 夜雨聆风
夜雨聆风一、Task Executor核心架构
1.1 全局配置与信号处理
源码位置:rag/svr/task_executor.py:82-140
BATCH_SIZE = 64 # 第82行:批处理大小# 第84-101行:解析器工厂映射表FACTORY = {"general": naive,ParserType.NAIVE.value: naive,ParserType.PAPER.value: paper,ParserType.BOOK.value: book,ParserType.PRESENTATION.value: presentation,ParserType.MANUAL.value: manual,ParserType.LAWS.value: laws,ParserType.QA.value: qa,ParserType.TABLE.value: table,ParserType.RESUME.value: resume,ParserType.PICTURE.value: picture,ParserType.ONE.value: one,ParserType.AUDIO.value: audio,ParserType.EMAIL.value: email,ParserType.KG.value: naive, # 知识图谱使用naive解析器ParserType.TAG.value: tag}# 第103-109行:任务类型到Pipeline任务类型映射TASK_TYPE_TO_PIPELINE_TASK_TYPE = {"dataflow": PipelineTaskType.PARSE,"raptor": PipelineTaskType.RAPTOR,"graphrag": PipelineTaskType.GRAPH_RAG,"mindmap": PipelineTaskType.MINDMAP,"memory": PipelineTaskType.MEMORY,}# 第113-119行:消费者状态全局变量CONSUMER_NO = "0" if len(sys.argv) < 2 else sys.argv[1] # 第113行:消费者编号CONSUMER_NAME = "task_executor_" + CONSUMER_NO # 第114行:消费者名称BOOT_AT = datetime.now().astimezone().isoformat(timespec="milliseconds") # 第115行:启动时间PENDING_TASKS = 0 # 第116行:待处理任务数LAG_TASKS = 0 # 第117行:延迟任务数DONE_TASKS = 0 # 第118行:已完成任务数FAILED_TASKS = 0 # 第119行:失败任务数# 第121行:当前执行任务字典CURRENT_TASKS = {}# 第123-131行:并发控制信号量MAX_CONCURRENT_TASKS = int(os.environ.get('MAX_CONCURRENT_TASKS', "5")) # 第123行:最大并发任务数MAX_CONCURRENT_CHUNK_BUILDERS = int(os.environ.get('MAX_CONCURRENT_CHUNK_BUILDERS', "1")) # 第124行MAX_CONCURRENT_MINIO = int(os.environ.get('MAX_CONCURRENT_MINIO', '10')) # 第125行task_limiter = asyncio.Semaphore(MAX_CONCURRENT_TASKS) # 第126行:任务并发限制chunk_limiter = asyncio.Semaphore(MAX_CONCURRENT_CHUNK_BUILDERS) # 第127行:chunk构建限制embed_limiter = asyncio.Semaphore(MAX_CONCURRENT_CHUNK_BUILDERS) # 第128行:embedding限制minio_limiter = asyncio.Semaphore(MAX_CONCURRENT_MINIO) # 第129行:MinIO操作限制kg_limiter = asyncio.Semaphore(2) # 第130行:知识图谱限制(固定为2)WORKER_HEARTBEAT_TIMEOUT = int(os.environ.get('WORKER_HEARTBEAT_TIMEOUT', '120')) # 第131行stop_event = threading.Event() # 第132行:停止事件标志# 第135-139行:信号处理器def signal_handler(sig, frame):logging.info("Received interrupt signal, shutting down...")stop_event.set() # 第137行:设置停止标志time.sleep(1)sys.exit(0) # 第139行:优雅退出
并发控制架构图:

关键技术点:
- 解析器工厂模式
(第84-101行): FACTORY字典将ParserType枚举映射到具体解析器模块,支持动态扩展新解析器 - 多级并发控制
(第126-130行):不同资源使用不同信号量,防止资源竞争(如MinIO限制10并发,KG限制2并发) - 消费者命名机制
(第113-114行):支持多消费者并行处理,通过命令行参数 sys.argv[1]区分不同消费者实例 - 优雅退出机制
(第135-139行): signal_handler捕获中断信号,设置stop_event通知所有线程停止
1.2 进度回调与任务取消检测
源码位置:rag/svr/task_executor.py:142-174
