 夜雨聆风
夜雨聆风声明:【好玩的AI】单独开了一个系列,主体内容来自我,文档生成及排版来自AI工具,旨在记录自己学习AI的实际进展,并且给那些还在犹豫徘徊的读者一点参考。
本期想要传达的主要观点是:AI处理信息是手到擒来的容易,快把你需要的信息转成自己喜欢的样子!
一、缘起:我只想看几篇新闻 📰
事情的起点特别简单。英语不太好的我,时不时有读英文新闻以鞭策自己努力学习的习惯,主要是为了保持语感,chinadaily相对来说比较适合我。这两天玩AI,心想:"5月快过完了,这个月的重点新闻有哪些?能不能一次性拉下来,方便回看?"
我: "去 https://www.chinadaily.com.cn/e/index.html ,帮我把 China Daily 5月份的新闻汇总成一个可导航的 HTML,顺便把四六级词汇表附在后面。"
AI: "好的,我来抓取主页上的新闻列表。"
当时觉得这就是个"信息搬运"的活,没啥技术含量,以前的手工操作或者python抓网页的dirty work,现在可以交给AI啦。
二、第一个版本:卡片导航 + 词汇表 🃏
AI 很快就交出了第一版。它从 China Daily 首页抓到了 23 篇 5月新闻,按主题分成了 6 大板块:
⭐ 重点推荐:中美智库峰会 🌏 国际外交:中俄联合声明、钓鱼岛事件等 4 篇 📊 经济发展:亚投行、算力经济等 4 篇 🤖 科技教育:AI学院、教育红利等 4 篇 👥 社会民生:新就业形态、西藏等 4 篇 💬 观点评论:FIFA转播权、生态文明等 5 篇
布局很清晰 —— 左侧固定导航栏按类别一触即达,右侧卡片流展示新闻标题和摘要,底部是 CET-4(30词)+ CET-6(25词) 的词汇表,支持按等级和词性筛选。
💡 第一版效果:
✅ 23篇新闻按6大主题分类,可导航
✅ 深色主题,响应式布局(手机也能看)
✅ 词汇表支持 CET-4 / CET-6 筛选 + 词性过滤
⚠️ 但是 — 每篇文章只有摘要,想看全文还得跳回原网站
这时候我提了第一个"得寸进尺"的需求——
我: "我希望每一篇文章都可以离线阅读,请帮我拉下来。"
三、第二个版本:把23篇全文装进口袋 📡
这次AI的工作量有点难度了——它分 3 轮并行抓取,对每一篇文章的原文链接逐个发起请求,把完整正文拉到本地,嵌入 HTML 内的可展开区域。
