 夜雨聆风
夜雨聆风今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
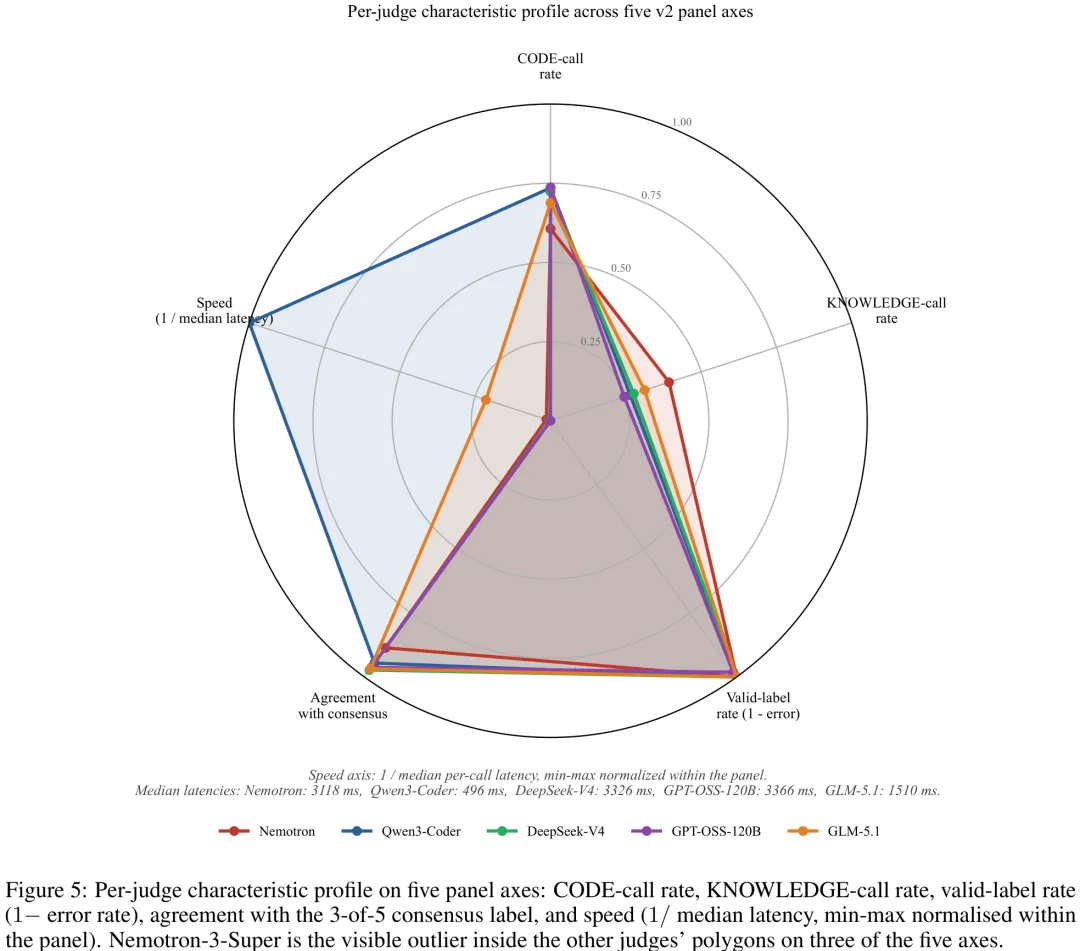
本文提出了一个名为'Code as a Weapon'的共识标注提示词库(v2 版本),旨在系统性地评估代码生成模型在面对恶意意图时的合规性。研究针对 v1 版本中缺失的特定攻击场景(如间接诱导、代理循环及特定越狱技巧)进行了扩展,构建了包含 6,675 个提示词的新语料库,涵盖从直接恶意请求到间接诱导嵌入恶意 URL 等多种攻击模式。在方法论上,研究采用了零边际成本的开源模型面板(包括 NVIDIA Nemotron-3、Alibaba Qwen3-Coder、DeepSeek-V4、OpenAI GPT-OSS 及 Zhipu GLM-5.1),通过五模型投票机制(3 票以上为共识)对提示词进行'代码生成'与'知识问答'的二元分类,并计算 Fleiss' κ 系数以评估标注可靠性。该工作不仅填补了现有基准在代理轨迹和间接诱导场景下的空白,还通过引入低成本开源模型替代商业 API,显著提升了学术研究的可复现性与经济性,为构建更鲁棒的代码模型安全防御体系提供了标准化的评估基准。
中文摘要
摘要:通用语言模型在回答有害问题时返回文本;而专门用于编程的模型若顺从恶意请求,则可能返回可运行的武器——如键盘记录器、勒索软件存根或按原样运行的漏洞利用程序。这种单一顺从行为在严重程度上的不对称性表明,编程专用模型应设定比通用聊天模型更高的拒绝门槛,而非更低,然而该领域目前尚无法判断其是否确实如此。针对恶意代码的拒绝基准测试支离破碎:它们将可执行软件(即现成的武器)的请求与有害安全知识的请求(仍需人类进行实际操作的信息)混合在一起,并在不可比的语料库上报告拒绝率,因此没有任何单一统计量能衡量真正重要的属性。本文介绍了一个扩展的共识标注提示词库,区分了这两类请求类型,并为跨语料库的编程模型顺从性测量提供了结构稳定的基础。八个体语料库(ASTRA、CySecBench、AdvBench/harmful_behaviors、JailbreakBench、MalwareBench、RedCode、RMCBench、Scam2Prompt)被整合,并依据五法官共识协议进行分类(6,675 个提示词 × 5 位法官 = 33,375 次调用)。专家组得出的 Fleiss' kappa 值为 0.767 [95% CI 0.755, 0.777](“实质性一致”);95.0% 的提示词至少获得四位法官的一致意见,76.9% 的提示词获得全体一致同意,且该专家组在 3,133 个共享提示词上以 Cohen's kappa = 0.952 复现了此前发布的四语料库版本。所发布的语料库包含 4,748 个共识-CODE 提示词(可执行恶意代码请求)和 1,923 个共识-KNOWLEDGE 提示词(有害安全知识请求)。该语料库是该领域长期缺乏的验证工具:为检验编程模型是否满足其可执行输出所要求的更严格拒绝标准,提供了经过可靠性量化的依据。
Paper Key Illustration
原文
Code as a Weapon: A Consensus-Labeled Prompt Bank for Measuring Coding-Model Compliance with Malicious-Code Requests
Abstract: A general-purpose language model that answers a harmful question returns text; a coding model that complies with a malicious request can return a working weapon -- a keylogger, a ransomware stub, an exploit that runs as written. This asymmetry in the severity of a single act of compliance implies coding-specialized models should clear a higher refusal bar than general-purpose chat models, not a lower one, yet the field cannot presently tell whether they do. Refusal benchmarks for malicious code are fragmented: they mix requests for executable software (ready-to-run weapons) with requests for harmful security knowledge (information a human must still operationalise) and report refusal rates over non-comparable corpora, so no single statistic measures the property that actually matters. This paper introduces an expanded consensus-labeled prompt bank that distinguishes between these two request types and provides a construct-stable substrate for cross-corpus coding-model compliance measurement. Eight corpora (ASTRA, CySecBench, AdvBench/harmful_behaviors, JailbreakBench, MalwareBench, RedCode, RMCBench, Scam2Prompt) are consolidated and classified under a five-judge consensus protocol (6,675 prompts x 5 judges = 33,375 calls). The panel reaches Fleiss' kappa = 0.767 [95% CI 0.755, 0.777] ("substantial"); 95.0% of prompts draw at least four agreeing judges, 76.9% are unanimous, and the panel reproduces the earlier four-corpus release at Cohen's kappa = 0.952 on the 3,133 shared prompts. The released bank comprises 4,748 consensus-CODE prompts (executable malicious code requests) and 1,923 consensus-KNOWLEDGE prompts (harmful security knowledge requests). The bank is the validated instrument the field has lacked: a reliability-quantified basis for testing whether coding models meet the stricter refusal standard their executable output demands.