def set_progress(task_id, from_page=0, to_page=-1, prog=None, msg="Processing..."):try:# 第144-145行:负进度表示错误if prog is not None and prog < 0:msg = "[ERROR]" + msg# 第146-150行:检测任务是否取消cancel = has_canceled(task_id)if cancel:msg += " [Canceled]"prog = -1# 第152-157行:构建进度消息if to_page > 0:if msg:if from_page < to_page:msg = f"Page({from_page + 1}~{to_page + 1}): " + msgif msg:msg = datetime.now().strftime("%H:%M:%S") + " " + msg# 第158-162行:更新数据库进度d = {"progress_msg": msg}if prog is not None:d["progress"] = progTaskService.update_progress(task_id, d)# 第164-166行:关闭数据库连接并检测取消close_connection()if cancel:raise TaskCanceledException(msg) # 第166行:抛出取消异常logging.info(f"set_progress({task_id}), progress: {prog}, progress_msg: {msg}")except TaskCanceledException:raise # 第169行:重新抛出取消异常except DoesNotExist:logging.warning(f"set_progress({task_id}) got exception DoesNotExist") # 第171行:任务不存在警告except Exception as e:logging.exception(f"set_progress({task_id}), progress: {prog}, progress_msg: {msg}, got exception: {e}")
进度回调流程图:
渲染错误: Mermaid 渲染失败: Parse error on line 3: ... B -->|是| C[msg = "[ERROR]" + msg] -----------------------^ Expecting 'SQE', 'DOUBLECIRCLEEND', 'PE', '-)', 'STADIUMEND', 'SUBROUTINEEND', 'PIPE', 'CYLINDEREND', 'DIAMOND_STOP', 'TAGEND', 'TRAPEND', 'INVTRAPEND', 'UNICODE_TEXT', 'TEXT', 'TAGSTART', got 'STR'
设计意图分析:
- 双取消检测
(第146、164-166行):在进度更新前后都检测取消状态,确保任务及时终止 - 进度消息格式化
(第152-157行): Page(from~to)格式便于追踪多页文档处理进度 - 异常分类处理
(第168-173行): TaskCanceledException重新抛出,DoesNotExist仅警告,其他异常记录完整堆栈
1.3 Redis任务收集机制
源码位置:rag/svr/task_executor.py:176-237
async def collect():global CONSUMER_NAME, DONE_TASKS, FAILED_TASKSglobal UNACKED_ITERATOR# 第180行:获取服务队列名称列表svr_queue_names = settings.get_svr_queue_names()redis_msg = Nonetry:# 第183-184行:获取未确认消息迭代器if not UNACKED_ITERATOR:UNACKED_ITERATOR = REDIS_CONN.get_unacked_iterator(svr_queue_names,SVR_CONSUMER_GROUP_NAME,CONSUMER_NAME)try:# 第186行:尝试从迭代器获取下一条消息redis_msg = next(UNACKED_ITERATOR)except StopIteration:# 第188-191行:迭代器耗尽,从队列消费者获取新消息for svr_queue_name in svr_queue_names:redis_msg = REDIS_CONN.queue_consumer(svr_queue_name,SVR_CONSUMER_GROUP_NAME,CONSUMER_NAME)if redis_msg:breakexcept Exception as e:logging.exception(f"collect got exception: {e}")return None, None # 第194行:异常时返回None# 第196-202行:消息为空或内容为空,确认并返回if not redis_msg:return None, Nonemsg = redis_msg.get_message()if not msg:logging.error(f"collect got empty message of {redis_msg.get_msg_id()}")redis_msg.ack() # 第201行:确认空消息,防止重复处理return None, None# 第204-216行:根据doc_id和task_type获取任务详情canceled = Falseif msg.get("doc_id", "") in [GRAPH_RAPTOR_FAKE_DOC_ID, CANVAS_DEBUG_DOC_ID]:task = msgif task["task_type"] in PIPELINE_SPECIAL_PROGRESS_FREEZE_TASK_TYPES:task = TaskService.get_task(msg["id"], msg["doc_ids"])if