 夜雨聆风
夜雨聆风故事要从一个很会干活、但总像刚睡醒的家伙说起。
这个家伙叫 AI。
你问它问题,它答得头头是道。你让它写文章,它可以一口气写几千字。你让它解释概念,它能从小学讲到大学。
看起来很聪明。
但你多用几次,就会发现它有个毛病:
它很容易像第一次见你。
昨天刚说过的要求,今天又忘了。
刚上传过的资料,换个窗口又不知道了。
你说“我喜欢短一点、接地气一点”,它下次又写成了教材。
于是,人类坐不住了。
这么能干的东西,如果每次都像刚入职第一天,那还怎么长期协作?
所以,人类开始做一件事:
想办法让 AI 记住。
但故事最精彩的地方就在这里。
AI 的“记住”,不是一个按钮。
它不像人脑那样,今天认识你,明天自然想起你。它更像一间临时办公室。
办公室里有桌子,有白板,有资料柜,有便签,有电话,也有工程师偷偷塞进去的草稿纸。
你以为大家都在做“记忆”。
其实他们在干完全不同的活。

第一批人:先给它写张便条
最早的问题不是 AI 不会干活。
而是你不说清楚,它就自己猜。
你说“帮我写一篇文章”,它不知道写给谁看。你说“帮我分析一下”,它不知道你要结论、表格、步骤,还是建议。
于是第一批人拿出一张便条:
你是谁。
你要做什么。
读者是谁。
不能做什么。
输出成什么样。
怎样才算完成。
这张便条,就是提示词工程。
提示词工程不是咒语,也不是“请深度思考”四个字打天下。
它更像给一个临时同事写工作说明。
所以它解决的是:
这一次沟通里,怎么让 AI 明白你要什么。
但便条只是便条。
便条写得好,今天干活顺。
不代表它下次一定还记得。
第二批人:桌子太小,那就换张大桌子
便条写好了,又出问题了。
AI 能看的东西太少。
你拿几页文档,它还能凑合。你拿一本书、一堆合同、一整段聊天记录,它就开始吃力。
于是第二批人说:
桌子太小,那就换张大桌子。
这就是上下文窗口。
你看到的 32K、128K、1M、2M,大概说的就是:
这一次任务里,AI 最多能看到多少内容。
桌子小,只能放几页纸。
桌子大,可以放一本书、几份资料、一段长聊天、一些工具说明。
但桌子变大以后,人类很快发现一件尴尬的事:
桌子大,不代表桌上东西有用。
旧版本、错资料、无关聊天、重复内容、过期规则,全堆上去,AI 可能看得更多,也可能乱得更彻底。
所以记住一句话:
上下文长度不是长期记忆,它只是这一次的工作空间。
第三批人:桌子大了,也得有人收拾
长上下文火了以后,很多人以为答案来了:
能塞多少塞多少。
现实很快给了大家一巴掌。
信息太多,AI 也会迷路。
资料互相矛盾,它不知道信谁。
工具结果越堆越多,它不知道哪条最新。
于是第三批人站出来:
桌子大不够,还得会摆。
这就是上下文工程。
提示词工程是写便条。
上下文工程是管理整张工作台。
什么放前面,什么放后面,什么该压缩,什么该删除,什么从知识库里找,什么从工具里查,什么只在当前任务里临时保存。
它解决的是:
不是让 AI 看最多,而是让 AI 在正确的时候看正确的东西。
这也是为什么真正能落地的 AI 应用,不只是提示词写得好。
背后通常还有资料筛选、摘要压缩、状态管理、工具结果清洗、权限控制和日志复盘。
第四批人:给它一块临时白板
如果一个任务要做很多步,AI 还得知道自己做到哪了。
比如:
先整理资料。
再判断重点。
再写大纲。
再写正文。
再检查风险。
这时候,它需要一块临时白板。
白板上写着当前目标、已完成事项、下一步、刚查到的结果、还没处理的问题。
这就是短期记忆。
短期记忆不是“它从此了解你”。
它更像当前任务的进度板。
所以它解决的是:
这件事还在进行中,AI 怎么知道当前进度。
一句话:
短期记忆是任务白板,不是人生简历。
第五批人:别老重算,先把草稿纸留下
后台工程师又发现一个问题。
AI 写答案,不是一下子吐出整篇文章。
它通常是一点一点往下写。每写下一个词元,都要参考前面已经出现过的内容。
如果每一步都从头重新算一遍前文,那就太浪费。
于是第五批人说:
别重复算。
这就是 KV Cache,也叫键值缓存。
小白可以这样理解:
KV Cache 是 AI 这一次写答案时放在旁边的计算草稿纸。
它不是保存答案。
不是保存原文。
不是保存聊天记录。
也不是让 AI 明天还记得你。
它主要解决的是:
同一次回答内部,别把前文一遍遍重算。
第六批人:如果开头一样,下次就别重读了
KV Cache 解决的是一次回答内部少重算。
但很多请求的开头都一样。
比如 AI 客服每次工作前,都要先读一大段固定规则:
你是客服助手。
退款规则如下。
投诉流程如下。
工具说明如下。
输出格式如下。
这些内容每次都一样。
如果每个用户来问问题,AI 都重新读一遍,成本很高。
于是第六批人说:
既然开头一样,那就复用开头。
这就是提示词缓存,也叫 Prompt Cache 或 Prefix Cache。
它解决的是:
多次请求之间,如果前面一大段完全相同,就尽量复用已经处理过的开头。
但它不是答案缓存。
命中提示词缓存以后,AI 仍然要处理这次新问题,也仍然要生成新答案。
它省的是相同开头的重复处理。
第七批人:有些答案,别让 AI 写了
有些问题太固定。
比如:
客服电话是多少?
营业时间是什么?
退货地址在哪里?
这种问题每次都让大模型重新生成,其实没必要。
于是第七批人说:
干脆把答案存起来。
下次再问,直接返回。
这就是答案缓存。
后来又出现了语义缓存。
普通答案缓存看“问题是不是一样”。
语义缓存看“意思是不是差不多”。
比如“你们几点下班”“客服几点结束”“晚上还能联系人工吗”,问题不完全一样,但意思接近。
不过这里有坑:
相似不等于相同。
“能不能退款”和“怎么退款”看起来接近,但业务动作可能不同。
所以语义缓存适合低风险、高重复、答案稳定的场景。
不适合医疗、法律、财务、权限、实时价格这类场景随便复用。
第八批人:脑子记不住,就建资料室
公司制度、产品手册、课程文档、合同模板、历史案例、客户 FAQ,不可能全塞进提示词,也不该指望模型背下来。
于是第八批人说:
别让它硬背。
给它建资料室。
这就是知识库和 RAG。
RAG 先不用背英文。
你只要记住:
先去资料库找,再拿着资料回答。
真正的知识库,不是把文件一丢就完事。
它至少要做几件事:
把资料拆成合适的小块。
给资料标来源、时间、版本、主题和权限。
把资料变成方便检索的形式。
用户提问时,先找相关资料。
再把找到的资料放回当前上下文。
最后让 AI 基于资料回答。
知识库解决的是:
模型训练时没有、训练后才出现、属于你自己的资料,怎么让 AI 用上。
所以“上传文档”不等于知识库。
文档堆和知识库,中间隔着整理、检索、权限、版本和验收。
第九批人:光找资料还不够,还要看关系
普通 RAG 像在资料室里找几页纸。
但有些问题,不是一页纸能解决的。
比如这个客户和哪些项目有关,这几家公司之间是什么关系,一个政策变化会影响哪些流程。
这时候,只找相似片段不够。
于是第九批人说:
不能只找纸,还要画关系网。
这就是知识图谱和 GraphRAG。
知识图谱像一张关系网:
谁和谁有关。
谁属于谁。
谁影响谁。
哪个流程连接哪个系统。
GraphRAG 则是在检索资料时,把这张关系网也用起来。
它解决的是:
当答案藏在多个文档、多个人物、多条关系之间时,AI 怎么别只看到零散片段。