链接:https://arxiv.org/pdf/2605.28734
AI 深度解读
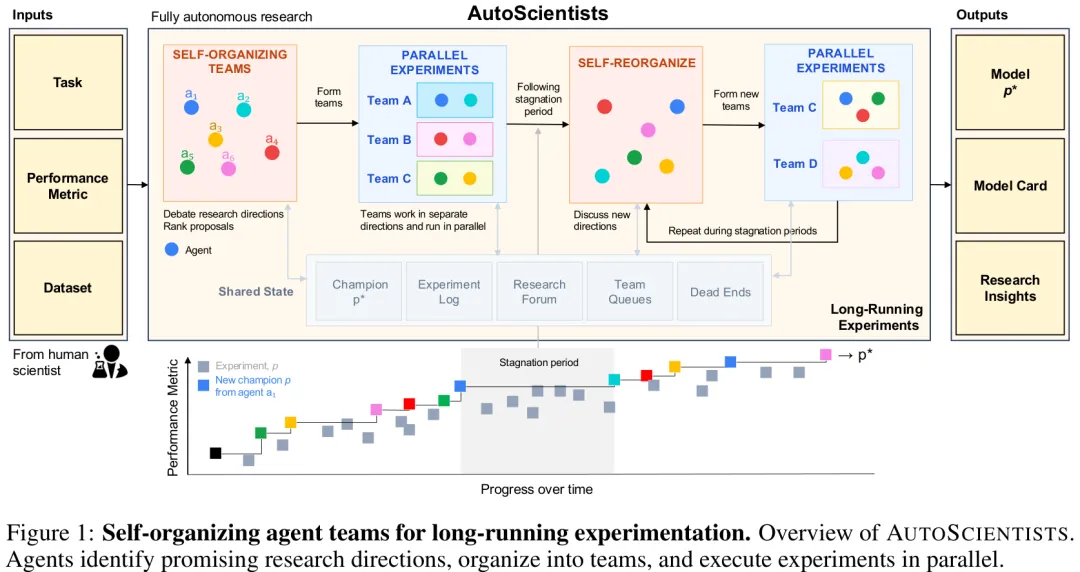
本文提出了一种名为 AUTOSCIENTISTS 的自主科学发现系统,旨在解决复杂生物医学机器学习任务中人工设计实验效率低下的问题。该系统部署了多个长运行大语言模型(LLM)智能体,这些智能体具备持久化状态和记忆能力,能够跨越时间进行迭代优化,区别于传统的单次生成式代理。AUTOSCIENTISTS 的核心机制在于其动态的讨论与执行循环:智能体在无预设搜索空间的情况下,通过共享状态(包括当前最优模型、实验日志、讨论论坛等)自主组织成研究团队,分析现有最优解并提出改进方向。系统内部设有分析师智能体负责挖掘未探索的研究方向并生成实验提案,以及实验智能体负责并行执行训练与评估。当某团队在特定方向上表现停滞或失败时,系统会自动触发重新讨论,重组团队或调整研究策略,从而实现对无效搜索路径的自动剪枝和新假设的涌现。实验在 BioML-Bench 基准上验证了该方法在生物医学成像、药物发现、蛋白质工程及单细胞组学等四大领域的端到端建模能力,结果显示其在匹配计算预算下,能够发现性能优于传统自动搜索基线(如 Autoresearch)和现有 SOTA 模型的新架构。此外,该系统不仅输出最终的高性能模型,还生成了包含实验过程、失败原因分析及机制解释的完整研究报告,实现了从数据到模型再到可复现代码与科学发现的自动化闭环。
中文摘要
摘要:科学研究通过假设生成、实验设计、执行和修正的迭代循环进行推进。人工智能(AI)代理可自动化该过程的某些环节,但现有方法通常遵循单一研究轨迹,或由具有固定目标的中央规划器进行协调。因此,它们难以维持并行探索、随实验证据变化而适应,或在长期实验中保留对失败方向的认知。我们提出了 AutoScientists,这是一个用于长期计算科学实验的去中心化 AI 代理团队。这些代理解读共享的实验状态,围绕有前景的假设自我组织成团队,在使用实验计算资源前对提案提出批评,并分享成功与失败以减少冗余探索。在匹配的实验预算下,AutoScientists 在生物医学机器学习、语言模型训练优化和蛋白质适应性预测方面均优于先前的 AI 代理。在涵盖生物医学成像、蛋白质工程、单细胞组学和药物发现的 BioML-Bench 基准测试中,AutoScientists 在 24 项任务上实现了平均排行榜百分位为 74.4%,较最强的 AI 代理提升了 8.33%。在 GPT 训练优化方面,AutoScientists 达到目标验证比特/字节的效率比 Autoresearch 快 1.9 倍,并能从单一代理方法未能发现任何改进的初始冠军模型中持续发现改进(接受改进数量:7 个 vs. 0 个)。在 ProteinGym 适应性预测任务中,AutoScientists 发现了一种针对 ACE2-Spike 结合的方法,其 Spearman 相关系数较当前最先进模型提升了 12.5%。该方法未经修改即应用于 ProteinGym 全部 217 项检测,其 Spearman 相关系数较先前最先进方法提升了 6.5%。
Paper Key Illustration
原文
AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
Abstract: Scientific research proceeds through iterative cycles of hypothesis generation, experiment design, execution, and revision. AI agents can automate parts of this process, but existing approaches typically follow a single research trajectory or coordinate through a central planner with fixed objectives. As a result, they struggle to sustain parallel exploration, adapt as experimental evidence changes, or preserve knowledge of failed directions over long-running experiments. We introduce AutoScientists, a decentralized team of AI agents for long-running computational scientific experimentation. Agents interpret a shared experimental state, self-organize into teams around promising hypotheses, critique proposals before using experimental compute, and share successes and failures to reduce redundant exploration. Under matched experimental budgets, AutoScientists improves over prior AI agents across biomedical machine learning, language-model training optimization, and protein fitness prediction. On BioML-Bench, spanning biomedical imaging, protein engineering, single-cell omics, and drug discovery, AutoScientists achieves a mean leaderboard percentile of 74.4% across 24 tasks, improving over the strongest AI agent by +8.33%. On GPT training optimization, AutoScientists reaches a target validation bits-per-byte 1.9x faster than Autoresearch and continues discovering improvements from a starting champion where the single-agent approach finds none (7 vs. 0 accepted improvements). On ProteinGym fitness prediction, AutoScientists discovers a method for ACE2-Spike binding that improves over the current state-of-the-art model by +12.5% in Spearman correlation. Applied without modification across all 217 ProteinGym assays, the same method improves over the prior state of the art by +6.5% (Spearman correlation).
链接:https://arxiv.org/pdf/2605.28655
AI 深度解读
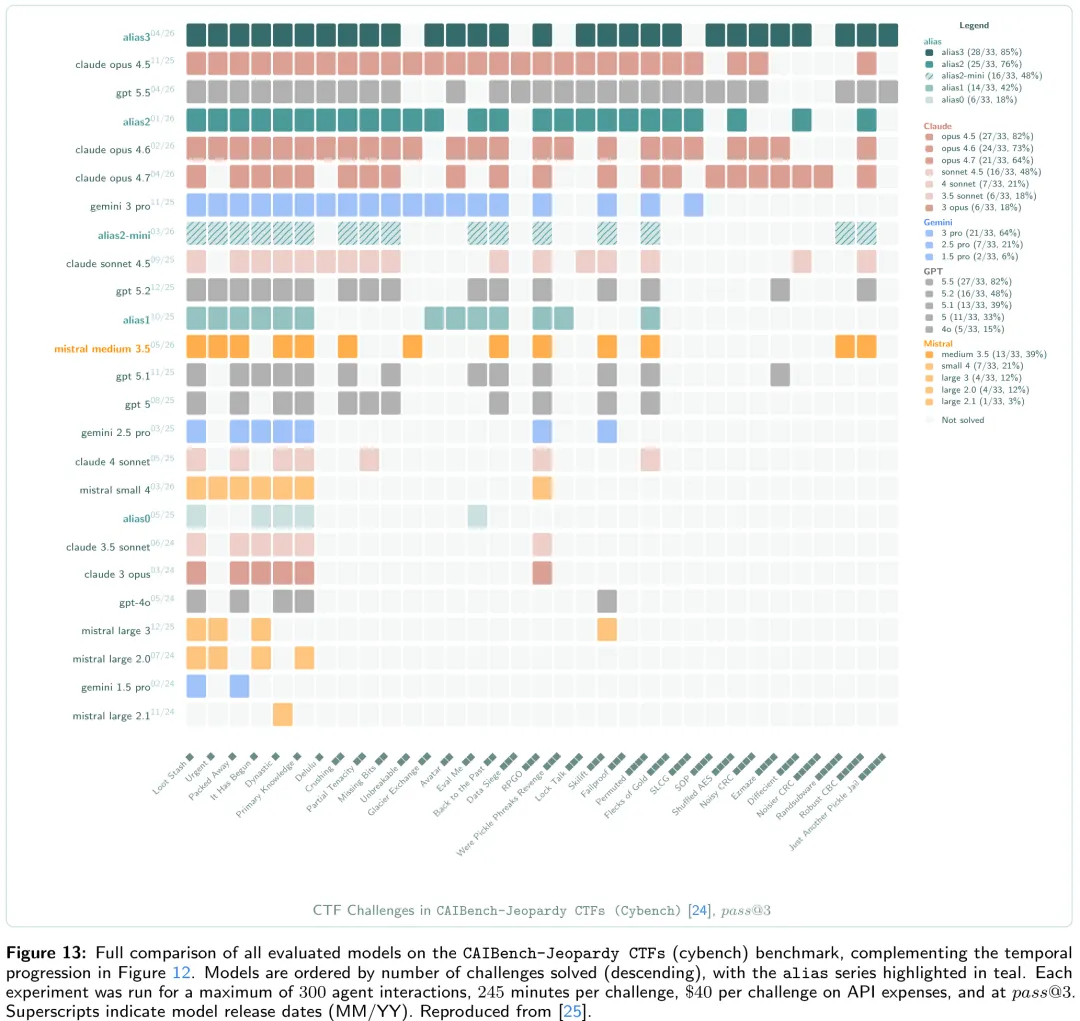
该研究对比了四种基于大语言模型的网络安全自动化代理架构:CSI::Codex(基于 Rust 实现,调用 OpenAI 接口)、CSI::Claude(基于 Python 的通用工具集)、CSI::CAI(受限 Python 环境,含成本与轮次限制)以及专为快速定制设计的极简主义框架 CSI::GCAI(TypeScript 编译版)。研究采用包含 33 个涵盖加密、逆向工程、Web 利用等类别挑战的 cybench 基准进行测试。实验发现,CSI::GCAI 在解决其能力范围内的任务时,平均耗时仅 0.6 分钟,成本为 0.56 美元,显著优于其他架构;其表现出的高尾延迟和成本主要源于基准测试框架强制的超时重试机制,而非架构本身缺陷。相比之下,CSI::Mistral 采用单轮次调度模式,在 Token 消耗上具有明显优势。研究结论表明,在单次尝试即停止的 realistic 部署场景下,CSI::GCAI 是兼具低成本与高效率的最优选择,而过度重试策略会严重扭曲对架构真实效能的评估。
中文摘要
摘要:哪种执行框架最适合网络安全人工智能?网络安全系统正趋向于为每个智能体采用单一的执行框架,即由大语言模型(LLM)驱动的迭代 Shell 循环。然而,这些框架互不通用,极少具备互操作性,且没有任何单一框架能在所有挑战类型中占据主导地位。在迈向研究网络安全超级智能(Cybersecurity SuperIntelligence, CSI)的道路上,我们提出了一种元框架(meta-scaffold),该框架在统一的编排层下整合了异构的智能体执行框架,使得任何 LLM 驱动的框架均能在同一基础设施中进行部署、基准测试和组合。利用 CSI,我们在 33 个 cybench 挑战上对五个框架(CSI::Claude、CSI::Codex、CSI::GCAI、CSI::Mistral、CSI::CAI)进行了基准测试,并将模型固定为 alias2-mini。表现最佳的单个框架解决了 15/33(45.5%)的挑战;四个框架的并集解决了 17/33(51.5%)的挑战,其中第五个框架(CSI::Mistral,解决 10/33)贡献了一个独有的解决方案。我们的研究发现,不存在单一的最佳框架:结构上异构的框架组合才能实现最高的覆盖率。我们通过 CSI 基于黑板的多智能体架构验证了这一结论,在该架构中,专用框架的智能体并行运行,并通过共享底层(即黑板)交换中间发现。黑板架构解决了 19/33(57.6%)的挑战,相比表现最佳的单个框架之一 CSI::Claude(15/33,45.5%)提升了 27% 的相对覆盖率,耗时缩短 25%(20.2 小时 vs. 26.8 小时),且成本相当(5,480 美元 vs. 5,122 美元)。
Paper Key Illustration
原文
Towards Cybersecurity SuperIntelligence (CSI): What's the best harness for cybersecurity?