task:task["doc_id"] = msg["doc_id"]task["doc_ids"] = msg.get("doc_ids", []) or []elif msg.get("task_type") == PipelineTaskType.MEMORY.lower():_, task_obj = TaskService.get_by_id(msg["id"])task = task_obj.to_dict()else:task = TaskService.get_task(msg["id"]) # 第216行:标准任务获取# 第218-225行:检测任务是否取消或不存在if task:canceled = has_canceled(task["id"])if not task or canceled:state = "is unknown" if not task else "has been cancelled"FAILED_TASKS += 1logging.warning(f"collect task {msg['id']}{state}")redis_msg.ack() # 第224行:确认已取消或不存在的任务return None, None# 第227-236行:根据task_type补充任务字段task_type = msg.get("task_type", "")task["task_type"] = task_typeif task_type[:8] == "dataflow":task["tenant_id"] = msg["tenant_id"]task["dataflow_id"] = msg["dataflow_id"]task["kb_id"] = msg.get("kb_id", "")if task_type[:6] == "memory":task["memory_id"] = msg["memory_id"]task["source_id"] = msg["source_id"]task["message_dict"] = msg["message_dict"]return redis_msg, task # 第237行:返回Redis消息和任务对象
Redis任务收集流程图:

关键技术点:
- 未确认消息优先
(第183-186行): UNACKED_ITERATOR优先处理未确认消息,确保消息可靠性 - 多队列轮询
(第188-191行):遍历所有服务队列,确保不遗漏任何队列的任务 - 特殊任务处理
(第205-216行): GRAPH_RAPTOR_FAKE_DOC_ID和CANVAS_DEBUG_DOC_ID使用特殊逻辑获取任务 - 任务取消提前检测
(第218-225行):在任务执行前检测取消状态,避免无效处理
1.4 Chunk构建流程
源码位置:rag/svr/task_executor.py:244-515
@timeout(60 * 80, 1) # 第244行:80分钟超时装饰器async def build_chunks(task, progress_callback):# 第246-249行:文件大小检查if task["size"] > settings.DOC_MAXIMUM_SIZE:set_progress(task["id"], prog=-1, msg="File size exceeds( <= %dMb )" %(int(settings.DOC_MAXIMUM_SIZE / 1024 / 1024)))return []# 第251行:从工厂获取解析器chunker = FACTORY[task["parser_id"].lower()]try:st = timer()# 第254-255行:获取文件存储地址和二进制数据bucket, name = File2DocumentService.get_storage_address(doc_id=task["doc_id"])binary = await get_storage_binary(bucket, name) # 第255行:异步获取文件logging.info("From minio({}) {}/{}".format(timer() - st, task["location"], task["name"]))except TimeoutError:progress_callback(-1, "Internal server error: Fetch file from minio timeout. Could you try it again.")logging.exception("Minio {}/{} got timeout: Fetch file from minio timeout.".format(task["location"], task["name"]))raiseexcept Exception as e:if re.search("(No such file|not found)", str(e)):progress_callback(-1, "Can not find file <%s> from minio. Could you try it again?" % task["name"])else:progress_callback(-1, "Get file from minio: %s" % str(e).replace("'", ""))logging.exception("Chunking {}/{} got exception".format(task["location"], task["name"]))raisetry:# 第271-283行:异步调用chunker.chunkasync with chunk_limiter: # 第271行:chunk并发限制cks = await