
一个 durable prompt 至少要写清楚六件事:
1. 目标:每次醒来到底要完成什么。 2. 范围:只看哪些项目、目录、分支、时间窗口。 3. 方法:优先用哪些 Skill、命令、文档或数据源。 4. 停止条件:什么时候可以说没有发现,什么时候必须停下来。 5. 输出结构:有发现怎么报告,没发现怎么归档。 6. 风险边界:哪些文件不能改,哪些动作需要人工确认。
比如一个“每日代码健康检查”的 automation,不应该只写:
每天检查这个项目有没有 bug。这句话太宽。它会迫使模型自己定义“bug”“检查”“项目”“每天”的边界。
更好的写法是:
每天上午 9 点检查当前 Git 仓库最近 24 小时由我提交的改动。范围:- 只检查最近 24 小时内变更过的文件。- 优先关注测试、构建、类型、边界条件、错误处理。- 不做大范围重构,不改无关文件。方法:- 先读取 git diff/log,找出变更文件。- 运行最小相关验证命令;如果找不到命令,只做静态检查并说明原因。- 如果发现明确 bug,在 worktree 中做最小修复,并留下验证证据。输出:- 有修复:总结 root cause、修改文件、验证命令、剩余风险。- 只有风险但不适合自动修:进入 Triage,列出人工复核项。- 没有发现:自动归档,不打扰。停止条件:- 需要访问生产系统、凭据、外部付费服务时停止。- 需要修改迁移、部署、权限配置时只提建议,不直接改。这才是可以交给后台的 prompt。
你会发现,写 durable prompt 的过程,本质上就是把人的经验变成流程。
这和 Skills 的关系非常自然:如果这段 prompt 越写越长,说明它应该被沉淀成 Skill。Automation 只负责定时调用它。
四层能力栈:Rules、Skills、Hooks、Automations
过去几篇文章,我们其实一直在搭同一套系统。
《65 行 CLAUDE.md:给 AI 编程助手装上刹车》讲的是 Rules:让 AI 知道团队底线。
《MCP 负责连接,Skills 负责纪律:给 AI Agent 加能力的正确姿势》讲的是能力和流程:MCP 接外部世界,Skills 沉淀操作手册。
《别再只靠提示词管 AI 了:Claude Code Hooks 实战指南》讲的是 Hooks:在工具执行、权限请求、任务完成等节点真正拦住风险。
Codex Automations 则是下一层:让这些已经稳定的流程按节奏运行。
可以把它们放进一张表:
这四层不是互相替代,而是递进关系。
如果没有 Rules,Automation 只是在定时放大不确定性。
如果没有 Skills,Automation 每次都像重新培训一位新同事。
如果没有 Hooks 或 CI,Automation 可能把错误推进得更快。
如果没有 Automations,前面三层再好,也仍然依赖你记得启动。
所以我不建议一上来就问:“哪些事情可以让 AI 自动做?”
更好的问题是:
哪些已经被规则、技能和验证约束住的流程,值得交给后台按节奏运行?
