 夜雨聆风
夜雨聆风别再说"端到端科研Agent"了,这篇综述给所有Vibe Research划了等级
最近翻arXiv翻到一篇挺有意思的综述——《AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery》。挂的是华科、Lehigh、清华、斯坦福、UCSD、微软、Salesforce等一长串机构的名字,作者列表里既有Caiming Xiong、Jianfeng Gao这种工业界大佬,也有Philip S. Yu、Pengtao Xie这种学术圈的老熟人。
这种"豪华阵容综述"其实很挑读者——写得好就是地图,写不好就是大杂烩。笔者花了一下午把全文翻完,发现这篇还真做了件挺有价值的事:它没有把"AI能不能做科研"当成一个yes/no问题来回答,而是直接给了一把尺子——L0到L4的五级自主度框架。这个框架的好处是,下次再有人说"我的Agent能做端到端科研",你可以直接拿这把尺子量一量,到底是L2-P,还是真的摸到了L3的边。
这篇笔者主要带大家把研究背景和相关工作这两块捋一遍。后面的技术分解、评估体系、领域分析其实更精彩,但内容太多,留着以后再聊。
一、从AlphaFold到The AI Scientist:科研范式悄悄换了
要理解这篇综述为什么要写,得先看看AI做科研这件事到底经历了什么。
早些年AI for Science这个领域,基本是"专用模型打专用问题"的玩法。蛋白质结构预测就训一个AlphaFold,分子性质预测就训一个图神经网络,科学图像分析就上CNN——每个系统都死磕一个边界清晰的子问题。AlphaFold之所以是这一代的代表作,恰恰是因为它把"蛋白质结构预测"这个高度专门化的任务干到了极致,但它本质上还是在一个相对窄的问题设定里工作。
转折点出现在大语言模型起来之后。能力前沿从"窄域预测+检索"挪到了语言理解、推理、检索增强、工具使用、代码生成、多步执行这一整套通用能力上。这件事的关键不在于模型变强了多少,而在于AI能参与科研流程的广度突然被打开了——文献调研、想法生成、计划制定、代码执行、结果分析、论文撰写,原本散落在科研流程各处的环节,第一次有可能被同一个系统串起来。
The AI Scientist就是这个转折的标志性产物。它不再瞄准某一个科研子任务,而是直接尝试把ideation、写代码、跑实验、画图、写论文、模拟评审拼到一个pipeline里。后来的AI Scientist-v2、Agent Laboratory、AI-Researcher、ARIS、NanoResearch都在沿着这条路往前推。
但这里就出现了一个非常容易被混淆的问题:**"流程被打通了"不等于"科研自主了"**。
这是这篇综述反复强调的一个判断:现在的系统在搜索、起草、写代码、跑bounded execution上确实越来越能打,但在validation(验证)、rejection(拒绝弱方向)、reproducibility(可复现)、exception handling(异常处理)、accountable closure(可问责的科学收尾)这些环节上还差得远。一个能写出像模像样论文的Agent,不代表它写的论文站得住脚。
二、L0到L4:把"AI自主科研"切成五段
