 夜雨聆风
夜雨聆风写在前面
很多企业在建设 AI 知识库之后,很快会进入一个新阶段:不再满足于“问文档、找资料、做总结”,而是希望 AI 真正参与业务工作。
上一篇内容,我们介绍了在工业软件研发场景中,进行知识治理的数据流水线的介绍:
从知识库到企业语义资产:工业软件 AI-Ready 数据治理项目案例分享
工业软件研发场景中,一个很典型的任务就是:根据需求说明和设计交互资料,自动生成测试点和测试用例。
表面看,这件事很适合大模型。只要把需求文档、设计文档、测试规范放进去,让 AI 输出测试点和测试用例即可。但在真实研发过程中,很快会遇到一个问题:AI 生成的内容看起来完整,却不一定具备专家测试思维。它可能覆盖了很多规则,却没有状态建模;可能写了很多用例,却没有识别高风险路径;可能列出了配置项,却没有理解物理机理、求解器约束和历史缺陷。
因此在实施过程中,我们特意进行了严格地对比测试,证明了企业对非结构化数据治理的价值。
本文基于一次严格 A/B 实验,对比两种生成方式:
Gen1 基线:未经过语义化、实体建模和类型校验,直接让 AI 基于需求和设计资料生成测试点、测试用例。 Gen2 知识嵌入:经过测试模式抽取、领域知识沉淀、语义对齐、知识图谱和规则约束后,再让 AI 生成测试点、测试用例。
文章希望说明一个核心观点:AI 生成质量的差异,不只来自模型能力,更来自企业是否把非结构化资料治理成了 AI 可消费、可校验、可复用的数据资产。
一、实验对象:同一个工业软件开发Story,两次生成
本次案例来自工业仿真软件中的一个测试场景:质量流出口, Mass Flow Outlet。
该功能涉及边界条件、属性页配置、多相流、辐射模型、DPM 离散相、时间表引用、set 文件导出、持久化、求解器可算性和数值准确性等多个维度。
对测试专家来说,这不是一个普通表单功能。测试时不仅要看 UI 是否显示、输入是否保存,还要看:
边界类型切换后模型树是否同步。 质量流率的默认值、合法范围、单位换算是否正确。 Profile(Time) 模式在无时间表时是否正确报错。 多相流 Phase1 / Phase2 配置是否独立持久化。 欧拉多相流与质量流出口不兼容时是否正确降级。 DO 与 S2S 辐射模型差异是否被正确验证。 set 文件导出是否与求解器约定一致。 历史缺陷是否被触发为回归测试。
本次 A/B 实验保持业务对象一致,比较两次生成结果:
Gen2 应用的知识资产包括:
state_modeling_knowledge.json:53 个状态模式。 physical_reasoning_rules.json:PR-001 至 PR-007 物理推理规则,以及 PE-001 持久化派生规则。 知识图谱:83 个节点、51 条关系。 3 条强制生成规则:每个测试点输出状态、推理中包含物理解释、持久化需求按场景分化。
这次对比的意义在于:不是比较“AI 能不能生成测试用例”,而是比较“同样数量的测试点和用例,在经过语义治理之后,结构质量是否明显变化”。
二、Gen1:文档直喂 AI 的结果,数量不少但结构性短板明显
Gen1 直接生成阶段,AI 并不是完全无效。它生成了 18 个测试点、65 条测试用例,并且在需求规则覆盖上表现不差。
从早期语义对比结果看,AI 与专家基线之间有较高的表层等效度:
如果只看数量,Gen1 似乎已经够用。但继续看结构化字段,问题就暴露出来了:
这个对比非常重要。它说明 AI 可以生成数量不少的测试内容,但如果没有语义化治理,它更擅长罗列规则和步骤,不擅长建模状态、风险、工作流、领域机理和持久化场景。
三、Gen1 综合评估:52.7 分,D 级
项目使用多维度评估体系对 Gen1 结果进行评分,综合得分为 52.7,等级为 D。