这个问题一问,自动化范围会立刻收敛。
三个可以直接拿去改的模板
下面这几个模板,适合从低风险开始试。
模板一:AGENTS.md 漂移检查
这个场景来自 OpenAI customization 文档[4]里的建议:重复错误、读取路径过散、PR feedback 反复出现时,应该更新 AGENTS.md;也可以用 Automations 定期检查 guidance gaps。
每周一上午检查当前项目最近 7 天的 Codex 会话、提交记录和 PR 反馈,判断是否存在应该沉淀进 AGENTS.md 的重复规则。范围:- 只提出建议,不直接修改 AGENTS.md,除非建议非常小且确定。- 优先识别重复错误、重复 review feedback、反复找错目录、反复漏跑验证命令。输出:- 按“建议新增规则 / 建议更新规则 / 不建议改变”三类报告。- 每条建议都要给出证据:来自哪个提交、反馈或会话现象。- 没有明确重复模式时自动归档。边界:- 不要把一次性偏好写成长期规则。- 不要加入和现有规则冲突的内容。这个任务很适合自动化,因为它不需要每天都改规则。大多数时候它应该什么都不做。它的价值在于发现“我们总在同一个地方摔倒”。
模板二:PR 反馈守护
每 30 分钟在当前线程检查目标 PR 是否有新的 review comment 或 CI 失败。方法:- 使用可用的 GitHub 插件或本地 gh 命令读取 PR 状态。- 如果没有新反馈,简短记录并继续等待。- 如果有新反馈,先分类:必须修复、需要澄清、可选建议。- 对必须修复项,先提出最小修改计划;只有低风险改动才直接实现。输出:- 有新反馈:列出反馈、处理动作、需要用户决定的问题。- 无新反馈:不打扰或自动归档。停止条件:- 需要产品决策、接口破坏性变更、数据库迁移、部署权限时停止并询问。这类任务适合 thread automation,因为它需要保留同一个 PR 的上下文。
模板三:内容生产流水线复查
对于内容创作者,Automation 不一定是写代码。它也可以跑稳定的内容工作流。
每天上午根据当前账号定位,生产一篇可发布的技术文章草稿包。方法:- 先读取项目规范、文章索引和账号偏好。- 从 2-4 个候选选题中自主选择一个,避免和已有文章重复。- 如果涉及最新产品或文档变化,必须使用可验证来源,并在 research.md 记录抓取日期、URL 和事实口径。- 按 content-pipeline 执行:research、原始稿、formatted、审校、配图、HTML、发布到草稿箱。输出:- 成功:报告文章目录、关键产物、草稿箱状态、人工复核项。- 失败:保留已完成产物,明确失败阶段、错误信息、下一步人工处理建议。边界:- 不报告未完成发布为成功。- 不关闭浏览器后台,方便人工复核。这其实就是一个典型 Skill + Automation 场景。
Skill 定义生产方法,Automation 负责每天启动一次。文章、图片、HTML、发布状态都落到磁盘和草稿箱,而不是停留在聊天窗口里。
权限:后台运行时要更保守
自动化一旦进入后台,权限就比交互式聊天更敏感。
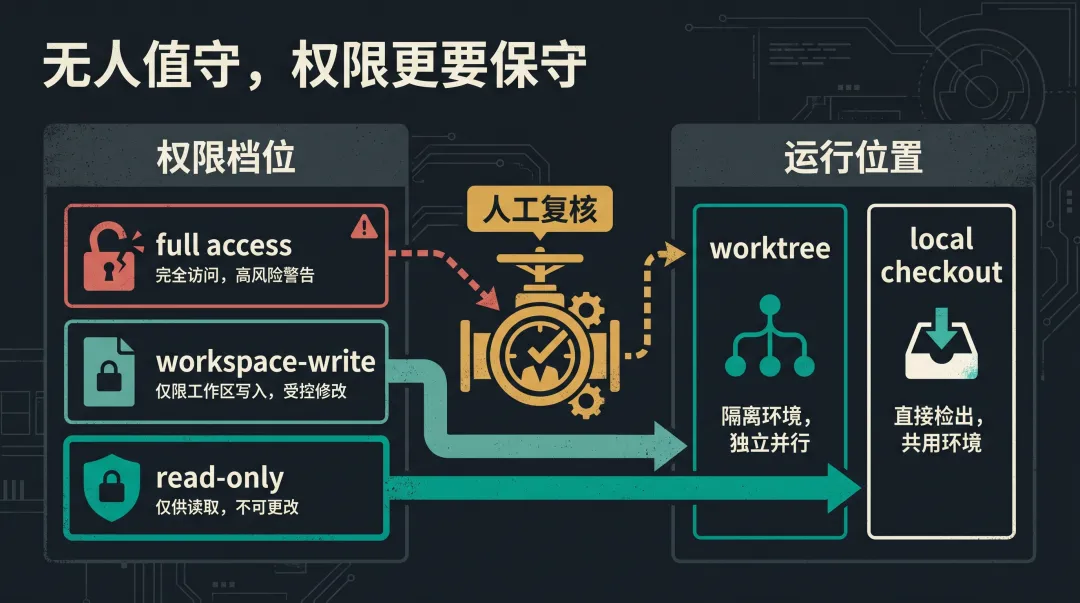
官方文档说明,Automations 使用默认 sandbox 设置;在 read-only 下,需要改文件、访问网络或操作本机 app 的工具调用会失败;workspace-write 会限制工作区外修改、网络和 app 操作;full access 下,无人值守风险更高。
这意味着你不应该为了“省事”直接给后台任务最大权限。
比较稳妥的做法是:
1. 先用 read-only 或 workspace-write 跑报告型任务。 2. 涉及文件修改时优先用 worktree。 3. 把危险命令放进规则或 hooks,而不是靠模型自觉。 4. 第一次调度前手动跑一遍 prompt。 5. 前几次输出必须人工复查,再逐步提高频率和权限。