但它也不是越上越高级。
关系抽取会出错,图谱维护有成本,实体命名会混乱。
如果你的业务没有清晰关系,硬上图谱只会把简单问题复杂化。
第十批人:它不只要记资料,还要记你
后来,人类发现另一个需求越来越强:
用户不只希望 AI 记资料,还希望它记住自己。
比如:
我喜欢中文。
我不喜欢假大空。
我正在做 AI 小白科普。
我写公众号要有获得感。
这就是长期记忆。
长期记忆最容易被神化。
很多人一听“长期记忆”,就以为 AI 像人一样真正了解你。
更稳的理解是:
系统帮你保存了一些以后可能还会用到的信息,需要时再拿出来放进当前上下文。
长期记忆可以记偏好、稳定事实、过去经验、做事流程和反例。
但它也会记错、过期、越权。
所以好的长期记忆不该是黑箱。
它应该能查看、能修改、能删除、能分项目隔离。
长期记忆不是越多越好。记错了,还不如不记。
第十一批人:有些东西别记,直接查
故事讲到这里,出现一个重要反转。
不是所有东西都该让 AI 记住。
比如今天库存多少、客户最新订单是什么状态、账户余额是多少、物流到哪了、今天价格有没有变。
这些信息变化太快。
让 AI 记住,反而危险。
正确做法是:
别记。
去查。
这就是工具调用、函数调用、API、MCP 的意义。
工具调用解决的是:
AI 不要凭记忆回答,而是按权限去真实系统查询或执行动作。
MCP 可以理解成一种更统一的连接方式。
它想解决的是:AI 接文件、数据库、代码仓库、业务系统时,能不能有一种更标准的插头。
但 MCP 和工具调用不是记忆本身。
它们更像电话线。
真正重要的是权限、审计、确认、回滚和安全边界。
一个能随便读文件、随便调接口、随便执行动作的 AI,不叫强大。
那叫风险。
第十二批人:把稳定习惯训练进去
再往后,人类又想到一招:
能不能把一些稳定习惯直接训练进模型?
这就是微调。
微调经常被误解成:
我把公司资料喂进去,模型就永远懂我们公司。
这不稳。
微调更适合稳定格式、稳定风格、稳定分类、稳定输出结构、特定任务表现。
它不适合频繁变化的事实。
公司制度每天改,产品价格经常变,客户信息不断更新,这些不该优先靠微调。
更稳的判断是:
事实放知识库,实时数据走工具,稳定风格和任务习惯才考虑微调。
第十三批人:把经验写成技能
还有一种“记住”,不是让模型记住。
而是让系统记住做事方法。
比如写公众号前,先判断读者问题;分析数据前,先确认数据来源;生成配图前,先判断哪张图真的有信息价值。
这类东西可以叫工作流、Skills、操作规程,也可以放进 Agent Harness 里。
它解决的是:
不要每次都让 AI 重新发明做事方法。
长期记忆记偏好。
知识库记资料。
技能文件记流程。
复盘记录记经验。
你真正想要的,不是 AI 偶尔答得好。
而是同一类任务,下次还稳定。
第十四批人:把所有人组织起来,叫智能体
终于,故事走到了智能体。
很多人把智能体讲得像万能员工。
但真实情况没那么玄。
很多所谓智能体,本质上是这些东西组合起来:
模型能力、提示词、上下文管理、短期状态、长期记忆、知识库检索、工具调用、流程编排、失败重试、日志复盘、权限控制、人工确认。
也就是说,智能体不是模型突然觉醒。
它更像一个软件工程系统。
它要知道目标是什么、先做哪一步、用哪些资料、调哪些工具、哪些动作要人确认、错误怎么发现、结果怎么验收、记忆怎么写入和删除。
如果再复杂一点,还会出现多智能体、A2A、任务总控、子任务代理。
它们解决的也不是“一个模型突然拥有神秘记忆”。
而是:
多个角色怎么分工,怎么传递上下文,怎么汇报结果,怎么避免互相污染。
这段历史,为什么 2024 年以后突然热闹?
