 夜雨聆风
夜雨聆风从云端到桌面,这位“口袋里的超算”正在改写AI开发规则

过去,AI开发者往往面临一个两难选择:要么斥巨资搭建本地算力平台,要么忍受云端算力的排队等待和高昂成本。直到华硕与NVIDIA联手推出了Ascent GX10,这个困局终于迎来了破局者-。
今天,就让我们一起走进这台被戏称为“大模型神器”的迷你超级计算机——华硕Ascent GX10。
一、这是一台什么样的设备?
简单来说,华硕Ascent GX10是一台迷你桌面型AI超级计算机,它的核心任务只有一个:让开发者能够在自己的办公桌上,运行原本只存在于数据中心级别的超大参数AI模型。
它的尺寸仅为150×150×51mm,体积不足1.5升,重量仅1.48kg。你可以轻松把它摆在办公桌上,接上电源就能开始AI开发。这样小巧的身形背后,藏着的是足以媲美数据中心级的强大算力。
一句话定位:专为AI开发者和研究人员打造的桌面级AI算力解决方案。
二、产品核心特性详解
🔥 性能核心:NVIDIA GB10 Grace Blackwell超级芯片
Ascent GX10的心脏是NVIDIA专为桌面AI设计的GB10 Grace Blackwell超级芯片,这是一款在同一颗芯片内封装了20核Arm架构Grace CPU与Blackwell GPU的超级芯片。
20核Arm处理器:包含10个Cortex-X925超大核和10个Cortex-A725核心,优化数据预处理与调度,加速模型微调和实时推理
Blackwell GPU:搭载第五代Tensor Core,支持FP4数据格式,可大幅提升推理效率

🚀 惊人算力:1 petaFLOP AI性能 + 2000亿参数支持
在FP4精度下,Ascent GX10可提供高达1 petaFLOP(每秒千万亿次浮点运算)的AI算力,足以支撑最前沿的大规模AI工作负载。
更关键的是,它配备了128GB LPDDR5X统一内存,CPU和GPU共享同一内存池,可以灵活分配100GB以上作为显存使用-56。这意味着,你的桌面可以直接运行2000亿参数级别的大型语言模型——这些参数规模的模型,以往只能托管在云端数据中心。

⚡ 高速互联:NVLink-C2C + ConnectX-7
Ascent GX10采用了NVIDIA NVLink-C2C技术实现CPU与GPU间的超高速互联,带宽是PCIe 5.0的五倍,CPU和GPU之间实现了无缝的数据共享与协作。
此外,设备内置NVIDIA ConnectX-7 SmartNIC(智能网卡) ,支持高达200Gbps的超低延迟传输。

🧊 冰川散热:7×24小时稳定运行
GX10采用华硕独家的冰川散热架构,通过真空腔均热板、液态金属导热和双风扇设计的组合,即便满负荷运行也能保持45分贝以下的静音环境-。散热系统还包含57个超宽鳍片(总散热面积高达161549mm²)和五根热管的组合,配合智能温控系统,确保设备可以7×24小时稳定运行-23。
🔌 丰富接口:全面适应各类场景
后置接口:
3个USB 3.2 Gen 2×2 Type-C(20Gbps,支持DisplayPort 2.1替代模式)
1个USB Type-C接口(180W PD输入,符合PD 3.1 EPR标准)
HDMI 2.1a接口
10 GbE RJ45网口
ConnectX-7 NIC QSFP端口
无线连接:
Wi-Fi 7 + 蓝牙5.4

存储方案:
1TB M.2 2242 NVMe PCIe 4.0 SSD(入门级)
2TB M.2 2242 NVMe PCIe 4.0 SSD(进阶)
4TB M.2 2242 NVMe PCIe 5.0 SSD(专业级)
三、可扩展架构:从单机到集群的升级路径
Ascent GX10不仅单机能力出众,更支持高速扩展。通过ConnectX-7端口,你可以将两台GX10设备串联堆叠:
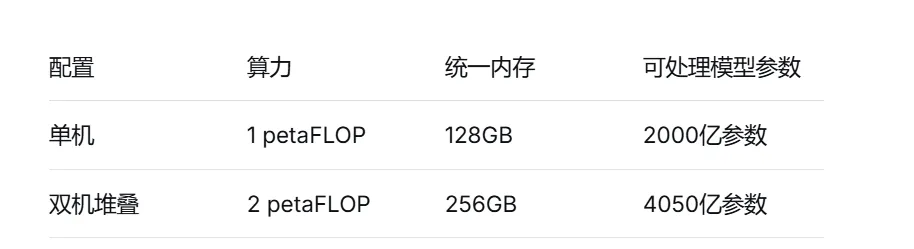
这意味着,当项目规模扩大时,你只需增加一台设备,就能轻松驾驭Llama 3.1等405B参数级别的前沿模型-。
至顶AI实验室的实际测评显示,三台GX10互联后,统一内存池突破300GB,可以稳定运行Qwen3.2 235B这样的超大模型。