第一轮:6 篇并行抓取 中美峰会、中俄声明、钓鱼岛、AI学院、新就业形态、FIFA转播权
第二轮:7 篇并行抓取 数字基建、算力经济、对华投资、人才红利、青年交流、民族纹样、生态文明
第三轮:剩余文章 + 分页处理 海洋治理(4页)、算力(2页)等多页长文也尽量收录了核心内容
这里有个小坑: 有些文章是多页的(4页长文),WebFetch 工具每次只能抓一页。AI 的处理方式是:尽可能抓取第1页和第2页,收录核心内容,并在文中标注"本文共X页,此处为部分内容"。不完美,但诚实。
最终交付:21 篇全文 + 2 篇核心摘录,全部嵌入 HTML,断网也能打开阅读。每张卡片右下角有个「📖 展开全文」按钮。
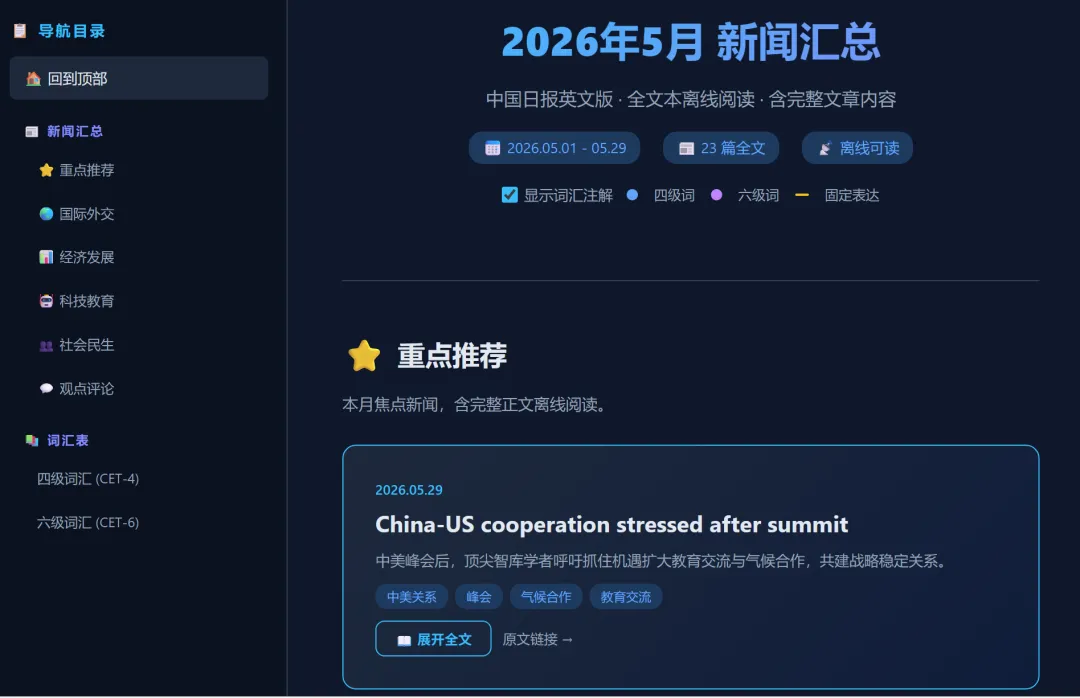
我本来觉得这已经很完美了,但突然冒出一个念头——
我: "每篇文章中的四六级词汇和固定表达,能加个注解么?"
这意味着 AI 需要:
读懂 23 篇英文文章的全文 自动识别哪些词是 CET-4/6 词汇 还要处理词的变形形式(比如 established 是 establish 的过去分词) 同时识别 45 个固定搭配(如 in terms of、pave the way for) 还不破坏原有的 HTML 结构
四、第三个版本:新闻里的"弹幕式"英语课堂 📝
这是整个项目最有趣的部分,也是技术含量最高的一环。
注解引擎怎么工作的?(这当然是让AI复盘给我讲的啦)
AI 在 HTML 里嵌入了整整一个 JavaScript 注解引擎,工作流程是这样的:
🔧 注解引擎工作流程:
第1步 — 构建词库: 55个四六级核心词 + 120+变形词映射表(如 established → establish, significantly → significant, facilitates → facilitate)
第2步 — 先标固定表达: 45个常用短语(in terms of, pave the way for, across the board, at stake 等),按短语长度从长到短排序处理,避免"短词吃长词"
第3步 — 再标词汇: 用 TreeWalker 遍历所有文本节点,对每个单词查词库,匹配到的就包一层标签
第4步 — 避免冲突: 跳过已经在注解内的文本节点,跳过链接和脚本标签
注解长什么样?