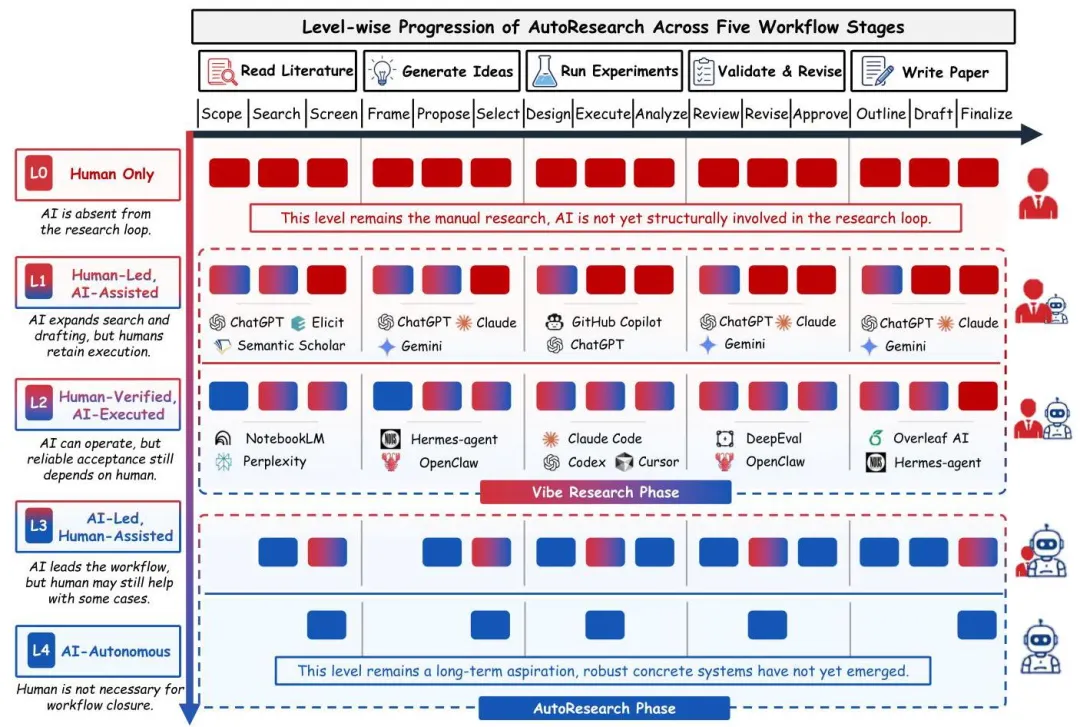
为了不让大家陷在"能 vs 不能"的二元争论里,作者直接搬出了一个五级自主度框架。这个框架的核心思路是:沿着workflow控制权、任务执行权、验证权、科学问责权这四个维度,看人和AI是怎么分工的。
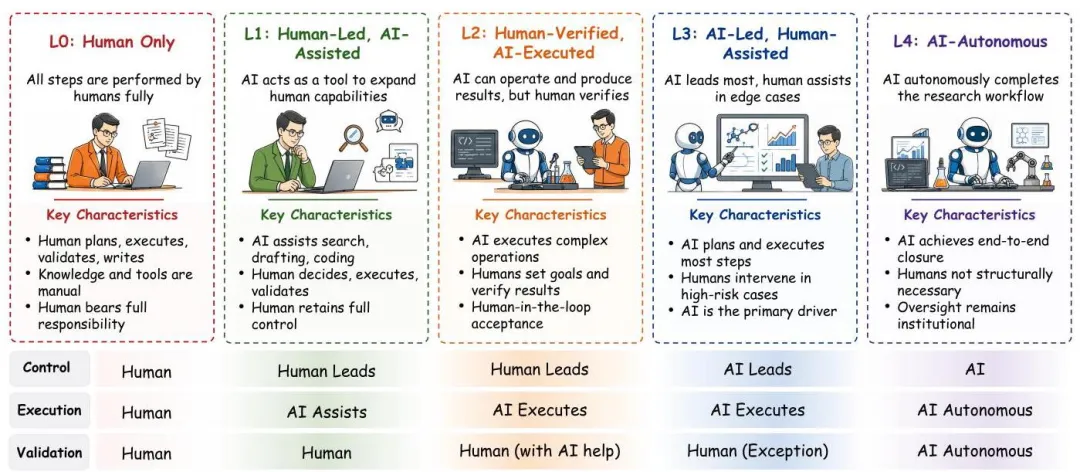
笔者用大白话把这五级给大家翻译一下:
L0 — Human Only:纯人工,AI完全不参与科研环节。这是历史基线,对应的就是Popper、Kuhn、Merton那套人类主导的科学实践,所有判断、验证、问责都在人这边。
L1 — Human-Led, AI-Assisted:人主导,AI辅助。这是目前大部分研究者每天都在做的事——用ChatGPT、Claude、Gemini帮忙搜文献、改语法、写draft、brainstorm。但workflow的组织、关键判断、最终责任全在人手里。这一级的代表是LitLLM、STORM、OpenScholar、PaperQA2、GPT Researcher这类系统。
L2 — Human-Verified, AI-Executed:AI干活,人验收。这是当前最热闹也最复杂的一级。AI开始真正承担执行性的工作——读写文件、生成修改代码、调用工具、跑分析——但科学有效性、新颖性、可复现性、可用性的最终判断还在人这边。代表系统多得吓人:OpenHands、Aider、SWE-agent是执行底座;AI co-scientist、FreePhD是协作型;The AI Scientist、AI Scientist-v2、Agent Laboratory是pipeline型。
L3 — AI-Led, Human-Assisted:AI主导,人辅助。这一级最容易被滥用。作者特意强调:pipeline能跑通≠到了L3。L3的硬指标是"AI能在没有日常人工逐步验证的情况下,跨多个阶段维持科学上可信的进展"。换句话说,L2-P的pipeline系统再花哨,只要每一步还得让人盯着、还得让人最后拍板,就还在L2里。当前文献里说自己到了L3的,作者基本都给打回L2-P了。
L4 — AI-Autonomous:AI完全自主。这是个aspirational horizon(理想化的远期目标),不是已经实现的状态。需要AI能自己提问题、自己定方向、自己跑研究、自己验证、自己拒掉弱方向、自己保存provenance、自己按领域标准沟通成果。作者直说了:目前没有任何系统真到了L4,benchmark里测的也只是"离L4还差多远"。
这个框架的精妙之处在于,它把"Vibe Research"和"AutoResearch"做了一个非常清晰的切分:L1-L2是Vibe Research(人在驾驶座上,AI是副驾),L3-L4才是真正的AutoResearch(AI在驾驶座上)。这个命名笔者觉得相当传神——Vibe这个词本身就有点"靠感觉,靠协作"的意思,跟当前科研Agent的实际工作方式非常贴。
三、贡献:一个框架,一个分类,一套评估维度
作者把自己的贡献归纳成三块:
第一是给AutoResearch一个workflow-level的概念框架。不再用model family、agent架构、benchmark分数来分类,而是看"AI在科研workflow里到底分担了多少control、execution、validation、accountability"。这个视角的好处是能避免一个特别常见的误判——把"pipeline覆盖广"当成"自主度高"。
第二是按五个workflow条件做技术分类。文献grounding、假设形成与规划、实验与工具使用、反馈/验证/评审、报告与知识沟通——这五个阶段下面,作者把现有系统都摆了进去。这部分笔者后面再单独写,信息量太大。
第三是提出一套评估维度:novelty(新颖性)、validity(有效性)、impact(影响力)、reliability(可靠性)、provenance(可溯源性)。这五个维度的核心思路是把"评估"从"任务完成度"切换到"科学可信度"上。一个Agent能跑通流程,不代表它的产出有科学价值。
四、AutoResearch的发展史:从机器人科学家到Kosmos
综述里有一张时间线图,把从2021年前到2026年的代表性工作全摆了出来。笔者觉得这张图比文字描述更直观,强烈建议大家自己去看原文。
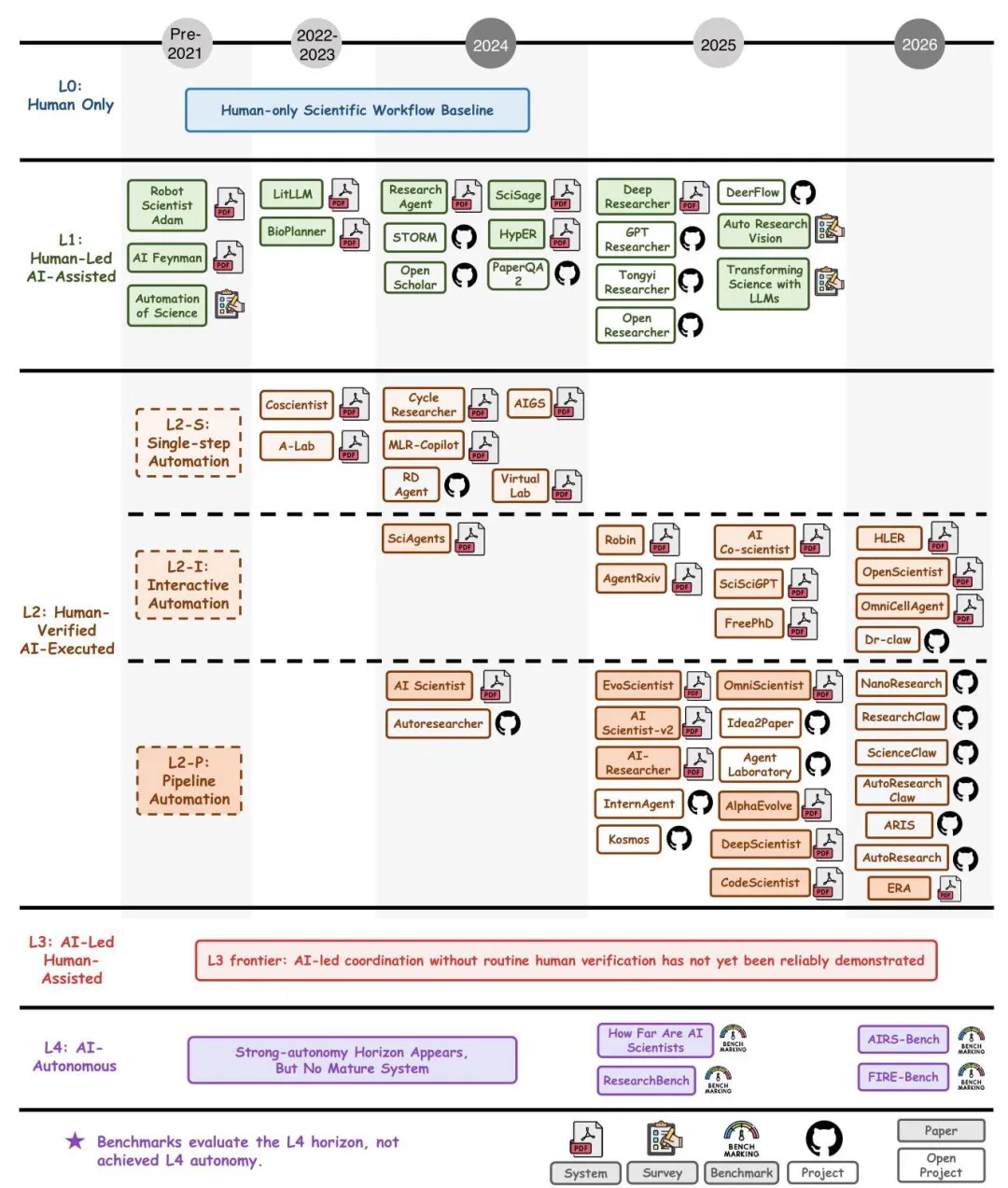
下面笔者按时间顺序梳理一下关键节点。
4.1 史前时代:人类科研baseline与早期自动化探索
在LLM起来之前,AI做科研基本是科幻。Popper的证伪主义、Kuhn的范式革命、Merton的科学社会学,描述的都是人类主导的科学实践。战后科学传播规模变大了,但科学的"收尾权"始终在人和学术共同体手里。
早期的几个标志性工作值得记一下:
Robot Scientist Adam(2004):King等人在Nature上发的那篇,第一次把假设生成、实验设计、机器人执行整合到一起,做的是酵母功能基因组学的研究。这是"自动化科学"这个概念的实物起点。 AI Feynman(2020):从数据里恢复物理方程的符号回归方法。证明了在结构化场景下,AI可以做出某种意义上的"科学发现"。
这些工作虽然成就很高,但都局限在"结构化、可表达"的科学子问题里。
4.2 L1层:知识工作的自动化(2023起步,2024-2025爆发)
LLM起来之后,第一波能稳定落地的就是文献相关的知识工作辅助。
2023年BioPlanner和LitLLM是早期的代表,前者做生物学实验协议规划,后者从abstract出发检索论文并生成related work。
2024年这一层彻底爆发:
Research Agent:自动提出研究问题、方法、实验设计,并在文献基础上迭代 STORM:检索+多视角问题驱动的长文生成(注意它本质是writing系统,不是execution agent) OpenScholar:从大规模文献库里找相关段落,做citation-backed synthesis PaperQA2:基于论文的问答和综合 SciSage、HypER:综述生成、文献驱动假设生成
2025-2026年这一层进一步深化:Deep Research Arena、GPT Researcher、Tongyi Researcher、Open Researcher、DeerFlow把"deep research"做成了标配能力。同时还出现了几篇field-framing的工作——比如Auto Research Vision、Transforming Science with LLMs——开始尝试给这个领域写"愿景"。