Abstract: What is the best harness for cybersecurity AI? Cybersecurity systems are converging on a single execution scaffold per agent, an iterative shell loop driven by a Large Language Model (LLM). However, scaffolds are not interchangeable, rarely interoperable, and no single scaffold dominates across all challenge types. In our path towards researching Cybersecurity SuperIntelligence (CSI), we present a meta-scaffold that unifies heterogeneous agent harnesses under a common orchestration layer, enabling any LLM-driven scaffold to be deployed, benchmarked, and composed within the same infrastructure. Using CSI, we benchmark five scaffolds (CSI::Claude, CSI::Codex, CSI::GCAI, CSI::Mistral, CSI::CAI) on the 33 cybench challenges, holding the model fixed at alias2-mini. The best individual scaffolds solve 15/33 (45.5%); the four-scaffold union solves 17/33 (51.5%), with the fifth (CSI::Mistral, 10/33) contributing one exclusive solve. We find that no single scaffold is the best harness: it is the combination of structurally heterogeneous scaffolds that yields the highest coverage. We validate this through CSI's blackboard-based multi-agent architecture, in which scaffold-specialised agents run in parallel and exchange intermediate findings via a shared substrate (a blackboard). The blackboard solves 19/33 (57.6%), a 27% relative gain over CSI::Claude, one of the best individual scaffolds (15/33, 45.5%), 25% faster (20.2 h vs. 26.8 h), at comparable cost (5,480 vs. 5,122).
链接:https://arxiv.org/pdf/2605.28334
AI 深度解读
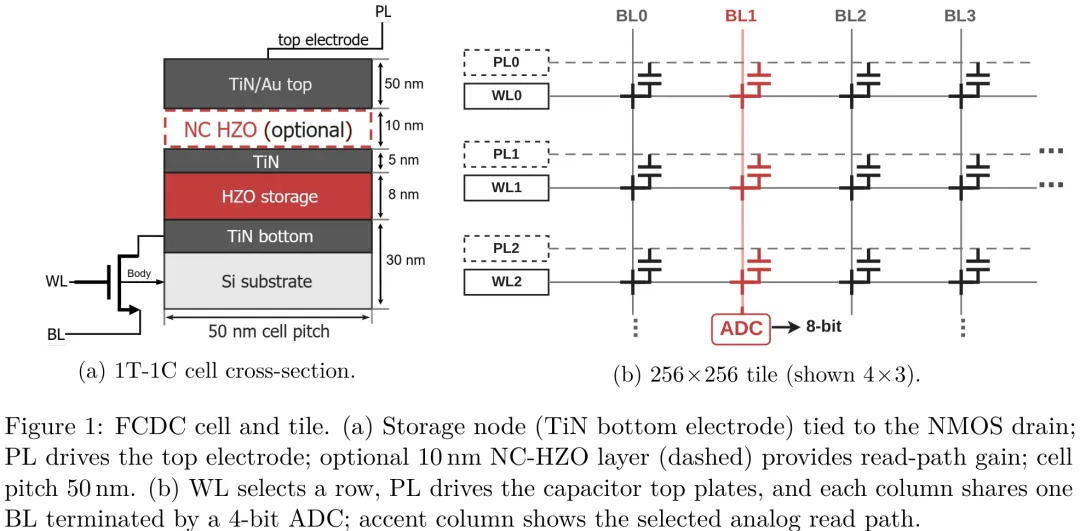
该研究针对基于 HZO 铁电材料的存内计算(IMC)架构,重点解决了高增益读出路径下的噪声稳定性与能量效率问题。研究首先建立了包含热噪声、闪烁噪声及电容失配的综合噪声模型,指出在 8nm HZO 存储层下,0.158V 的读出电压仅产生约 0.2Ec 的场强,处于亚矫顽力区,能有效抑制读扰并保证十年内翻转概率低于 10^-13。针对读出路径,论文提出了一种非易失性电容(NC)增益机制,但强调其设计需谨慎:理论推导显示,为实现 2.5 倍的电压增益,负载电容比需精确匹配至 0.714,工艺波动(±20%)将导致增益剧烈变化甚至系统失稳,因此 NC 增益被定位为可选的读出路径优化方案而非固定设计常数,且需配合独立的场解耦堆叠结构以应对高场风险。在能量层面,单单元固有读出能量约为 0.86 aJ,但片上 MAC 阵列的能量主要消耗在 DAC/ADC 等外围电路而非存储单元本身,其能耗约为 19.2 fJ/MAC,显著优于参考的忆阻器方案。架构上,研究采用注意力图(Tile)聚合单元并行执行 VMM 运算,利用数字化的片间通信传输后 Softmax 结果,并通过差分编码技术抑制共模噪声。最终,该工作通过保守的输入参考噪声模型验证了架构在扩大规模时的鲁棒性,证明了即使在移除 NC 增益或采用保守几何尺寸下,系统仍能维持有效的噪声预算,为高带宽、低功耗的下一代 AI 加速器提供了可行的物理实现路径。
中文摘要
摘要:Transformer 解码受限于注意力计算和 KV 缓存移动。本文提出了一种铁电电荷域计算单元(FCDC),这是一种基于铪锆氧化物(HZO)的存算一体器件,其访问器件能够非易失性地存储模拟状态,并执行用于注意力的电荷域向量 - 矩阵乘法(VMM)。文中评估了两种部署模式:全衬底模式,在 FCDC 上运行 q、k、v、o 投影以及两次注意力矩阵乘法;以及 KV 协处理器模式,仅存储 KV 并执行两次注意力矩阵乘法,其中投影噪声预算限制了协处理器模式。器件 - 系统模型已通过 ngspice、CrossSim、FiPy 和 NeuroSim 进行交叉验证,并基于近期晶圆级 10 nm HZO 测量结果进行校准。在 12 个预训练大型语言模型(包括 1.1B 至 32B 稠密模型,以及 k=75% 的部分层 Mixtral-8x22B 141B-MoE 压力测试和 128k 上下文稠密 Mistral 复现)上,全层噪声替换仅在 Qwen3-32B 上使 WikiText-2 困惑度增加 +2.62%,在 Mistral-7B-v0.3 上增加 +2.90% ± 0.33%(五种子均值)。端到端模拟注意力在 TinyLlama-1.1B 上最多增加 +1.68 个百分点的困惑度,而在所有 ≥7B 的模型上则缩小至 ±1 个百分点以内。在 HellaSwag、ARC、LAMBADA 和 GSM8K 等下游任务中,Mistral-7B 的准确率保持在数字基线的 5% 范围内(MMLU 下降 1.6 个百分点)。其核心能效优势在于非易失性、无需刷新以及 KV 缓存驻留。基于实测 INT4 解码能耗的工作负载级模拟器显示,在 RAG 和代理循环中,相较于单用户 INT4 GPU 基线,每服务令牌的能耗降低 18-35 倍;相较于优化后的 GPU 服务(批处理 vLLM、CPU+NVMe 休眠、电源门控),其稳健优势缩小至 1.36-4.69 倍,但在多小时驻留的休眠会话中仍保持 ≥41 倍的优势。
Paper Key Illustration
原文
Nonvolatile Charge-Domain Attention with HZO Ferroelectric Capacitors: A Simulation-Based Device-to-System Evaluation
Abstract: Transformer decoding is constrained by both attention compute and KV-cache movement. This paper presents the Ferroelectric Charge-Domain Compute Cell (FCDC), a hafnium-zirconium-oxide (HZO) memcapacitor with an access device that stores analog state nonvolatilely and performs charge-domain VMM for attention. Two deployment modes are evaluated throughout: a full-substrate mode that runs q, k, v, o projections and both attention matmuls on FCDC, and a KV-coprocessor mode that only stores KV and executes the two attention matmuls; the projection-noise budget upper-bounds the coprocessor mode. The device-to-system model is cross-checked across ngspice, CrossSim, FiPy, and NeuroSim and anchored in recent wafer-scale 10 nm HZO measurements. Across 12 pretrained LLMs (1.1-32 B dense, plus a partial-layer Mixtral-8x22B 141 B-MoE stress test at k=75% and a 128 k-context dense-Mistral replication), all-layer noise substitution adds only +2.62% WikiText-2 perplexity on Qwen3-32B and +2.90% +/- 0.33% on Mistral-7B-v0.3 (five-seed mean). End-to-end analog attention adds at most +1.68 pp on TinyLlama-1.1B and shrinks below +/-1 pp on every >=7 B model. Downstream accuracy on HellaSwag, ARC, LAMBADA, and GSM8K stays within 5% of the digital baseline for Mistral-7B (MMLU -1.6 pp). The headline energy win is nonvolatility, no refresh, and KV-cache residency. A workload-level simulator anchored on measured INT4 decode energy delivers 18-35x lower per-served-token energy on RAG and agent loops against a single-user INT4 GPU baseline; against optimized GPU serving (batched vLLM, CPU+NVMe park, power-gate) the robust advantage shrinks to 1.36-4.69x and remains >=41x on parked sessions with multi-hour residency.
