夜雨聆风
夜雨聆风
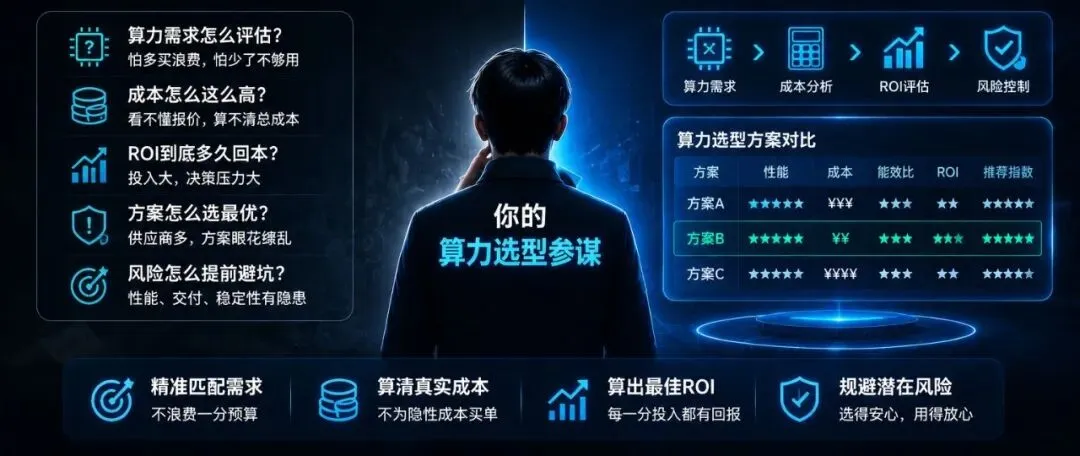
昨天那篇5笔账,有人留言说"我拿不出50万硬件预算,怎么搞?"这篇就给你答案。不讲二手卡、不走野路子、不说"凑合凑合就行"。三套方案——纯租赁、新硬件自建、混合架构——全部走正规渠道,全部有售后保障。
━━━━━━━━━━━━━━━━━━━━

| 昨天那篇5笔账吓到你了?别怕,这篇来"解绑"
先确认一件事。
昨天我们算了5笔账——硬件、电力、散热、人力、折旧——结论是10台服务器起步的中型集群,支出规模在百万级。
看完那篇,有人私信说:"我公司才15个人,你说的那些我根本用不上。"
说得对。那篇是给"打算上规模化算力"的人看的。今天这篇是给"想用AI但预算有限"的人看的。
你的场景大概率是这样的:
▪️ 团队十几人到几十人,需要一个内部知识库或客服问答系统
▪️ 数据敏感(客户资料、合同、财务),不能上公有云API
▪️ 并发不超过10人
▪️ 不需要训练大模型,只做推理
这个场景下,你不需要几十台服务器,不需要全职运维团队,不需要液冷机房。
但是有一条底线不能破:不碰二手硬件,不走非正规渠道。
为什么?三条理由,都很实在:
▪️ 二手显卡没有保修。一张3070在矿场里跑了两年,到你手里两个月就挂了,找谁?
▪️ 没有安全审计。你不知道那张卡被刷过什么BIOS、装过什么后门。
▪️ 跟不上发展。2026年的模型(DeepSeek V4、Qwen3)对显存和驱动有硬性要求,三代前的卡跑不动新模型。
所以这篇的方案,全部基于全新正品 + 正规渠道 + 有保修。不是最省钱的方案,是"最安全且花得值"的方案。
━━━━━━━━━━━━━━━━━━━━

| 方案A:纯GPU云租赁——最省心
纯租赁:5万 ≈ 约8-10个月独享GPU实例租金(按市场均价),如果你的团队没有IT运维人员,这是首选。
怎么做:
在你信任的云厂商(阿里云、腾讯云、华为云昇腾智算)或正规GPU租赁平台上,租一台独享GPU实例。选"独享"而不是"共享"——共享实例虽然更便宜,但其他租户抢占算力时你的推理延迟会飙升。
硬件配置逻辑:
GPU选≥24GB显存。7B模型推理约需8GB,14B约需16GB,但加上KV缓存(上下文越长缓存越大)、系统开销和并发队列——24GB是保证不OOM(显存溢出)的安全线。如果你将来可能上更大的模型,起步就选24GB。
存储配500GB SSD。一个模型文件通常10-30GB,加上知识库数据和日志,冗余空间留够。不要配HDD机械硬盘——模型加载速度会慢一个数量级,每次重启服务都要等半天。
你能得到什么:
▪️ 跑通7B-14B参数的开源模型(Qwen3-8B、DeepSeek V4 Flash),推理延迟≤2-3秒
▪️ 5-10人并发无压力
▪️ 平台承担安全隔离、硬件保修和99.9%的SLA
▪️ 不需要自己管电力、散热、运维——这些服务商全包了
这份方案不适合什么:
▪️ 数据极度敏感(金融、医疗合规要求数据不出物理内网)
▪️ 需要7×24小时不间断推理(云平台偶尔有维护窗口)
▪️ 长期看3年以上——累计租金会超过自建成本
━━━━━━━━━━━━━━━━━━━━

| 方案B:新硬件自建——最安全
新硬件自建:约3.5-4.5万一台24GB显存整机 + 预留缓冲金,如果你的业务数据不能出内网——选这套。
硬件配置逻辑(不讲价格,只讲为什么是这个规格):