thread_pool_exec(chunker.chunk,task["name"],binary=binary,from_page=task["from_page"],to_page=task["to_page"],lang=task["language"],callback=progress_callback,kb_id=task["kb_id"],parser_config=task["parser_config"],tenant_id=task["tenant_id"],)logging.info("Chunking({}) {}/{} done".format(timer() - st, task["location"], task["name"]))except TaskCanceledException:raiseexcept Exception as e:progress_callback(-1, "Internal server error while chunking: %s" % str(e).replace("'", ""))logging.exception("Chunking {}/{} got exception".format(task["location"], task["name"]))raise# 第292-299行:初始化文档基础信息docs = []doc = {"doc_id": task["doc_id"],"kb_id": str(task["kb_id"])}if task["pagerank"]:doc[PAGERANK_FLD] = int(task["pagerank"])st = timer()# 第301-325行:上传图片到MinIO的异步函数@timeout(60)async def upload_to_minio(document, chunk):try:d = copy.deepcopy(document)d.update(chunk)# 第306-307行:生成chunk ID(xxhash)d["id"] = xxhash.xxh64((chunk["content_with_weight"] + str(d["doc_id"])).encode("utf-8", "surrogatepass")).hexdigest()d["create_time"] = str(datetime.now()).replace("T", " ")[:19]d["create_timestamp_flt"] = datetime.now().timestamp()# 第311-319行:处理图片if d.get("img_id"):docs.append(d)returnif not d.get("image"):_ = d.pop("image", None)d["img_id"] = ""docs.append(d)return# 第320行:将图片转换为ID并上传await image2id(d, partial(settings.STORAGE_IMPL.put, tenant_id=task["tenant_id"]), d["id"], task["kb_id"])docs.append(d)except Exception:logging.exception("Saving image of chunk {}/{}/{} got exception".format(task["location"], task["name"], d["id"]))raise# 第327-337行:并发上传所有chunktasks = []for ck in cks:tasks.append(asyncio.create_task(upload_to_minio(doc, ck)))try:await asyncio.gather(*tasks, return_exceptions=False)except Exception as e:logging.error(f"MINIO PUT({task['name']}) got exception: {e}")for t in tasks:t.cancel()await asyncio.gather(*tasks, return_exceptions=True)raiseel = timer() - stlogging.info("MINIO PUT({}) cost {:.3f} s".format(task["name"], el))# 第342-373行:自动关键词生成if task["parser_config"].get("auto_keywords", 0):st = timer()progress_callback(msg="Start to generate keywords for every chunk ...")chat_mdl = LLMBundle(task["tenant_id"], LLMType.CHAT, llm_name=task["llm_id"], lang=task["language"])async def doc_keyword_extraction(chat_mdl, d, topn):cached = get_llm_cache(chat_mdl.llm_name, d["content_with_weight"], "keywords", {"topn": topn})if not cached:if has_canceled(task["id"]):progress_callback(-1, msg="Task has been canceled.")returnasync with chat_limiter:cached = await keyword_extraction(chat_mdl, d["content_with_weight"], topn)set_llm_cache(chat_mdl.llm_name, d["content_with_weight"], cached, "keywords", {"topn": topn})if cached:d["important_kwd"] = cached.split(",")d["important_tks"] = rag_tokenizer.tokenize(" ".join(d["important_kwd"]))returntasks = []for d in docs:tasks.append(asyncio.create_task(doc_keyword_extraction(chat_mdl, d, task["parser_config"]["auto_keywords"])))try:await asyncio.gather(*tasks, return_exceptions=False)except Exception as e:logging.error("Error in doc_keyword_extraction: {}".format(e))for t in tasks:t.cancel()await asyncio.gather(*tasks, return_exceptions=True)raiseprogress_callback(msg="Keywords generation {} chunks completed in {:.2f}s".format(len(docs), timer() - st))# 第375-405行:自动问题生成(类似关键词生成)if task["parser_config"].get("auto_questions", 0):# ...省略类似逻辑...# 第407-448行:元数据生成if task["parser_config"].get("enable_metadata", False) and task["parser_config"].get("metadata"):# ...省略类似逻辑...# 第450-513行:标签生成if task["kb_parser_config"].get("tag_kb_ids", []):# ...省略类似逻辑...return docs # 第515行:返回所有chunk文档
Chunk构建完整流程图:
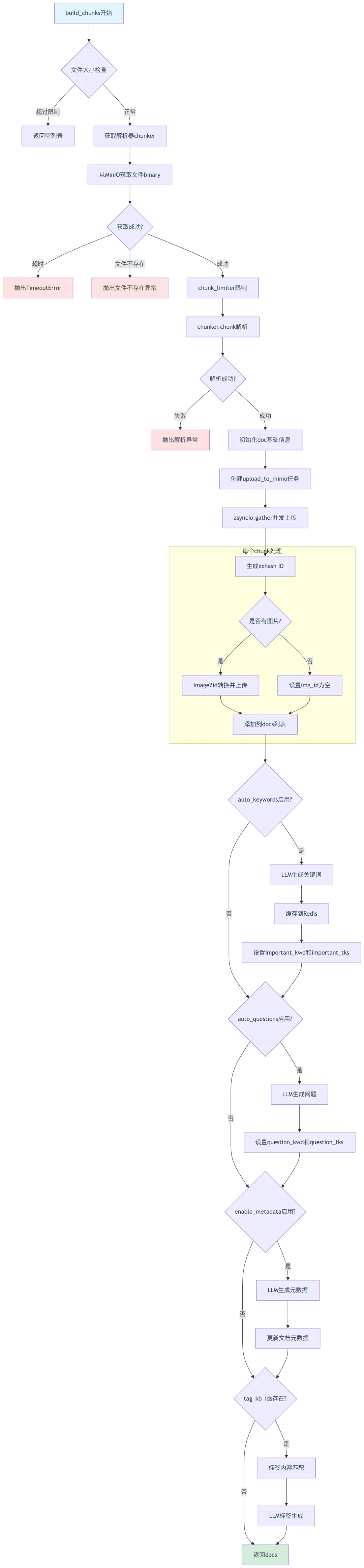
关键技术点:
- 超时装饰器
(第244行): @timeout(60 * 80, 1)设置80分钟超时,防止长时间挂起 - xxhash ID生成
(第306-307行):使用xxhash算法生成唯一ID,速度快且碰撞率低 - 并发上传MinIO
(第327-337行): asyncio.gather并发上传所有chunk图片,提升性能 - LLM缓存机制
(第348、381、413行): get_llm_cache和set_llm_cache避免重复调用LLM,节省成本
1.5 Embedding向量化流程
源码位置:rag/svr/task_executor.py:570-621
async def embedding(docs, mdl, parser_config=None, callback=None):if parser_config is None:parser_config = {}# 第573-582行:准备标题和内容文本tts, cnts = [], []for d in docs:tts.append(d.get("docnm_kwd", "Title")) # 第575行:标题文本c = "\n".join(d.get("question_kwd", [])) # 第576行:问题文本优先if not c:c = d["content_with_weight"] # 第578行:否则使用内容c = re.sub(r"</?(table|td|caption|tr|th)( [^<>]{0,12})?>", " ", c) # 第579行:去除HTML标签if not c:c = "None"cnts.append(c)tk_count = 0# 第585-588行:标题向量化(复用第一个向量)if len(tts) == len(cnts):vts, c = await thread_pool_exec(mdl.encode, tts[0:1])tts = np.tile(vts[0], (len(cnts), 1)) # 第587行:复制标题向量到所有chunktk_count += c# 第590-593行:批量编码函数(带截断)@timeout(60)def batch_encode(txts):nonlocal mdlreturn mdl.encode([truncate(c, mdl.max_length - 10) for c in txts])# 第595-605行:分批向量化cnts_ = np.array([])for i in range(0, len(cnts), settings.EMBEDDING_BATCH_SIZE):async with embed_limiter: # 第597行:embedding并发限制vts, c = await thread_pool_exec(batch_encode, cnts[i: i + settings.EMBEDDING_BATCH_SIZE])if len(cnts_) == 0:cnts_ = vtselse:cnts_ = np.concatenate((cnts_, vts), axis=0) # 第602行:NumPy拼接tk_count += ccallback(prog=0.7 + 0.2 * (i + 1) / len(cnts), msg="") # 第604行:进度回调cnts = cnts_# 第606-613行:标题权重融合filename_embd_weight = parser_config.get("filename_embd_weight", 0.1)if not filename_embd_weight:filename_embd_weight = 0.1title_w = float(filename_embd_weight)if tts.ndim == 2 and cnts.ndim == 2 and tts.shape == cnts.shape:vects = title_w * tts + (1 - title_w) * cnts # 第611行:加权融合else:vects = cnts# 第615-620行:将向量添加到文档assert len(vects) == len(docs)vector_size = 0for i, d in enumerate(docs):v = vects[i].tolist()vector_size = len(v)d["q_%d_vec" % len(v)] = v # 第620行:动态字段名q_1024_vecreturn tk_count, vector_size
