 夜雨聆风
夜雨聆风你导出的 PDF 文字为什么永远选不中?我们用一个自研引擎,把这个沉疴彻底治好了

你一定遇到过这种尴尬——
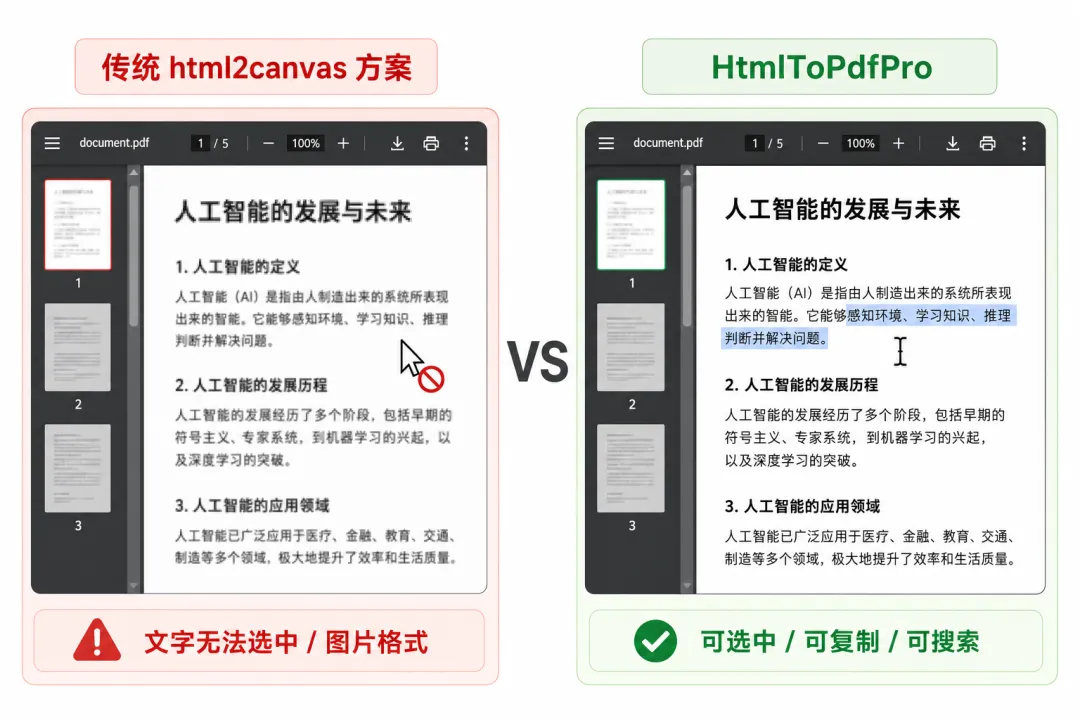
好不容易搭出一个精美的报表页面,点击"导出 PDF",文件生成了,打开一看,视觉上还说得过去,可当你试图用鼠标选中里面的一段文字,准备复制的时候,光标变成了箭头,文字纹丝不动。整个 PDF,不过是一张拼接起来的大图而已。
你去搜索解决方案:找到的要么是 html2canvas + jsPDF 的老搭档——你已经在用,它就是问题本身;要么是 Puppeteer,需要一台服务器、一套 Node 环境、一个 Chromium 实例,为了生成一份前端报告绕了一大圈;再往深处找,是一些 Rust 原生渲染方案,理论上能生成真正的矢量 PDF,可实际上支持的 CSS 样式寥寥无几——Flex 可能对不齐,Grid 更是直接翻车,圆角、阴影、渐变,都是奢望,导出来的排版与你精心设计的 UI 相差十万八千里。
这个痛,我们也痛了很久。
问题的根源,从未被正视过
说来简单:几乎所有前端 HTML 转 PDF 的方案,都在用同一个思路——把页面截图,然后贴进 PDF。
html2canvas 把整个 DOM 画成一张 Canvas 图片,jsPDF 把这张图片装进 PDF 文件里,你看到的"PDF",本质上是一张超大的 JPEG。文字没有文字,只有像素。放大了看模糊,Ctrl+F 搜不到,复制粘贴只能得到乱码,甚至根本无从选中,打印出来也是图片画质。
那些基于 Rust 的原生渲染方案,比如曾经被寄予厚望的 IronPress,走的是另一条路——自己解析 HTML、自己排布文字,理论上可以输出真正的矢量 PDF,文字层原生可选。只是现实残酷:当你把一个使用了现代 CSS 的业务页面交给它,等来的往往是一份面目全非的输出。Flex 布局失位,Grid 排版错乱,大量样式特性付之阙如。对于稍微复杂一点的产品 UI,那样的结果几乎不可用。
我们试过很多条路,绕了很多弯,最终问了自己一个问题:能不能让浏览器去计算布局,我们只负责把结果完整地写进 PDF?