笔者的观察是,L1这一层的工具其实已经渗透到了大量科研工作者的日常里。Perplexity、NotebookLM、ChatGPT/Claude/Gemini的deep research模式,本质上都是L1级的东西。它们提升了科研的"信息吞吐效率",但没有改变"谁来做判断"。
4.3 L2-S:单步自动化执行(2023开始)
下一个转折点是AI从"帮人想"变成"帮人做"。
Coscientist(2023):把LLM跟搜索、代码执行、实验自动化系统连起来,做化学合成。这是Daniil Boiko和Gabe Gomes发在Nature上的工作,挺标志性。 A-Lab(2023):MRS的工作,自主无机材料合成的实物loop——计算、文献知识、主动学习、机器人执行,全套打通。
2024年这一层进一步扩展:CycleResearcher做planning-revision循环、MLR-Copilot和RD Agent做ML研究辅助、AIGS做AI驱动的科学生成、Virtual Lab做虚拟实验环境。
这一层的特点是:任务边界清楚,AI执行单步操作,外部验证仍然必要。
4.4 L2-I:交互式工作流自动化
第二种L2模式是"AI在多步workflow里维持进展,但需要人来steering或accept"。
代表性工作:
SciAgents:多智能体科学推理,基于本体知识图和图推理做跨学科假设生成 AI co-scientist:Google的工作,最近发了Nature。多智能体协同假设生成、协作科学推理 FreePhD:个性化研究组的多agent框架 AgentRxiv:协作式自主研究 Robin:lab-in-the-loop的多agent发现工作流 SciSciGPT、HLER:扩展到科学计量学、经济学方向
这里有个细节值得说一下——Co-scientist 2026年发在Nature上的那篇正式版(注意和"AI co-scientist"工作paper的区别),把"多agent协同+文献grounded假设生成"做了一个非常完整的工程化呈现。这件事对整个领域有标杆意义,因为它意味着主流期刊开始正面承认AI参与科学发现的合法性。
4.5 L2-P:流水线自动化(人工验证下)
这是目前最热闹、也最容易被overclaim的一层。
代表性系统:
The AI Scientist(2024):Sakana AI的工作,把ideation→code→experiment→figure→paper draft→simulated review整合成一个端到端框架。开创性意义大。 AI Scientist-v2(2025):用agentic tree search做更长horizon的scientific search Agent Laboratory:用户给idea,AI做完整研究pipeline AlphaEvolve:DeepMind的工作,coding agent做科学和算法发现,evaluator反馈驱动迭代 DeepScientist:长horizon的iterative discovery CodeScientist:code-centric的实验pipeline Idea2Paper、OmniScientist:从idea到paper的多agent生态 AI-Researcher、InternAgent、Kosmos:进一步强化agentic search、experiment management、persistent state