这和传统自动化没有本质区别。
CI 也不是第一天就能直接部署生产。它先跑测试,再跑 staging,再加审批,再逐步进入发布链路。
Agent 自动化也一样。它只是把“写脚本”升级成“写可理解上下文的后台流程”,但安全边界仍然要靠工程系统来守。
尤其要警惕三类任务:
自动化最怕的不是慢,而是悄悄变得不可审计。
怎么从今天开始用
如果你还没用过 Codex Automations,可以按这个顺序来,不要一步到位。
第一步,选一个只读任务。
比如“每天总结某个目录最近 24 小时提交”。它不会改文件,结果也容易检查。先让你熟悉 Triage、调度频率、输出格式。
第二步,把 prompt 写成 durable prompt。
不要只写一句“帮我总结”。写清楚时间窗口、目录范围、输出结构、没有结果时怎么处理。
第三步,手动跑一次。
官方文档也建议调度前先在普通线程里测试 prompt,确认范围、工具、模型、输出 diff 都符合预期。不要把第一次试运行交给后台。
第四步,低频运行几次。
每天一次比每 10 分钟一次更适合新流程。前几次你要认真看结果:它有没有过度读取?有没有输出废话?有没有漏掉关键证据?有没有提出不该改的文件?
第五步,沉淀成 Skill。
如果你发现 prompt 越来越长,里面开始出现固定步骤、模板、检查清单,那就把它做成 Skill。之后 Automation 只需要调用 $skill-name。
第六步,再考虑写入式自动化。
这时才让它在 worktree 里修小 bug、更新文档、生成草稿。每一步都应该有清晰证据和人工复核点。
这套顺序听起来慢,但它会让自动化变得可持续。
真正成熟的 Agent 工作流,不是让 AI 获得无限自由,而是让它在明确轨道里稳定前进。
结语:把“提醒 AI”变成系统节奏
AI 编程工具已经走过了几个阶段。
第一阶段,是聊天。你问,它答。
第二阶段,是工具调用。它能读文件、跑命令、改代码。
第三阶段,是规则和技能。你开始用 AGENTS.md、CLAUDE.md、Skills、MCP、Hooks 管住它。
第四阶段,就是自动化。你不再每次手动提醒它,而是把稳定流程交给后台节奏。
但这里有一个反直觉的结论:
自动化不是为了让 AI 更自由,而是为了让人的注意力更集中。
AI 负责重复、扫描、整理、草稿、初步修复。
人负责判断、授权、取舍、发布、承担责任。
Codex Automations 的价值不在于“它能自己跑”,而在于它把一件事变得可重复、可复查、可沉淀。
当你发现某段 prompt 已经连续复制了三次,就该问自己:它是不是该变成 Skill?
当你发现某个 Skill 已经稳定运行了三次,就该问自己:它是不是该变成 Automation?
这就是从“会用 AI”到“经营 AI 工作流”的分界线。
关注「ArcThink」,把复杂的信息讲得更明白,把零散的想法整理成有价值的理解与认知。
如果这篇文章对你有帮助,欢迎点赞、在看、转发,让更多人看到。
引用链接
[1] OpenAI Codex Automations 文档: https://developers.openai.com/codex/app/automations[2] OpenAI 的最佳实践: https://developers.openai.com/codex/learn/best-practices#use-automations-for-repeated-work[3] 官方文档: https://developers.openai.com/codex/app/automations#thread-automations[4] OpenAI customization 文档: https://developers.openai.com/codex/concepts/customization#when-to-update-agentsmd