选16GB显存还是24GB显存的GPU?
▪️ 16GB:7B-14B模型推理,5-10人并发,够用。当前主流模型(Qwen3-8B、DeepSeek V4 Flash 7B版本)全在这个显存范围内。
▪️ 24GB:14B-32B模型推理,20人并发。如果你预计一年内要上更大的模型,一步到位买24G,免得到时候整机升级。
部署软件(全免费开源):
▪️ Ollama:一行命令拉取模型。ollama pull qwen3:8b,5分钟跑起来。不需要配环境变量、不需要编译驱动。
▪️ Open WebUI:给Ollama加一个ChatGPT风格的聊天界面,你的员工不需要学命令行,打开浏览器就能用。
▪️ vLLM:当并发上去了,把Ollama换成vLLM,吞吐量提升3-5倍。两个工具API接口兼容,切换成本近乎为零。
这套方案的核心优势:
▪️ 硬件按3年折旧,每年摊下来的成本非常低
▪️ 软件全部免费(开源),没有授权费
▪️ 电力:单台机器每天开机8小时,一个月电费不超过一台空调
▪️ 最关键的一点——你的数据从没离开过这台机器
这份方案不适合什么:
▪️ 需要弹性扩容(物理机跑满了就是跑满了,不像云端可以随时加GPU ▪️ 突发的大规模计算需求(比如突然要用百万条数据做一轮批量分析)
━━━━━━━━━━━━━━━━━━━━

| 方案C:混合架构——最灵活
如果你想"安全的数据留在内网,重活丢给云端"——这是你的方案。混合:约2万本地节点 + 剩余3万按需租用云端
架构设计:
▪️ 本地轻量推理节点:一台中配PC(不含高端独显,CPU+内存+SSD即可),跑最敏感的日常问答。客户资料、财务数据——永远不出内网。 ▪️ 云端GPU:当需要跑大模型、做批量处理时,临时租用云端GPU实例,按小时计费。用完即停,不养闲卡。
为什么这样设计:
你日常80%的AI调用量是"帮我搜一下这个合同""这个客户上个月的沟通记录总结一下"——这种轻量推理,一台没有高端显卡的PC用CPU跑都能处理,延迟是可接受的。
剩下20%的重活——"帮我把这一万份简历筛出符合条件的100份"——一个月可能就发生两次。为这两次买一张高端显卡,相当于为了一年用两次的东西付了一整年的钱。
混合架构的逻辑就是:日常够用即可,峰值按需租赁。
成本画像:
投入分两笔——本地节点一次性买断,云端按实际使用量付费。因为本地不需要独显,机器成本降了一大截;云端用在刀刃上,按月算可能就几百块。用得越多云端花的越多,用得少云端几乎没成本——弹性完全在你手里。
这份方案的精髓:
你不需要为"可能用到"的算力提前买单。不需要猜"我一年后用量涨多少"。涨了就多用云端,没涨就本地跑。
这份方案不适合什么:
▪️ 每天都有大量推理请求(那样云端累计费用不如自建)
▪️ IT能力特别弱的团队(需要有人判断什么时候该开关云端实例)
━━━━━━━━━━━━━━━━━━━━

