 夜雨聆风
夜雨聆风BERT 是自然语言处理、深度学习、Transformer、预训练语言模型和大语言模型发展史中非常重要的一个术语,全称是 Bidirectional Encoder Representations from Transformers,通常可译为“基于 Transformer 的双向编码器表示”。它用来描述一种通过大规模文本预训练得到的语言理解模型。换句话说,BERT 是在回答:模型怎样通过上下文理解一个词、一句话或一段文本的含义。
如果说传统词向量常把一个词表示成固定向量,那么 BERT 更进一步:它会根据上下文动态理解词义。例如,“苹果”在“我吃了一个苹果”和“苹果发布了新手机”中含义不同,BERT 可以根据前后文生成不同的表示。
因此,BERT 常用于文本分类、情感分析、命名实体识别、问答系统、句子匹配、文本检索、语义理解和特征表示等任务,是理解现代 NLP 预训练模型的重要基础概念之一。
一、基本概念:什么是 BERT
BERT 是一种基于 Transformer Encoder 的预训练语言模型。
它的核心思想是:先在大规模文本上学习语言规律,再迁移到具体 NLP 任务中使用。
例如,BERT 可以先从大量文本中学习:
• 词语之间的上下文关系
• 句子内部的语法结构
• 句子之间的语义关系
• 不同词在不同语境中的含义
然后再用于具体任务,例如:
• 文本分类:判断评论是正面还是负面
• 序列标注:识别人名、地名、机构名
• 问答任务:从文章中找出问题答案
• 句子匹配:判断两句话是否语义相近
从通俗角度看:BERT 像一个先读过大量文本、学会语言理解能力的“通用阅读模型”。当它被用于具体任务时,只需要在任务数据上进一步训练,就能适应不同场景。
可以简单概括为:
BERT = Transformer Encoder + 双向上下文理解 + 大规模预训练 + 下游任务微调
二、为什么需要 BERT
BERT 之所以重要,是因为它解决了传统 NLP 方法中的几个关键问题。
1、传统词向量难以表达上下文差异
早期词向量通常给每个词一个固定向量。
例如,“苹果”可能只有一个固定表示。
但在不同句子中,“苹果”的含义可能不同:
我吃了一个苹果。苹果公司发布了新手机。
第一个“苹果”是水果。
第二个“苹果”是公司。
固定词向量很难区分这种语境差异。BERT 则会根据整句话生成词的上下文表示。
从通俗角度看:传统词向量更像查词典。BERT 更像结合上下文读懂句子。
2、传统模型依赖大量任务标注数据
在 BERT 之前,很多 NLP 任务都需要为每个任务单独训练模型。
如果任务数据少,模型效果往往受限。
BERT 采用“预训练—微调”范式:
大规模无标注文本预训练 → 少量任务标注数据微调
这使模型能够先学习通用语言知识,再适配具体任务。
3、BERT 提升了语言理解任务效果
BERT 特别适合理解类任务。
例如:
• 判断文本类别
• 判断句子关系
• 识别实体边界
• 从文章中抽取答案
• 判断两句话是否相似
