 夜雨聆风
夜雨聆风如果你用过 ChatGPT 写代码,大概经历过这样的流程:复制代码 → 粘贴到对话框 → 描述问题 → 把改好的代码贴回去 → 保存 → 来回切换。
Claude Code(简称 CC)彻底改变了这个模式。
CC 不是一个"聊天框里的代码助手",而是一个驻留在你终端里的 AI 编程 Agent。它拥有对文件系统的直接访问权限,可以读文件、写代码、执行命令、搜索整个代码库——就像一个能理解自然语言的资深工程师坐在你旁边,直接操作你的项目。
它与普通 AI 聊天的核心区别:
| 交互方式 | ||
| 代码感知 | ||
| 动手能力 | ||
| 执行流程 |
本文将从架构层面,拆解 CC 的内部引擎是如何工作的。
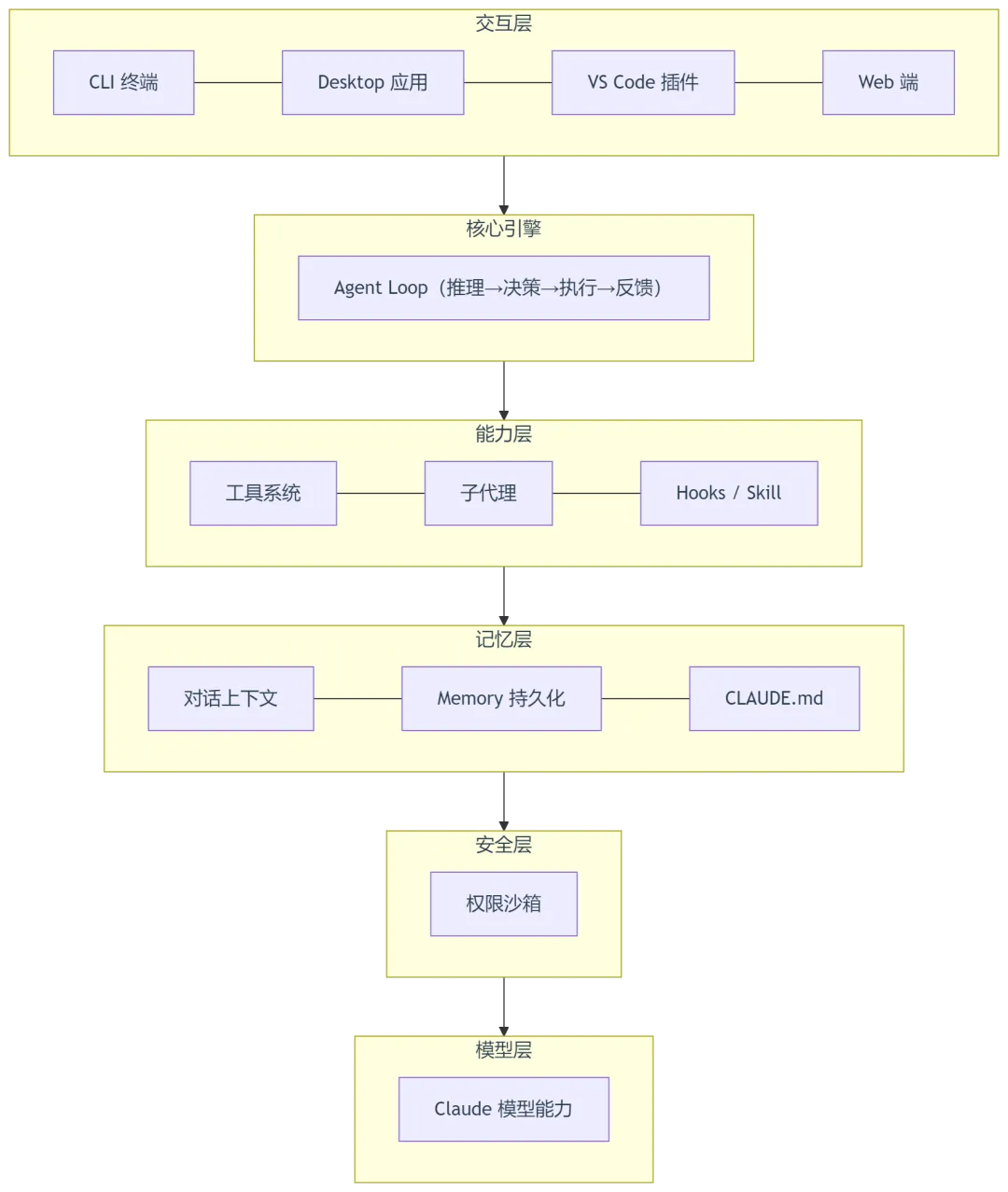
二、核心循环:Agent Loop
CC 的一切工作都围绕一个核心机制——Agent Loop(代理循环)。
2.1 循环流程
这不是传统的"一问一答",而是一个持续循环:
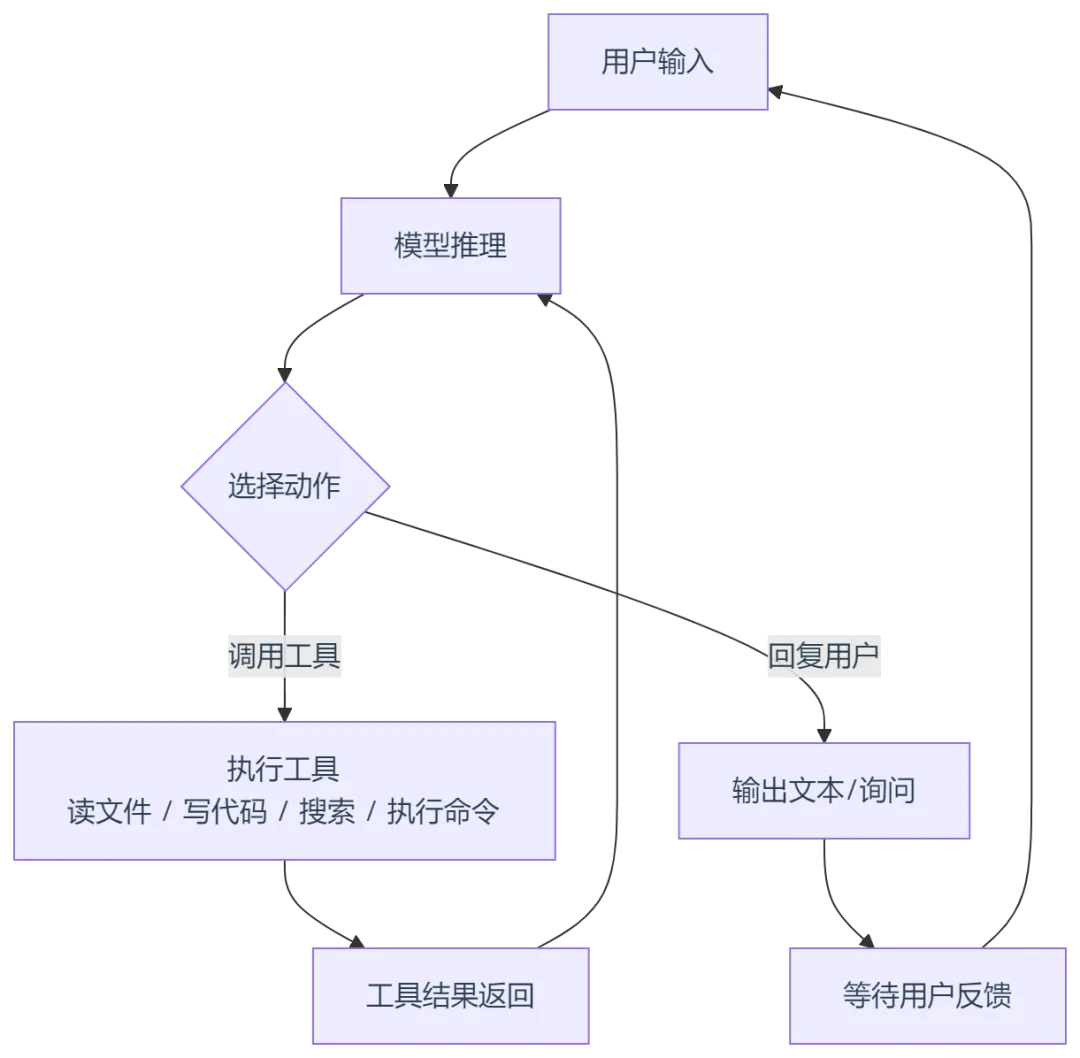
2.2 关键理解
在这个循环中,模型自己是决策者。每一轮它都要决定:
是不是该说句话回复用户? 是不是该读某个文件? 是不是该执行一个 shell 命令? 是不是该修改某行代码? 任务是不是完成了?
