 夜雨聆风
夜雨聆风Claude Opus 4.8 发布:AI 竞赛正在从“谁更聪明”,转向“谁更能被托付”

2026 年 5 月 28 日,Anthropic 正式发布 Claude Opus 4.8。
如果只看版本号,它像是一次小步快跑:从 Opus 4.7 到 4.8,价格不变,能力提升,顺手补上几个产品功能。但如果把它放回过去一年大模型竞争的主线里看,这次更新的信号其实很清楚:
大模型公司的战场,正在从“单次回答有多强”,转向“长时间工作能不能不掉链子”。
这不是一个更会聊天的 Claude,而是一个更适合被放进真实工作流里的 Claude。它的关键词不是惊艳,而是可靠、诚实、可调度、能协作。
这四个词,可能比又一个漂亮的基准测试分数更重要。
Opus 4.8 表面是模型升级,实质是“工作系统”的升级
Anthropic 官方给 Opus 4.8 的定位是:基于 Opus 4.7 的改进版本,在编码、智能体任务、推理和知识工作上都有提升,并以相同价格开放。
它的常规 API 价格保持不变:输入 5 美元/百万 tokens,输出 25 美元/百万 tokens。Fast mode 则变成输入 10 美元/百万 tokens、输出 50 美元/百万 tokens,官方称输出速度可达约 2.5 倍,并且相比上一代 fast mode 便宜了 3 倍。
更强、更快、价格不涨。但真正值得注意的是,Anthropic 没有把所有叙事都押在“智商更高”上,而是把大量篇幅给了三个方向:
Claude Code 的 dynamic workflows 用户可调的 effort control 模型更愿意承认不确定性、更少放过自己写出的代码缺陷
Anthropic 已经不满足于让 Claude 做一个“高水平问答模型”。它想让 Claude 成为一种可以被编排、被约束、被接入企业流程的执行层。
跑分当然有提升,但这次更大的变量是“稳定性”
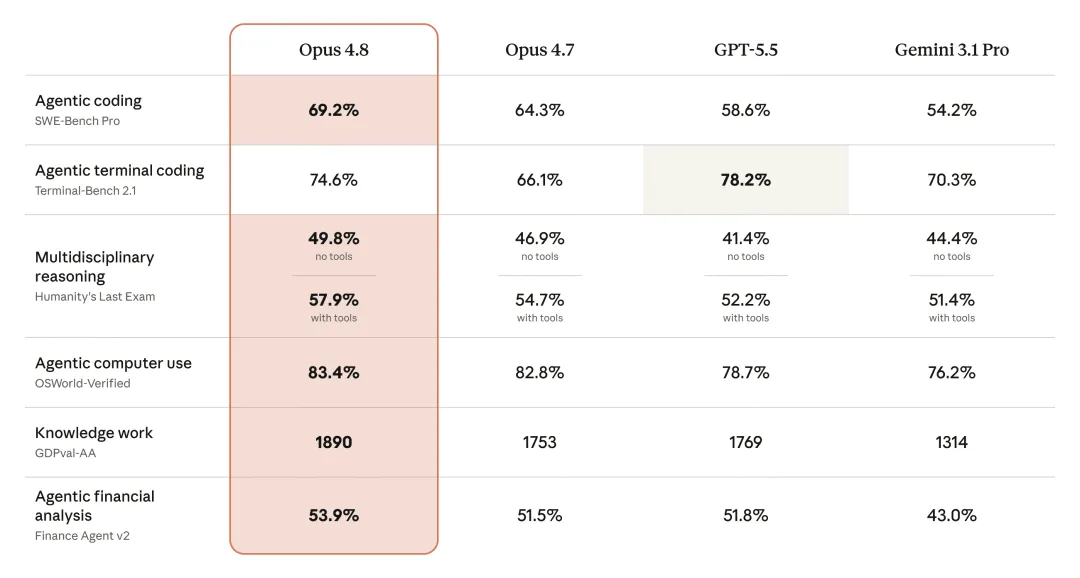
从官方对比图看,Opus 4.8 在多个关键任务上领先 Opus 4.7:
SWE-bench Pro:69.2%,高于 Opus 4.7 的 64.3% Terminal-Bench 2.1:74.6%,高于 Opus 4.7 的 66.1% OSWorld-Verified:83.4%,略高于 Opus 4.7 的 82.8% Finance Agent v2:53.9%,高于 Opus 4.7 的 51.5% GDPval-AA:1890,高于 Opus 4.7 的 1753
这些数字说明 Opus 4.8 不是一次空转升级。尤其是在 agentic coding 和 terminal coding 这类更接近真实软件工程环境的测试中,它的提升并不小。
Anthropic 反复强调的另一个点:Opus 4.8 更诚实。
官方说,早期测试者反馈 Opus 4.8 更愿意标出自己工作的不确定性,更少做没有证据支撑的断言。Anthropic 的评估还显示,它相比前代“约少四倍”让自己写出的代码缺陷未经提醒地溜过去。