2026年的趋势是从"研究agent demo"转向"可复用基础设施"——NanoResearch、ResearchClaw、ScienceClaw、AutoResearchClaw、ARIS、EvoScientist、NeuroClaw这一批,开始把可复用workspace、tool orchestration、persistent project state做成infrastructure。
还有最近的两个工作值得单独提:
ERA(Empirical Research Assistance):用LLM-guided tree search做expert-level empirical scientific software的生成,强调implementation才是computational research的关键瓶颈。
Robin:通过把假设生成、实验分析、文献引导的workflow refinement放在semi-autonomous loop里做迭代,把AutoResearch往真正的"科学发现pipeline"推。
但作者反复提醒:这些系统再花哨,只要还需要人来判断hypothesis是否有意义、experiment是否valid、result是否reproducible、manuscript是否scientifically usable,它们就还在L2-P,没到L3。这种"保守归类"是这篇综述最值得学的地方。
4.6 L3-L4:benchmark测出来的"地平线"
最后一层不是已经populated的系统类别,而是evaluation的前沿。作者非常坦诚地说:目前没有任何系统是mature L3,更别说L4了。但已经有一批benchmark在测"离L3/L4还差多远":
How Far Are AI Scientists from Changing the World? :直接把"系统野心 vs 实际科学影响"的gap摆到台面上 ResearchBench:把科学发现拆成可分解的benchmark问题 AIRS-Bench:测frontier research agent FIRE-Bench:测full-cycle rediscovery任务
这一层的意义在于,整个领域不再只被"越来越强的系统"定义,也开始被"越来越严格的测试"定义。
五、当代landscape:分工而非统一架构
读完整个发展史,再回过头看现在的landscape,会发现一个挺有意思的结构——当前的AutoResearch领域不是被某个canonical架构统治,而是由功能分工组成的。
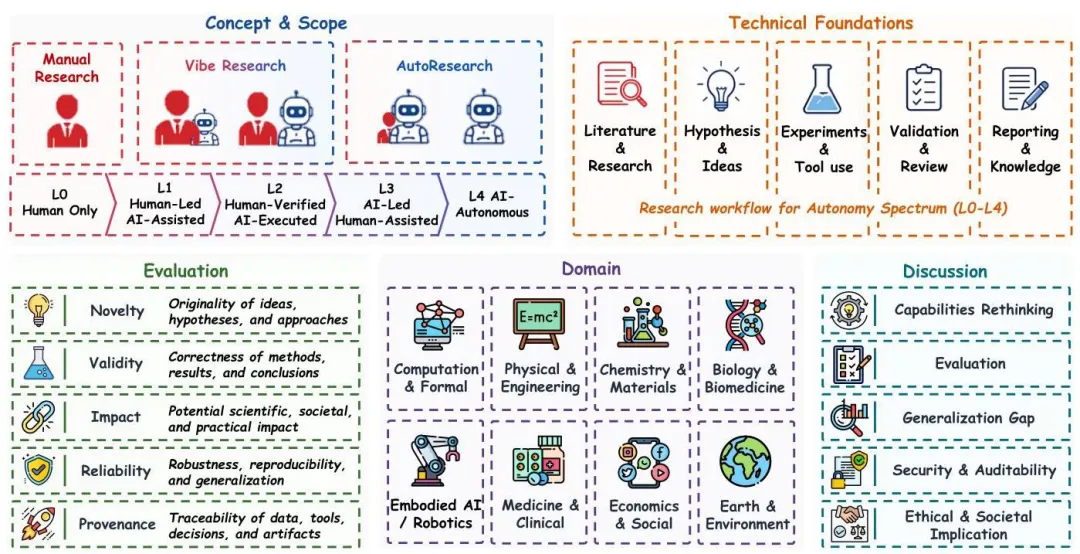
作者把这个分工归纳成几层:
知识支持层:稳定文献grounding、source-grounded synthesis、QA、planning、report construction。STORM、OpenScholar是典型。