这就是 Agent Loop 的核心思想:模型不再是被动回答问题,而是主动驱动工作流。
这也解释了为什么 Agent Loop 如此重要——传统 AI 问答是"你问一句,它答一句"的模式,而 Agent Loop 让 CC 具备了独立完成任务的能力:它可以从"修复这个 bug"这样模糊的指令出发,自主规划步骤、执行操作、根据结果调整策略,直到 bug 真的被修好。
三、工具系统:AI 的"手脚"
模型本身不能直接操作你的电脑。Agent Loop 中的"执行工具"这一步,靠的就是 CC 的工具系统——这是 AI 与真实世界交互的桥梁。
3.1 CC 的核心工具
| 文件读取 | ReadGlob、Grep | |
| 文件写入 | EditWrite | |
| 命令执行 | Bash | |
| 网络 | WebFetchWebSearch | |
| 任务管理 | TaskCreate/Update | |
| 子代理 | Agent | |
| 定时任务 | CronCreate/Delete |
3.2 工具的设计哲学
每个工具的设计都遵循一个原则:让模型更容易做出正确决策。
Edit工具要求你指定 old_string和new_string,而不是简单地"替换第 30 行"——因为模型可能数错行号Grep使用 ripgrep,在大型代码库中秒级搜索 工具调用失败时会返回明确的错误信息,帮助模型自我修正
3.3 工具调用的幕后
当模型决定"我要调用 Read 工具读这个文件"时:
模型输出一个结构化的工具调用请求 CC 的运行时解析这个请求,执行对应操作 结果(文件内容或报错信息)以 tool_result 的形式返回给模型 模型看到结果,决定下一步怎么做
这个循环每轮都在毫秒到秒级别完成,给用户的体感就是模型在"流畅地工作"。
四、子代理架构:并行工作的秘密
当你让 CC 做一件涉及多方面探索的任务(比如"查一下这个目录的结构,同时搜一下某个函数在哪里定义的"),CC 不会一个一个地顺序执行——它会启动子代理并行工作。
4.1 什么是子代理?
子代理(Sub-agent)是一个独立的、短暂的 Agent 实例。它拥有自己的上下文窗口,在后台运行,完成任务后返回结果。
4.2 工作模式
主 Agent 分析任务需求├── 启动子代理 A → 搜索文件内容├── 启动子代理 B → 查找代码引用└── 启动子代理 C → 获取外部文档↓所有子代理返回结果↓主 Agent 汇总、分析、执行
4.3 适用场景
- 并行搜索
:同时在多个位置搜索不同关键词 - 独立验证
:让子代理审查代码、运行测试、生成报告 - Worktree 隔离
:对高风险操作可以在独立的 git worktree 中运行子代理,失败不影响主分支
这一架构让 CC 在大型代码库中的工作效率远超单线程的 Agent。
五、上下文管理:记忆的奥秘
大语言模型有一个众所周知的限制——上下文窗口有限。一次长时间编程会话可能产生数万行对话历史,CC 是如何应对的?