这个评分结果对非结构化数据治理部门有一个直接启发:文档直接给 AI,通常可以得到“可读结果”,但不一定得到“可用资产”。
如果没有语义层、实体关系和评估体系,企业很难知道 AI 的结果到底缺在哪里,也难以判断它能不能进入正式业务流程。
四、语义治理后:Gen2 做了什么不同
Gen2 不是简单换一个提示词,而是把前一轮评估差距转化为知识资产,再将知识资产嵌入生成过程。
第一,嵌入状态模式库。
项目从少量高质量人类测试专家历史测试案例中提取出 53 个状态模式,覆盖模型激活/关闭态、互斥阻塞态、降级过渡态、条件可见态、持久化验证态、批量操作态和页面动态更新态。
这类资产用于解决 Gen1 “有规则、无状态”的问题。
第二,嵌入物理推理规则库。
项目从专家与 AI 语义对比中提取出 7 条物理推理规则,包括:
边界类型到物理约束再到配置项映射。 代码架构假设到测试覆盖策略推导。 默认值到物理假设再到安全策略推导。 数值区间到物理含义映射。 求解器算法到兼容性再到互斥推导。 质量守恒到数值验证链推导。 差异驱动到验证焦点推导。
这类资产用于解决 Gen1 “有规则、缺物理推理”的问题。
第三,嵌入场景化持久化规则。
项目从历史测试案例中抽取出规则,用于根据测试场景派生持久化需求。例如多相流场景需要分相独立持久化,降级场景需要验证降级后类型保持,动态更新场景需要验证外部模型切换后的值一致性。
第四,增加结构化生成约束。
Gen2 对测试点和测试用例增加了强制字段要求:每个测试点必须输出状态,推理中必须包含物理推理,持久化需求必须按简易、多相流、辐射、DPM、降级等场景分化。
这已经不是普通提示词优化,而是把测试生成变成了一套可治理的数据工程流程。
五、知识嵌入示例:从文档片段到可调用知识资产
为了说明“知识嵌入”不是一句抽象概念,下面用本项目中的几类真实资产举例。
整个数据工程过程可以理解为:
原始研发资料
→ Markdown 中间层
→ 语义对象抽取
→ 测试模式/领域知识/状态模式沉淀
→ 实体关系与知识图谱
→ Gen2 生成时作为上下文与约束注入
→ 评估脚本量化反馈
第一类示例,是语义层对象。
原始测试用例里可能只是几条步骤:打开质量流出口属性页、查看 Mass Flow Rate、输入 0、输入 -0.1、选择 Profile(Time)、无时间表时报错。但经过语义层抽取后,它会变成一个可复用的业务语义对象:
{
"语义类型": "属性页最简易场景配置",
"测试目标": "验证质量流出口在无额外物理模型时的基础属性页结构和默认值正确性",
"覆盖的规则": [
"Mass Flow Rate子项含Constant和Profile(Time)两种定义方式",
"Constant模式:默认0 kg/s,合法值[0,+∞),单位跟随全局配置",
"Profile(Time)模式:无时间表时红框报错无法应用"
],
"覆盖的状态": [
"Mass Flow Rate=Constant(常量模式)",
"Mass Flow Rate=Profile(Time)(时间表模式)",
"无时间数据表时的非法态(红框报错)"
],
"覆盖的风险": [
"质量流率负值被接受导致反向流动与出口定义矛盾",
"Profile(Time)无数据表时未报错导致求解器运行时引用空数据表崩溃"
],
"应用的测试模式": [
"P03-属性页完整检查清单",
"C06-值范围边界精度"
],
"边界值": [
{"值": 0, "含义": "合法最小值,零质量流率", "预期": "接受"},
{"值": -0.1, "含义": "非法负值", "预期": "拒绝"},
{"值": null, "含义": "Profile模式无数据表", "预期": "红框报错"}
]
}
这类语义对象的价值在于,它把“测试步骤”提升成了“测试意图、规则、状态、风险、模式、边界值”的组合。Gen2 在生成时不再只看文档文字,而是能引用这些结构化语义单元。