Embedding向量化流程图:
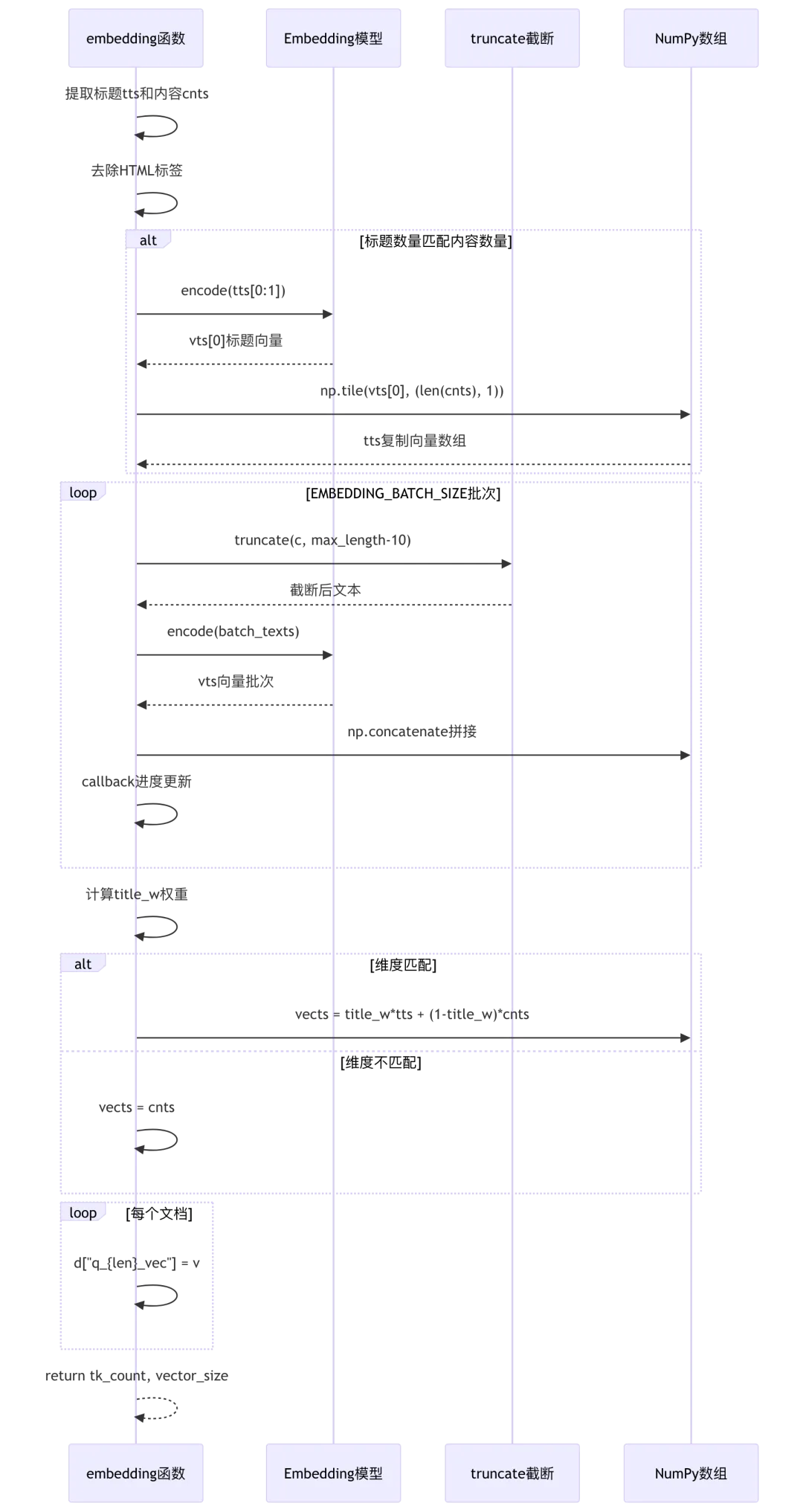
关键技术点:
- 标题向量复用
(第587行): np.tile(vts[0], (len(cnts), 1))所有chunk共享同一标题向量,节省计算 - 文本截断保护
(第593行): truncate(c, mdl.max_length - 10)预留10个token防止边界溢出 - 加权向量融合
(第611行): title_w * tts + (1 - title_w) * cnts标题和内容向量加权融合,默认标题权重0.1 - 动态字段名
(第620行): d["q_%d_vec" % len(v)]根据向量维度动态生成字段名(如q_1024_vec)
1.6 RAPTOR递归摘要处理
源码位置:rag/svr/task_executor.py:765-859
@timeout(3600) # 第765行:1小时超时async def run_raptor_for_kb(row, kb_parser_config, chat_mdl, embd_mdl, vector_size, callback=None, doc_ids=[]):fake_doc_id = GRAPH_RAPTOR_FAKE_DOC_ID # 第767行:虚拟文档IDraptor_config = kb_parser_config.get("raptor", {})vctr_nm = "q_%d_vec" % vector_size # 第770行:向量字段名res = []tk_count = 0max_errors = int(os.environ.get("RAPTOR_MAX_ERRORS", 3)) # 第774行:最大错误数# 第776-809行:generate函数定义async def generate(chunks, did):nonlocal tk_count, resraptor = Raptor(raptor_config.get("max_cluster", 64), # 第779行:最大聚类数chat_mdl,embd_mdl,raptor_config["prompt"],raptor_config["max_token"],raptor_config["threshold"],max_errors=max_errors,)original_length = len(chunks)chunks = await raptor(chunks, kb_parser_config["raptor"]["random_seed"], callback, row["id"]) # 第788行:调用Raptor# 第789-797行:构建文档基础信息doc = {"doc_id": did,"kb_id": [str(row["kb_id"])],"docnm_kwd": row["name"],"title_tks": rag_tokenizer.tokenize(row["name"]),"raptor_kwd": "raptor" # 第794行:标记为raptor chunk}if row["pagerank"]:doc[PAGERANK_FLD] = int(row["pagerank"])# 第799-809行:添加新生成的摘要chunkfor content, vctr in chunks[original_length:]:d = copy.deepcopy(doc)d["id"] = xxhash.xxh64((content + str(fake_doc_id)).encode("utf-8")).hexdigest()d["create_time"] = str(datetime.now()).replace("T", " ")[:19]d["create_timestamp_flt"] = datetime.now().timestamp()d[vctr_nm] = vctr.tolist()d["content_with_weight"] = contentd["content_ltks"] = rag_tokenizer.tokenize(content)d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])res.append(d)tk_count += num_tokens_from_string(content)# 第811-834行:file scope处理(每个文档单独处理)if raptor_config.get("scope", "file") == "file":for x, doc_id in enumerate(doc_ids):chunks = []skipped_chunks = 0# 第815-823行:从文档存储获取chunksfor d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],fields=["content_with_weight", vctr_nm],sort_by_position=True):if vctr_nm not in d or d[vctr_nm] is None:skipped_chunks += 1logging.warning(f"RAPTOR: Chunk missing vector field '{vctr_nm}' in