 夜雨聆风
夜雨聆风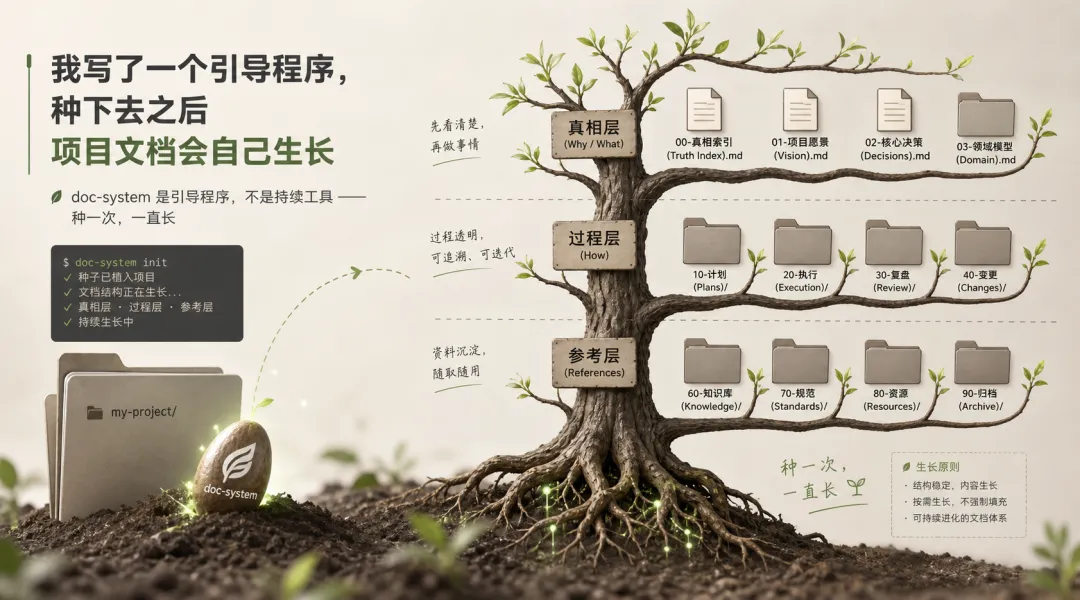
最麻烦的就是开发过程中,codex新开对话还要重复的说一遍需求,并且还可能不详细。
那天晚上我在改 llmnode 的路由注册逻辑,正写到第二阶段——把 model_routes 从内存缓存升级成持久化注册表,支持 profile_seed 和 manual 两种来源,手动路由重启不丢失。
写到一半,脑子里突然蹦出来一个想法。
密钥管理。现在的 admin key 和 inference key 全混在通用密钥表里。admin key 应该是全库唯一的,scope 固定写死,不能通过普通密钥接口增删改查。这块不改,后面权限模型一定会炸。
但我现在正在写路由注册。切过去改密钥,上下文全丢。不切,这想法明天可能就忘了。
我当时的做法跟大多数开发者一样:在聊天框里敲了一行「记住,后面要做 admin key 分离」,然后继续写路由。
第二天早上换了一台电脑。打开 Claude Code,它读了一遍代码,开始给建议。
歪了。全歪了。
它不知道路由注册已经切成了两阶段,不知道密钥那边我标记过隐患,不知道这批改动里哪些是已完成的、哪些是待办的、哪些是我随手记的想法。
我突然意识到一件事。
AI 编辑器有一个致命弱点:它没有跨会话的记忆。
你关掉终端、换一台设备、新建一个会话,它就回到出厂状态。对项目的所有认知只剩代码本身。
代码能告诉你「现在是什么」。代码不会告诉你「为什么变成这样」「接下来要做什么」「上次那个还没处理的想法去了哪里」。
这些东西,只在你脑子里。
等你换了一台设备,脑子跟着走了,AI 就瞎了。
▍superpowers 能设计蓝图,但管不了这些
你可能会问,不是已经有 superpowers 了吗?
