 夜雨聆风
夜雨聆风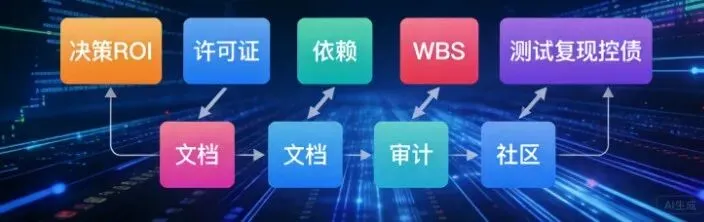
你精通 Kohn-Sham 方程,能闭眼写出 PAW 赝势的生成流程,对平面波截断能的选取如数家珍。但当导师说"把这个方法做成一个软件工具"的时候,你突然发现——写代码和做软件,是两个完全不同的世界。
VASP 花了 20 多年才走到今天。QE 的代码库超过 200 万行。ABACUS 从 2016 年启动,到 2024 年才发布 3.0。DFT 软件的开发周期以"年"为单位,而大多数课题组的项目周期只有 1-3 年。
以下 10 个概念不是并列的清单,它们沿着软件生命周期依次展开——每一步是下一步的前提,跳过任何一步,后面的步骤都会塌方。
决策 → 法律 → 技术 → 规划 → 开发(测试→复现→控债) → 交付(文档) → 运维(审计) → 生存(社区)第一阶段:开工前——三个问题决定要不要动手
1. ROI:值不值得做?
ROI(Return on Investment,投资回报率)不是商业课的专利。写代码之前,先算一笔账:
投入: 你花 6 个月写一个自动化后处理脚本,期间不能发论文。回报: 课题组 20 个人每人每周省 2 小时,一年省 2000 小时。
6 个月 ≈ 1000 小时投入,换 2000 小时/年的回报——第一年就回本,值得做。
但如果只是你自己用,一年省 100 小时——6 个月投入换 100 小时回报,ROI 为负。不如直接用现成工具。
ROI 为负?到此为止,不用往下看了。ROI 为正?进入下一个问题。
2. 许可证:能不能做?
你基于 QE(GPLv2)写了一个后处理工具,想发布到 GitHub——你的工具必须也用 GPLv2。这不是建议,是法律要求。
许可证决定了你的技术选型边界。如果你打算做商业化的 DFT 工具,GPL 系列的代码一行都不能碰。先搞清楚许可证,再决定用什么库——否则写了一半发现法律上走不通,全部推倒重来。
许可证没问题?进入技术选型。
3. 依赖关系:站在谁的肩膀上?
许可证划定了法律边界,依赖关系划定了技术边界。两者必须同步考虑——你选的库许可证不兼容,等于白选。
DFT 软件的依赖链比你想象的长:
你的工具 ├── numpy 1.24+ ├── scipy 1.10+ ├── pymatgen 2024.x │ ├── monty │ ├── spglib │ └── matplotlib ├── ASE 3.23+ │ └── numpy (版本冲突?) └── paramiko 3.x └── cryptography └── cffi三个真实踩坑场景:
• pymatgen 要求 numpy ≥ 1.24,但你的超算环境只有 1.21。升 numpy?其他软件可能崩。 • ASE 和 pymatgen 对同一概念(如晶胞)的数据结构不同,混用时要手动转换。 • paramiko 依赖的 cryptography 库需要编译,Windows 上经常装不上。
最佳实践: 用 pyproject.toml 声明依赖,用 pip-compile 生成锁文件,用 conda 或 uv 管理环境。不要裸 pip install。
三个前置问题都过了?恭喜,可以开工了。
第二阶段:规划——把愿望变成路线图
4. 规划(WBS):大目标拆小任务
"我要写一个 DFT 计算工作流管理工具"——这句话不是规划,是愿望。
规划的第一步是 WBS(Work Breakdown Structure,工作分解结构)。把大目标拆成可执行的小任务:
DFT 工作流工具├── 输入模块│ ├── 结构文件解析(POSCAR/CIF)│ ├── 参数模板生成(INCAR)│ └── K 点自动生成├── 提交模块│ ├── Slurm 脚本生成│ ├── PBS 脚本生成│ └── 本地直接运行├── 监控模块│ ├── 作业状态查询│ ├── 收敛判断│ └── 异常告警└── 后处理模块 ├── 能量/力提取 ├── 带结构绘制 └── 电荷密度可视化每个叶子节点都是一个可以在 1-2 周内完成的任务。没有 WBS,你的项目会变成"什么都做了但什么都没做完"。
WBS 还有一个隐藏价值:它让你在写第一行代码之前就看清了依赖关系和优先级——输入模块是提交模块的前提,提交模块是监控模块的前提。先做哪个,后做哪个,一目了然。
第三阶段:开发——三个概念守住质量底线
开发阶段有三个概念,它们之间也有因果链:测试保证正确性 → 可复现性保证一致性 → 技术债务控制长期成本。跳过测试,可复现性无从谈起;不控制技术债,测试本身也会崩。
5. 测试:DFT 代码的测试比 Web 代码难 10 倍
Web 应用测试:输入 A,期望输出 B,断言通过。
DFT 代码测试:输入一个 Si 晶胞,跑 20 步自洽,期望总能量在 -5.43 ± 0.01 eV 附近——但这个值依赖截断能、K 点密度、赝势选择、收敛阈值……
单元测试用 pytest,跑得快,每次提交都跑。集成测试和回归测试用 CI 的 nightly build,每天跑一次。不要试图每次提交都跑全量回归——一个 VASP 测试套件跑完要 4 小时。
测试是后续一切的基础。没有测试,你无法确认代码是否正确;无法确认正确,可复现性就无从谈起。
6. 可复现性:6 个月后你自己也跑不出同样的结果
测试告诉你"现在对不对",可复现性告诉你"以后还能不能对"。