从通俗角度看,BERT 的价值在于:让模型不只是看词,还能理解词在上下文中的位置和含义。
三、BERT 的核心结构:Transformer Encoder
BERT 基于 Transformer Encoder。
Transformer Encoder 的核心能力是通过自注意力机制理解序列中各个 token 之间的关系。
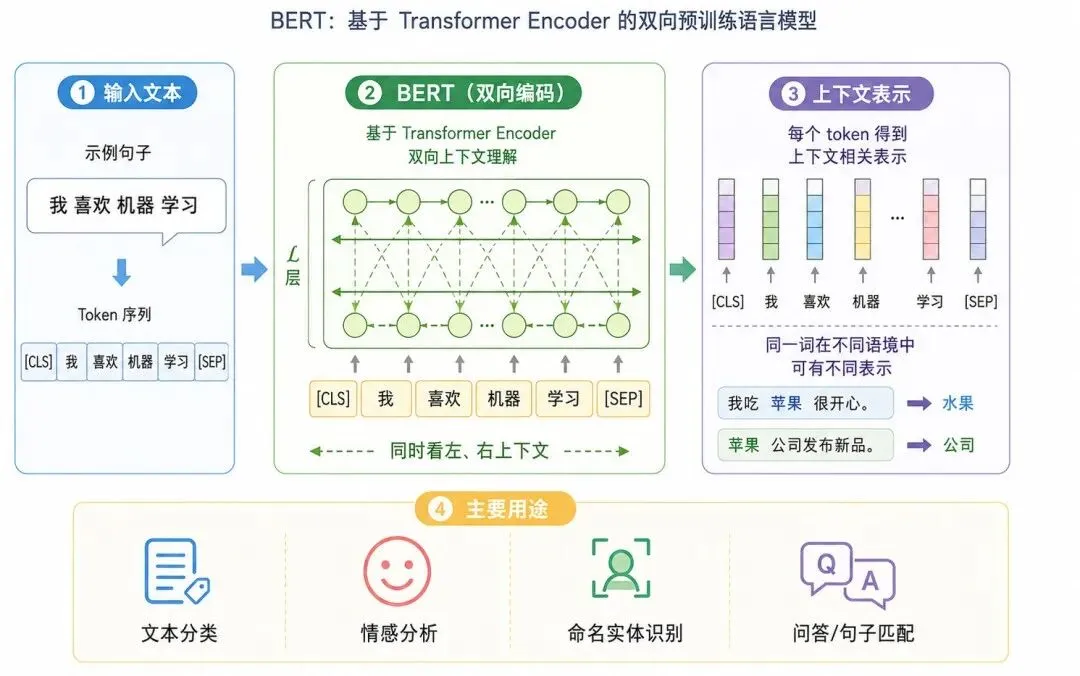
图 1:BERT 核心结构及用途
1、输入 token
一句话会先被切分成 token。
例如:
我喜欢机器学习可以被切分为若干 token:
[CLS] 我 喜欢 机器 学习 [SEP]其中:
• [CLS] 常用于表示整段文本
• [SEP] 用于分隔句子或标记输入结束
2、Embedding 输入表示
BERT 的输入表示通常由三部分相加得到:
其中:
• hᵢ⁽⁰⁾ 表示第 i 个 token 的初始输入表示
• eᵢ 表示 Token Embedding
• pᵢ 表示 Position Embedding
• sᵢ 表示 Segment Embedding
这三部分分别告诉模型:
• 当前 token 是什么
• 当前 token 在句子中的位置
• 当前 token 属于哪一句话
3、Transformer Encoder 层
BERT 由多层 Transformer Encoder 堆叠而成。
每一层都会更新 token 表示,使每个 token 能融合上下文信息。
可以简化表示为:
其中:
• H⁽ˡ⁻¹⁾ 表示上一层的 token 表示
• H⁽ˡ⁾ 表示第 l 层输出表示
从通俗角度看:BERT 会一层一层阅读句子,每一层都让词语更充分地理解周围上下文。
四、双向编码:BERT 的关键思想
BERT 名字中的 Bidirectional 表示“双向”。也就是说,BERT 在理解某个词时,可以同时看它左边和右边的上下文。
例如:
我把钱存进了银行。河边有一排柳树,旁边是银行。
理解“银行”时,只看前面的词可能不够,还需要结合后面的词。
BERT 的双向理解可以概括为:
左侧上下文 + 当前 token + 右侧上下文 → 当前 token 的语义表示
这与传统从左到右生成文本的模型不同。
1、BERT 适合理解任务
因为 BERT 可以同时看完整输入,所以它非常适合文本理解。
例如:
• 文本分类
• 情感分析
• 句子匹配
• 阅读理解
• 命名实体识别
2、BERT 不适合直接逐词生成
BERT 不是典型的自回归生成模型。它不像 GPT 那样从左到右逐 token 生成文本。
因此,BERT 通常不直接用于长文本生成,而更常用于理解、编码和判别任务。
从通俗角度看:
• BERT 更像“阅读理解模型”
• GPT 更像“文本续写模型”
五、BERT 的预训练任务
BERT 通过预训练获得通用语言理解能力。
经典 BERT 主要使用两个预训练任务:MLM 和 NSP。
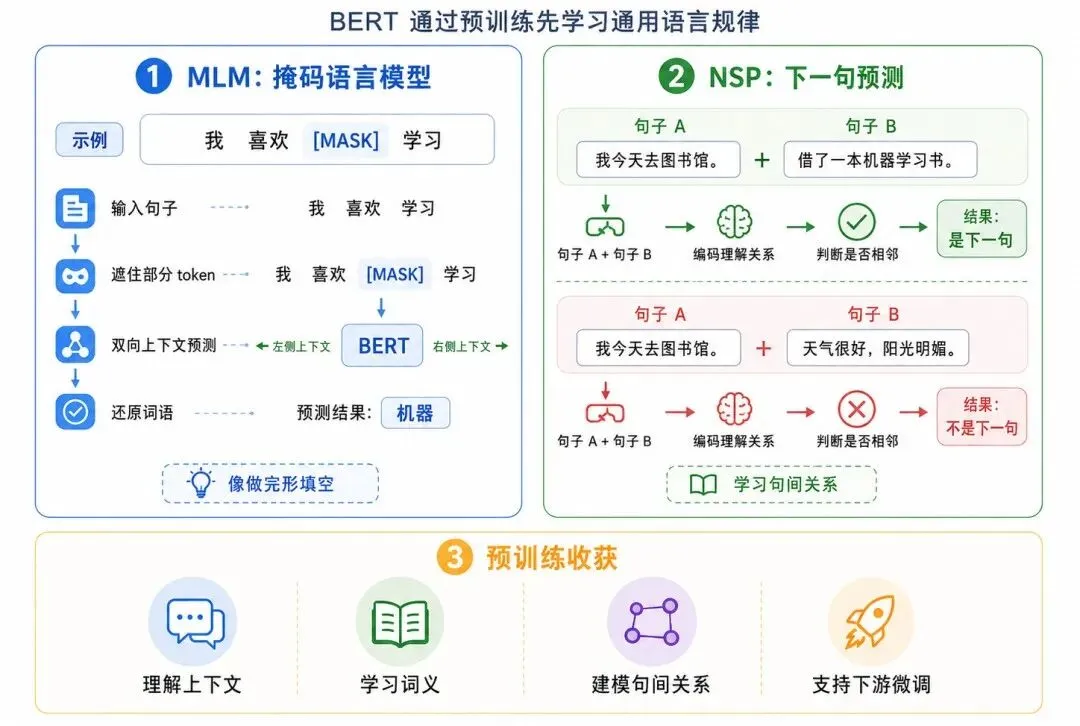
