 夜雨聆风
夜雨聆风一、后摩尔时代的新范式:从几何缩放到时间缩放
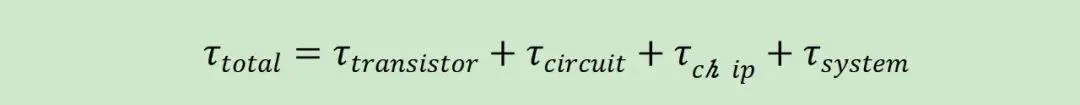
晶体管层:通过提升载流子迁移率、应变工程、高k 金属栅极及全环绕栅极(GAA)架构优化本征开关延迟,重点解决已超过本征传输时间数倍的局部互连寄生电阻和电容问题。 电路层:采用更低电阻率的导体、低k 电介质,核心通过垂直集成缩短导线长度,降低信号路径的 RC 传播延迟。 芯片层:通过架构选择、流水线深度调整、内存层次结构优化和片上网络设计,解决计算与内存访问的延迟失配。 系统层:通过重构互连拓扑、简化协议栈和优化网络结构,缩短端到端的消息传递与同步时间。
二、核心实现技术:逻辑折叠与垂直集成
晶体管密度从155 MTr/mm² 跃升至 238 MTr/mm²(百万晶体管 / 平方毫米),这一提升幅度以往需要约 3 年的几何缩放才能实现。 SoC 性能核心能效提升 41%,最大时钟频率提升近 13%。 SRAM 操作频率提升超过 40%。 时钟缓冲区减少50% 以上,时钟偏斜减少 25%。
三、AI 算力革命:α 因子与全栈系统级 τ 优化

系统互连架构(灵衢总线,Unified Bus):用单一协议取代传统多节点、多加速器架构的堆叠结构,使主要通信路径的系统τ 缩短约 500 倍。 近封装光引擎(Hi-ONE):采用高密度光互连节点,将串行器/ 解串器(SerDes)传输距离从约 100 厘米缩短到约 5 厘米,消除笨重布线,并将有效传输距离从不足 1 米扩展到 100 米,使分布式吉瓦级数据中心的高密度互连成为可能。 封装拓扑重组(3D 折叠):将原本束缚在边缘的资源迁移至垂直表面,形成垂直集成堆栈,使内存、互连、电源和逻辑同步扩展,解决传统2.5D 扇出瓶颈。
四、产业格局重构:价值重心从节点转向系统
五、现存挑战与全球产业协作
τ 原生工具链空白:全面的逻辑折叠要求工具链将多个堆叠的芯片视为单一连续设计实体,而垂直互连的寄生参数、禁区(KOZ)以及晶圆间工艺变异的相互作用,是传统二维 EDA 工具无法充分处理的。论文披露,华为已开发出初步内部工具并取得实用成果,方法学细节将在未来几个月公布,并强调 “一个 τ 原生的工具链 —— 开放的、多物理场的、三维原生的 —— 是未来 10 年最重要的赋能投资”。 能量极限制约:论文明确指出“τ 是一个时间定律,而不是焦耳定律”。性能 10 倍提升可能伴随功耗同比例增长,单个 “超级节点” 的功耗可能超出电网承载能力,正如摩尔定律遭遇物理极限一样,τ 缩放最终也将面临能量极限的制约。 制造与测试复杂性:晶圆间工艺变异、垂直互连的额外制造成本,以及适配新缩放原理的基准测试体系,均有待进一步完善。