四、应用场景全解析
场景一:AI研究与高校实验室
典型用户:高校AI研究团队、科研院所、量子计算/光子学实验室
多伦多大学集成光子学研究团队就是一个典型案例。该团队需要高保真度的科学模拟以及AI辅助设计自动化工具的持续迭代。传统方案下,他们不得不依赖云端算力,但云端既存在高昂的成本,也面临数据隐私和网络延迟的困扰。选择Ascent GX10后,团队实现了大语言模型的本地部署,科研人员可以直接在实验室环境内完成光子电路的设计与优化,迭代效率大幅提升。
场景二:AI技术公司与企业研发中心
典型用户:AI创业公司、软件开发商、企业的AI创新团队
对于AI技术公司而言,模型的原型设计、微调和推理是日常工作。以往这些工作要么依赖昂贵的GPU工作站,要么需要向云端平台支付持续高昂的API调用费用。Ascent GX10的本地化部署方案,让AI应用开发的成本显著降低,同时敏感数据始终存储于本地,解决了数据合规和安全方面的隐忧-。
一位开发者实测显示,用GX10运行70B规模的模型时,生成速度可达4.5 tokens/秒;运行14B的DeepSeek-R1时,速度超过20 tokens/秒。
场景三:教育机构与AI培训
典型用户:大学的AI课程教学、职业培训机构、中小学STEM教育
传统的AI教学内容往往停留在理论层面,学生难以真正上手训练大模型。GX10以极小的体积提供数据中心级的算力,可以部署在任何教室、实验室甚至办公桌上-55。在Ascent GX10的支持下,师生可以绕过云端平台的昂贵成本和隐私担忧,直接在本地部署最前沿的大语言模型进行教学实践。
场景四:企业边缘计算/本地部署
典型用户:医疗机构(病历分析)、金融企业(风控模型)、制造业(质检分析)、政府机构(安全需求)
对于金融、医疗、政府等对数据安全有极高要求的机构而言,云端部署显然不是最优方案。Ascent GX10让这些机构拥有了一个“私有、本地化、高性能”的AI算力节点,在安全可控的前提下快速构建AI能力。
例如在医疗领域,可以结合大语言模型进行病历分析和诊疗辅助的本地部署;在制造环节,GX10可以分析大量数据,检测出在特定条件下才能发现的设备制造问题。
场景五:机器人学、计算机视觉与多模态AI开发
典型用户:机器人公司、自动驾驶技术团队、计算机视觉研发团队
GX10完美支持机器人学、计算机视觉和视觉语言模型(VLMs)等领域的AI应用开发,为原型设计、模型微调和推理提供全栈工具支持。某自动驾驶实验室实测表明,其环境感知模型迭代速度较传统云端方案提升3倍。

五、为什么选择Ascent GX10?六大核心优势总结
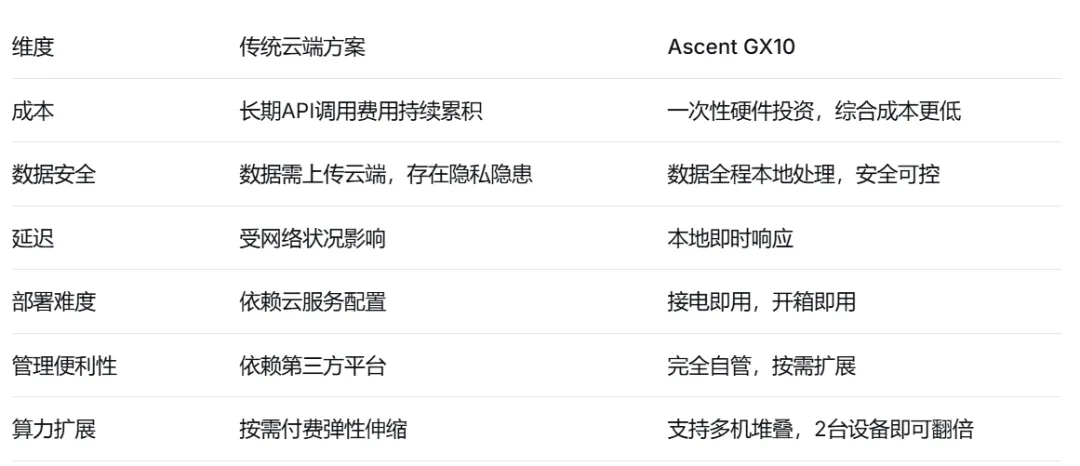
相比NVIDIA官方的DGX Spark,华硕在相同的核心硬件规格基础上优化了散热设计并提供更灵活的本地存储配置选择,对成本敏感且追求高性能的开发团队而言更具吸引力。
需要特别说明的是:Ascent GX10的运行平台是基于Ubuntu的NVIDIA DGX OS(ARM架构),不兼容普通的Windows应用或传统x86游戏-13。这是一款为AI开发而生的专业工具,适合对ARM/Linux环境有基本了解或愿意学习的AI研究人员、数据科学家和技术团队。
结语:AI开发的下一个十年,从桌面开始
Ascent GX10绝非一台普通的迷你主机——它是AI从云端“下沉”到桌面的标志性产品,是AI民主化进程中的重要里程碑。它将原本蛰伏于数据中心的超级计算能力封装进桌面设备,让AI研究人员、开发者和企业用户可以在桌面上完成从前难以想象的工作。
Ascent GX10不仅是一个潜力巨大的硬件产品,更意味着一个新赛道的开启。在2025-2026年AI应用加速落地的浪潮中,谁能最早把“桌面级AI超算”的价值传递给目标客户,谁就能抢占先机。