三种颜色,一眼分清:
🔵 蓝色虚线下划线 = CET-4 词汇(如 benefit, significant, involve) 🟣 紫色虚线下划线 = CET-6 词汇(如 consolidate, unprecedented, facilitate) 🟡 金色虚线背景 = 固定表达(如 due to, take into account, the tip of the iceberg)
鼠标悬停任何一个标注词,就会弹出释义:词性 + 中文翻译。不悬停的时候,注解静静地躺在文字下面,完全不干扰正常阅读。

而且顶部有个勾选框 —— 「显示词汇注解」,取消勾选后所有标注瞬间消失,变回纯净的英文原文。
这个设计很妙: 读新闻的时候想顺便学单词,打开注解;想专注阅读的时候,一键关掉。就像一个可以随时切换"学习模式"和"阅读模式"的开关。
五、过程中踩了哪些坑?😅
坑1:WebFetch 不是万能的
文章分页的时候,只抓了第一页就返回了。虽然我提示"提取所有段落",但工具本身有 token 限制,特别长的文章会在中途截断。最后 23 篇里有 2 篇不完整(都是 2-4 页的长文),只能标注说明。
坑2:词形变体比想象的多
最开始我只列了 55 个词的原形,比如 establish。但文章里出现的是 established, establishes, establishing, establishment……如果不做映射,这些词就不会被标注。后来补了一个 LEMMA 映射表,把常见变形全部手动配对上,覆盖了约 120 个词形。
坑3:标注顺序很重要
如果先标单词再标短语,会出现 "in terms of" 里的 terms 被单独标注为词汇,导致短语的标注失效。正确的做法是:先标长短语,再标单词。
坑4:HTML 结构不能乱
用正则直接替换 HTML 文本很容易破坏标签结构。最后用了 TreeWalker API,只遍历纯文本节点,逐个替换,保证了 DOM 结构完整。
六、我学到了什么 💡
1. AI 擅长"增量交付"
这个项目不是一次就做完的,而是三次迭代——从摘要到全文到注解,每一步都建立在上一步的基础上。AI 在这个过程中表现得非常好:它记住了之前的文件结构、理解了需求演进的方向,每次升级都是"增量修改"而非"推倒重来"。
2. 最好的工具是"看懂了你的数据"的工具
词汇注解这个功能,本质上是 AI 把它自己的语言能力嵌入到了输出产品里。它不是简单地把数据搬过来,而是理解数据、加工数据、让数据产生新价值。
3. 离线优先是用户的真实需求
我一开始没说要离线阅读,但试完第一个版本后立刻意识到:如果每次都要打开网站,这跟直接读 China Daily 有什么区别? 离线嵌入全文才是这个工具的核心竞争力。
4. 用户会不断"得寸进尺"——这恰恰是产品迭代的正常节奏
从"搜新闻"到"离线全文"到"词汇注解",每一步都是我在用完之后发现"还能更好"。AI 能跟得上这种节奏,才是它区别于传统工具的地方。
七、这个方案还能怎么用?🚀
这套"信息抓取 → 结构化整理 → 知识标注"的流水线,换个数据源就是一套新产品:
📚 场景1:学术论文阅读助手
把 ArXiv / PubMed 上的论文拉下来 → 按主题分类 → 自动标注学科术语和参考文献 → 生成思维导图。
📖 场景2:分级阅读训练
把《纽约时报》《经济学人》文章自动标注蓝思值(Lexile),按难度分级,给不同水平的学习者推荐合适文章。
🗣️ 场景3:演讲稿 / 辩论素材库
抓取 TED 演讲稿 → 标注修辞手法(排比、反问、引用)→ 标注"金句" → 一键生成演讲训练卡片。
🎓 场景4:考试真题词汇频率分析
把近10年考研 / 雅思 / 托福阅读真题拉下来 → 统计四级/六级/考研词汇出现频率 → 按"高频必背"和"低频了解"生成分级词表。
🧒 场景5:儿童英语分级阅读
抓取 BBC Learning English / VOA 慢速英语 → 按CEFR等级(A1-C1)自动分级标注 → 生成带插图的绘本页面。
八、你也可以试试 💪
你不需要懂代码,你要做的事情就是:
告诉AI我要什么("China Daily 5月新闻,可导航HTML,加词汇表") 在拿到第一个版本后,提出改进意见("能离线看吗?") 再提出一个"过分"的需求("能标注四六级词汇吗?") AI 自己完成了全部的技术工作
核心逻辑: 你负责"想要什么",AI 负责"怎么做到"。两者之间不需要"你会编程"这个中间环节。
🎯 给你的 Prompt 模板:
去 [新闻网站URL] 获取 [某时间段] 的新闻,汇总成为可导航的HTML,要求:
按主题分类 保留原文链接 把 [你要学习的词汇类型] 词汇表附在最后 支持离线阅读 文章中的生词自动加注解 —— 把中括号里的内容换成你自己的需求,扔给AI就行了。
✨ 今天就到这里,去试试吧 ✨