第二类示例,是抽取后的领域推理规则。
比如从专家测试逻辑中抽取出的 PR-004 规则,专门处理数值区间到物理含义的映射:
{
"规则编号":"PR-004",
"规则名称":"数值区间→物理含义映射",
"推理模式":"将数学区间[0,1]、[0,+∞)等映射到CFD物理含义",
"模板":"[{区间}]的物理含义:值为{0}时表示[{物理含义A}],值为{1}时表示[{物理含义B}]。在CFD求解器中,值为0可能导致[{数值风险}],值为1可能触发[{限制函数}]",
"适用场景":"任何涉及数值参数合法范围验证的推理"
}
这条规则被嵌入后,AI 生成质量流率测试时,就更容易从“合法值是 [0,+∞)”继续推导出“0 kg/s 是零质量通量”“负值代表反向流动”“Profile 无时间表是空引用风险”。这就是知识治理对生成过程的影响。
第三类示例,是状态模式库。
工业软件测试中的很多缺陷发生在状态切换中,而不是静态字段中。项目从历史案例中抽取了 53 个状态模式,例如:
{
"state_name": "化学反应模型On态",
"source": "ST-2",
"trigger_enter": "右键Model-On/属性页选On",
"trigger_leave": "选Off/前置条件破坏",
"observable_properties": [
"模型树显示(On)",
"Reactions Option大类可见",
"混合物/流体材料/组分/计算域/监测/后处理出现化学专有项"
]
}
虽然这个状态模式来自化学反应场景,但它可以迁移到质量流出口的状态建模:某个模型打开、某类配置出现、前置条件破坏、配置消失或降级。Gen2 的 59 个测试点状态和 65 个用例状态,就是这类状态模式被嵌入后的结果。
第四类示例,是知识图谱中的实体关系。
知识图谱不是为了展示图形,而是为了把“边界条件、物理约束、UI 配置、状态、测试策略、缺陷模式”串成可查询链路。
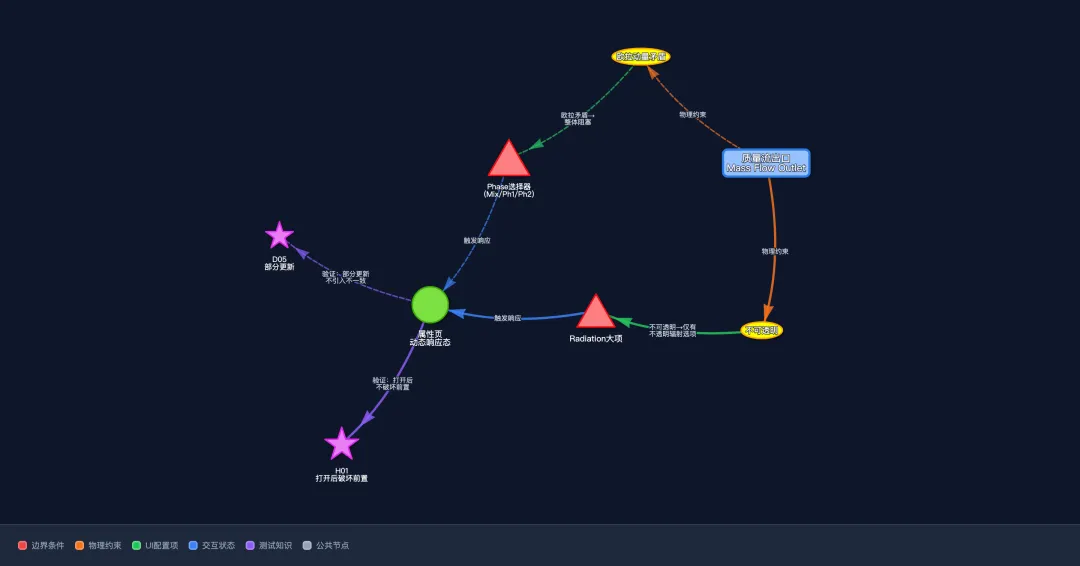
在质量流出口图谱中,部分实体如下:
BC-MFO 质量流出口 · Mass Flow Outlet boundary
PC-MassFlux 固定质量通量 constraint
PC-EulerianConflict 欧拉动量矛盾 constraint
PM-Eulerian 欧拉多相流 model
UI-MFR MassFlowRate · Const/Profile ui
ST-EulerianBlock 欧拉互斥阻塞态 state
TK-P04 P04 双向互斥 knowledge
TK-D12 D12 欧拉清理不全 knowledge
部分关系如下:
BC-MFO → PC-MassFlux 物理约束
BC-MFO → PC-EulerianConflict 欧拉动量矛盾
PC-MassFlux → UI-MFR 驱动UI规则
PM-Eulerian → ST-EulerianBlock 触发阻塞态
ST-EulerianBlock → TK-P04 验证双向互斥
ST-EulerianForce → TK-D12 防欧拉清理不全
PM-Eulerian → BC-MFO 不兼容·降级为壁面
这样一来,Agent 在生成测试点时可以沿着图谱做推理:
质量流出口
→ 固定质量通量 / 欧拉动量矛盾
→ MassFlowRate UI / 欧拉互斥阻塞态
→ P04 双向互斥 / D12 欧拉清理不全
→ 生成正向降级、反向置灰、set 文件残留清理测试
这就是“知识嵌入”的核心:不是把资料原文塞进上下文,而是把可复用的语义对象、领域规则、状态模板和实体关系变成 Agent 可调用的结构化上下文。