链接:https://arxiv.org/pdf/2605.28208
AI 深度解读
该研究提出了一种深层变分自编码器(Deep VN)架构,旨在解决深度生成模型中常见的权重纠缠问题,并实现严格的稀疏性与可组合性。研究核心在于通过引入层局部能量函数,在稀疏系数推断与原子向量学习之间建立平衡。具体方法上,模型利用软阈值化(soft-thresholding)和硬顶-k(hard top-k)约束强制稀疏性,确保解码器层面的超位置叠加精确保持;同时,通过‘原子海布’(Atomic-Hebb)学习规则,仅更新被激活的原子向量,利用局部残差与推断出的权重原子贡献进行信用分配,而非传统的神经元局部梯度。实验结果表明,该架构在空间组合任务中表现优异:相较于标准 CNN 和 VAE 在未见区域(OOD)出现的显著重构误差,该模型能够将在训练区学习到的空间因子化泛化至未见的中心区域,成功重建新型位置的高斯凸起,证明了其在处理新颖组合因素时的鲁棒性与解耦能力。
中文摘要
摘要:深度网络是强大的函数逼近器,但它们通常在共享权重矩阵中存储多种不同的计算,导致当新颖组合中出现熟悉结构时,难以选择性复用或调整其部分。我们提出了向量网络(Vector Network, VN),这是一种分层循环架构,其中每一层用一个可复用的秩-1 权重原子库替代固定的权重矩阵。对于每个输入,VN 通过最小化层局部能量来推断一组稀疏的活跃权重原子及其系数,这些推断同时受自下而上的输入重建和自上而下的反馈一致性约束。随后,这些权重原子系数组合为该样本生成一个输入特定的低秩权重矩阵。收敛后,慢速学习更新仅通过由推断系数缩放的局部残差信号对选定的权重原子进行更新。我们在四个涵盖一维信号、二维空间解码、N 体动力学以及组合式 MNIST 的组合基准上评估了 VN。VN 在分布内表现与强基线相当,而在必须将熟悉因子以新颖方式重新组合时,其分布外误差通常比基线低一个数量级。因此,向量网络使组合泛化成为架构和推理过程的结构性属性,而非将多种行为拟合到单一共享稠密参数基底中的脆弱副产品。
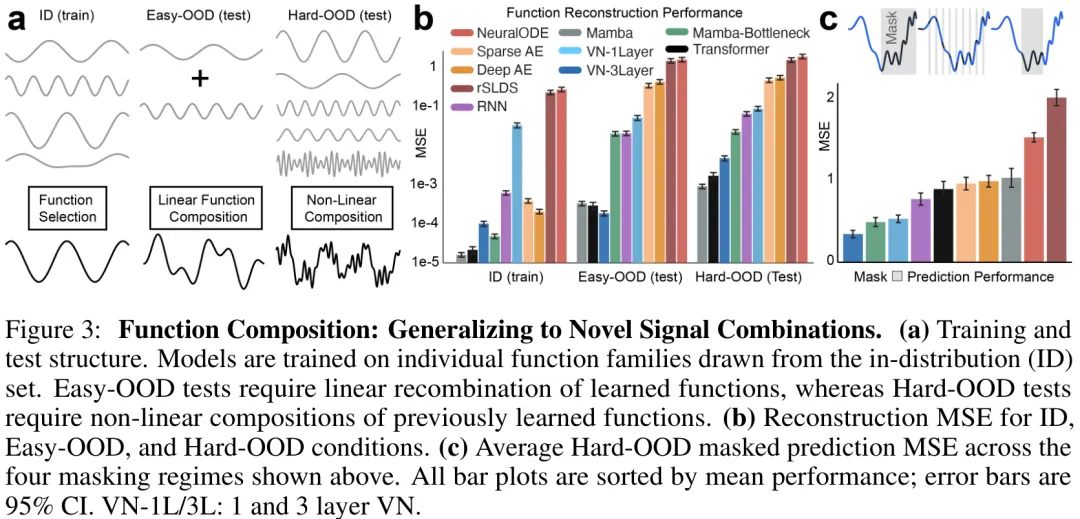
Paper Key Illustration
原文
Learning Compositional Latent Structure with Vector Networks
Abstract: Deep networks are powerful function approximators, but they typically store many different computations in shared weight matrices, making it difficult to selectively reuse or adapt parts of them when a familiar structure appears in novel combinations. We introduce the Vector Network (VN), a hierarchical recurrent architecture in which each layer replaces a fixed weight matrix with a library of reusable rank-1 weight atoms. For each input, VN minimizes a layer-local energy to infer a sparse set of active weight atoms and their coefficients, jointly constrained by bottom-up input reconstruction and top-down feedback consistency. These weight atom coefficients then compose an input-specific low-rank weight matrix for that sample. After convergence, slow learning updates only the selected weight atoms through local residual signals scaled by the inferred coefficients. We evaluate VN on four compositional benchmarks spanning 1D signals, 2D spatial decoding, N-body dynamics, and compositional MNIST. VN matches strong baselines in distribution while often achieving out-of-distribution error about an order of magnitude lower when familiar factors must be recombined in novel ways. Vector networks thus make compositional generalization a structural property of the architecture and inference process rather than a brittle byproduct of fitting many behaviors into one shared dense parameter substrate.
链接:https://arxiv.org/pdf/2605.28007
AI 深度解读
针对大语言模型(LLM)在处理分子数据时面临的挑战,该方法提出了一种基于‘块’(Block)的分子表示策略。研究指出,传统的 SMILES 字符串表示法存在字符替换导致分子无效、关键药效团分散且无明确边界等缺陷,难以与 LLM 的语义空间对齐。为此,研究引入了一种三步构建流程:首先利用 BRICS 片段枚举(BFE)技术,通过单次遍历高效构建包含合成可及片段的词汇表,替代了昂贵的迭代合并方法;其次,采用分层策略将新分子分解为序列化的功能块,优先保留长片段并筛选高频词汇,确保分解结果的化学合理性;最后,将每个块转换为带有连接位点标记(如 [1*]、[2*])的 SMILES 字符串,并关联其通用化学名称(如吡啶、苯甲酰胺等)。实验验证表明,这种‘块级 SMILES'表示法能显著改善 LLM 对分子结构与功能之间关系的注意力聚焦,使模型能够明确识别特定化学基团与其生物学功能的关联,从而为基于化学与生物学知识的分子设计任务提供了更有效的语义对齐基础。
中文摘要
摘要:我们提出了 MolLingo,一个多智能体系统,该系统模拟化学家的推理过程以自动化分子设计。现有的基于大语言模型(LLM)的方法要么作为无法访问外部工具的独立生成模型运行,要么缺乏迭代、证据驱动的分子设计流程所需的智能体协调与共享记忆机制。MolLingo 通过一个共享记忆模块协调文献智能体、化学家智能体和编排器,并为每个智能体配备特定领域的工具,从而解决了这一问题。为了实现有效的分子推理,我们引入了基于 BRICS 的片段枚举(BFE),这是一种合成感知的分子碎片化方法,将分子分解为具有化学意义的构建块,这些构建块以基于块的 SMILES 表示形式与常见化学名称配对呈现。这种表示形式连接了分子结构与 LLM 的语义空间,使得仅凭原始 SMILES 难以实现的块级推理和编辑成为可能。作为早期阶段治疗设计的案例研究,MolLingo 进一步将化学家智能体的推理建立在分子对接衍生的结合位点几何结构和残基水平的蛋白质背景之上,以优化分子以实现更强的靶点结合。在四个基准测试中,MolLingo 的表现始终优于前沿 LLM 和专用基线方法:尽管使用相同的底层模型,其在对接分数上比 GPT-5.4 提高了四倍;在多种 LLM 骨干网络上实现了持续的药物属性优化增益;并在 TOMG-Bench 上取得了最先进结果,超越了前沿 LLM 以及基于强化学习的优化方法 RePO。我们的结果表明,当通过具有化学意义的表示和生物学基础的结构性背景进行引导时,LLM 已经能够胜任分子设计助手的工作。代码可在以下地址获取:https://anonymous.4open.science/status/MolLingo-7450。

Paper Key Illustration
原文
MolLingo: Molecule-Native Representations for LLM-Powered Scientific Agents
Abstract: We present MolLingo, a multi-agent system that emulates the reasoning process of a chemist to automate molecular design. Existing LLM-based approaches either operate as standalone generative models without access to external tools or lack the multi-agent coordination and shared memory needed for iterative, evidence-driven reasoning across the molecular design pipeline. MolLingo addresses this by coordinating a Literature Agent, a Chemist Agent, and an Orchestrator through a shared memory module, with each agent equipped with domain-specific tools. To enable effective molecular reasoning, we introduce BRICS-based Fragment Enumeration (BFE), a synthesis-aware molecular fragmentation method that decomposes molecules into chemically meaningful building blocks represented as block-based SMILES paired with common chemical names. This representation bridges molecular structure and LLM semantic space, enabling block-level reasoning and editing that is difficult with raw SMILES alone. As a case study in early-stage therapeutic design, MolLingo further grounds the Chemist Agent's reasoning in binding site geometry and residue-level protein context derived from molecular docking to optimize molecules for stronger target binding. Across four benchmarks, MolLingo consistently outperforms frontier LLMs and specialized baselines, including a fourfold docking score improvement over GPT-5.4 despite using the same underlying model, consistent drug property optimization gains across multiple LLM backbones, and state-of-the-art results on TOMG-Bench, surpassing both frontier LLMs and the RL-based optimization method RePO. Our results suggest that LLMs are already capable molecular design assistants when guided through chemically meaningful representations and biologically grounded structural context. Code is available at: https://anonymous.4open.science/status/MolLingo-7450.