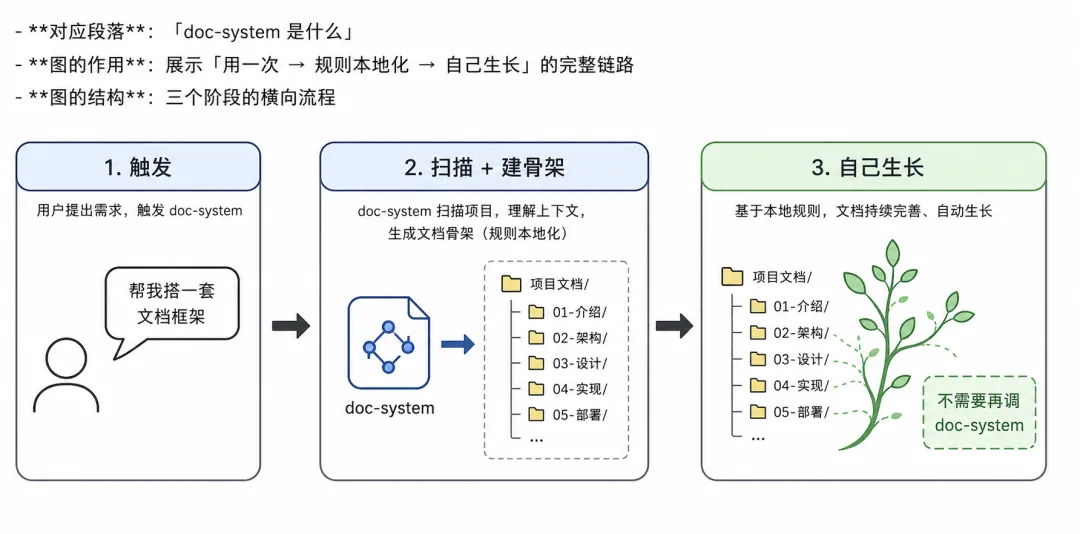
对,superpowers 确实能帮我们做蓝图设计。你告诉它要做什么功能,它会展开 spec,写设计文档,输出执行 plan。
但 superpowers 只管「这一次怎么做」。
它不管这些事:这个 spec 做完之后,里面的关键结论有没有回流到正式文档?三个月前那份设计稿还躺在目录里,新 AI 会话读到它会不会当成当前状态?开发到一半被打断了,下次怎么快速找到「上次写到哪了」?那个突然冒出来的灵感,应该放在哪里才不会丢?
superpowers 是画笔,不是画室。
你需要的是一套规则。一套让所有信息——蓝图、计划、灵感、经验、当前状态——各归其位、持续更新、不会腐化的规则。
▍doc-system 是什么
01
简单说,它是一个引导程序。
你用一次。就一次。
对它说「帮我搭一套文档框架」,它会扫描你的仓库,告诉你当前文档哪里有问题,然后帮你建好骨架、写好规则。
之后你就可以把它忘了。
因为规则已经写进了你项目的 CLAUDE、glossary、development-workflow 里。后续每一次打开 Claude Code 或 Codex,AI 读到的第一件事就是这套规则。
它不需要再加载 doc-system。规则本地化了。
这就是我说的「引导程序」——它种下一颗种子,然后项目文档系统自己生长。
▍三层模型:信息找到了自己的家
02
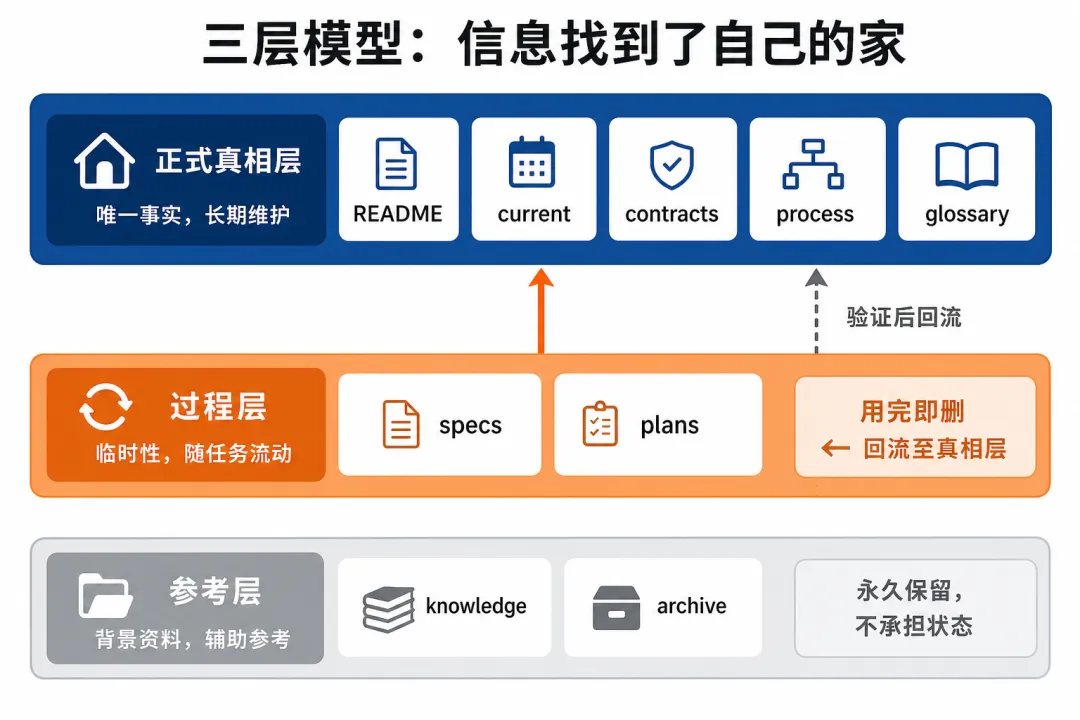
doc-system 在项目里建立的核心结构是三层。
第一层,正式真相层。回答一个问题:这个项目现在是什么。
这里面只有五个东西。
docs/blueprint/current 写系统当前真实状态。当前主链路是什么,哪些能力已经落地,哪些还在设计,配置真相源在哪里。没有任何未来规划混进去。
docs/contracts/ 写契约。CLI 命令的精确语义、路由对象的 19 个字段定义、API 的请求响应格式。这不叫文档,这叫「代码必须长这样,否则就是 bug」。
docs/process/ 写流程。怎么启动,怎么开发,怎么部署,开发完后要回流哪些文档。
docs/glossary 写术语。什么是 ready,什么是 warming,backend_type 有几个合法值。87 行,没有任何废话。只做一件事:让项目里所有人(包括 AI)对同一个词有同一种理解。
README 写入口。项目是什么,最小启动方式,阅读顺序。仅此而已。
第二层,过程层。回答一个问题:现在正在设计什么、正在做什么。
docs/superpowers/specs/ 放设计展开,docs/superpowers/plans/ 放执行计划。
但这一层有一条铁律。
用完就删。
一个功能做完了,对应的 spec 和 plan 必须删除。里面的关键结论回流到正式真相层。不能让它永远躺在那里,污染下一个 AI 会话的判断。
这就是 superpowers 缺掉的那一环。superpowers 负责生产 spec 和 plan,doc-system 负责管理它们的生命周期——什么时候创建,什么时候回流,什么时候删除。
第三层,参考层。回答一个问题:为什么这样做。
工程经验、联调日志、对比资料。