其实很多底层思想早就有了。
RAG 在 2020 年前后已经进入研究视野。
向量检索、知识图谱、缓存、软件工作流,也都不是 2024 年才出现。
真正的变化是:
2024 年以后,这些原本偏工程、偏研究的东西,被大模型产品和智能体应用推到了普通人面前。

这条线说明了一件事:
大家不是突然爱造词。
而是同一个问题越来越大:
AI 怎么在长任务、长期项目、真实业务里,不要每次都从零开始。
小白真正该记住的,不是术语
以后你再说“我想让 AI 记住”,先别急着找工具。
先问:
你到底想让它记住什么?
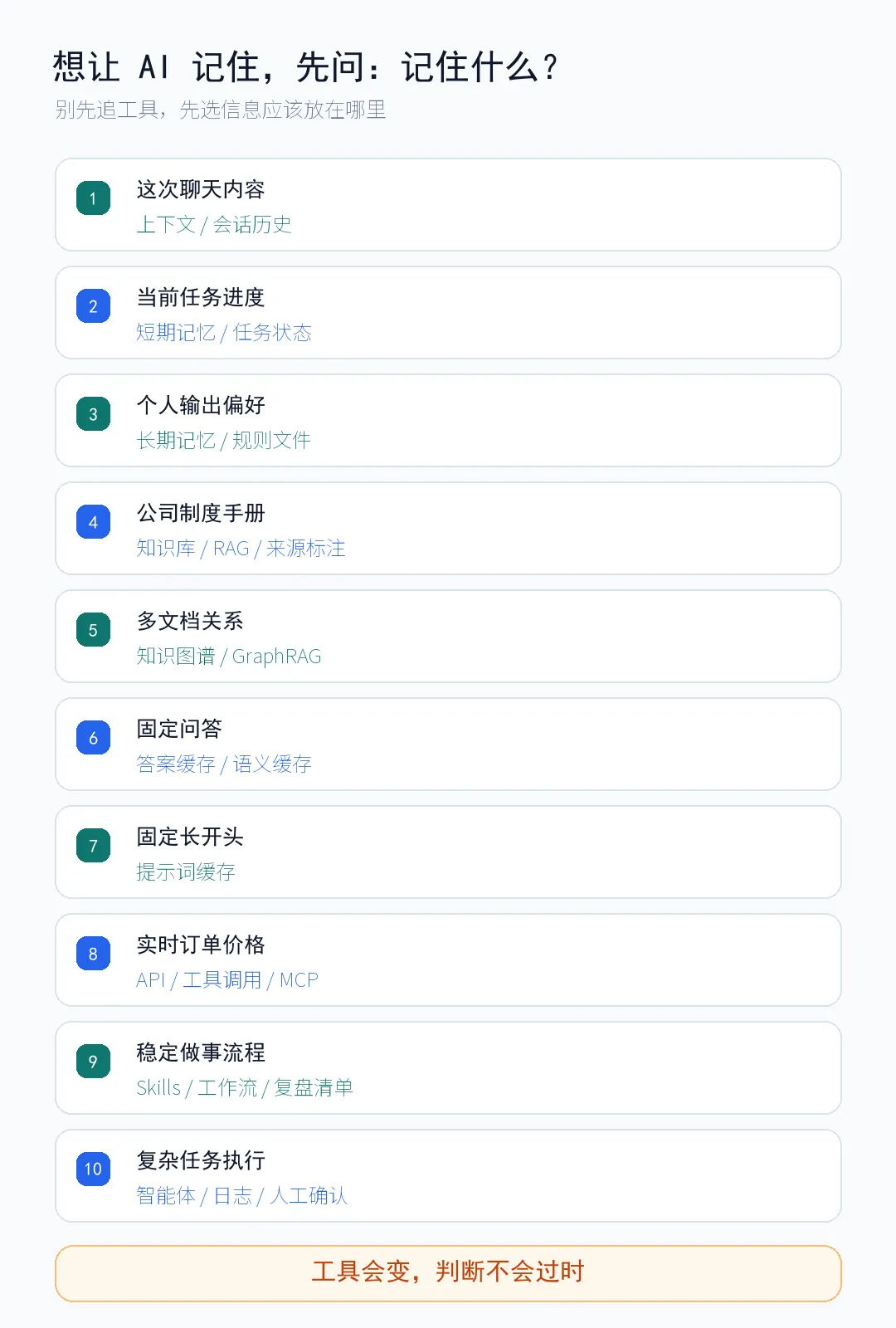
这张判断卡比工具清单更重要。
工具会变。
判断不会过时。
最容易踩的五个坑
第一个坑:
把长上下文当长期记忆。
128K、1M、2M 只是这次桌子更大,不是它以后一定记得。
第二个坑:
把缓存当记忆。
KV Cache 和提示词缓存主要是省计算、省时间、省成本,不是人格记忆。
第三个坑:
把知识库当上传文件。
真正的知识库要有拆分、索引、来源、版本、权限、更新、删除和验收。
第四个坑:
把长期记忆当事实真相。
AI 记得你的偏好,不代表它知道最新政策。偏好可以记,事实要核。
第五个坑:
把智能体当魔法。
智能体能不能干活,不取决于名字,取决于任务拆分、工具连接、上下文管理、权限边界、失败处理和人工确认。
普通人怎么开始?
你不需要一上来就搭复杂系统。
先做五张卡,就够用了。
