 夜雨聆风
夜雨聆风《7天AI通识计划:读懂大模型,用好人工智能》系列写到第五篇了。前四篇我们搞懂了AI是什么、模型怎么选、怎么提问、怎么防忽悠。 但有一个问题一直没解决:你用的AI,数据都上传到了云端。
关注我的朋友很多是同行,都是从事金融工作的,那我们日常处理的数据都比较敏感,我们更希望能在本地处理, 网上也有相关教你如何本地部署大模型的教程,其中以Ollama、LM Studio这两款软件居多。
我简单介绍一下,Ollama和LM Studio,内核用的都是llama.cpp。 llama.cpp是“引擎”,作者用C++写的,能在普通电脑甚至手机上高效运行大模型。 Ollama和LM Studio是“整车”,套在llama.cpp外面,让你不用直接操作发动机,点火挂挡就能开。 所以,性能潜力上三者的天花板一样,但在易用性、封装程度和适用场景上区别巨大。理解了这个,再看它们各自的特点就清晰多了。
Ollama的设计处处体现着极简和自动化,是为“集成”而生的开发工具。 一句话:ollama run qwen2.5:7b。一条命令自动搞定下载、运行等所有事。
集成能力:内置OpenAI兼容API,启动即服务(localhost:11434),可直接被LangChain、VS Code插件等调用。Docker支持让它能方便地跑在服务器上做服务。
模型管理:主要通过命令行pull/list/rm管理。但官方收录的模型有限,导入非官方GGUF模型需要写配置文件。
优缺点:对熟悉命令行的开发者极其友好;但抽象层多,若出问题排查困难,在高并发场景下吞吐量可能是瓶颈。
LM Studio是开箱即用的图形界面应用,让你像浏览应用商店一样探索AI模型。
使用体验:界面精美,纯鼠标操作。内置模型搜索,可浏览HuggingFace按模型大小等下载GGUF模型。
集成能力:可一键开启兼容OpenAI的API服务器,但主要供聊天或测试用。
优缺点:对新手和技术团队非开发成员都很友好;但软件自身占较多系统资源(约500MB),长期服务不稳定。
llama.cpp就是最底层、最高效的那个C++库,由你亲手操控。
使用方式:你需要自己编译它,在命令行使用./main或./llama-server敲命令。学习曲线陡峭,但换来了对推理过程精确到极致的控制权。
性能优势:极低开销,在相同硬件测试中,它的生成速度略快,且内存占用最小(约0.3GB)。
集成能力:自带llama-server提供API,但需自己配置,更像可嵌入项目的模块。
优缺点:性能极致,高度可控;但没有图形界面,需要懂编译、会命令行等技术背景。
特性 | Ollama | LM Studio | llama.cpp |
核心定位 | 轻量部署与服务集成 | 桌面端图形化管理与测试 | 底层高性能推理引擎 |
用户界面 | 命令行 (CLI) | 图形界面 (GUI) | 命令行 (CLI) |
安装难度 | 极低(一行命令) | 低 (下载安装包) | 高 (需编译环境) |
主要用户 | 开发者、技术爱好者 | 新手、非技术用户、模型探索者 | 硬核极客、追求极致控制和性能者 |
资源占用 | 中等 (~0.5GB开销) | 较高 (~0.6GB开销 + 约500MB GUI) | 最低(~0.3GB开销) |
API集成 | 最佳(原生REST API) | 支持 (需手动开启) | 支持 (内置llama-server) |
模型来源 | Ollama官方库 | 内置搜索下载(HuggingFace) | 手动下载GGUF文件 |
最佳场景 | 构建本地AI应用,无缝集成 | 快速体验、评估模型、非技术团队使用 | 深度定制、资源受限环境、嵌入式开发 |
听了上面介绍后,大家会不会有一种感觉,如果一个软件既有llama.cpp的高性能,又有LM Studio的图形界面和新手友好性,而且一键执行不用安装各种编译环境,岂不是很爽!
有这样想法的人,一定是领导!至少是分行行长!因为只有你们既要贷款新增、又要储蓄增长、还要中收倍增等等...... 你们想的真美!
但是,谁让我也是干金融的,通过我不懈努力,还真找到这样变态的产品,来满足你的需求!感谢悄枫同学,他做了一个llama-cpp-desktop,完美的满足了行长们的要求。
你连安装都不用,直接解压执行就好! 接下来,我介绍如何做
跟着操作即可(懒得一步步看的,直接转到最后“福利”)
第一步 需要到github下载llama.cpp
你会看到很多版本,到底下载哪个版本,是根据你的电脑硬件配置决定的。
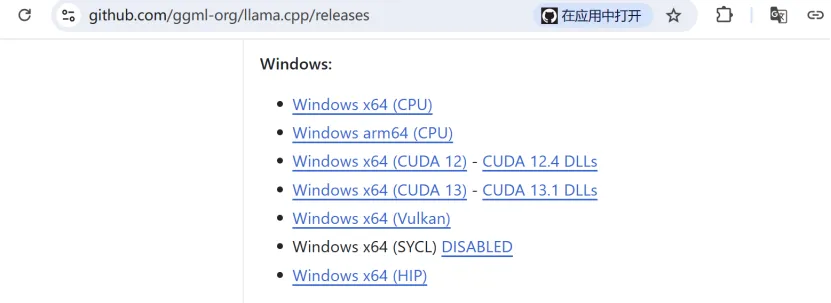
一、纯 CPU 版本(不挑显卡)
二、NVIDIA 显卡加速版本(需要独显)
如果你的电脑有 NVIDIA 显卡(RTX 30/40 系列、GTX 16 系列等),选这两个能跑得飞快。
怎么知道自己的显卡支持哪个? 在命令行输 nvidia-smi,看右上角 “CUDA Version”,如果显示 12.x 就下 CUDA 12;如果是 13.x 或更高,可以尝试 CUDA 13。
三、其他显卡 / 通用加速版本
四、一句话总结:我该下哪个?