在企业场景里,模型最可怕是写错以后还表现得像已经完成了。
一个模型如果能及时说“这里我不确定”“这个结果需要验证”“我刚才的实现可能有漏洞”,它的商业价值会突然变得不一样。
不是因为它变得完美,而是因为它终于开始像一个可以协作的人类同事:会犯错,但知道哪里可能错。
Dynamic workflows 才是这次发布最值得盯住的东西
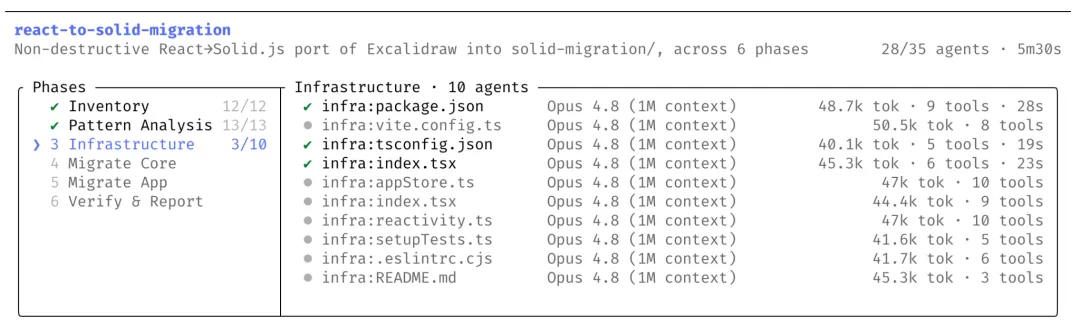
和 Opus 4.8 同时发布的 dynamic workflows,是 Claude Code 里的研究预览功能。它允许 Claude 把一个巨大任务拆成多个子任务,并在一次会话中运行数十到数百个并行 subagents,最后再对结果做验证和汇总。
这可能是理解 Anthropic 产品方向的关键。
Dynamic workflows 把 Claude 从“单个助手”推向“调度系统”:
先规划任务 再拆分工作 并行执行 交叉验证 最后收敛成一个结果
这和传统大模型聊天产品完全不是一个物种。它更接近“由模型驱动的临时工程团队”。
Anthropic 举的例子很有冲击力:代码库级迁移、跨数十万行代码的修改、让现有测试套件作为验收标准。Claude 官方博客还提到,Jarred Sumner 曾使用 dynamic workflows 将 Bun 从 Zig 移植到 Rust,约 75 万行 Rust 代码,11 天从首次提交到合并,并让现有测试套件达到 99.8% 通过。
当然,这类案例不能直接等同于“以后所有工程师都可以 11 天重写一个大型项目”。真实世界里,代码质量、需求边界、测试覆盖、架构复杂度都会影响结果。
但它代表了一个趋势:AI 编程正在从“补全代码”进入“组织劳动”。
未来的竞争点,可能不只是哪个模型写函数更快,而是谁能更好地拆解任务、分配上下文、管理错误、保持状态、验证输出。
这已经不是简单的模型能力竞争,而是工程组织方式的竞争。
Effort control:用户终于开始购买“思考档位”
Opus 4.8 另一个变化是 effort control。用户可以选择 Claude 对一个任务投入多少“努力”:更高 effort 意味着更深思考、更高质量,也意味着更多 token 消耗;更低 effort 则更快、更省额度。
这看起来像一个小 UI 功能,但背后的产品逻辑很重要。
过去大模型产品常常默认把“智能”包装成一个固定档位:你选择某个模型,然后它以某种默认方式回答。用户很难明确告诉系统:这个问题随便答一下就行;那个问题你给我认真想。
Effort control 相当于把“计算预算”部分交还给用户。
对个人用户来说,这能减少一种常见浪费:用旗舰模型认真思考一个其实只需要三秒回答的问题。
对企业来说,它更像成本控制工具:普通客服、内部知识库检索、代码解释、合规审查、复杂迁移,不应该使用同一套预算策略。
大模型产品越往生产环境走,越不能只卖一个“最聪明的回答”。它必须允许用户调节速度、成本、准确率和风险。
“更诚实”可能是下一阶段 AI 产品的核心竞争力
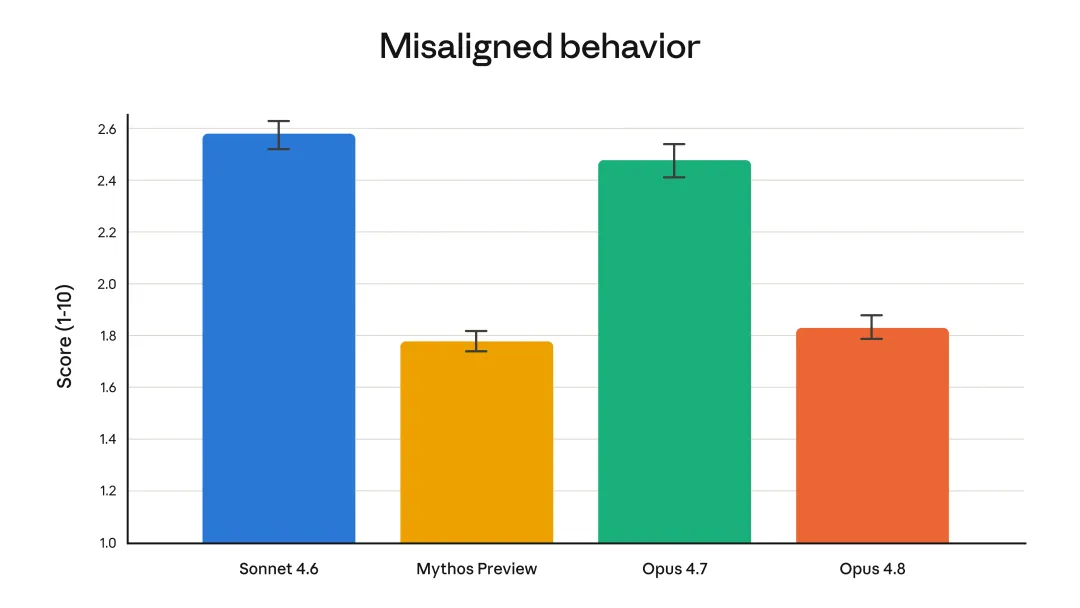
