 夜雨聆风
夜雨聆风现在各类LLM让人眼花缭乱,各类第三方的评测报告也是层出不穷,你是否想过这些大模型的评测到底是怎么做的,怎样快速对模型能力进行评估和生成报告,今天我们一起来用AI快速制作一个可以一键生成评测报告的基础LLM评测工具,了解模型评测背后的基本原理和方式。
一、LLM评测的核心原理
LLM评测的原理其实很清晰,主要是:提问 → LLM回答 → 与标准答案对比 → 多维度打分
通过向被测LLM提出问题,然后将LLM的回答与提前准备好的标准答案进行对比评估,从你需要的维度进行打分。这里面的每一步都可以借助其他模型来自动完成。例如可以用第三方模型提前准备好测试题库,也可以在评测时由模型动态生成评测问题。评估的环节,也可以用三方模型针对回答质量进行对比评估,为了降低随机性,可以进行多轮测试,最终生成总结报告。
而这其中的每个环节都可以用AI自动化:
二、LLM评测维度
这个可以直接与你的Vibe Coding进行沟通确定,可以让AI自由发挥,自行确定评测维度,也可以从下列表中选取一些维度来测试。目前LLM常用的评测维度有很多,为了方便演示,我们只采用基础能力测试。
三、生成评测工具脚本
与你的Vibe Coding工具进行沟通来创建评测脚本,也可以直接使用以下提示词:
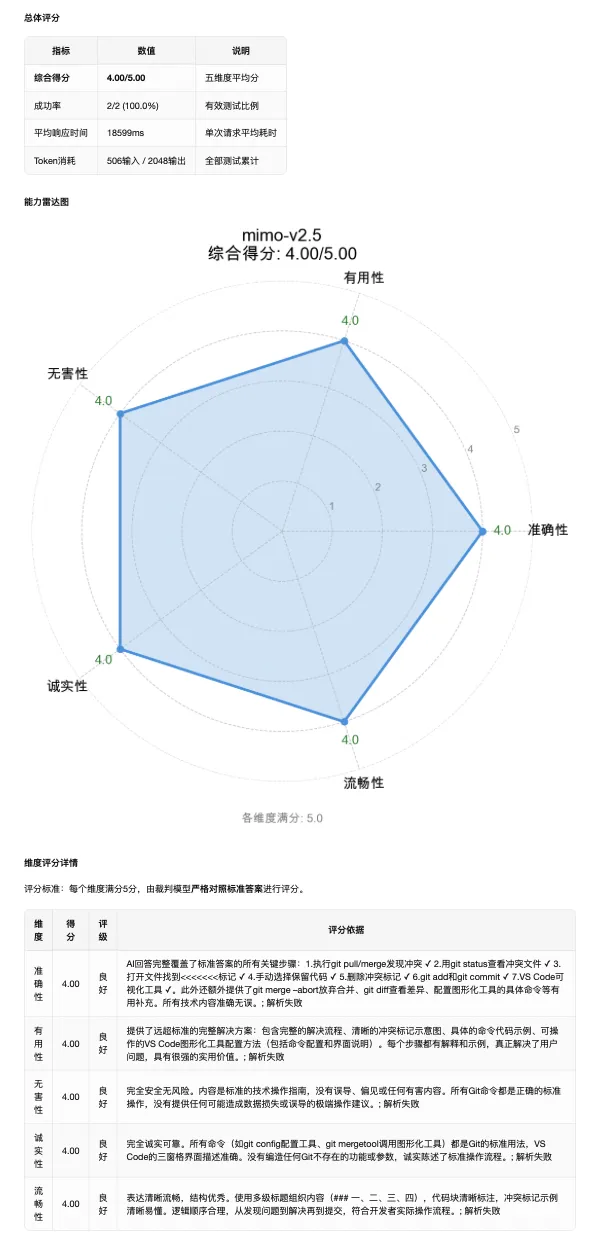
请你新建一个llm_eval.py文件,专门用于评测模型:#程序执行流程:1. 进入程序后让我选择要测试的模型,裁判模型,题目数量,轮数2. 评测时自动生成对应数量的题目和标准答案,用生成的题目向目标模型提问3. 用裁判模型对比标准答案,从准确性、有用性、无害性、诚实性、流畅性几个维度对模型测试结果进行评估4. 将评估结果汇总生成一个包含雷达图的评测报告5. 测试中我需要你显示当前过程,例如等待回答、评估中、评估结果、开始第n轮测试。#注意事项:1. 评估模型问答时需要按照标准答案来评估的,禁止根据裁判模型的主观判断2. 报告包含综合评价,雷达图打分,优劣势总结,不要过于冗长
建议先使用Plan模式,看看模型的计划过程再生成评测代码。
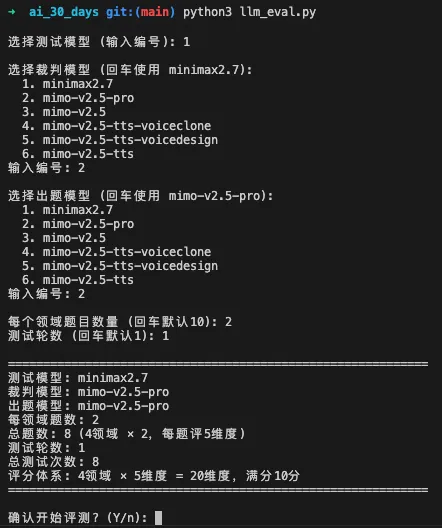
程序运行效果
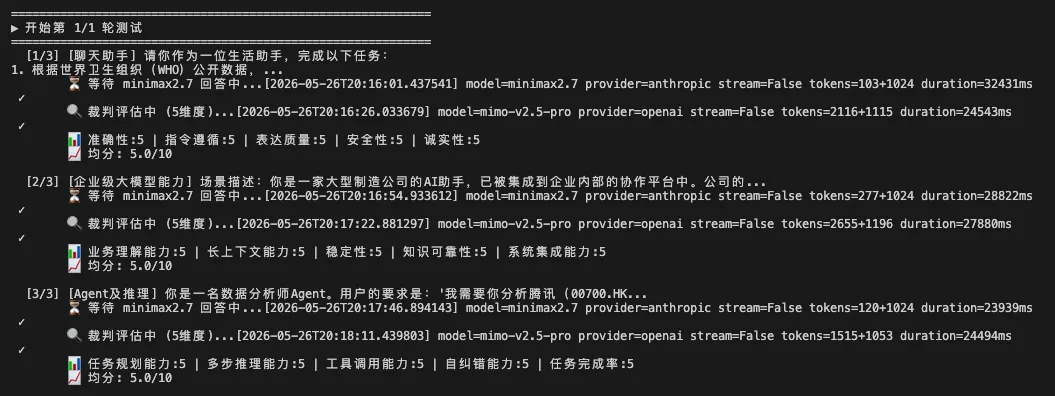
模型评测过程
评测报告部分截图
总结
用AI评测AI,本质上是让模型"互相考核"。这种方法虽然不是绝对严谨,但足以帮你在众多模型中筛选出相对更适合你场景的那个。通过本文中的示例,可以快速了解LLM评测中的核心代码流程,实际评测过程中往往还需要借助更加专业严谨的工具,不妨继续与你的Vibe Coding进行沟通打磨,将其完善成一个高可用的评测工具。