第五类示例,是图谱查询能力。
项目中已经准备了知识图谱查询模板,例如查询质量流出口的完整约束链:
MATCH p=(v)-[:relation*1..4]->(end)
WHERE id(v) == "BC-MFO"
RETURN p;
也可以查询欧拉多相流的不兼容传播链:
MATCH p=(m)-[:relation{relation_type:"conflicts_with"}]->(bc)-[:relation*1..4]->(tk)
WHERE id(m) == "PM-Eulerian"AND tk.entity_group == "knowledge"
RETURN p;
这些查询模板的价值在于:当后续新增一个功能或测试场景时,Agent 不必重新“猜”测试策略,而是可以先从图谱中召回相关约束、状态和测试知识,再进入生成环节。
因此,本项目中的知识嵌入不是单点能力,而是一条数据治理链路:
文档治理为语义对象
→ 语义对象沉淀为领域规则
→ 领域规则连接成知识图谱
→ 知识图谱和规则库嵌入生成过程
→ 生成结果再被评估脚本量化
→ 评估差距反向更新知识资产
六、A/B 实验全量统计:同样 18 个测试点、65 条用例,结构质量发生明显变化
本次 A/B 实验的关键,是 Gen1 和 Gen2 的输出规模保持一致:都是 18 个测试点、65 条测试用例。
因此,下面的提升不是靠“多生成一些内容”实现的,而是在同等输出规模下,结构化字段和推理质量发生变化。
测试用例层面的变化更明显:
这组数据对非结构化数据治理部门非常关键。它说明,语义治理的价值不只是“让 AI 说得更像专家”,而是让 AI 输出从自然语言文本变成结构化数据资产。
Gen1 的 65 条用例更多是“步骤和预期”;Gen2 的 65 条用例开始带有状态、持久化、领域知识和推理字段。这些字段后续可以被评估脚本、测试管理系统、知识图谱和 Agent 继续消费。
七、主评估结果:Gen2 从 52.7 提升到 59.2,达到专家水平的 72.2%
评估脚本对 Gen1、Gen2 和人类专家结果进行了对比。
Gen2 总评分比 Gen1 提升 6.5 分,达到人类专家水平的 72.2%。
这个提升没有达到最初 Quick Win 预期中的 65 分目标,但已经证明三类知识资产确实对生成质量产生了正向影响。
更重要的是,提升不是平均发生的,而是集中发生在几个关键短板维度上。
这个表格值得仔细看。Gen2 并不是所有维度都提升,而是在状态建模、领域推理、持久化、风险意识和工作流方面提升明显,同时也暴露出边界值和策略质量两个新问题。
这恰恰说明 A/B 实验的价值:它不是为了证明“治理后一定全面更好”,而是为了量化哪些治理动作有效,哪些治理动作还没有被稳定转化为生成质量。
八、最大提升一:从 0 个状态到 59 个测试点状态、65 个用例状态
Gen1 最大的问题是“有规则,没有状态”。
例如,Gen1 能写出“开启欧拉多相流后质量流出口不可用”,但不会显式表达:
欧拉关闭、质量流出口激活的正常态。 欧拉开启、质量流出口自动变为壁面的降级过渡态。 欧拉开启、质量流出口置灰不可选的互斥阻塞态。 属性页打开时开启欧拉后的强制关闭态。
Gen2 在知识嵌入后,将这些内容写入“覆盖的状态”字段。全量统计显示:
测试点层面,状态数从 0 增加到 59。 测试用例层面,状态数从 0 增加到 65。
这说明状态模式库确实生效了。AI 不再只是列规则,而是开始把测试对象理解为状态机。
对工业软件测试来说,这是一个关键提升。因为很多缺陷并不发生在静态规则上,而发生在状态切换、动态刷新、保存重开、模型切换和异常路径中。
九、最大提升二:持久化从全局声明变成场景化数据
Gen1 的持久化问题非常典型:它知道“要验证保存重开”,但不知道不同场景的持久化含义完全不同。