第一张,个人偏好卡:我是谁,我常做什么,我喜欢什么输出风格,我不接受什么写法。
第二张,项目背景卡:项目目标是什么,读者是谁,目前做到哪一步,哪些资料可信,哪些结论待核。
第三张,资料卡:每份资料标清楚来源、时间、主题、适用范围,不要把所有文件乱丢给 AI。
第四张,任务拆解卡:这次目标是什么,输入是什么,输出是什么,边界是什么,怎么验收。
第五张,复盘卡:这次 AI 哪里答得好,哪里答得差,哪些规则下次要保留,哪些内容该进知识库,哪些只是临时信息。
这套东西不炫酷。
但它很有用。
因为你真正要解决的不是“我有没有 AI 工具”。
而是:
我能不能把目标、资料、规则、流程和反馈,组织成 AI 能使用的上下文。
最后的判断
这段“让 AI 记住”的历史,表面看是一堆技术名词。
提示词、上下文、缓存、知识库、长期记忆、MCP、智能体、微调、Skills。
但它们背后其实只有一个问题:
正确的信息,应该在正确的时候,以正确的方式,被 AI 使用。
该放桌面,就放桌面。
该进资料室,就进资料室。
该写偏好卡,就写偏好卡。
该留临时白板,就留临时白板。
该查真实系统,就别靠记忆。
该忘掉,就不要硬记。
真正会用 AI 的人,不是让 AI 什么都记住。
而是知道:
什么该记,什么该查,什么该删,什么只该在这次任务里出现。
为了让 AI 记住,人类做过很多事。
但最后最重要的,可能不是让它记住更多。
而是我们自己先想清楚:
到底要让它记住什么。
也欢迎留言你感兴趣的 AI 概念,我们继续用小白能听懂的话讲清楚。