第二步、在gitbub下载llama-cpp-desktop
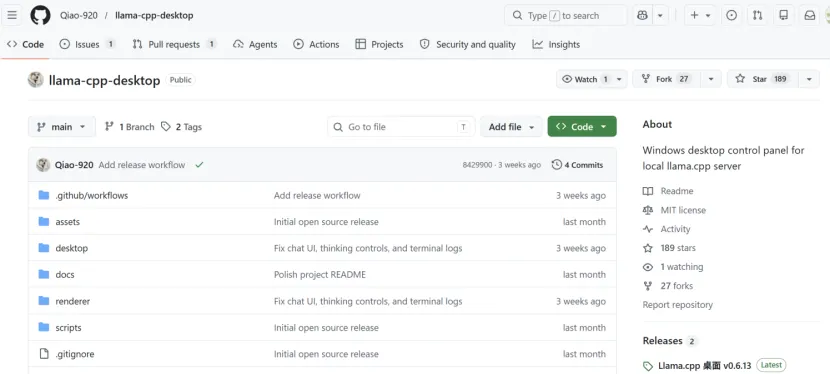
第三步、去魔搭社区下载你需要的模型
模型很多,根据你的需要下载即可。
第四步、启动llama-cpp-desktop运行大模型
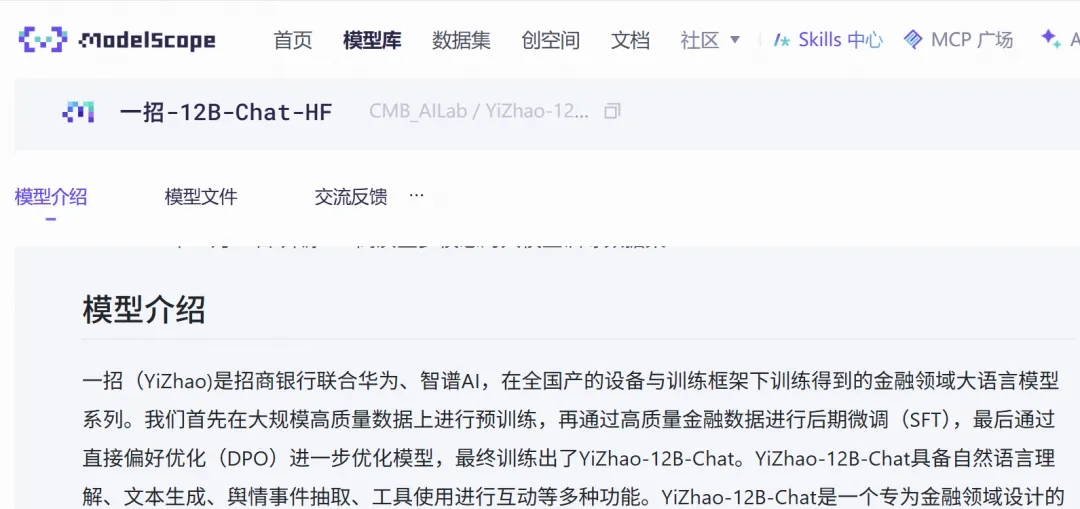
顺便把我在“全国银行对公负责人交流群”挖的坑填上,我把招商银行一招模型转换好了,已经做了量化YiZhao-12B-Chat-HF-Q4_K_M.gguf,可以直接用llama-cpp-desktop调用。关注“昆仑雪域”,私信“一招”,即可获取量化后的一招模型。
这是我用cpu跑的,可以看到比较慢11.09t/s

这是我用gpu跑的,可以看到速度明显提升84.84t/s

最后,再说一点硬件到底要什么配置?——别被吓跑
很多人一听“本地部署大模型”,第一反应是“我电脑不行”。没有那么绝对,行不行跟你的使用场景有关。
| 大多数办公电脑 | ||||
B是什么? 大模型的参数规模。7B就是70亿个参数。参数越多,模型越聪明,但需要的硬件也越高。
直接给结论: 绝大多数人用7B-8B模型完全够。你不用为了这个买新电脑。先用现有电脑试,觉得慢再考虑升级。如果你是Windows用户且没有独显,建议用7B以下模型。
这里是“福利”
我就知道当行长的你比较聪(lan)明(duo),所以我把需要用到的软件及模型都放到百度网盘上了,关注“昆仑雪域”,私信“本地部署”即可获得下载链接。
如果你的电脑没有独立显卡,你就下载llama-b9360-bin-win-cpu-x64 + Llama.cpp-Desktop.exe + DeepSeek-R1-0528-Qwen3-8B-Q2_K.gguf 即可。