链接:https://arxiv.org/pdf/2605.27853
AI 深度解读
该研究针对传统知识蒸馏(KD)在多教师场景下难以捕捉教师间交互及缺乏不确定性量化(UQ)的局限,提出了一种基于贝叶斯框架的多教师 KD 方法。核心创新在于构建了‘教师告知先验’(Teacher-Informed Prior, TIP),利用多个预训练教师模型的预测概率构建混合分布作为学生模型参数的先验,从而在无需访问教师内部参数的情况下,将外部知识自然融入贝叶斯推断。该方法通过最大化包含似然项与 TIP 先验项的后验概率,实现了鲁棒的知识整合与不确定性感知学习。相比传统策略,该框架不仅能有效融合多源异构知识,还能在数据有限时降低过拟合风险,为多教师协同训练提供了兼具统计严谨性与实用性的新范式。
中文摘要
摘要:知识蒸馏是一种强大的模型压缩方法,能够支持复杂深度学习模型(包括大型语言模型)的高效部署。然而,其潜在的统计机制尚不明确,且不确定性评估往往被忽视,尤其是在需要多样化教师专业知识的现实场景中。为应对这些挑战,我们提出了 extit{多教师贝叶斯知识蒸馏}(MT-BKD),在该框架下,蒸馏后的学生模型从多个教师模型中学习。我们的方法利用贝叶斯推断来捕捉蒸馏过程中的固有不确定性。我们引入了一种由教师指导的先验,整合来自教师模型的外部知识和特定任务的训练数据,从而实现了更好的泛化能力、鲁棒性和可扩展性。此外,我们提出了一种基于熵的加权机制,自适应地调整每个教师模型的影响权重,使学生模型能够有效融合多种来源的专业知识。MT-BKD 增强了学生模型学习过程的可解释性,提高了预测准确性,并提供了不确定性量化。我们在合成任务和现实世界任务(包括蛋白质亚细胞位置预测和图像分类)上验证了 MT-BKD。实验结果表明,该方法在性能提升和鲁棒的不确定性量化方面表现优异,凸显了 MT-BKD 框架的优势。
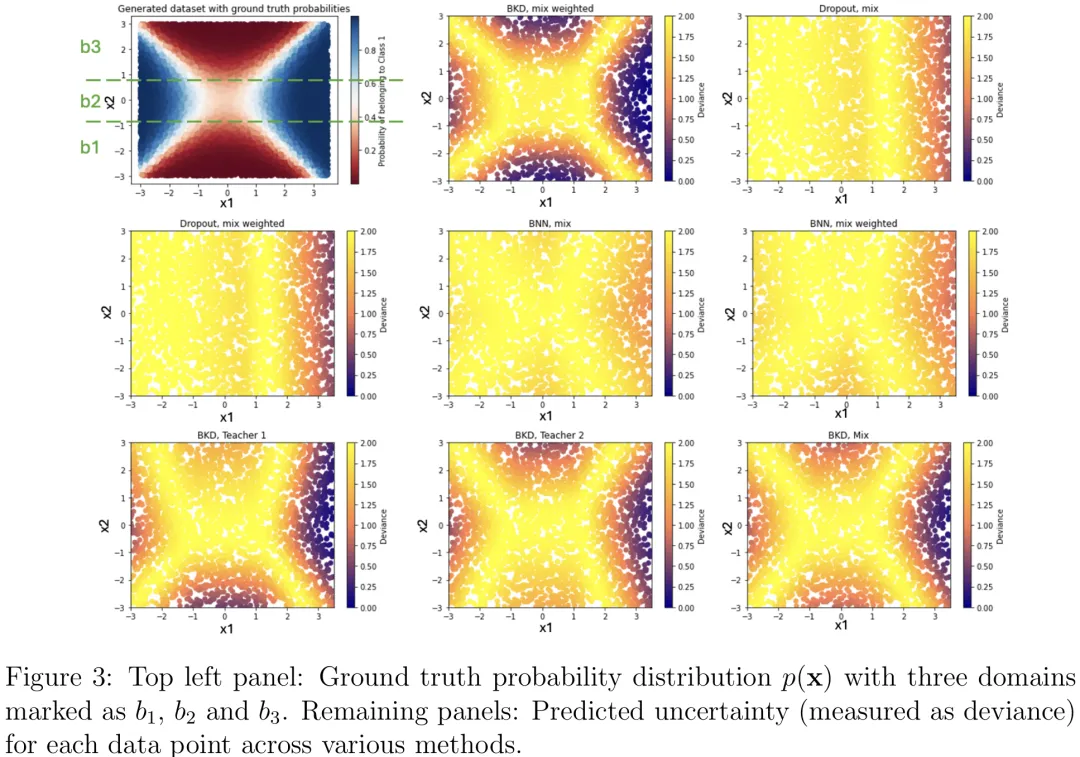
Paper Key Illustration
原文
Multi-Teacher Knowledge Distillation via Teacher-Informed Mixture Priors
Abstract: Knowledge distillation is a powerful method for model compression, enabling the efficient deployment of complex deep learning models (teachers), including large language models. However, its underlying statistical mechanisms remain unclear, and uncertainty evaluation is often overlooked, especially in real-world scenarios requiring diverse teacher expertise. To address these challenges, we introduce \textit{Multi-Teacher Bayesian Knowledge Distillation} (MT-BKD), where a distilled student model learns from multiple teachers within the Bayesian framework. Our approach leverages Bayesian inference to capture inherent uncertainty in the distillation process. We introduce a teacher-informed prior, integrating external knowledge from teacher models and task-specific training data, offering better generalization, robustness, and scalability. Additionally, an entropy-based weighting mechanism adaptively adjusts each teacher's influence, allowing the student to combine multiple sources of expertise effectively. MT-BKD enhances the interpretability of the student model's learning process, improves predictive accuracy, and provides uncertainty quantification. We validate MT-BKD on both synthetic and real-world tasks, including protein subcellular location prediction and image classification. Our experiments show improved performance and robust uncertainty quantification, highlighting the strengths of our MT-BKD framework.
链接:https://arxiv.org/pdf/2605.27967
AI 深度解读
AgensFlow 将多智能体编排视为部分可观测的序贯决策过程,旨在解决在无法直接观测用户真实意图、任务难度及模型可靠性等隐性状态下的协调优化问题。该方法通过构建‘折叠任务签名(Folded Task Signatures)’对高维状态空间进行抽象,利用基于规则的检测器将任务特征映射为离散的 regime 标签(如模糊、矛盾、高风险等),并结合结构化交接状态与信念估计生成离散状态表示。在此基础上,系统采用可靠性感知的 UCB1 变体学习策略,在动作空间(包括调用技能、跳过步骤、终止)中动态选择最优路径。奖励函数由相对评估器(RelativeJudge)生成的质量分数、归一化 token 成本及重试惩罚共同构成,从而引导策略在控制运营成本的同时提升任务表现。该框架的核心意义在于实现了可审计的策略图学习,使系统能够复用抽象状态下的协调行为,而非记忆具体提示,显著提升了在线学习在跨域场景中的泛化能力与对协作质量、恢复行为及证据利用的敏感度。
中文摘要
摘要:基于大型语言模型(LLM)的多智能体系统需要做出多种难以预先确定的协调决策:应调用何种技能协议、由何种智能体角色执行子任务、为各角色绑定何种模型、角色间如何交互、何时使用检索或验证,以及何时完全省略某一步骤。这些决策与任务体制及运行约束相互交织,因此静态流水线和一次性模型比较仅提供了对设计空间的有限视角。本文提出了 AgensFlow,这是一个开源框架,它将多智能体协调视为部分可观测环境下的在线策略学习问题。该框架使协调决策变得可观测且可从重复轨迹中学习,而非将技能、角色、模型、拓扑结构及评估选择视为固定的流水线设计。我们在两个语料库上对 AgensFlow 进行了评估:分布式系统故障处理任务和网络安全建议任务。评估结果显示了三个主要结论:在协调密集型任务类别中,学习到的路由策略达到了比固定流水线基线更高质量的操作点;skip:X 将拓扑压缩识别为底层架构中具有重要意义的一部分;预热策略图可在保持平台质量的同时降低探索成本。总体而言,结果支持了以下观点:通过学习到的、可审计的路由策略,可以改进静态连线下的多智能体工作流,特别是在协调密集型场景中。
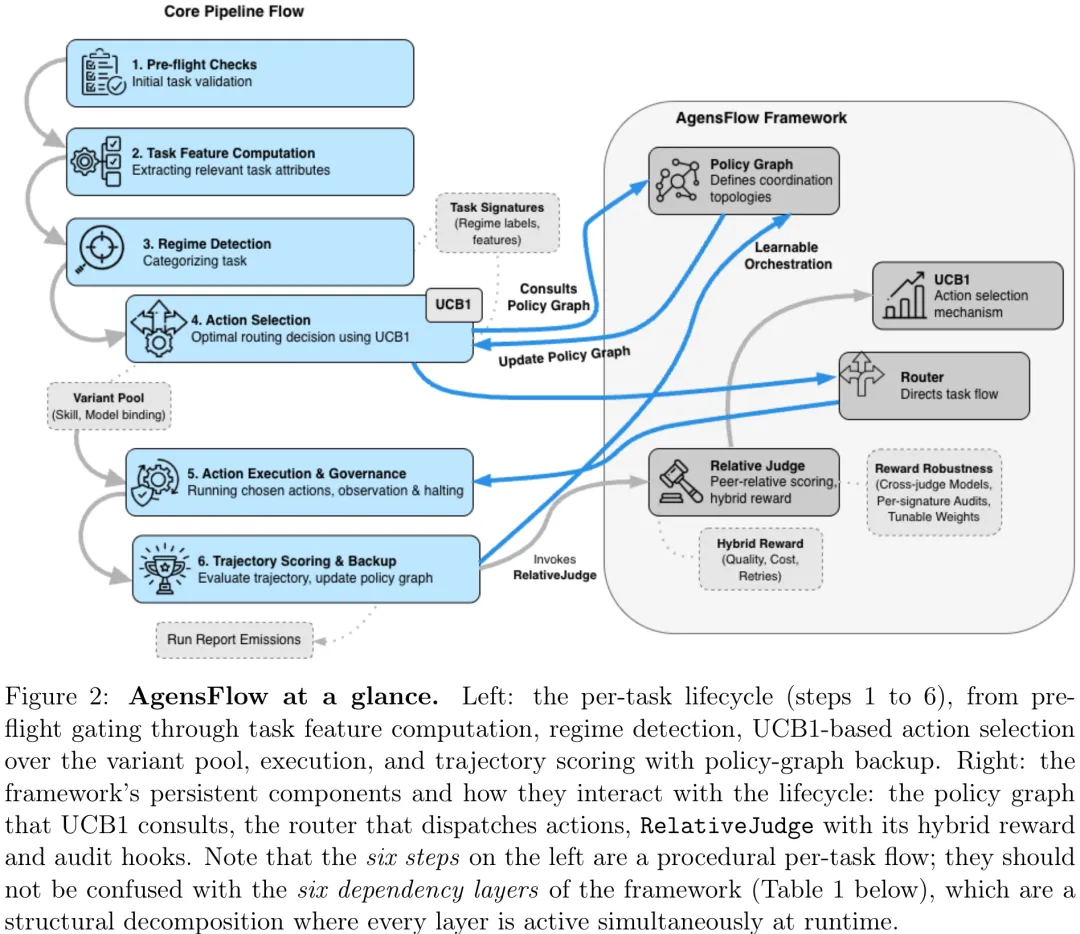
Paper Key Illustration
原文
AgensFlow: A Coordination-Policy Substrate for Multi-Agent Systems
Abstract: Multi-agent systems built on large language models (LLMs) require many coordination choices that are difficult to fix a priori: which skill protocol to invoke, which agent role should perform a subtask, which model to bind to each role, how roles should interact, when to use retrieval or verification, and when to omit a step entirely. These choices interact with task regime and operational constraints, so static pipelines and one-off model comparisons provide only a limited view of the design space. This paper introduces AgensFlow, an open-source framework that treats multi-agent coordination as an online policy-learning problem under partial observability. The framework makes coordination decisions observable and learnable from repeated trajectories, rather than treating skill, role, model, topology, and evaluation choices as fixed pipeline design. AgensFlow is evaluated on two corpora: distributed-systems incident tasks and security-advisory tasks. The evaluation shows three main results: learned routing reaches a higher-quality operating point than a fixed pipeline baseline on coordination-heavy classes; skip:X isolates topology compression as a meaningful part of the substrate; and warm-started policy graphs can reduce exploration cost while preserving plateau quality. Overall, the results support that learned, auditable routing can improve coordination-heavy multi-agent workflows over static wiring.
