 夜雨聆风
夜雨聆风本文档基于 GeoAI 项目源码深度分析及行业最佳实践,系统阐述面向深度学习训练的**矢量标注(Vector Annotation)**规范。在整个 GeoAI 项目 的工作链条中,“标签(Label)”并不是一个简单的附属物,而是决定模型认知边界的核心数据。GeoAI 中的大量训练流程,本质上都是:
遥感影像(Raster) + 矢量标注(Vector Label) → 栅格标签(Mask) → 模型训练
因此,“矢量标注阶段”实际上就是传统 GIS 中的:遥感影像目标矢量化。但 GeoAI 里的“矢量化”与传统测绘制图中的“矢量化”又略有区别。
矢量标注 vs.矢量化
矢量化的广义定义
矢量化(Vectorization) 是 GIS 领域的通用术语,指将栅格数据(如扫描地图、遥感影像)转换为矢量数据(点、线、面)的过程。其目的多样:
• 地图数字化与制图 • 空间数据库建设 • 地物边界提取 • 地籍 • 测绘成果 • 空间分析
矢量标注的特定定义
在 GeoAI 项目中,矢量标注(Vector Annotation) 是矢量化在深度学习场景下的专业化子集。它强调:
| 目的 | ||
| 属性要求 | 必须包含类别字段class),属性尽量简单 | |
| 几何精度 | ||
| 拓扑要求 | ||
| 坐标系 | 必须与参考影像完全一致 | |
| 输出格式 |
矢量标注 = 面向 AI 训练的、带类别属性的、与影像严格对齐的矢量化成果。
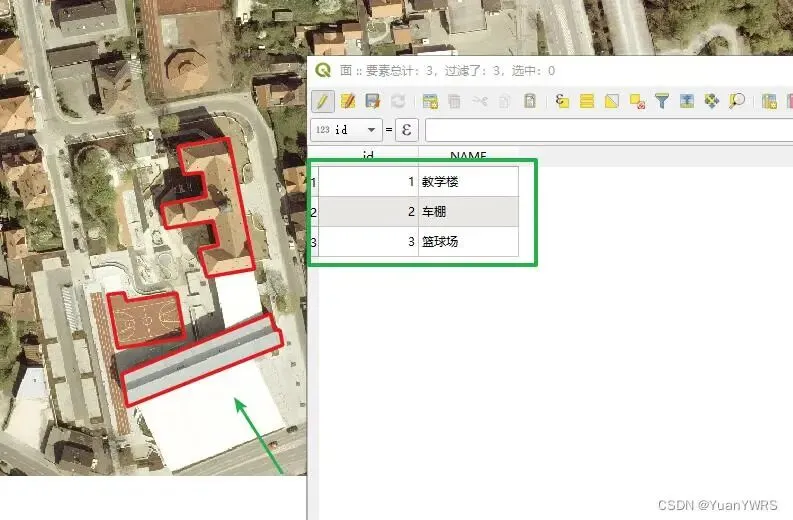
当你拿到一张高清影像图,在 GIS 软件中勾绘建筑、植被、水系的边界并赋予类别属性时,你正在进行的就是矢量标注。
SHP 图层结构设计
图层命名
建议:{区域标识}_{任务类型}_{版本号}_{日期},如beijing_building_2026.shp,nanjing_vegetation_2026.shp,不要随意其名称,因为后期数据量会指数爆炸。
字段设计
GeoAI 标签字段:越简单越好,训练阶段通常只需要:
| class | ||
推荐最小训练字段只id 和class字段,如果要进行语义增强,使用id、class、classname、source、remark。方便数据治理也符合STAC规范。
编码推荐:
0 | 保留值,矢量文件中不应出现 | |
1 | ||
2 | ||
3 | ||
4 | ||
5 |
内容两种组织方式对比
假设需要标注建筑、植被、水系三类地物,有两种数据组织策略:
策略 A:多个单种类 SHP(Single-class Multi-layer)
project_annotations/├── buildings.shp # 仅含建筑,class=1├── vegetation.shp # 仅含植被,class=2└── water.shp # 仅含水系,class=3策略 B:单一综合 SHP(Multi-class Single Layer)
project_annotations/└── landcover_annotations.shp # 含所有地物,class 字段区分类别深度对比分析
| GeoAI 源码支持度 | 原生支持export_geotiff_tiles_batch 直接读取单文件 | |
class_value_field | ||
| 空间一致性保证 | ||
| 类别冲突处理 | np.maximum | |
| 标注效率 | ||
| 数据管理 | ||
| COCO/YOLO 导出 | ||
| 实例分割支持 | instance_class_value_field 区分类别与实例 |
推荐方案
做语义分割,推荐综合shp,适用模型:UNet、DeepLab、SegFormer、SAM 微调
做目标检测,推荐单类别shp,适用模型:YOLO、MMDetection、Detectron2
GeoAI 源码证据
在 geoai/utils/training.py 中,核心切分函数 _process_image_mask_pair 对矢量数据的处理逻辑如下:
# Check if class_value_field existsif class_value_field in gdf.columns: unique_classes = gdf[class_value_field].unique()# Create class mapping: 自动将任意类别值映射为 1, 2, 3... class_to_id = {cls: i + 1for i, cls inenumerate(unique_classes)}else: class_to_id = {1: 1} # Default mapping关键结论:GeoAI 的栅格化引擎天然设计为处理单文件多类别输入。它会自动提取 class_value_field 中的唯一值,并将其映射为连续的整数类别 ID。若使用多个单种类 SHP,则需:
1. 分别读取每个文件; 2. 手动指定每个文件的类别 ID; 3. 栅格化后通过 np.maximum或波段叠加合并;4. 极易引入对齐误差和缝隙。
在 geoai/utils/training.py 的瓦片级栅格化代码中:
for idx, feature in window_features.iterrows(): class_val = feature[class_value_field] if class_value_field in feature else1 class_id = class_to_id.get(class_val, 1) feature_mask = features.rasterize( [(geom, class_id)], ... ) label_mask = np.maximum(label_mask, feature_mask) # 高值优先这进一步证明:单文件多类别是 GeoAI 的一等公民,多文件需额外适配。
类别映射表
每个矢量标注文件必须附带一个类别映射表(JSON 或 YAML),明确 class 值与语义之间的对应关系:
{"0":"background","1":"building","2":"vegetation","3":"water","4":"road","5":"bare_soil"}此映射表用于:
• 训练时配置 num_classes;• 推理结果可视化时赋予颜色与图例; • 多项目协作时统一语义理解。
几何与拓扑规范
几何类型选择
| Polygon(多边形) | ||
GeoAI 优先处理 Polygon。对于线状或点状地物,建议在标注阶段通过
buffer_radius扩展为面状,或在 GeoAI 导出时设置buffer_radius参数。
拓扑规则
| 无重叠(No Overlap) | ||
| 无缝隙(No Gaps) | ||
| 无自相交(No Self-intersection) | shapely.is_valid | |
| 无悬挂节点 |
重叠处理原则:
在 GeoAI 栅格化时,若多边形重叠,后绘制的多边形会覆盖先绘制的(np.maximum 取高值)。为避免不确定性,应在矢量阶段消除重叠:
• 建筑压盖植被 → 优先保留建筑,从植被中裁剪出建筑区域; • 道路穿越农田 → 道路与农田边界应完全重合。
边界精度要求
• 配准误差:矢量边界与影像地物边界的偏差应 ≤ 0.5 个像元; • 最小图斑:面积小于 4 × 4 像元的地物建议合并到相邻类别或不单独标注;• 简化容差:矢量简化(Simplify)的容差应 ≤ 0.5 个像元,避免过度平滑。
坐标系与投影规范
坐标系选择
| UTM 投影 | ||
与影像的对齐要求
矢量标注的 CRS 必须与参考影像完全一致GeoAI 在读取矢量时会自动检查并重投影:
if gdf.crs != src.crs: gdf = gdf.to_crs(src.crs)但自动重投影会引入微小变形,因此最佳实践是:
在标注阶段就将影像和矢量统一为同一投影坐标系。
数据格式问题
Shapefile 严格来说已经不是最佳选择。Shapefile 有大量历史问题:
• 字段名最长10字符 • 中文乱码问题 • 多文件依赖 • NULL 支持差
现在越来越推荐:
• GeoPackage • GeoJSON • FlatGeobuf
推荐目录结构
dataset/├── images/│ ├── tile_001.tif│ ├── tile_002.tif│├── labels/│ ├── landcover.geojson│├── masks/│ ├── tile_001_mask.tif│├── chips/│ ├── images/│ ├── masks/完整工作流程示例
从影像到训练标签的全流程
步骤 1: 准备高清影像 └── beijing_hd_2025.tif (EPSG:32650)步骤 2: 创建综合 SHP 并标注 └── 在 QGIS 中新建 "beijing_hd_landcover_v1.geojson" └── 添加字段: class (Integer), class_name (String) └── 勾绘所有地物,填写 class 值步骤 3: 拓扑检查与修复 └── QGIS → Vector → Geoprocessing Tools → Check Validity └── 修复重叠、缝隙、自相交步骤 4: 导出为 GeoJSON(推荐) └── beijing_hd_landcover_v1.geojson └── 配套: class_mapping.json步骤 5: 使用 GeoAI 生成训练数据 └── Python 代码见下方步骤 6: 验证标签质量 └── 可视化检查瓦片与掩膜的对齐情况GeoAI 训练数据导出代码
import geoai# 单文件多类别模式(推荐)stats = geoai.export_geotiff_tiles_batch( images_folder="data/images", masks_file="data/beijing_hd_landcover_v1.geojson", # 单一综合文件 output_folder="output/training_tiles", tile_size=256, stride=256, class_value_field="class", # 指定类别字段 skip_empty_tiles=True, # 跳过无标注瓦片 all_touched=True, # 接触即标记 buffer_radius=0, # 无缓冲)print(f"生成瓦片: {stats['total_tiles']}")print(f"含标注瓦片: {stats['tiles_with_features']}")类别映射表示例
# class_mapping.json{"project": "beijing_hd_landcover","version": "v1","num_classes": 6,"classes": {"0": {"name": "background", "color": [0, 0, 0]},"1": {"name": "building", "color": [255, 0, 0]},"2": {"name": "vegetation", "color": [0, 255, 0]},"3": {"name": "water", "color": [0, 0, 255]},"4": {"name": "road", "color": [255, 255, 0]},"5": {"name": "bare_soil", "color": [139, 69, 19]} }}常见问题与解决方案
tile_size 或增大 buffer_radius | ||
stride = tile_size / 2 产生重叠 | ||
class | class=0 仅用于背景,矢量中不出现 | |
class | class 字段是否填充完整 |
| 数据组织 | |
| 文件名 | {区域}_{任务}_v{版本}_{日期}.geojson |
| 核心字段 | class |
| 辅助字段 | class_namesource, confidence, date |
| 类别编码 | 1=建筑, 2=植被, 3=水体... |
| 背景处理 | 0 |
| 拓扑规则 | |
| 坐标系 | |
| 配套文件 | class_mapping.json |
核心原则:矢量标注是 GeoAI 训练数据流水线的起点,其质量直接决定模型性能。采用单一综合 SHP、规范字段命名、严格拓扑检查,是高效、准确制作训练标签的根本保障。