5.1 自动上下文压缩
当对话接近上下文窗口上限时,CC 会自动执行压缩:
[早期对话内容]→ 压缩为摘要(保留关键信息,丢弃细节)→ 摘要留在上下文中→ 新的对话继续展开
这意味着 CC 不会"失忆",但早期细节可能会模糊化。这是与上下文窗口限制的务实妥协。
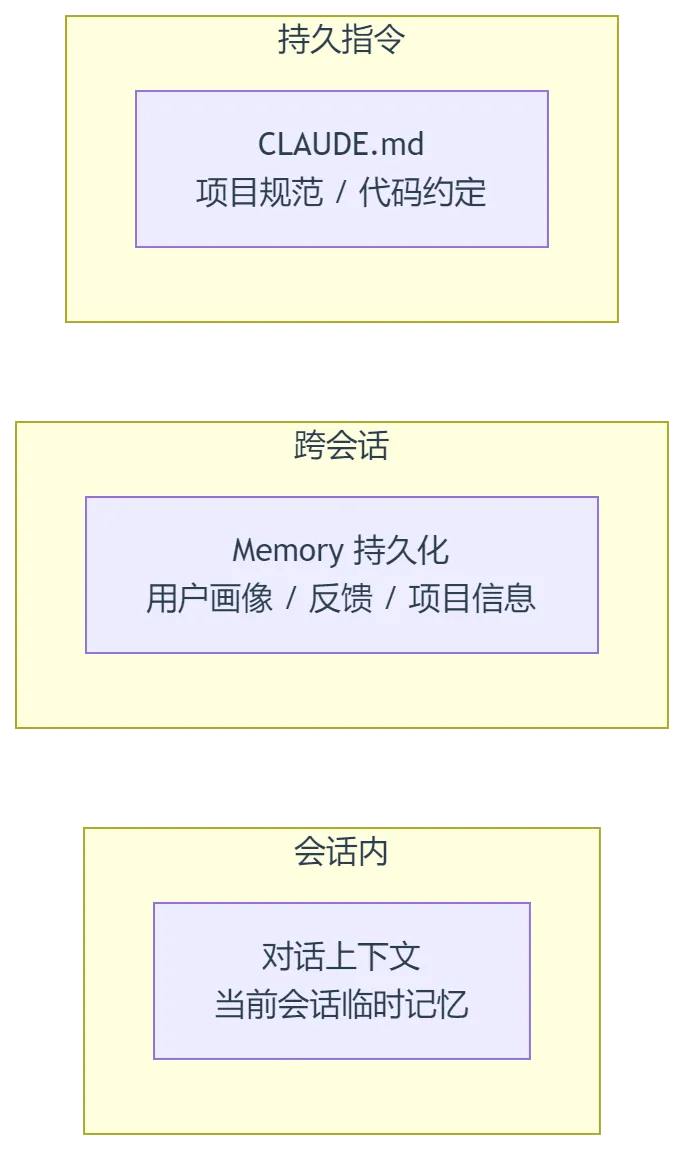
5.2 Memory 持久化(跨会话记忆)
比上下文压缩更强大的是 Memory 系统。它存储在本地文件系统中(~/.claude/projects/<项目名>/memory/),跨会话持久存在。
Memory 有四种类型:
| user | ||
| feedback | ||
| project | ||
| reference |
当 CC 根据用户指令写入 Memory,或在需要时主动读取相关记忆时,便形成一种持续学习的效果——同一个用户在不同会话中不需要重复介绍自己的偏好和项目背景。
5.3 CLAUDE.md:项目级指令
项目根目录或用户全局目录下的 CLAUDE.md 文件,是 CC 的启动配置文件。每次会话开始时,CC 自动加载这些文件,获取:
项目概述和架构 代码规范和约定 常用命令 特殊注意事项
这相当于给 CC 一份"入职手册",让它快速适应项目。
三层记忆的关系可以直观地看作:
六、权限与安全:笼中的猛兽
给一个 AI 模型直接操作文件系统和执行命令的能力,听起来有点危险。CC 通过多层权限系统来控制风险。
6.1 三档权限级别
| 自动允许 | ||
| 每次询问 | ||
| 禁止 |
用户可以在 settings.json 中精确配置每个工具和命令的权限级别。
6.2 权限优化
CC 还能通过 /fewer-permission-prompts 命令自动扫描你的操作历史,识别出你经常放行的安全操作(比如 npm install、git status),批量添加到允许列表中,减少不必要的弹窗——一次授权,后续免扰。
6.3 双重防护
除了权限系统,CC 还有 Worktree 隔离机制(详见第 4.3 节):对高风险任务可以在独立的 git worktree 中执行,即使出了问题,主分支纹丝不动。
七、Hooks 与 Skill:扩展生态
CC 不是封闭系统——它提供了两层扩展机制。
7.1 Hooks:事件驱动扩展
Hooks 允许用户在特定事件发生时自动触发自定义脚本。配置在 settings.json 中:
{"hooks": {"PreMessage": "echo '用户即将输入'","PostToolUse": "node scripts/validate-output.js","PreExit": "git stash drop"}}
支持的事件包括:
PreMessage | |
PostMessage | |
PreToolUse | |
PostToolUse | |
PreExit |
这可以用来做代码风格检查、自动 commit、日志记录等自动化工作流。
7.2 Skill:领域知识封装
Skill 是 CC 的"技能包"——封装了特定领域的专业知识、行为模式和输出规范。例如:
frontend-design | |
explain-code | |
fashion-design | |
security-review | |
verify |
用户可以通过 /skill-name 直接调用技能,或在对话中自动触发。
Skill 背后是一组精心编写的系统提示词,它们引导模型进入特定的角色和思考模式,从而在特定领域产出更专业的成果。
八、多形态部署与底层模型