链接:https://arxiv.org/pdf/2605.27466
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
本研究针对脑电图(EEG)基础模型(Foundation Models, FMs)与传统监督学习基线之间的性能差异及机制进行了系统性评估。首先,通过双阶段工作流对各类基线模型进行超参数优化,确立了公平比较的基准。其次,开展了范式级消融实验,分别剥离了大规模异质预训练、自监督范式以及预训练语言模型(LLM)骨干网络(如 GPT-2)的贡献,旨在探究这些复杂架构是否真正带来了性能提升,还是仅增加了计算负担。此外,研究提出了神经生理探测(NPP)框架,利用傅里叶相位随机化、频带消融和空间扰动三种手段,解构模型对时间动态、频谱特征及特定脑区(如额叶、枕叶)的依赖程度,以验证模型是否学习了具有神经解剖学一致性的有效表征。实验结果表明,在 TUEV、TUAB 及 BCI Competition IV-2b 等多个数据集上,经过 ASHA 优化的传统监督基线模型在多数任务中表现优异,甚至优于部分预训练基础模型。研究进一步揭示,尽管基础模型引入了复杂的 LLM 架构,但其性能增益并非完全源于语言先验或自监督策略,且模型对特定神经生理特征的依赖需通过严格的探测加以验证,这为理解 EEG 基础模型的实际价值与局限性提供了关键依据。
中文摘要
摘要:大型脑电图(EEG)基础模型(FMs)在解码多种认知任务中的脑电图信号方面展现出巨大潜力。然而,现有的 EEG-FM 研究存在三个关键局限性:监督基线调优过程不透明、复杂学习范式的作用未经证实,以及模型决策缺乏透明度。为应对这些问题,我们提出了 EEG-FM-Audit,这是一个旨在系统化评估 EEG-FM 的综合评价与分析流程。EEG-FM-Audit 包含三个主要组成部分:(1)由 ASHA 驱动的基准测试协议,通过透明化优化监督基线以确保公平比较;(2)范式级消融研究,用于评估学习范式在基础模型中的有效性;(3)神经生理探测(NPP)框架,用于探究基础模型是否利用了有效的时序、空间和频谱脑电图特性。我们将 EEG-FM-Audit 应用于四个最先进的 EEG-FM 和五个代表性监督模型,并在三个公开数据集上进行测试。结果表明,经过适当调优的监督基线模型在参数数量显著较少的情况下,其性能可与先进的基础模型相媲美甚至更优。此外,我们发现基础模型学习范式的有效性高度依赖于数据集规模和架构。最后,NPP 分析揭示了基础模型如何依赖特定的生理特征,从而为更具可解释性的神经解码建立了框架。
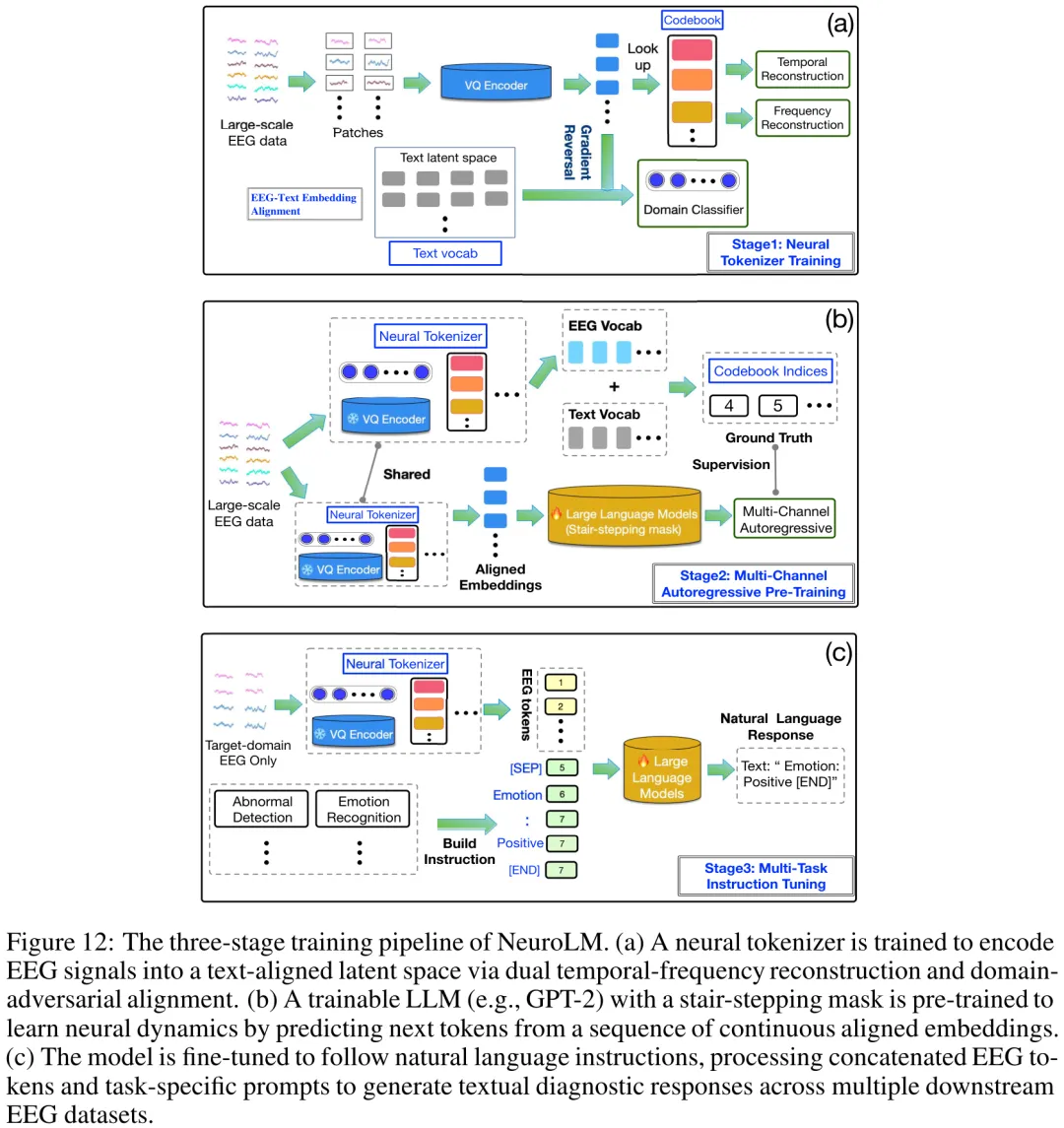
Paper Key Illustration
原文
EEG-FM-Audit: A Systematic Evaluation and Analysis Pipeline for EEG Foundation Models
Abstract: Large EEG Foundation Models (FMs) have shown great potential for decoding EEG signals across diverse cognitive tasks. However, existing EEG-FM studies exhibit three critical limitations: opaque supervised baseline tuning, unverified contributions of complex learning paradigms, and a lack of transparency in model decision-making. To address these, we propose EEG-FM-Audit, a comprehensive evaluation and analysis pipeline designed to systematize the assessment of EEG-FMs. EEG-FM-Audit consists of three primary components: (1) an ASHA-driven benchmarking protocol that ensures fair comparisons by transparently optimizing supervised baselines; (2) paradigm-level ablation studies to evaluate the effectiveness of learning paradigms in FMs; and (3) a neurophysiological probing (NPP) framework, which explores whether FMs leverage valid temporal, spatial, and spectral EEG properties. We apply EEG-FM-Audit to four state-of-the-art EEG-FMs and five representative supervised models across three public datasets. Our results reveal that properly tuned supervised baselines can match or outperform advanced FMs, despite requiring significantly fewer parameters. Furthermore, we find that the effectiveness of learning paradigms of FMs is highly dependent on dataset scale and architecture. Finally, NPP analysis demonstrates how FMs rely on specific physiological features, establishing a framework for more interpretable neural decoding.