你的脚本在 Ubuntu 22.04 + Python 3.10 + numpy 1.24 上跑出了结果。换到 CentOS 7 + Python 3.6 + numpy 1.19——结果不一样,甚至不收敛。
这不是 numpy 的 bug。不同版本的 BLAS/LAPACK 实现在浮点运算的精度上有微小差异,经过几百次自洽迭代后,这些差异会放大到影响最终能量 0.01 eV 的量级。
锁定可复现环境的清单:
• 操作系统版本 • Python 版本 • 所有依赖的精确版本( pip freeze > requirements.txt)• BLAS/LAPACK 实现(OpenBLAS vs MKL) • 编译器版本(GCC vs Intel) • 并行参数(MPI 进程数、OpenMP 线程数)
VASP 官方文档专门有一节讲"Numerical Precision",就是因为这个。
可复现性是技术债务的照妖镜——如果你的环境都锁不住,技术债的积累速度会远超你的想象。
7. 技术债务:今天偷的懒,明天双倍还
技术债务(Technical Debt)在 DFT 软件中特别容易积累,因为——
"先跑起来再说"是每个物理人的口头禅。于是你硬编码了路径、跳过了输入校验、把 500 行逻辑塞进一个函数、没有写测试。代码能跑,结果也对,你发了论文。
然后师弟接手了。他花了 3 天才搞懂你的代码结构,又花了 2 天才发现那个硬编码路径。改一个参数,另外三个地方跟着崩。
DFT 软件最常见的 5 类技术债:
1. 硬编码:路径、参数、文件名写死在代码里 2. 魔法数字: if energy < 0.001里的 0.001 是什么?3. 无测试:改一行代码,不知道会不会影响收敛判断 4. 无文档:函数名是 calc1、calc2、calc_final_v25. 单文件架构:3000 行的 main.py
还债的利息是指数增长的。第 1 个月修一个 bug 要 10 分钟,第 6 个月修同一个类型的 bug 要 2 小时——因为代码已经乱到看不懂了。
技术债不控制,代码就不可维护。不可维护的代码,文档写得再好也没用——因为没人敢改。
第四阶段:交付——文档是代码的另一半
8. 文档:没有文档的代码等于没有写
pymatgen 为什么能成为材料信息学的事实标准?不是因为它的算法最先进,是因为它的文档最完整。
DFT 软件文档的四个层次:
1. API 文档:每个函数的参数、返回值、示例。用 Sphinx + autodoc 自动生成。 2. 教程:从零开始的 step-by-step 指南。"5 分钟完成你的第一个计算"比"详细 API 参考"重要 10 倍。 3. 理论背景:你的代码实现了什么物理?公式是什么?引用哪篇论文?用户不是来猜的。 4. 变更日志:每个版本改了什么、修了什么、不兼容什么。用 CHANGELOG.md 维护。
反面教材: 某开源 DFT 后处理工具,README 只有一行 "See source code for details"。GitHub 上 200 星,但 issue 区全是 "怎么安装" 和 "这个函数是干什么的"。
文档是审计的前提——没有文档,你连"应该是什么"都不知道,怎么审计"实际是什么"?
第五阶段:运维——出了问题怎么追溯
9. 审计:代码不是写完就完事
审计(Audit)在 DFT 软件中有两层含义:
数值审计: DFT 计算的结果对不对?你的代码实现的公式和论文里写的是不是一回事?一个符号错误,整个自洽场就不收敛。QE 的测试套件有 300+ 个回归测试用例,每个新提交都要跑一遍。VASP 的测试集覆盖了从简单原子到复杂界面的全场景。
代码审计: 谁改了什么、为什么改、有没有引入新 bug。Git 的 commit message 不是写给自己看的——三个月后你自己也看不懂。规范的格式:
fix: 修正电荷密度求和的符号错误在 rho.py 第 142 行,平面波展开的虚部符号应为负,导致 Si 的总能量偏差 0.3 eV。参考 Kresse 1996 Eq.(23)。没有审计的代码,就像没有 OUTCAR 的计算——你不知道它对不对。
审计能力决定了社区的信任度。一个连"上个月改了什么"都说不清楚的项目,没人敢贡献代码。
第六阶段:生存——软件的终极考验
10. 社区:一个人写的软件,一个人维护到放弃
VASP 有商业公司支撑。QE 有意大利 SISSA 团队。ABACUS 有北大团队 + 开源社区。这些项目能活 10 年以上,不是因为代码写得好,是因为有人持续维护。
开源社区建设的三个关键:
• 贡献门槛要低:CONTRIBUTING.md 写清楚怎么提 PR,代码规范是什么,测试怎么跑。新人第一次贡献的体验决定了他会不会来第二次。 • 响应要及时:issue 3 天内回复,PR 1 周内 review。沉默是社区最大的杀手。 • 决策要透明:功能路线图公开,重大变更提前讨论。不要搞"核心开发者闭门决定"。
反面案例: p4vasp,曾经最流行的 VASP 可视化工具,因为唯一维护者失联,Python 2 停更后无人接手,整个社区被迫迁移。一个依赖单人的项目,不是项目,是定时炸弹。
社区是前面 9 个概念的终极检验:ROI 决定了有没有人用,许可证决定了能不能用,依赖关系决定了好不好装,测试决定了敢不敢用,文档决定了会不会用,审计决定了信不信你。每一个环节的缺失,都会在社区层面被放大。
全景图
做 DFT 研究和做 DFT 软件,需要的技能重叠度大概只有 30%。物理直觉帮你写出正确的公式,但软件工程实践才能让你的代码活过下一篇论文。