例如:
Constant 模式要验证数值持久化。 Profile(Time) 模式要验证时间表变量引用持久化。 多相流场景要验证 Phase1 / Phase2 分相独立持久化。 辐射场景要验证 Emissivity、BoundaryType 等字段持久化。 DPM 场景要验证 Escape / Trap 选择持久化。 欧拉降级场景要验证降级后的 Wall 类型持久化,以及 set 文件中质量流出口特有块被清除。
Gen2 通过 PE-001 持久化派生规则,把持久化从“全局声明”变成了“按场景派生”。
A/B 统计显示:
在维度评分中,持久化验证从 25 分提升到 100 分,是本次 A/B 实验中提升最大的维度。
这对数据治理部门很有启发:所谓高质量数据,不只是字段更多,而是字段要能表达业务场景差异。
十、最大提升三:领域推理从配置规则进入物理和求解器层
Gen1 的推理更多停留在“配置规则到预期结果”层。例如它会说“质量流率合法值是 [0,+∞)”,但不一定说明:
0 kg/s 表示无流动出口,是合法最小值。 负质量流率意味着反向流动,与出口定义矛盾。 欧拉多相流为什么与固定出口质量通量不兼容。 质量流出口的验证链为什么要从用户设定走到求解器迭代、监测值和后处理积分。
Gen2 引入物理推理规则后,测试点和用例中开始出现更明确的物理解释和策略说明。
代表性测试点评估显示:
这里需要注意,推理更长不等于一定更好,但它说明 Gen2 已经从“只输出步骤”进入“输出测试意图、物理原因、状态解释、策略选择”的阶段。
对非结构化数据治理来说,这类推理字段非常重要。它们可以反向沉淀为领域知识库,也可以作为后续 Agent 解释测试设计依据的上下文。
十一、最大提升四:风险意识从 55 提升到 85
Gen1 并不是没有风险意识,但它更多识别显性风险,例如 UI 错误、字段错误、set 文件残留等。
Gen2 在嵌入缺陷模式、状态模式和物理推理后,风险识别开始靠近专家思路。例如:
欧拉不兼容清理不全导致 GUI 与求解器合约断裂。 多相流 Phase 间质量流率相互覆盖。 Profile(Time) 变量重命名后引用断开。 set 文件字段名、值、结构错误导致求解失败。 降级后原质量流出口特有块未被清理。
评估结果显示,风险意识从 55 提升到 85,已经高于人类专家基线中的 80 分。
这并不意味着 Gen2 超过了专家,而是说明在结构化风险字段和显式风险描述上,AI 可以被知识资产显著拉升。
十二、仍然暴露的问题:边界值和策略质量没有被稳定治理
这次 A/B 实验也暴露出两个重要问题。
第一,边界值治理不稳定。
代表性测试点中,Gen2 已经出现了 3 个边界值,例如 0 kg/s、-0.1 kg/s、无时间表选 Profile 等。但在全量 18 个测试点统计中,边界值字段仍然没有稳定扩展,维度评分也从 Gen1 的 45 降到 Gen2 的 20。
这说明边界值不是靠几条物理推理规则就能稳定生成的。后续需要单独建立数值风险知识库,覆盖:
零值。 负值。 极大值。 空值。 单位换算边界。 浮点精度和容差。 Profile 时间插值带来的瞬态稳定性问题。
第二,策略质量评分下降。
Gen2 的策略质量从 65 降到 1.7,主要说明在新的生成格式中,测试策略标签、策略引用结构或评估脚本识别口径没有被稳定保持。
这不一定表示 Gen2 没有策略思路,因为 Gen2 文本中已经出现了 P01、P03、C02、C03、C10、D12 等策略和缺陷模式。但它说明策略信息没有以评估脚本可稳定识别的结构输出。
对数据治理部门来说,这也是一个典型问题:文本里“写到了”,不等于结构化字段里“治理到了”。如果希望后续可评估、可检索、可统计,策略必须成为稳定字段,而不能只是自然语言说明。
十三、治理前后对测试生成质量的本质差异
