 夜雨聆风
夜雨聆风AI 帮你写代码的时候,同时帮你做安全审查。
而且审查它的,不是你,不是你的同事,是另一个 Claude。
5 月 26 日,Anthropic 官方账号@ClaudeDevs 发了一条推文,宣布给 Claude Code 装上了「security-guidance」插件——AI 帮你把代码写出来,另一个 AI 模型在同一轮对话里帮你把安全漏洞揪出来,当场修掉。
推文本身拿到了 100 万次浏览。多家安全媒体在报道中引用了 J.P.Morgan 安全负责人 Shalini Goyal 的评价——她说把安全指导嵌入编码环节"比依赖下游审查周期强太多了"。
一句话总结这件小事的分量:以前是写了代码 → 提交 PR → 人审出漏洞 → 返工。现在是写了代码 → AI 当场说"这里有洞"→ 当场修 → 干净的代码进入 PR。
内部测试数据显示,安全相关的 PR 评论直接少了 30-40%。
好嘛,这玩意儿怎么做到的?
三层防线:不是一道闸,是一整套流水线
security-guidance 插件在三个时间点出手检查你的代码,而且每一层用的手段都不一样。
第一层:编辑时模式匹配——秒级拦截,零开销
你让 Claude 写一段代码,它刚写完、文件保存的那一刻——插件直接扫一遍新内容。
这层不调 AI 模型,纯靠模式匹配。怎么简单怎么来:eval(→警告,pickle→警告,.innerHTML =→警告,.github/workflows/下改了东西→警告。
因为这层不涉及模型调用,零 token 消耗。相当于一个不要钱的安全 lint。
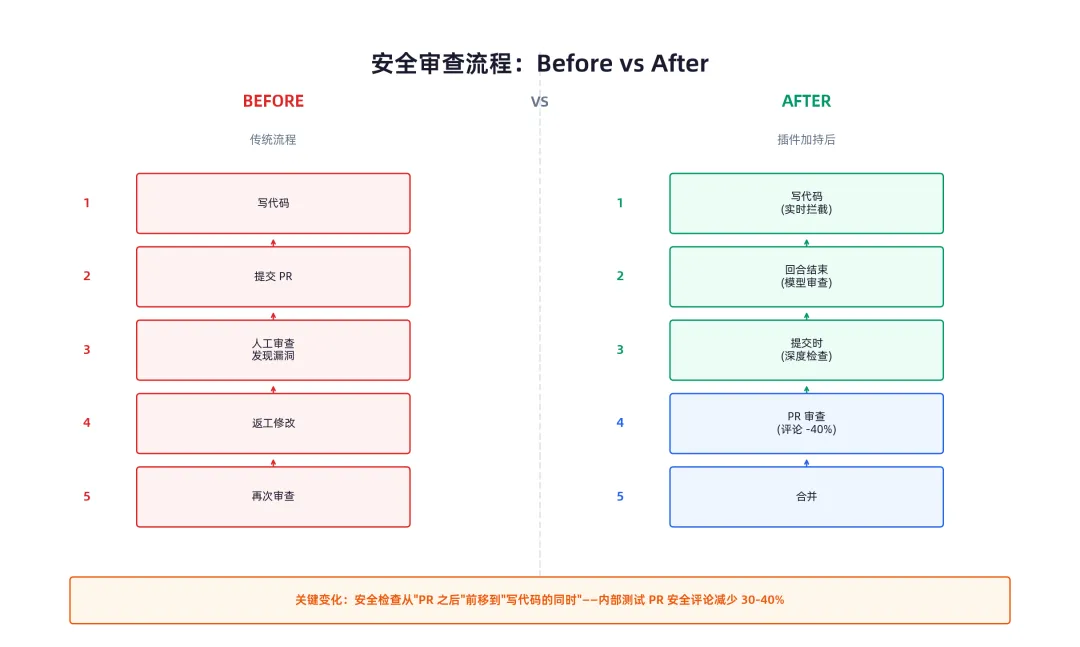
第二层:回合结束时模型审查——换一个 Claude 来看你的代码
这层有点意思。
你发一条消息,Claude 回复你,这叫一个"回合"。每轮回合结束,插件把这一轮改过的所有文件打个 git diff,丢给另一个 Claude 模型去看。
注意——不是写代码的那个 Claude 自己审自己。是一个全新的、独立的 Claude 实例,拿着 diff 从零开始看,对被审查的代码没有任何感情包袱。
这一层能抓到模式匹配抓不住的东西:未授权、不安全的直接对象引用(IDOR)、SSRF、弱加密。
默认用Claude Opus 4.7跑审查。可以配环境变量
SECURITY_REVIEW_MODEL换别的模型。
第三层:提交/推送时代理审查——更深的上下文,更少的误报
当 Claude 帮你git commit或git push的时候,插件触发最重的一层审查:读的不只是改动的代码,还读周围的调用链、清理器、相关文件,判断"这个发现是真的漏洞还是看起来像但实际上安全的"。
重点:三层都不阻止写入或提交。发现的问题变成对话里的指令,Claude 在同会话里修复。插件是"引导",不是"门禁"。
这个设计挺聪明的——它尊重开发者的控制权,但在 Bug 还没走出编辑器的时候就把问题标记了出来。
第一次上手:2 步把它跑起来
前置条件不复杂:
Claude Code CLI 版本 ≥ 2.1.144 Python 3.8+ 在你的 PATH 里 当前工作目录是个 git 仓库
在 Claude Code 会话里敲两行:
/plugin install security-guidance@claude-plugins-official/reload-plugins第一行从 Anthropic 官方市场拉插件。如果报"找不到市场",先跑/plugin marketplace add anthropics/claude-plugins-official再装。
第二行让当前会话加载插件,不用重启 Claude Code。
装的时候会提示选 scope。选用户范围(user)——这样以后每开一个新会话,插件都会自动加载,不用反复装。选项目范围(project)的话,只对那个项目生效。
这步最容易卡的地方:首次运行,插件会在~/.claude/security/下建虚拟环境装 Claude Agent SDK,需要 pip 和网络。Windows 上跳过虚拟环境那一步,所以代理提交审查只在claude-agent-sdk已经能 import 的时候跑——如果没装,自动降级到单次审查。装失败了也别慌,不影响第一层模式匹配。
配好之后,每次使用不需要做任何事。插件全自动运行——你写你的代码,它扫它的漏洞。
云会话和共享仓库怎么装
云端的 Claude Code 会话跑在 Anthropic 自己的机器上,用户范围的插件带不进去。要在这类环境用,在项目的.claude/settings.json里声明:
{"enabledPlugins": {"security-guidance@claude-plugins-official": true }}检入仓库后,clone 这个仓库的人也会自动启用插件。管理员还可以通过托管设置在组织级别统一开启。

