 夜雨聆风
夜雨聆风


5月25日,在全球AI算力需求的井喷式增长与半导体工艺逼近物理极限的巨大张力之下,华为公司董事、半导体业务部总裁何庭波在上海举行的2026国际电路与系统研讨会(ISCAS 2026)上,扔下了一颗震撼全球科技圈的“重磅炸弹”——正式发布了指导半导体产业演进的全新原则:“韬(τ)定律” 。
这是中国在全球半导体领域首次系统性地提出产业发展的指导新原则。它的出现,标志着一场为“AI算力荒”量身打造的破局之战,正式打响了信号枪。

近两年,中国AI产业以日均Token调用量突破140万亿次的爆发式增长,向全世界展示了人工智能应用的滚烫活力。然而,巨大的应用需求与有限的算力供给之间,正裂开一道难以弥合的鸿沟。要理解韬定律的革命性,必须先看清这套运行了60年的旧规则——摩尔定律,如今为何已经跟不上AI的脚步。
AI大模型训练所需的核心算力,正以每3至4个月翻一番的速度暴增。与之形成鲜明对照的是,摩尔定律所依赖的“几何缩微”——靠不断缩小晶体管面积来堆密度、压成本——正撞上三座无法逾越的高墙。
一是物理墙。 目前最先进的纳米级芯片栅极宽度仅相当于十几个硅原子,再缩下去,量子隧穿效应将使电子彻底失控,晶体管将名存实亡。
二是经济墙。 以前研发新工艺能省成本,如今设计一颗最先进芯片的研发预算已经超过10亿美元,建一条先进产线动辄数百亿美元。工艺越先进,单个晶体管的造价不降反升。
三是性能墙。 在系统层面制约性能的早已不是晶体管开关速度,而是RC时间常数——信号在芯片内部“长途跋涉”的延迟才是真正的“性能卡点”。管子做小了,但数据搬不动,性能依旧上不去。
正因为摩尔定律在这三重瓶颈下逐渐失灵,全球半导体产业亟待寻找新的性能增长引擎。而华为韬定律提出的“τ缩微”——以“时间”而非“纳米”作为衡量进步的标尺,便是在这一背景下应运而生。