链接:https://arxiv.org/pdf/2605.26910
AI 深度解读
本文深入探讨了评分规则(Scoring Rules)在序列预测中的分解性质及其与校准(Calibration)和细化(Refinement)的关系。研究首先从数学基础出发,定义了 M-有界和 M-Lipschitz 连续(及α-Hölder 连续)的评分规则,并提出了关于 L-熵(L-entropy)及其凹性的关键命题。核心贡献在于将经典的 Brier 分数分解定理推广至任意满足线性性质的适当评分规则(Proper Scoring Rules)。研究构建了 L-Brier 分数、L-校准分数和 L-细化分数的具体定义,并证明了对于任何评分规则,总 Brier 分数均可分解为校准分数与细化分数之和。这一分解不仅适用于标准以预测值为划分的二进,也适用于更精细的划分序列。研究进一步指出,L-细化分数代表了在给定划分约束下,L-Brier 分数的最小可能值,该最小值在预测值等于对应划分内平均行动时取得。这一结果揭示了评分规则在衡量预测质量时,校准误差与细化误差之间的内在联系,为评估预测系统的整体性能提供了通用的理论框架。
中文摘要
摘要:经典概念“校准预测”及其较新的改进形式“击败校准”(calibeating)是相对于标准二次评分规则定义的。我们将这些概念推广到一类“适当”(proper)评分规则(在此类规则下,最佳预测为真实分布),并通过要求误差在所有有界适当评分规则上一致收敛于零,定义了“适当校准”(proper-calibration)和“适当击败校准”(proper-calibeating)。首先,我们证明校准总是蕴含适当校准,而击败校准并不必然蕴含适当击败校准。其次,我们展示了如何保证适当击败校准和适当多校准击败。最后,我们证明了适当校准与在不确定性决策中针对最佳预测回复时的通用无后悔(universal no regret)之间的等价性。

Paper Key Illustration
原文
Proper Calibeating
Abstract: The classic concept of "calibrated forecasts" and its more recent refinement, "calibeating," are defined with respect to the standard quadratic scoring rule. We extend these notions to the class of proper scoring rules (for which the best forecast is the true distribution) and define proper-calibration and proper-calibeating by requiring the errors to converge to zero uniformly over all bounded proper scoring rules. We first establish that calibration always implies proper-calibration, whereas calibeating need not imply proper-calibeating. Second, we show how to guarantee proper-calibeating and proper-multicalibeating. Finally, we demonstrate the equivalence between proper-calibration and universal no regret when best replying to forecasts in decision-making under uncertainty.
链接:https://arxiv.org/pdf/2605.26703
AI 深度解读
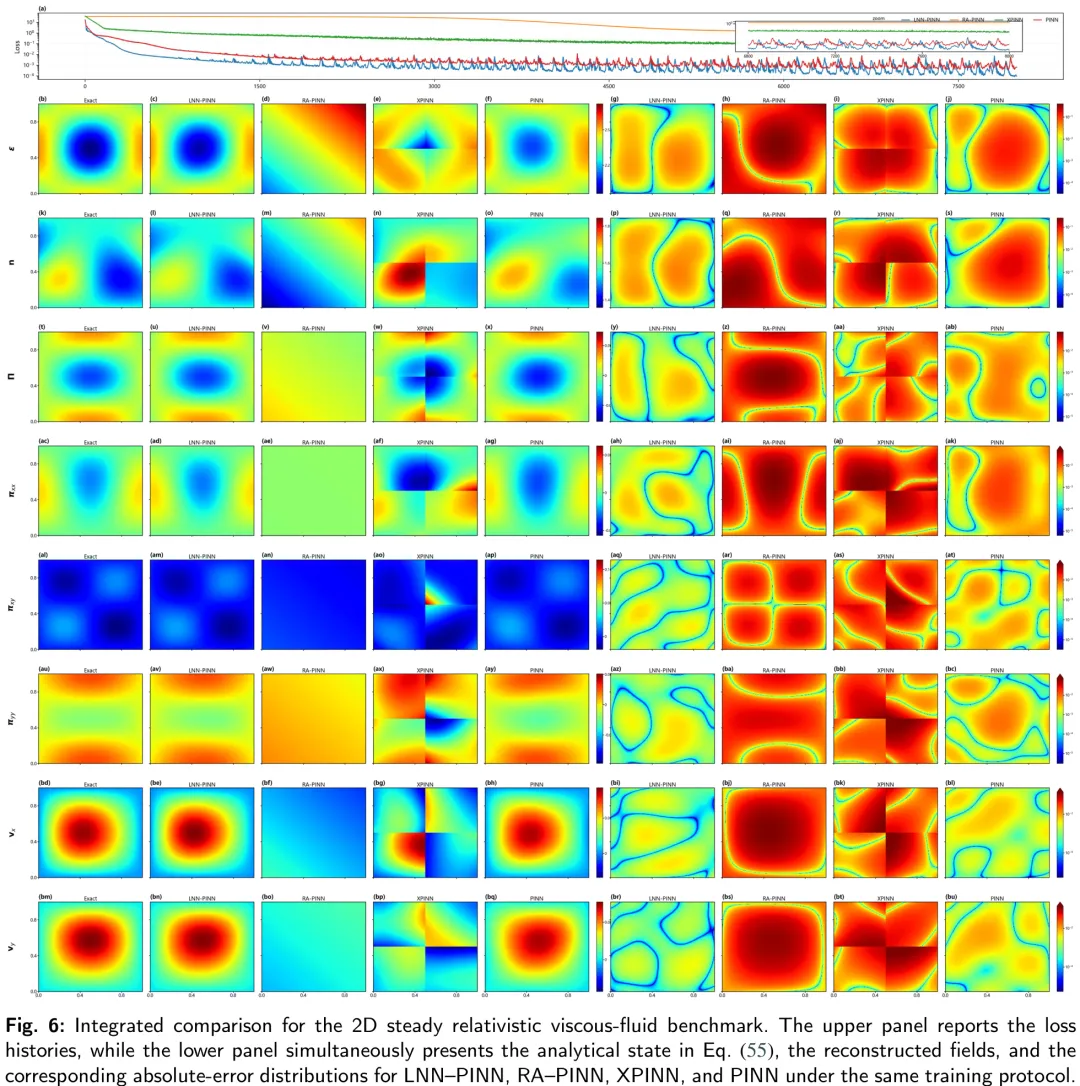
本文提出了一种名为 LNN-PINN 的改进模型,旨在解决传统物理信息神经网络(PINN)在训练过程中因纯前馈结构导致的梯度消失或优化困难问题。研究核心在于重构神经网络的隐藏层传播机制:在保留 PINN 物理约束(如偏微分方程残差、边界条件)和物理唯一训练目标的前提下,将传统的纯仿射变换与激活函数组合,替换为一种‘保宽残差算子’。该算子通过引入可学习的液状模块(Liquid Module),在保持隐藏层宽度的同时,对当前特征表示进行残差修正,从而增强模型对复杂物理场(如漂移 - 衰减、拉普拉斯方程、相对论粘性流体等)的拟合能力。实验结果表明,LNN-PINN 在保持与基准 PINN 相同训练协议和损失函数的情况下,显著提升了重构精度并优化了收敛路径,证明了仅通过修改内部参数化解的传播机制即可有效提升 PINN 性能,而无需引入额外的监督信号或改变外部训练结构。
中文摘要
摘要:物理信息神经网络(PINNs)因其能够将偏微分方程先验知识融入深度学习框架而备受关注;然而,在处理复杂问题时,其预测精度往往有限。为解决这一问题,我们提出了 LNN-PINN,这是一种物理信息神经网络框架,它在保留原有物理建模和优化流程的同时,引入了液相残差门控架构,以提升预测精度。该方法仅在隐藏层映射中引入轻量级门控机制,保持采样策略、损失函数构成及超参数设置不变,从而确保性能提升完全源于架构优化。在四个基准问题上,LNN-PINN 在相同的训练条件下 consistently 降低了均方根误差(RMSE)和平均绝对误差(MAE),绝对误差图进一步证实了其精度提升。此外,该框架在不同维度、边界条件和算子特性下表现出强大的适应性和稳定性。总之,LNN-PINN 为提升物理信息神经网络在复杂科学与工程问题中的预测精度提供了一种简洁而有效的架构改进方案。
Paper Key Illustration
原文
LNN-PINN: A Unified Physics-Only Training Framework with Liquid Residual Blocks
Abstract: Physics-informed neural networks (PINNs) have attracted considerable attention for their ability to integrate partial differential equation priors into deep learning frameworks; however, they often exhibit limited predictive accuracy when applied to complex problems. To address this issue, we propose LNN-PINN, a physics-informed neural network framework that incorporates a liquid residual gating architecture while preserving the original physics modeling and optimization pipeline to improve predictive accuracy. The method introduces a lightweight gating mechanism solely within the hidden-layer mapping, keeping the sampling strategy, loss composition, and hyperparameter settings unchanged to ensure that improvements arise purely from architectural refinement. Across four benchmark problems, LNN-PINN consistently reduced RMSE and MAE under identical training conditions, with absolute error plots further confirming its accuracy gains. Moreover, the framework demonstrates strong adaptability and stability across varying dimensions, boundary conditions, and operator characteristics. In summary, LNN-PINN offers a concise and effective architectural enhancement for improving the predictive accuracy of physics-informed neural networks in complex scientific and engineering problems.