比如 llmnode 的参考层里有一份 backend_integration_qa,记录了 vLLM、llama.cpp、SGLang 三个后端联调时踩的五个坑。每个都写明了现象、根因、解决方案。
这些信息不承担当前状态——契约改了参考层不会跟着改。但下次有人问「llama.cpp 的 Docker 镜像为什么要选 full-cuda 而不是 full」,翻到第三条记录就行,不用从头踩一遍。
三层拆开以后,一个 AI 会话启动时读到的不再是一团乱麻。
它知道 current 是唯一真相。roadmap 是下一步。spec 和 plan 是临时的工作区,随时可能被删。knowledge 是背景注释,仅供参考。
它不会再拿着一份三个月前的设计稿当圣旨。
▍灵光一闪的东西,终于有地方放了
03
回到开头那个场景。
你在写功能 A,脑子里蹦出来一个关于功能 B 的想法。不适合现在切过去做,但又不想丢掉。
没有 doc-system 的时候,你的选择基本只有两个:记在聊天框里,赌下次 AI 会话还能搜到;或者记在脑子里,赌自己不会忘。
有了这套系统之后,每个想法都有确定的去处。
如果是小优化,记进 roadmap 的 P2 区域,标一句「低优先级,有空再做」。
如果涉及跨层改动——比如 admin key 分离这种会影响 contracts、storage、API 三层的改动——直接在 superpowers/specs/ 里开一份轻量设计稿,把想法展开成具体方案。等当前功能做完了再回来看。
如果是已验证的经验教训,直接写进 knowledge/,下次翻得到就行。
重点不是「记下来了」。
重点是记在了对的地方。
三个月后你换了一台新电脑,打开 Claude Code,它读 roadmap 就能看到 P2 里挂着的那条。读 superpowers/specs/ 就能看到你展开过的设计稿。读 knowledge/ 就能看到你踩过的坑。
不需要你记得。系统替你记得。
▍它怎么帮你从「中断」里恢复
开发被打断这件事,频率比我们以为的高得多。
出去吃个饭,回来不记得写到哪了。周五下班,周一打开 IDE 一片空白。台式机写到一半,换笔记本继续,上下文全丢。在 Codex 里调了一个小时的 prompt,切到 Claude Code 要重新解释一遍项目背景。
doc-system 解决这个问题的方式,不是存储对话历史。它存储的是结构化的项目认知。
任何一个 AI 会话启动后,按这个顺序读一遍项目文档:
README → current → roadmap → CLAUDE
它就能在几分钟内理解:项目现在处于什么阶段,刚完成了什么,下一步要做什么,有哪些硬约束不能碰,哪些文件是真相源,哪些只是参考。
这不是一句「这是一个 LLM 推理网关项目」能比的。
这是一套完整的「项目当前认知」。信息密度极高,但噪音极低。
而 doc-system 最后生成的那份「交接提示词」,更是一个作弊器。
你今天在台式机上搭好文档骨架,明天带笔记本去咖啡馆。打开 Claude Code,把交接提示词往里一贴——AI 立刻知道当前骨架长什么样,需要补哪些文件,应该优先读哪些事实源,绝对不要编造哪些内容。
这就是我说的「让 AI 编辑器不再失忆」。
不是 AI 真的记住了。是它有了足够好的外部记忆结构,可以在几分钟内重建对项目的全部理解。
▍llmnode 就是一个活例子