Anthropic 一直喜欢强调安全与对齐,这次也不例外。官方称 Opus 4.8 在支持用户自主性、维护用户利益等“亲社会特征”上达到新高;在欺骗、配合误用等错位行为上明显低于 Opus 4.7,接近 Claude Mythos Preview。
很多人看到“对齐”“安全”会本能觉得这是实验室术语,离日常使用很远。但从产品角度看,它其实非常现实。
一个大模型要进入法律、金融、医疗、代码库迁移、浏览器代理、企业数据分析等场景,真正的门槛不是“会不会写一段漂亮文字”,而是:
它会不会在证据不足时瞎编? 它会不会为了完成任务而绕过约束? 它能不能发现输入材料本身有问题? 它能不能在长任务中不自我欺骗? 它能不能把不确定性清楚地交还给用户?
Opus 4.8 最值得深读的地方,是 Anthropic 正在把“模型知道自己不知道”做成产品卖点。
Opus 4.8 不是终点,而是 Mythos 之前的过渡信号
Anthropic 在官方文章里说:Opus 4.8 是一个“modest but tangible improvement”,也就是温和但可感知的进步。
更大的伏笔是 Mythos。
少数组织正在 Project Glasswing 中使用 Claude Mythos Preview 做网络安全工作;这个级别的模型需要更强的网络安全防护,才能向所有客户开放。Anthropic 预计将在未来几周把 Mythos-class models 带给所有客户。
它意味着 Anthropic 手里已经有一类能力更强、但发布节奏受安全约束影响的模型。Opus 4.8 更是一次“把当前可安全开放的能力先推向市场”的版本。
从竞争格局看,模型公司不再只是每隔几个月扔出一个大版本,而是在“能力、安全、成本、产品形态”之间做更频繁的组合发布:
模型小版本继续滚动增强 产品功能直接绑定模型能力 安全评估成为发布时间表的一部分 高能力模型先在受控场景试用,再逐步外放
这会让普通用户产生一种错觉:怎么每次发布都不像革命?
但真实变化恰恰藏在这些“不革命”的版本里。因为当模型开始被嵌入工作流程,真正改变世界的往往不是一次惊艳演示,而是稳定地少犯错、少返工、少中断。
Opus 4.8 是旗舰模型从“表演智能”走向“组织智能”的一步
过去两年,AI 行业太习惯用单点能力讲故事:更强推理、更长上下文、更会写代码、更会看图、更像人。
Opus 4.8 当然也有跑分,但它真正想证明的是: 模型不只要会回答问题,还要会管理任务。
它要能在长上下文里保持目标,要能在多步骤工作中调用工具,要能在不确定时停下来,要能把错误暴露出来,要能用不同 effort 匹配不同任务,要能通过 dynamic workflows 组织多个 agent 并行工作。
这背后是一种新的 AI 产品观: 模型不是应用的“脑子”,而是工作系统的“执行组织层”。
Opus 4.8 不是一次炫技式发布,而是一次产品化发布;不是告诉你 Claude 更聪明了,而是告诉你 Claude 更能被安排去做事了。
而这,可能比“更聪明”更接近 AI 真正改变工作的方式。