| 三套方案,一张表帮你选
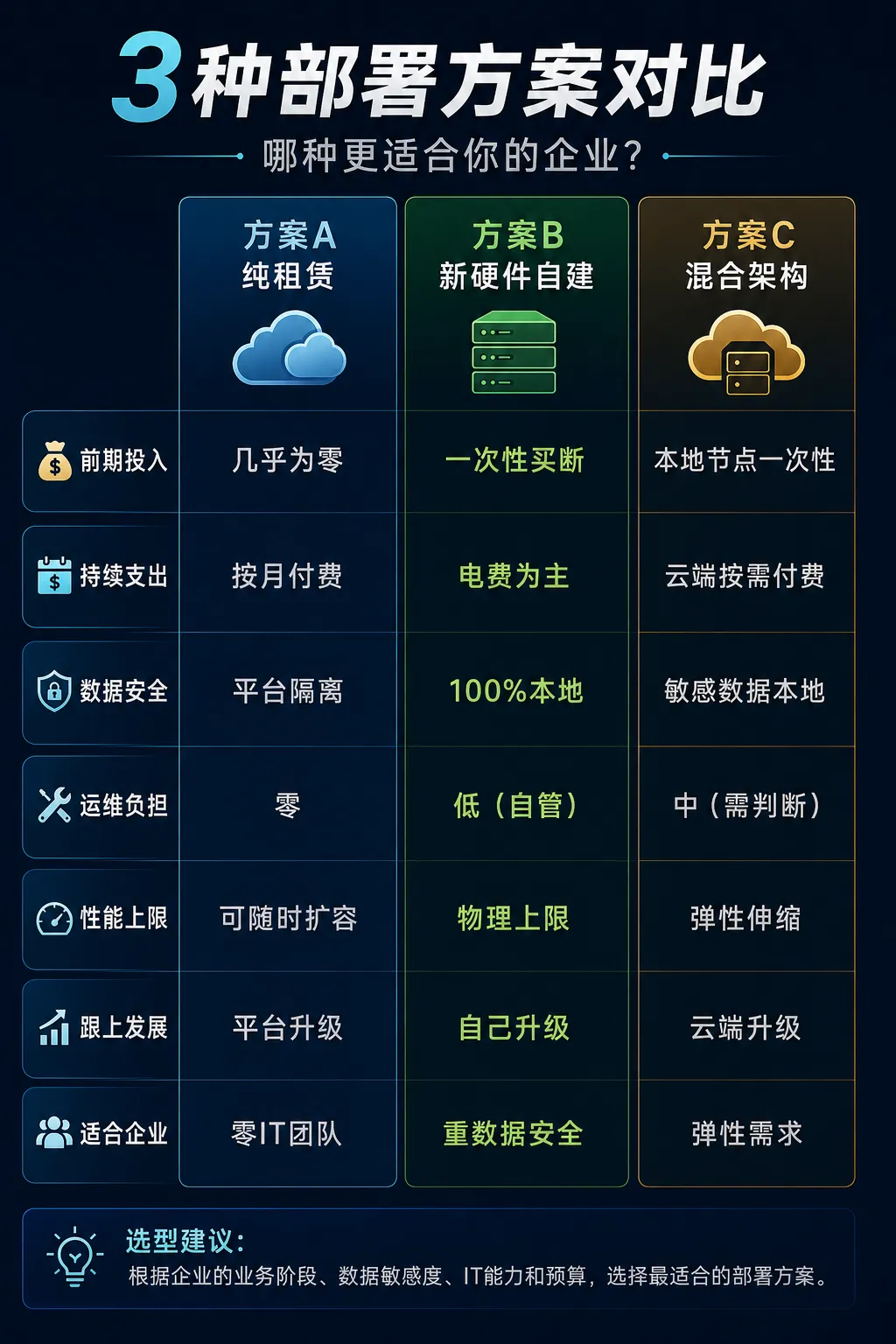
三个信号,帮你判断选哪套:
▪️ 信号一:你的数据有多敏感?
如果客户资料泄露=公司倒闭 → 选B(自建)。 如果主要是内部文档和操作手册 → 选A或C。
▪️ 信号二:你公司有人能搞定Linux命令行吗?
有 → 三套都可以。完全没有人 → 选A(纯租赁)。
▪️ 信号三:你预计一年后的用量是现在的多少倍?
2倍以内 → 自建够用。不确定 → 选C(混合),保持弹性。
━━━━━━━━━━━━━━━━━━━━

| 五条安全底线,小企业最常踩的坑
中小企业在AI部署上最容易犯的错误,不是"买贵了",是"买错了"。以下五条,每一条都来自真实踩坑案例:
底线一:渠道正规,发票齐全。 不要在拼多多/闲鱼上买"工包卡""拆机卡""矿卡翻新"。在京东自营、品牌官方旗舰店、授权经销商处购买,保留发票和保修凭证。一张显卡如果价格远低于正规渠道当天的标价——基本是翻新或者来路不明的卡。省下的差价不够你处理一次数据事故。
底线二:软件走开源官方渠道。 Ollama从官网(ollama.com)或GitHub Release页面下载,不要用第三方打包的"汉化版""绿色版"。模型从HuggingFace或ModelScope官方仓库拉取,hash值要对得上。
底线三:内网部署,物理隔离。 私有化部署的核心价值是"网络不可达"。把你的AI服务器放在内网,不暴露公网IP。员工只用内网地址访问。这一点做到了,90%的攻击向量直接切断。
底线四:账号权限最小化。 不管你用的是Ollama还是Open WebUI,默认设置往往权限过于宽松。部署完成后第一件事:关掉默认的管理员账号,给每个员工单独建账号,按需分配权限。有人离职,第一时间注销。
底线五:定期备份模型和数据。 模型文件通常几十GB,知识库数据可能几百MB。准备一个外置硬盘,每月做一次全量备份。不是怕硬件坏——是怕勒索病毒把你唯一的数据副本加密了。
━━━━━━━━━━━━━━━━━━━━
💬 互动问题
A. 看完三套方案,你目前最可能选哪个?
① 纯租赁(省心) ② 新硬件自建(安全)
③ 混合架构(灵活) ④ 还没想清楚
B. 你公司目前最大的AI部署障碍是什么?
① 预算有限 ② 没有IT人员
③ 数据安全顾虑 ④ 不知道从哪开始
如果你的答案是A④或B④——你可能需要一次15分钟的免费场景诊断。评论区直接说"想聊聊",我会一一回复。
━━━━━━━━━━━━━━━━━━━━
关注我,你的算力选型参谋。 这里不是AI新闻速递——是帮你算清楚每一笔算力账的地方。