图 2:BERT 预训练任务
1、MLM:掩码语言模型
MLM 是 Masked Language Model,通常译为“掩码语言模型”。
它的做法是:随机遮住句子中的一些 token,让模型根据上下文预测被遮住的 token。
例如:
我喜欢 [MASK] 学习。模型需要预测:
机器可以简化表示为:
其中:
• xᵢ 表示被遮住的 token
• x_{\setminus i} 表示除 xᵢ 之外的上下文 token
• p 表示模型预测概率
从通俗角度看:MLM 像做完形填空。模型必须结合前后文,才能猜出被遮住的词。
2、NSP:下一句预测
NSP 是 Next Sentence Prediction,通常译为“下一句预测”。
它让模型判断两句话是否在原文中相邻。
例如:
句子 A:我今天去图书馆。句子 B:借了一本机器学习书。
模型需要判断 B 是否是 A 的下一句。
这个任务旨在帮助模型理解句子之间的关系。
需要注意:后来的许多模型对 NSP 做了改进或取消,但在经典 BERT 中,NSP 是重要预训练任务之一。
3、预训练的意义
通过 MLM 和 NSP,BERT 学会了:
• 根据上下文预测词语
• 理解词语语义
• 建立句子之间的关系
• 形成可迁移的语言表示
从通俗角度看:预训练让 BERT 先获得“语言基础能力”,再用于具体任务。
六、BERT 如何用于下游任务
BERT 的典型使用方式是微调。
基本流程是:
预训练 BERT → 添加任务层 → 在任务数据上微调
1、文本分类
对于文本分类任务,通常使用 [CLS] 对应的输出向量表示整段文本。
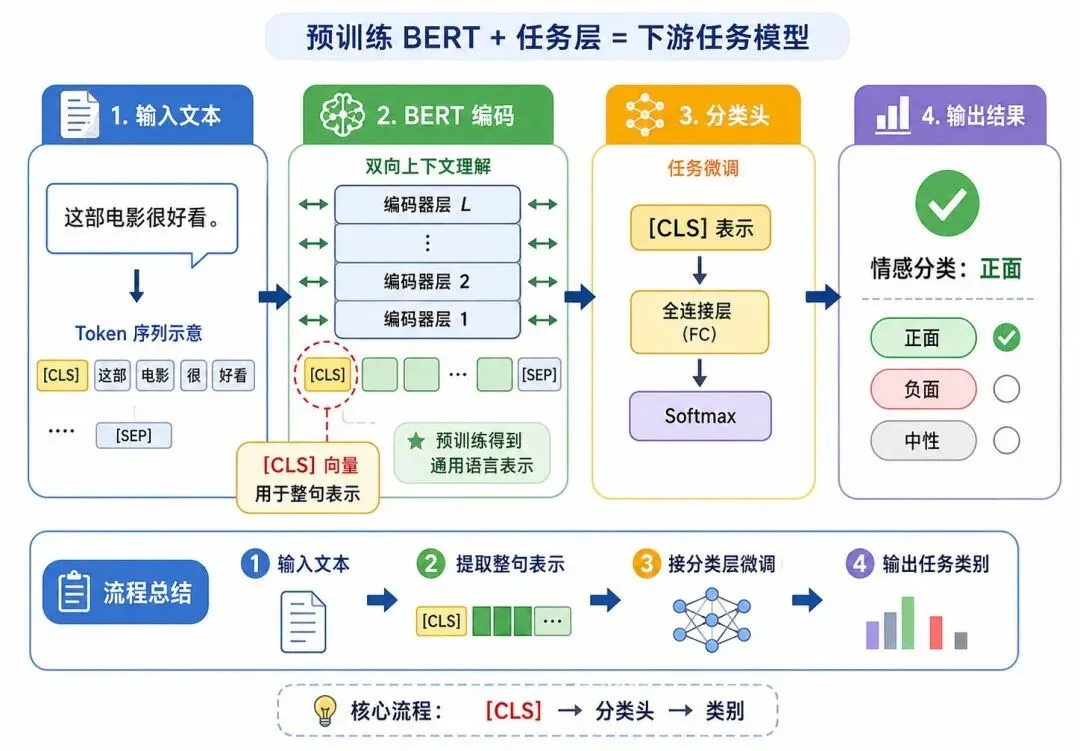
图 3:BERT 用于文本分类任务示意图
例如:
• 输入:这部电影很好看。
• 输出:正面情感
可以简化为:
其中:
• h_[CLS] 表示 [CLS] token 的最终隐藏表示
• W 和 b 表示分类层参数
• ŷ 表示预测类别分布
2、序列标注
对于命名实体识别等任务,需要对每个 token 输出一个标签。
例如:
张三 在 北京 工作B-PER O B-LOC O
BERT 会为每个 token 生成上下文表示,再接分类层预测标签。
3、阅读理解
对于抽取式问答,BERT 可以从文章中预测答案的开始位置和结束位置。
例如:
问题:谁提出了这个方法?
文章:该方法由李明提出……
答案:李明
可以简化为:预测答案起点 + 预测答案终点。
4、句子匹配
BERT 可以输入两个句子,并判断它们之间的关系。
例如:
• 是否语义相似
• 是否前后连贯
• 是否一方蕴含另一方
• 是否问答匹配
从通俗角度看:BERT 像一个通用文本理解底座,上面可以接不同任务头,完成不同 NLP 任务。
七、BERT、Transformer 与 GPT 的关系
BERT 经常与 Transformer 和 GPT 一起出现。
1、BERT 与 Transformer
Transformer 是一种神经网络结构。