执行底座层:code agent、tool use、laboratory interface、controlled environment、software-agent execution。OpenHands、Aider、SWE-agent是典型。
Pipeline协同层:把上面两层连起来,跨越ideation、implementation、experimentation、analysis、paper generation、review feedback。The AI Scientist、AI Scientist-v2、AI-Researcher、Agent Laboratory是典型。
开源基础设施层:软件agent执行环境、tool orchestration、persistent workspace、可复用研究环境。NanoResearch、ResearchClaw、AutoResearchClaw这些都是2026年才冒出来的新东西。
笔者特别想强调的一个判断是:当前的领域演进,是这四层在共同maturation,而不是某一层在单独突破。哪一层短板太严重,整个workflow就跑不通。
六、笔者的一些想法
这篇综述读下来,笔者最大的几个感受:
第一, "五级自主度"这把尺子有点用 。它不是完美的,但至少能挡住很多"我做了一个能做端到端科研的Agent"这种营销话术。下次看到这类宣传,先问一句:在哪个level?还需不需要人routine verification?
第二,Vibe Research这个命名很妙。它直接承认了"目前大部分所谓的科研Agent其实是辅助工具"这个事实,没有强行往L3拔。这种学术上的诚实在AI领域已经很难得了。
第三,领域间的不均衡是真实的。综述里明确指出,computational/formal sciences走得最快是因为artifact本身就是digital、executable、replayable的。化学/材料慢一些但有robotic lab;生物/医学/社科再慢,因为embodiment、ethical constraint、causal reasoning的难度根本不是"加大模型"能解决的。这个判断很重要——**不要拿coding agent的进展去推断"AI能做全科学的端到端研究"**。
第四,benchmark在反向定义这个领域。FIRE-Bench、AIRS-Bench、PaperBench、ResearcherBench这些近期出的benchmark,本质上都在做一件事——用更严格的测试逼出系统的真实能力。这件事和系统侧的进展同样重要。
最后留个尾巴:综述后面还有大量内容笔者今天没碰——技术分解的五个workflow stage、五个评估维度的细节、八个领域(计算/物理/embodied/化学/生物/医学/社科/地球科学)的autonomy ceiling分析。这些其实是这篇综述真正硬核的部分,笔者打算之后单独再写一篇。
感兴趣的朋友建议直接读原文,arXiv编号是2605.23204v1,52页正文+几百篇reference,作者团队的工作量是真的扎实。

如果你觉得这篇文章对你有帮助,别忘了点个赞、送个喜欢
>/ 作者:ChallengeHub小编
>/ 作者:欢迎转载,标注来源即可