8.1 同一内核,多种外壳
CC 不是一个单一产品——它是一个内核适配了多种交互形态:
| CLI (终端) | |
| Desktop App | |
| VS Code 插件 | |
| Web (claude.ai/code) |
所有形态共享同一个核心引擎,只是前端壳不同。
8.2 底层模型能力
CC 的能力上限,根本上取决于它所依赖的 Claude 模型的内置能力:
- Tool Use(函数调用)
:模型原生支持结构化工具调用,这是 Agent Loop 的基础 - Thinking(思考)
:模型在回答前进行内部推理,提高复杂任务的决策质量 - 多模态理解
:能读取截图、PDF、流程图等视觉内容 - 长上下文
:支持超大上下文窗口,适合分析大型代码库 - 代码生成
:在编程领域的专项训练
CC 团队还在持续优化提示工程(prompt engineering)——通过精心设计的系统提示来引导模型的行为模式,让这些基础能力发挥出最大效果。
九、一次任务的生命周期
让我们用一个实际例子把上面所有概念串起来。
场景:用户说"帮我修复这个登录页面的样式问题,按钮在移动端显示不全"

阶段一:理解任务
用户输入 → 模型推理└── 需要先了解项目结构和相关代码
阶段二:探索代码库
模型决定:└── 调用 Glob 查找 CSS/样式文件└── 调用 Grep 搜索 "button" 相关选择器└── 进一步读取相关文件确认上下文模型定位到问题文件中的响应式样式
阶段三:制定方案
模型推理:└── 问题是移动端媒体查询中的 button 宽度溢出└── 需要修改 CSS:添加 max-width 和 box-sizing
阶段四:执行修改
模型调用 Edit 工具修改样式文件模型调用 Bash 打开浏览器预览效果(需要用户确认权限)
阶段五:验证并收尾
模型检查修改无误└── 输出总结:改了什么、为什么改、效果预览
整个过程,模型执行了 10+ 步操作,但对用户来说只是"提了一个需求 → 看到代码改好了"。
十、总结:CC 架构设计的核心哲学
回顾整个架构,可以提炼出 Claude Code 的几个核心设计思想:
🔄 Agent Loop 是第一性原理
CC 不只是一个"更聪明的代码补全工具"。它的核心是自主决策的 Agent 循环——模型在循环中推理、行动、观察、再推理,直到任务完成。这是它与传统 AI 编程助手的本质区别。
🧩 工具即能力边界
CC 的能力不来自模型本身,而来自它能够操控的工具。每增加一个工具,CC 的能力边界就扩展一次。工具的精心设计(容错、明确反馈、结构化 I/O)直接决定了 Agent 的可靠性。
🛡️ 能力越大,权限控制越严格
CC 遵循最小权限原则:默认情况下操作需要确认,用户逐步授予信任。权限、沙箱、Worktree 隔离构成多层防护。
🧠 记忆分三层
每一层解决不同的问题,共同构成 CC 的"认知体系"。
🔌 开放胜过封闭
Hooks 让用户自定义行为,Skill 让专家封装领域知识,多形态部署让不同用户选择适合自己的交互方式。CC 设计的不是一座孤岛,而是一个可扩展的平台。
写在最后
回过头看,Claude Code 最有意思的地方不是它"能写代码"——能写代码的 AI 多了。真正特别的是它自己决定下一步干什么、出了错能自己调整、一个模糊的需求能自己拆成一步步做完。从"你问它答"到"你说它干",这个转变可能比表面看起来要大得多。
如果你也在折腾自己的 AI Agent 项目,CC 这套架构值得参考:一个循环驱动核心、一圈工具扩展能力、一套权限兜住底线。万变不离其宗。
如果你觉得这篇文章有帮助,欢迎分享给更多开发者朋友。