我自己的 llmnode 项目就是用 doc-system 建的。
https://github.com/territoryLiu/llmnode
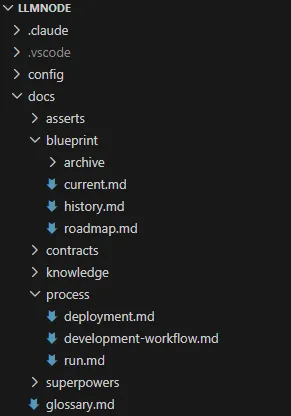
它的 docs 目录长这样:
docs/
├── glossary # 术语定义,87 行
├── blueprint/
│ ├── current # 系统当前真相,404 行
│ ├── history # 阶段演进摘要
│ ├── roadmap # 当前优先级
│ └── archive/ # V1/V2 历史快照
├── contracts/
│ ├── control-plane # CLI 命令契约,352 行
│ └── backend-routing # 路由契约,481 行
├── process/
│ ├── development-workflow
│ ├── run
│ └── deployment
├── knowledge/ # 6 份参考文档
├── superpowers/ # 活跃的设计和计划(目前空)
└── asserts/ # 控制台截图
每一个文件都只承担一个职责。没有任何两个文件在讲同一件事。
contracts/control-plane 里对 status 命令的定义精确到了返回字段级别。backend-routing 里对路由对象的定义精确到了 19 个字段。glossary 里 87 行定义了全部术语。
AI 读到这套文档的时候,它不猜。
▍怎么开始
doc-system 的 GitHub 在这里:
https://github.com/territoryLiu/doc-system
安装成 Claude Code 的 Skill 之后,你只需要说一句「帮我搭一套文档框架」。
Skill 会先扫描你的仓库现状——README 写了什么,CLAUDE 写了什么,docs 目录有什么,代码入口在哪。
然后输出一份诊断报告。告诉你在当前阶段,哪些文档已经有了但职责不清,哪些文档还缺着,建议建什么样的骨架。
你不确认,它不碰任何一个文件。
确认之后,它才会创建目录和骨架文件。骨架只包含结构和最小章节模板,不编造项目真相。没验证的内容会显式标成待补。
然后它的使命就结束了。
接下来,规则已经在你的项目里了。CLAUDE 知道真相源优先级。development-workflow 知道什么时候该写 spec、什么时候该回流。glossary 知道每个词的确切含义。
你继续开发。每次完成一个功能,按照回流规则更新对应的文档。每次冒出新想法,放进对应的层级。
文档系统跟着你的开发节奏自己生长。
不需要再调一次 doc-system。
---
AI 辅助编程的效率瓶颈,正在从「AI 不够聪明」转移到「AI 不够了解你的项目」。
而让 AI 了解你的项目,不靠更长的 prompt,不靠更详细的系统指令,不靠把整个对话历史塞进上下文窗口。
靠的是一套精简、结构化、语义边界清晰、会自己生长的文档系统。
种一次,一直长。
---
doc-system GitHub: https://github.com/territoryLiu/doc-system
llmnode 示例项目: https://github.com/territoryLiu/llmnode
以上。