BERT 使用的是 Transformer 的 Encoder 部分。
可以概括为:
• Transformer 是基础架构
• BERT 是基于 Transformer Encoder 的预训练模型
2、BERT 与 GPT
BERT 和 GPT 都基于 Transformer,但使用方式不同。
BERT 主要使用 Encoder,适合理解任务。
GPT 主要使用 Decoder,适合生成任务。
可以概括为:
• BERT:双向编码,适合理解
• GPT:单向生成,适合续写
例如:
• BERT 更适合文本分类、阅读理解、实体识别
• GPT 更适合对话、写作、代码生成、长文本生成
3、BERT 与现代大语言模型
现代大语言模型通常更偏向生成式架构。
但 BERT 仍然非常重要,因为它奠定了“预训练—微调”的范式,并且在许多理解类任务、文本编码和检索任务中仍有价值。
从通俗角度看:BERT 是阅读理解高手;GPT 是语言生成高手。
它们都来自 Transformer 思想,但训练目标和使用方式不同。
八、BERT 的优势、局限与常见误解
1、BERT 的主要优势
BERT 最大的优势是强大的上下文理解能力。
它能够:
• 根据前后文理解词义
• 生成上下文相关的 token 表示
• 适配多种 NLP 理解任务
• 利用预训练知识减少任务数据需求
• 在文本分类、实体识别、问答等任务中表现稳定
从通俗角度看:BERT 让机器从“看词”进步到“读句子、看上下文”。
2、BERT 的主要局限
BERT 也有局限。
首先,它不是专门的生成模型。
它不擅长像 GPT 那样逐 token 生成长文本。
其次,BERT 的输入长度有限。
长文档通常需要分段处理或使用专门长文本模型。
再次,BERT 的知识来自训练数据。
如果信息过时或训练数据不足,模型仍可能理解错误。
此外,BERT 的输出表示并不等于真正理解世界。
它学习的是文本模式和上下文关系,不一定具备人类意义上的常识、因果理解和真实经验。
3、常见误解
误解一:BERT = 大语言模型聊天机器人
不对。BERT 通常不是聊天生成模型,而是文本理解和表示模型。
误解二:BERT 只能做英文任务
不对。BERT 有多语言版本,也有许多中文预训练版本。
误解三:BERT 能直接生成高质量长文章
不适合。BERT 的结构和训练目标更偏向理解,不是自回归生成。
误解四:BERT 已经过时,没有价值
不准确。虽然生成式大模型更受关注,但 BERT 类模型在分类、检索、编码、序列标注等任务中仍然常用。
九、如何更好地使用 BERT
使用 BERT 时,需要根据任务选择合适方式。
1、理解类任务优先考虑 BERT
如果任务是:
• 文本分类
• 情感分析
• 命名实体识别
• 句子相似度
• 抽取式问答
• 文本编码
BERT 或 BERT 类模型通常是合适选择。
2、生成类任务不宜直接使用 BERT
如果任务是:
• 写文章
• 长对话
• 续写故事
• 生成代码
• 开放式问答