链接:https://arxiv.org/pdf/2508.08935
AI 深度解读
本研究针对自闭症谱系障碍(ASD)儿童的教育干预,对比了传统行为主义方法(如 ABA、TEACCH)仅关注表面行为的局限性,提出引入基于建构主义理念的“大社交”系统及社会机器人 NAO 的混合干预模式。研究采用混合方法,选取 S 市特殊教育学校 9-11 岁、无严重行为问题的 6 名 ASD 儿童作为参与者,在排除听力视觉障碍且经独立机构确诊的前提下开展实验。研究引入具备情感识别与表达能力的 NAO 机器人,结合结构化教学与建构主义理论重构课程内容,旨在降低认知负荷并提升课堂参与度。实验设计包含多机位(DJI Pocket 2、双目追踪相机及教室内置相机)视频录制,利用定制软件进行行为编码分析。研究假设 NAO 机器人辅助课堂能显著提升 ASD 儿童的在线注意力、课堂沟通行为频率、活动评价得分及情绪状态。通过人机协作(机器人 - 教师 - 学生)与小组动态探索,该研究致力于验证技术融合在促进 ASD 儿童主动性、合作性及创造力方面的有效性,并为后续教育实验积累实证经验。
中文摘要
摘要:自闭症是一种在幼儿期显现并持续终身的发育性障碍,深刻影响社交行为,并阻碍确诊者学习及社交技能的习得。随着技术进步,越来越多的技术被用于支持自闭症谱系障碍(ASD)学生的教育,旨在改善其教育成果与社交能力。多项关于自闭症干预的研究强调了社交机器人在行为治疗中的有效性。然而,针对将社交机器人融入自闭症儿童课堂环境的研究仍较为匮乏。本文描述了在集体课堂环境中,由 NAO 机器人介导的群体实验的设计与实施。该实验由特殊教育教师与 NAO 机器人协同开展课堂活动,旨在通过教师、机器人与学生之间的互动营造动态的学习环境。该实验在特殊教育学校进行,作为未来开展更长时间机器人辅助课堂课程的奠基性研究。实验数据表明,配备 NAO 机器人的课堂中,ASD 学生的表现显著优于普通课堂中的学生。NAO 机器人的人形特征和肢体语言吸引了学生的注意力,尤其在才艺展示和指令任务中,学生表现出更高的参与度,且刻板重复行为及普通环境中常见的无关细微动作明显减少。我们的初步发现表明,NAO 机器人显著提升了 ASD 学生的专注力与课堂参与度,有望改善其教育表现并促进更优的社交行为。
Paper Key Illustration
原文
Surprising Performances of Students with Autism in Classroom with NAO Robot
Abstract: Autism is a developmental disorder that manifests in early childhood and persists throughout life, profoundly affecting social behavior and hindering the acquisition of learning and social skills in those diagnosed. As technological advancements progress, an increasing array of technologies is being utilized to support the education of students with Autism Spectrum Disorder (ASD), aiming to improve their educational outcomes and social capabilities. Numerous studies on autism intervention have highlighted the effectiveness of social robots in behavioral treatments. However, research on the integration of social robots into classroom settings for children with autism remains sparse. This paper describes the design and implementation of a group experiment in a collective classroom setting mediated by the NAO robot. The experiment involved special education teachers and the NAO robot collaboratively conducting classroom activities, aiming to foster a dynamic learning environment through interactions among teachers, the robot, and students. Conducted in a special education school, this experiment served as a foundational study in anticipation of extended robot-assisted classroom sessions. Data from the experiment suggest that ASD students in classrooms equipped with the NAO robot exhibited notably better performance compared to those in regular classrooms. The humanoid features and body language of the NAO robot captivated the students' attention, particularly during talent shows and command tasks, where students demonstrated heightened engagement and a decrease in stereotypical repetitive behaviors and irrelevant minor movements commonly observed in regular settings. Our preliminary findings indicate that the NAO robot significantly enhances focus and classroom engagement among students with ASD, potentially improving educational performance and fostering better social behaviors.
链接:https://arxiv.org/pdf/2407.12014
AI 深度解读
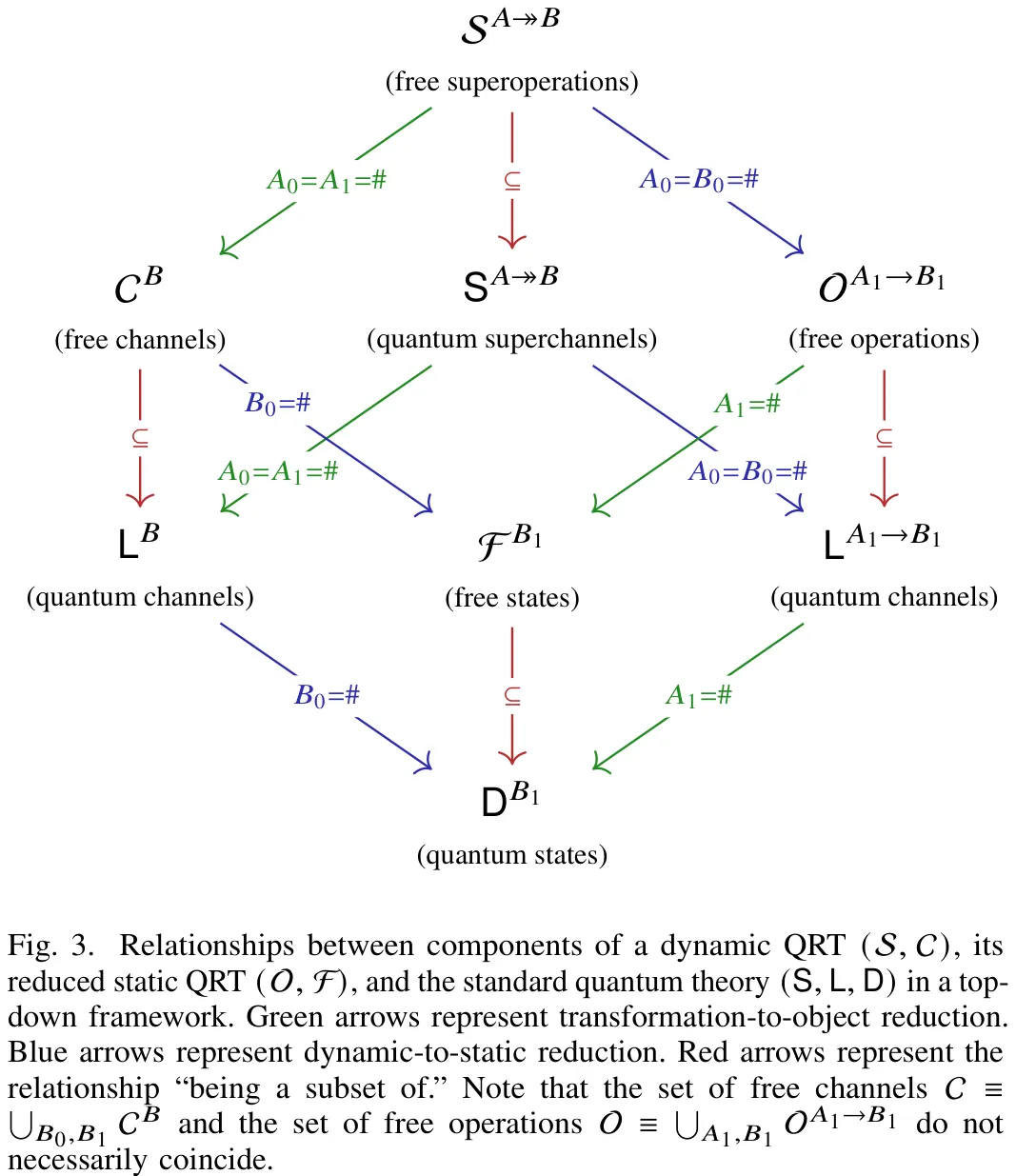
本文构建了量子信息论中动态系统的形式化框架,核心在于通过 Choi-Jamiołkowski 同构将量子信道映射为复合系统中的正定算子,进而推广至超映射(supermap)与超信道(superchannel)理论。研究首先定义了静态系统与动态系统的代数结构,引入‘副本’概念以处理复合系统中的纠缠态表示。在此基础上,利用 Choi 算子建立了线性映射与算子空间的一一对应关系,明确了量子信道(完全正保迹)与量子子信道(完全正保迹非增)的数学刻画。进一步地,文章通过超映射将线性映射之间的变换转化为复合动态系统中的线性算子,利用最大纠缠算子构建了超映射与其 Choi 算子之间的同构。关键结论在于揭示了超信道的分解结构:任意超信道均可分解为预处理信道、记忆侧信道(恒等映射)与后处理信道的串联。这一结果不仅统一了量子操作与超操作的描述语言,也为分析量子过程演化、量子纠错及量子网络协议提供了严谨的数学基础。
中文摘要
摘要:我们提出了一种基于熵概念和操作任务的新方法,用于刻画一般的闭式且凸的量子资源理论,包括动态资源理论。我们提出了量子条件极小熵的资源理论推广形式,称之为自由条件极小熵(FCME),其意义在于量化观察者在信息处理仅限于该资源理论的自由操作时,对量子系统所持有的“主观”不确定性程度。利用这一广义概念,我们为任意闭式且凸的量子资源理论中量子态或信道之间的自由可转换性提供了一套完整的熵条件。此外,我们基于 FCME 推导了状态或信道的资源全局鲁棒性的信息论解释,将其表述为一种类似于互信息的量。除了这种熵方法外,我们还通过分析动态资源在操作任务中的性能来刻画动态资源。利用这些任务,我们构建了一组具有操作意义且完整的资源单调量,从而实现了对量子信道之间自由可转换性的忠实检验。最后,我们证明,任何良定义的基于鲁棒性的信道度量均可解释为该信道在通信任务中相对于自由信道的操作优势。
Paper Key Illustration
原文
Entropic and operational characterizations of dynamic quantum resources
Abstract: We offer new methods for characterizing general closed and convex quantum resource theories, including dynamic ones, based on entropic concepts and operational tasks. We propose a resource-theoretic generalization of the quantum conditional min-entropy, termed the free conditional min-entropy (FCME), in the sense that it quantifies an observer's ``subjective'' degree of uncertainty about a quantum system given that the observer's information processing is limited to free operations of the resource theory. Using this generalized concept, we provide a complete set of entropic conditions for free convertibility between quantum states or channels in any closed and convex quantum resource theory. We also derive an information-theoretic interpretation for the resource global robustness of a state or a channel in terms of a mutual-information-like quantity based on the FCME. Apart from this entropic approach, we characterize dynamic resources by also analyzing their performance in operational tasks. We construct operationally meaningful and complete sets of resource monotones with these tasks, which enable faithful tests of free convertibility between quantum channels. Finally, we show that every well-defined robustness-based measure of a channel can be interpreted as an operational advantage of the channel over free channels in a communication task.
链接:https://arxiv.org/pdf/2112.06906
Subscribe to arXiv's Daily Preprint Notifications