从名字上看,“韬”取自希腊字母τ(tau),在电子学中代表“时间常数”——即信号从一种状态切换至另一种状态所需的时间。τ越小,电路切换越快,芯片性能越强。这种命名本身就将华为的突围路径一语道破:不再死磕“把晶体管做得多小”,而是一门心思琢磨“如何让信号跑得更快”。
具体到执行层面,韬定律构建了一个贯穿器件、电路、芯片和系统四个层级的全栈协同优化体系,将压低“时间成本”作为统一的、可量化的进化目标。这意味着,原本芯片性能的代际提升只是晶体管层面的单兵突进,而现在,每个层级的从业者都领到了同一张任务卡——压缩时间常数τ,让整个系统“跑得更快”。
半导体产业的演进逻辑由此发生了根本性转变:从“芯片能做多小”,转向“计算能有多快、系统响应能有多及时”。
有了全新的底层逻辑,还需要匹配落地的技术工具。韬定律不是空洞的理论框架,而是一套以“时间缩微”为总领的全套技术工具箱。其中四根关键支柱环环相扣,精准覆盖了AI算力从底层到顶层、从单芯片到集群系统的全方位痛点。
第一,器件层优化。 从物理底层压缩时间常数,通过优化晶体管和互连的电阻及寄生电容,让每一次信号切换都少一分等待、多一分效率。
第二,逻辑折叠技术。 这是韬定律的“杀手锏”级突破。逻辑折叠的本质是把数字、模拟和存储电路从平面“平铺”改成垂直“堆叠”,相当于在芯片内部搭建起立体交通网络。固定器件节点下,该技术实现了晶体管密度55%的阶跃式提升和41%的能效增益——仅靠架构创新,不动制程工艺,就能直接拉升AI芯片的性能。
第三,全栈软硬芯协同。 基于实际工作负载实现指令流和数据流的细粒度控制,大幅降低端到端执行时间。这种芯片、架构与软件一体化的协同设计,是AI大模型跑得快、跑得稳的关键保证。
第四,系统级互联重构。 华为定义了“灵衢”总线,以统一内存编址和原生内存语义大幅降低系统通信时延。在AI集群层面,结合近封装光学I/O及3D折叠技术,更将打破机柜间数据搬运的天然瓶颈。
这四层技术层层递进,从单管到集群,从硬件到软件,形成了一套为AI算力量身定制的系统性破局方案。
很多宏大理论都可能沦为空话,但韬定律不是。何庭波在演讲中给出了实打实的家底数据:过去六年,华为基于韬定律的设计理念,已成功设计并量产了381款芯片,横跨移动通信、AI计算、汽车等多个领域,覆盖千行百业的需求。
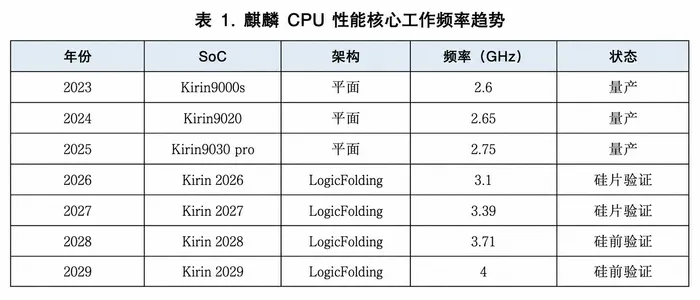
手机端,“麒麟2026”将在今年秋季首次完整采用逻辑折叠架构,CPU性能核心频率提至3.1GHz。按华为的规划,到2029年,这一频率将正式突破4GHz大关。在不提升功耗的前提下,用户能直接感受到应用加载速度的跃升和续航能力的强化。
而在AI赛道这条更关键的航道上,今年即将登场的昇腾950率先采用3D堆叠和Chiplet集成,到2030年前后的昇腾990将进一步引入逻辑折叠技术,首次把韬定律批量注入AI加速器领域。预计到2035年,AI硬件集成度将实现超过100倍的增长。
何庭波还在发布会上给出了一个颠覆性预测:预计到2031年,基于韬定律的高端芯片晶体管密度将达到等效1.4纳米制程的水平。而台积电的1.4纳米工艺依赖极紫外光刻机,单厂投资高达1.5万亿新台币量级。相比之下,韬定律的路径更经济、更可控,也为国产算力提供了扎实的底牌。
当AI被问到“韬定律相比摩尔定律在AI应用中有哪些系统性优越”时,分析指向了算力成本、功耗效率和算力供给三个层面的重构。
算力成本端: AI集群中超过80%的能源其实都浪费在数据搬运上。韬定律通过缩短数据移动路径,大幅降低能耗,让每单位Token的算力成本具备实质性压降空间。这对中文AI生态来说意义尤为重大——国内企业可以通过自主可控的架构路径,对冲先进工艺受限带来的供给侧冲击。
功耗控制端: 华为的逻辑折叠在7纳米固定节点下直接实现了41%的能效增益。这意味着同等算力需求下的电费账单大幅缩水,对规模化大模型训练群体而言,其降本效应将是决定性变量。
算力供给端: 韬定律还触发了国产算力产业链的全线价值重估。开源证券指出,华为提出的这一新演进逻辑,有望帮助国产算力在一定程度上摆脱对先进制程的依赖。现有成熟工艺产线就足以支撑高端AI芯片制造,利好光互联、液冷和整个国产AI全产业链。摩根士丹利也强调,韬定律是支撑AI光收发器产业指数级增长的基本理论,光通信凭借其低延迟、高带宽的固有优势,与韬定律高度契合。

韬定律的提出,其意义远不止于一家公司的技术路线升级。它更像何庭波在演讲结尾强调的“未来一定属于开放合作”的体现——在全球半导体产业从工艺竞赛转向系统竞赛的关键节点上,华为在尝试重新定义下一代芯片的演进逻辑。它把“尺寸竞争”这一单维度的制程内卷,拓展为器件、电路、芯片和系统的四维全栈竞赛——让“算力赋能”的核心命题从“依靠更尖端的工厂”延伸到“依靠更智慧的系统架构”。
资本市场很快给出了反馈。开源证券迅速判断,韬定律有望催化光通信、液冷、国产算力三大细分赛道迎来价值重估。其底层逻辑是:芯片性能不再仅靠晶体管密度说了算,系统集成能力和全栈协同能力将释放更高的价值权重,并直接转化为更低的算力成本和更可控的供应链风险。
对国产AI产业而言,这无疑是一场“及时雨”。随着算力瓶颈逐步解开,中文AI大模型在Token调用量屡创新高的基础上,又将迎来新一轮算力红利的加速释放——从更便宜的推理成本到更广泛的智能应用场景落地,韬定律的真正红利,还需要一段时间的量产落地才能充分释放。但它首先给了行业一个清晰的方向感。
2026年5月25日,何庭波发出“韬定律”——用“时间”替代“面积”,用“信号跑多快”替代“晶体管多小”。当全球半导体产业在AI算力的天量需求与物理极限之间焦虑徘徊时,华为以381款量产芯片的实战成绩正面作答:算力提升的路径不止一条。
技术爆发只是起点,深度的产业契合才是技术走向商业价值的“通行证”。对正在经历Token调用量指数级增长的中文AI产业而言,韬定律提供了一条自主可控、可预期、可量产的算力演进路线。当AI硬件集成度在未来十年增长百倍、当等效性能追平1.4纳米制程级别的水平,那些曾经被高昂电费“劝退”的应用场景,也许就会水到渠成地迎来真正的爆发。
本文基于公开信息整理,仅供参考。