通常更适合使用 GPT 类生成模型。
3、中文任务应选择中文或多语言模型
中文任务最好使用中文预训练 BERT 或多语言模型。否则,分词、词表和语料差异可能影响效果。
4、小数据任务可先微调
如果任务标注数据较少,可以在预训练 BERT 上微调,而不是从零训练模型。
5、长文本任务要注意长度限制
BERT 的标准输入长度有限。
如果文本太长,可以考虑:
• 截断
• 滑动窗口
• 分段编码
• 长文本 Transformer
• 检索增强
从实践角度看,BERT 适合作为文本理解底座,但需要根据任务目标和数据特点合理使用。
十、Python 示例
下面给出几个简化示例,帮助理解 BERT 的基本使用方式。
示例 1:BERT 输入结构
tokens = ["[CLS]","我","喜欢","机器","学习","[SEP]"]print(tokens)
其中:
• [CLS] 通常用于整句表示
• [SEP] 用于分隔或结束输入
示例 2:掩码语言模型任务
sentence = "我喜欢 [MASK] 学习"candidates = ["机器","苹果","天气"]print("输入句子:", sentence)print("候选词:", candidates)
BERT 会根据上下文判断哪个词更适合填入 [MASK]。在这个例子中,“机器”更符合上下文。
示例 3:文本分类样本
sample = {"text": "这部电影节奏紧凑,演员表现也很好。","label": "正面"}print(sample)
文本分类任务中,BERT 会读取整段文本,并输出类别。
示例 4:命名实体识别样本
tokens = ["张三", "在", "北京", "工作"]labels = ["B-PER", "O", "B-LOC", "O"]for token, label in zip(tokens, labels):print(token, label)
BERT 可以为每个 token 生成上下文表示,再预测实体类型。
示例 5:统计 BERT 输出形状的直观理解
batch_size = 2seq_len = 8hidden_size = 768bert_output_shape = (batch_size,seq_len,hidden_size)print("BERT 输出形状:", bert_output_shape)
这个形状可以理解为:
• batch_size 表示一次处理多少条文本
• seq_len 表示每条文本有多少 token
• hidden_size 表示每个 token 的向量维度
BERT 输出的是每个 token 的上下文表示。
BERT 是基于 Transformer Encoder 的双向预训练语言模型,核心优势是根据上下文理解文本含义。它通过掩码语言模型等任务进行预训练,再通过微调用于文本分类、实体识别、阅读理解和句子匹配等任务。对初学者而言,可以把 BERT 理解为:一个擅长阅读理解和文本表示的预训练语言模型。