从数据治理角度看,治理前后的差异不是“AI 有没有生成用例”,而是“生成过程是否可控、可解释、可评估、可复用”。
这说明,语义治理不是让 AI “多写一点”,而是让 AI 的输出具备更多可治理字段:状态、持久化、推理、风险、工作流。
这些字段一旦稳定下来,就可以进入企业数据资产体系,成为后续知识图谱、测试平台、Agent 服务和高质量数据集的基础。
十四、对非结构化数据治理部门的启示
这个案例对企业非结构化数据治理有几条直接启示。
第一,不能只治理文档格式,还要治理业务语义。
PPT、HTML、Excel、Markdown 只是载体。真正有价值的是里面的需求规则、状态流、参数约束、测试策略、风险模式和专家判断。
第二,AI 输出也应该成为治理对象。
AI 生成的测试点、测试用例、评估报告、语义对象和失败案例,都应该进入数据治理闭环。它们不是一次性内容,而是后续优化模型、完善知识库、构建数据集的重要来源。
第三,评估报告本身是高价值数据资产。
语义对齐、覆盖分析、风险差距、模式对比、领域推理评估、A/B 对比和综合评分,能够帮助企业明确 AI 能力边界。这类报告应该被持续沉淀,而不是只作为一次性项目材料。
第四,知识资产需要结构化到字段级。
这次实验中,策略质量下降说明一个问题:自然语言里写到了,不代表评估脚本能识别。企业语义资产不能只停留在文本描述层,需要明确字段、类型、枚举、校验规则和引用关系。
第五,数据治理要为 Agent 服务。
未来企业知识资产不只是给人查,还要给 Agent 调用。因此,每个语义对象都需要有来源、版本、权限、置信度、实体关系和可校验结构。
十五、持续地知识资产治理工作
基于本次 A/B 实验,后续不建议继续只做泛化提示词优化,而应围绕已经暴露的指标短板继续治理。
第一,建立数值风险知识库。
边界值和数值稳定性仍然是短板,需要把零值、负值、极大值、单位换算、浮点精度、时间插值、收敛容差等场景结构化。
第二,把策略模式改造成稳定字段。
策略不能只写在推理文本里,应拆成可统计字段,例如 strategy_id、strategy_name、strategy_type、applied_reason、source_pattern。
第三,扩充状态模式库。
当前 53 个状态模式已经验证有效,下一步可以扩展到 100 个以上,覆盖更多工业软件功能类型,例如材料、网格、求解控制、监测、后处理和报告。
第四,补齐实体关系和知识图谱召回链。
将边界类型、物理模型、UI 配置项、set 字段、求解器约束、测试策略、缺陷模式之间的关系稳定表达出来,让 Agent 在生成时不只是“记住知识”,而是能沿关系链推理。
第五,持续执行“生成、评估、抽取、反哺”的闭环。
这次 A/B 实验证明,知识嵌入能带来可量化提升;同时也证明,每次评估都会暴露新的治理问题。真正的 AI-Ready 数据治理,不是一轮建设完成,而是持续迭代的数据资产工程。
结语
这次严格 A/B 实验说明,未经过语义化、实体建模和类型校验的 AI 生成,确实可以产生看起来完整的测试点和测试用例,但它在状态建模、场景化持久化、工作流传播、领域推理和数值稳定性方面存在明显短板。
经过测试模式抽取、领域知识沉淀、语义对齐、知识图谱和规则嵌入后,Gen2 在同样 18 个测试点、65 条测试用例的规模下,将总评分从 52.7 提升到 59.2,并在状态建模、持久化验证、领域推理、风险意识和工作流方面取得明显提升。
同时实验也提醒我们:语义治理不是一次性把 AI 变成专家。边界值、数值稳定性和策略字段结构化仍然需要继续治理。
对非结构化数据治理来说,这正是 AI-Ready 数据治理的核心价值:不是把更多文档交给模型,而是把文档中的业务结构、专家经验、评估反馈和 A/B 实验结果,转化为可被 Agent 稳定调用、可被企业持续治理的语义资产。