换一条路:让浏览器干它最擅长的事
浏览器做 HTML 排版,是这个世界上最成熟的引擎。Flex、Grid、响应式、自定义字体、渐变背景——它全部都精通,而且已经安安静静地渲染好了。我们没有理由重新发明这个轮子。
我们真正需要的,是把浏览器排好的结果,以双通道的方式诚实地写进 PDF:
视觉通道:用 Canvas 把每一页的像素如实记录下来,以高清 JPEG 的方式嵌入 PDF,确保你在浏览器里看到的样子,导出后一模一样。
文字通道:在 JPEG 图像上方,覆盖一层完全透明的真实 Unicode 文字。每一个字的坐标,都与视觉像素精确对齐。对你的眼睛来说什么都看不见,但对 PDF 阅读器来说,那是真实的文字——可以选中,可以复制,可以被 Ctrl+F 搜索到。
这就是 HtmlToPdfPro 的核心逻辑:把视觉还原和文字可访问性,在同一个 PDF 文件里同时做到。
中文,是那道最难的坎
说起来容易,真正做起来,处处是坑。
文字层最棘手的地方,不是英文,而是中文。
英文单词之间天然有空格,测量起来相对从容。中文却是连续的字符流,没有词间距,浏览器会在任何相邻的两个汉字之间自动换行。当一段中文文本跨越了行尾,Range API 测量出来的坐标往往会把换行前的最后几个字和换行后的第一个字的位置搞混,导出的 PDF 里文字层对不上视觉层——你用鼠标选中一行,选出来的可能是错位的乱序文字。
为了把这个问题从根上解决,我们把文字层的测量粒度,压到了**逐字符(grapheme)**级别。每一个汉字、每一个标点,都单独测量它在页面上的精确像素坐标,再逐一写进 PDF 的文字层。
当你在导出的 PDF 里拖动鼠标框选一段中文,你选中的每一个字,都是真正的 Unicode 字符,顺序正确,位置准确。
这件事看起来只是一个工程细节,但对每一个因为"PDF 里的中文复制出来是乱码"而抓狂过的开发者来说,它意味着一切。
一眼就能看懂它能做什么

文字完整可复制 PDF 内任意文字都可以鼠标选中、Ctrl+C 复制、Ctrl+F 搜索,这不是"努力接近"的方向,而是设计上的基础保证。
高保真视觉还原 Flex 布局、Grid 排版、圆角边框、线性渐变背景、盒子阴影——只要你的 CSS 能在浏览器里呈现,导出来就是那个样子,不需要为了导出而削减样式。
智能分页,不粗暴截断
内容遇到分页线时会自动感知元素边界,卡片、表格行、段落会优雅地上移到下一页,不会被拦腰截成两半。想在某个位置强制换页?给元素加上 .pdf-page-break 即可。
长表格跨页渲染 几十行的数据表格,自动延伸到下一页,不需要额外配置。
超链接与书签目录
PDF 内的链接依然可以点击跳转。所有 h1–h6 标题自动生成阅读器左侧的书签大纲,文档导航开箱即得。
表单内容完整保留 页面上用户填写的输入框、下拉选项、文本域,导出时内容一并带走,一个字都不少。
页眉页脚与动态页码
自定义页眉、页脚内容,{page} 和 {pages} 占位符自动替换为当前页码和总页数。
Markdown 直接导出 传入一段 Markdown 文本,直接生成带文字层的 PDF,不需要先手动转 HTML。
纯前端,数据不离开浏览器 没有服务端,没有 Node 环境,没有 Puppeteer,涉及隐私的文档在本地完成全部转换,数据不经过任何外部服务。
三行代码,就能接入
npm install @flyfish-dev/html2pdf-js
import { HtmlToPdfPro } from '@flyfish-dev/html2pdf-js';
const exporter = new HtmlToPdfPro({
filename: 'report.pdf',
page: { format: 'a4' },
dpi: 192,
textLayer: true, // 开启可复制文字层
bookmarks: true, // 自动书签目录
linkAnnotations: true // 链接可点击
});
await exporter.download('#report-container');
如果页面里有不想带进 PDF 的工具栏或按钮,多传一行 CSS 就够了:
const exporter = new HtmlToPdfPro({
extraCss: '.toolbar { display: none !important; }'
});
在线体验地址:https://htmltopdfpro.vercel.app[1]
完全开源,源码永久更新,商业授权自助开通
项目以 AGPL-3.0 协议完全开源,代码托管在 GitHub,所有人都可以阅读、运行、修改,没有隐藏功能,没有限时试用。仓库会持续迭代,每一次改进都第一时间同步到公开仓库,你拿到的是一个真正在演进的项目,而不是一个被丢进角落的存档。
对于需要在商业产品中闭源使用的团队,商业授权支持自助开通,省去漫长的沟通流程,按需取用,即开即用。
GitHub:https://github.com/wybaby168/html2pdf-js[2] npm: @flyfish-dev/html2pdf-js
写在最后
这个项目从第一行代码到今天,走过的路比我们预想的要长得多。从 IronPress 到 html2canvas,从浏览器打印弹窗到自研 PDF writer,每一条路都留下了一些痕迹——每一个被放弃的方案,都让我们对"什么是真正可用的 HTML 转 PDF"有了更深一层的认识。
最终我们选择了最笨、也最彻底的路:让浏览器把排版算好,自己负责把结果诚实地记录下来,不走捷径,不偷工减料。视觉层是视觉层,文字层是文字层,两者各司其职,合在一起成为一份完整的、真正可用的 PDF。
如果你也在为这个问题困扰,欢迎来试试。
引用链接
[1]https://htmltopdfpro.vercel.app
[2]https://github.com/wybaby168/html2pdf-js