装好之后:两个自定义文件,想拦什么你说了算
插件自带的内置规则覆盖了最常见的漏洞模式。但如果你们团队有自己的安全底线——比如"日志不能打客户 ID""admin 路由必须先调require_role"——两个文件就能加进去。
给模型审查加指导
在项目根目录建.claude/claude-security-guidance.md,用大白话写你的威胁模型:
# 本仓库安全指导- 不要在 INFO 或以上级别日志中记录 customer_id 或 account_number。- /admin 下所有路由必须在任何数据库读取前调用 require_role("admin")。- 令牌比较用 crypto.timingSafeEqual,别用 ===。这些规则会作为附加上下文加载到每次模型审查里,和内置漏洞清单一起生效。
注意:这层是给审查模型的"指导",不是硬性拦截。违反了你写的规则,插件会标记出来让 Claude 修复,但不保证 100%捕获。要硬执行,搭配阻止编辑保护文件的 hook 或 CI 检查。
给编辑时检查加自定义模式
建.claude/security-patterns.yaml,写正则或子字符串规则:
patterns: - rule_name: internal_api_keysubstrings: ["sk_live_", "AKIA"]reminder: "硬编码的 API 密钥前缀。从密钥管理器加载凭证。" - rule_name: tenant_unfiltered_queryregex: "\\.objects\\.all\\(\\)"paths: ["**/src/tenants/**"]reminder: "多租户代码必须按 org_id 过滤。"这层零 token 消耗,和内置模式一起做确定性字符串匹配。最多加载 50 条自定义规则。
可以关,可以按层关
不想全开?环境变量精细控制:
ENABLE_PATTERN_RULES=0 | |
ENABLE_STOP_REVIEW=0 | |
ENABLE_COMMIT_REVIEW=0 | |
SECURITY_GUIDANCE_DISABLE=1 |
卸载也简单:/plugin uninstall security-guidance@claude-plugins-official。
实际影响:不同类型的开发者,各算什么账
独立开发者 / 小团队。人手不够,没人审代码?这个插件约等于白送了一个安全审查员。虽然不能替代渗透测试,但 SQL 注入、XSS、硬编码密钥这类低级错误直接拦在本地,提交到 GitHub 的代码至少过了三道机器审查。
企业团队。安全审查通常卡在 PR 环节——审查人不够,三天才轮到你的 PR。插件把安全发现前移到了编码环节,到 PR 的时候已经不是"第一次看到这些代码的安全问题"了。这也是 Anthropic 内部数据"PR 安全评论减少 30-40%"背后的逻辑。
安全工程师。别慌,插件不会抢你饭碗。Anthropic 自己说的是"深度防御中的一层",明确说了它不能替代后来的检查。典型栈是:会话内插件 → 按需 /security-review → PR 上的 Code Review → CI 里的静态分析。每一层捡前一层漏掉的东西。
很多开发者在讨论中问到:"这跟已有的 SAST 工具有啥区别?" 区别在于时机——SAST 在 CI 里跑,插件在编辑器里跑。CI 发现漏洞意味着你要切回去改;插件发现漏洞意味着你改完再提交,CI 是干净的。
如果你每次 git push 之前都会心虚地扫一眼有没有写了不该写的东西——装它。
说实话,Anthropic 这一步走得挺对的。AI 编程助手把写代码的速度拉上去了,但安全审查的速度没变——人还是那个人,一天还是 24 小时。速度差就是漏洞的窗口期。给 AI 配一个 AI 审查员,把"写代码"和"审代码"的速度拉到同一个量级,这个思路本身比"又一个安全工具"有意思得多。
开源参考实现anthropics/claude-code-security-review在 GitHub 上已经拿了 2.6 万 star。如果你对底层实现好奇,那个仓库演示了 Agent 怎么自主猎杀和修补 SQL 注入、XSS、反序列化 RCE、IDOR 和硬编码凭据——本质上是把插件第二、三层的思路开源了出来。
两行命令,一个插件,三道防线。试试不亏。
参考链接:
https://code.claude.com/docs/zh-CN/security-guidance
https://github.com/anthropics/claude-code-security-review
点赞、转发、小心心❤️欢迎在评论区留下你的想法——你的团队会考虑给 AI 编程助手配安全插件吗?
— 完 —