doc {doc_id}, skipping")continuechunks.append((d["content_with_weight"], np.array(d[vctr_nm])))if skipped_chunks > 0:callback(msg=f"[WARN] Skipped {skipped_chunks} chunks without vector field '{vctr_nm}' for doc {doc_id}.")if not chunks:logging.warning(f"RAPTOR: No valid chunks with vectors found for doc {doc_id}")callback(msg=f"[WARN] No valid chunks with vectors found for doc {doc_id}, skipping")continueawait generate(chunks, doc_id)callback(prog=(x + 1.) / len(doc_ids))# 第835-857行:knowledge base scope处理(所有文档合并处理)else:chunks = []skipped_chunks = 0for doc_id in doc_ids:for d in settings.retriever.chunk_list(doc_id, row["tenant_id"], [str(row["kb_id"])],fields=["content_with_weight", vctr_nm],sort_by_position=True):if vctr_nm not in d or d[vctr_nm] is None:skipped_chunks += 1continuechunks.append((d["content_with_weight"], np.array(d[vctr_nm])))if skipped_chunks > 0:callback(msg=f"[WARN] Skipped {skipped_chunks} chunks without vector field '{vctr_nm}'.")if not chunks:logging.error(f"RAPTOR: No valid chunks with vectors found in any document for kb {row['kb_id']}")callback(msg=f"[ERROR] No valid chunks with vectors found.")return res, tk_countawait generate(chunks, fake_doc_id)return res, tk_count
RAPTOR处理流程图:
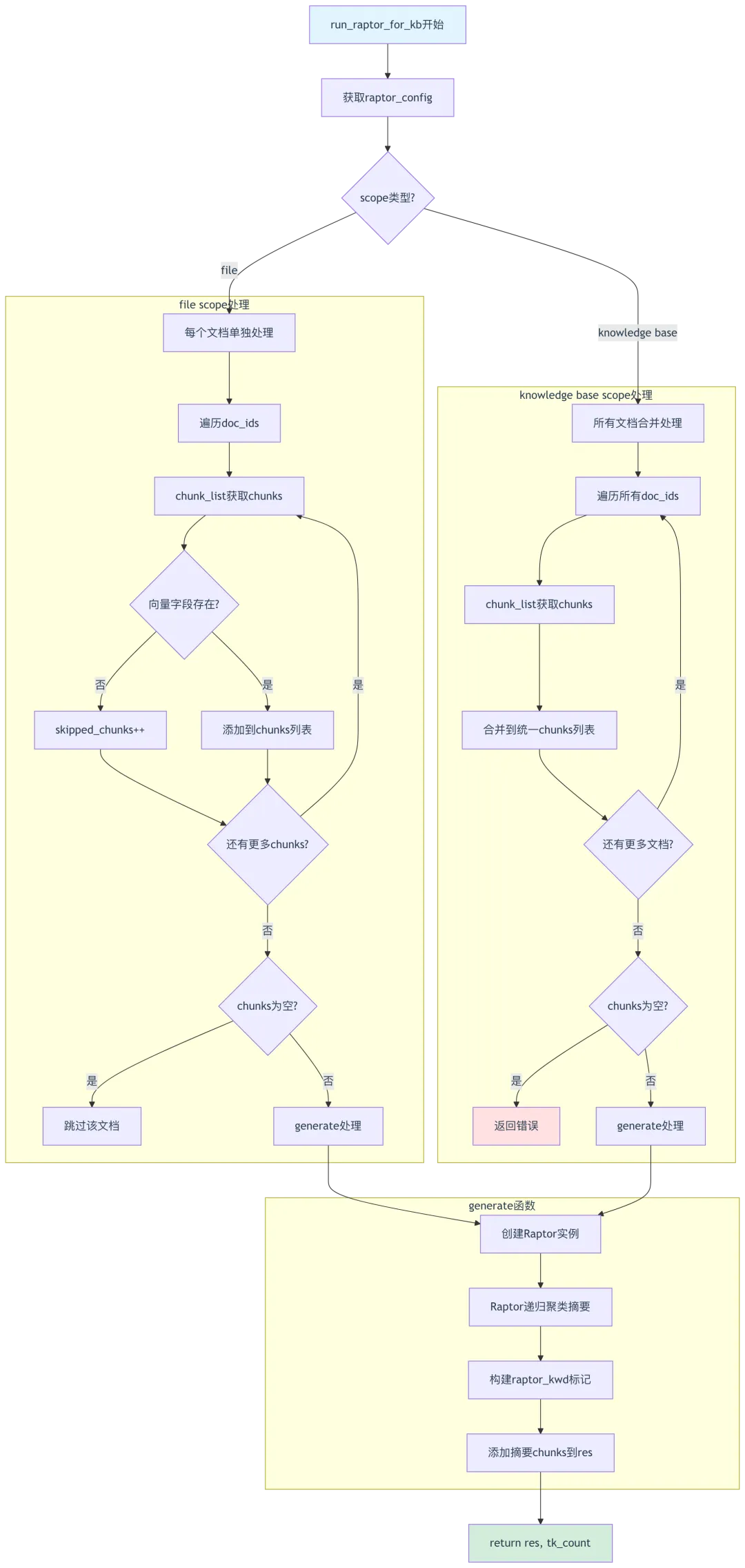
关键技术点:
- 双scope模式
(第811、835行): filescope每个文档独立处理,knowledge basescope所有文档合并处理 - 向量字段检查
(第819、843行):跳过缺少向量字段的chunk,防止后续处理错误 - raptor_kwd标记
(第794行): "raptor_kwd": "raptor"标识摘要chunk,便于检索时区分 - max_errors限制
(第774行): RAPTOR_MAX_ERRORS环境变量控制最大错误数,防止无限重试
二、NLP检索与分词系统
2.1 RagTokenizer分词器
源码位置:rag/nlp/rag_tokenizer.py:18-57
import infinity.rag_tokenizerclass RagTokenizer(infinity.rag_tokenizer.RagTokenizer): # 第18行:继承infinity分词器def tokenize(self, line: str) -> str:from common import settings # 第21行:延迟导入避免循环依赖if settings.DOC_ENGINE_INFINITY:return line # 第23行:Infinity引擎直接返回原文else:return super().tokenize(line) # 第25行:调用父类分词def fine_grained_tokenize(self, tks: str) -> str:from common import settingsif settings.DOC_ENGINE_INFINITY:return tks # 第30行:Infinity引擎直接返回else:return super().fine_grained_tokenize(tks) # 第32行:细粒度分词# 第35-44行:工具函数包装def is_chinese(s):return infinity.rag_tokenizer.is_chinese(s)def is_number(s):return infinity.rag_tokenizer.is_number(s)def is_alphabet(s):return infinity.rag_tokenizer.is_alphabet(s)def naive_qie(txt):return infinity.rag_tokenizer.naive_qie(txt)# 第51-57行:全局实例和函数绑定tokenizer = RagTokenizer()tokenize = tokenizer.tokenize # 第52行:绑定实例方法fine_grained_tokenize = tokenizer.fine_grained_tokenizetag = tokenizer.tagfreq = tokenizer.freqtradi2simp = tokenizer._tradi2simp # 第56行:繁体转简体strQ2B = tokenizer._strQ2B # 第57行:全角转半角
分词器继承关系图:
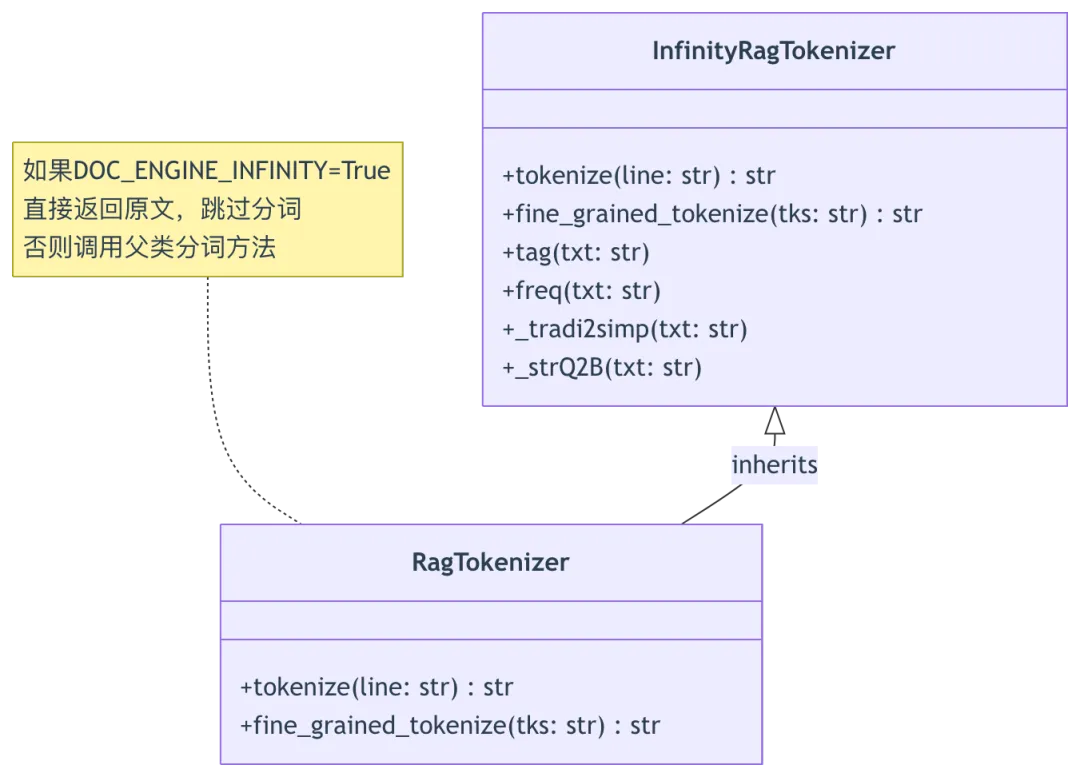
设计意图分析:
- 引擎适配
(第22-25、29-32行):Infinity引擎内置分词功能,直接返回原文;其他引擎需要显式分词 - 延迟导入
(第21、28行): from common import settings延迟导入避免循环依赖 - 函数绑定
(第52-57行):将实例方法绑定到模块级函数,简化调用(如 rag_tokenizer.tokenize(text))
2.2 FulltextQueryer全文查询构建
源码位置:rag/nlp/query.py:27-172
class FulltextQueryer(QueryBase):def __init__(self):self.tw = term_weight.Dealer() # 第29行:词权重计算器self.syn = synonym.Dealer() # 第30行:同义词查找器self.query_fields = [ # 第31-39行:查询字段列表(带权重)"title_tks^10", # 标题权重10"title_sm_tks^5", # 标题细粒度权重5"important_kwd^30", # 重要关键词权重30"important_tks^20", # 重要token权重20"question_tks^20", # 问题token权重20"content_ltks^2", # 内容长token权重2"content_sm_ltks", # 内容细粒度token权重1]def question(self, txt, tbl="qa", min_match: float = 0.6):original_query = txt# 第43-48行:文本预处理txt = self.add_space_between_eng_zh(txt) # 第43行:中英文添加空格txt = re.sub(r"[ :|\r\n\t,,。??/`!!&^%%()\[\]{}<>]+"," ",rag_tokenizer.tradi2simp(rag_tokenizer.strQ2B(txt.lower())), # 第47行:繁体转简体、全角转半角、小写).strip()otxt = txttxt = self.rmWWW(txt) # 第50行:去除www前缀# 第52-86行:非中文处理if not self.is_chinese(txt):txt = self.rmWWW(txt)tks = rag_tokenizer.tokenize(txt).split()keywords = [t for t in tks if t]tks_w = self.tw.weights(tks, preprocess=False) # 第56行:计算词权重tks_w = [(re.sub(r"[ \\\"'^]", "", tk), w) for tk, w in tks_w]tks_w = [(re.sub(r"^[\+-]", "", tk), w) for tk, w in tks_w if tk]tks_w = [(tk.strip(), w) for tk, w in tks_w if tk.strip()]syns = []for tk, w in tks_w[:256]:syn = [rag_tokenizer.tokenize(s) for s in self.syn.lookup(tk)] # 第62行:查找同义词keywords.extend(syn)syn = ["\"{}\"^{:.4f}".format(s, w / 4.) for s in syn if s.strip()]syns.append(" ".join(syn))# 第67-80行:构建查询字符串q = ["({}^{:.4f}".format(tk, w) + " {})".format(syn) for (tk, w), syn in zip(tks_w, syns) iftk and not re.match(r"[.^+\(\)-]", tk)]for i in range(1, len(tks_w)):left, right = tks_w[i - 1][0].strip(), tks_w[i][0].0].strip()if not left or not right:continueq.append('"%s %s"^%.4f'% (tks_w[i - 1][0],tks_w[i][0],max(tks_w[i - 1][1], tks_w[i][1]) * 2, # 第78行:相邻词组合权重翻倍))if not q:q.append(txt)query = " ".join(q)return MatchTextExpr(self.query_fields, query, 100, {"original_query": original_query}), keywords# 第88-172行:中文处理(省略详细逻辑)def need_fine_grained_tokenize(tk):if len(tk) < 3:return Falseif re.match(r"[0-9a-z\.\+#_\*-]+$", tk):return Falsereturn Truetxt = self.rmWWW(txt)qs, keywords = [], []for tt in self.tw.split(txt)[:256]:# ...中文分词和查询构建逻辑...if qs:query = " OR ".join([f"({t})" for t in qs if t])if not query:query = otxtreturn MatchTextExpr(self.query_fields, query, 100, {"minimum_should_match": min_match, "original_query": original_query}), keywordsreturn None, keywords
查询构建流程图:
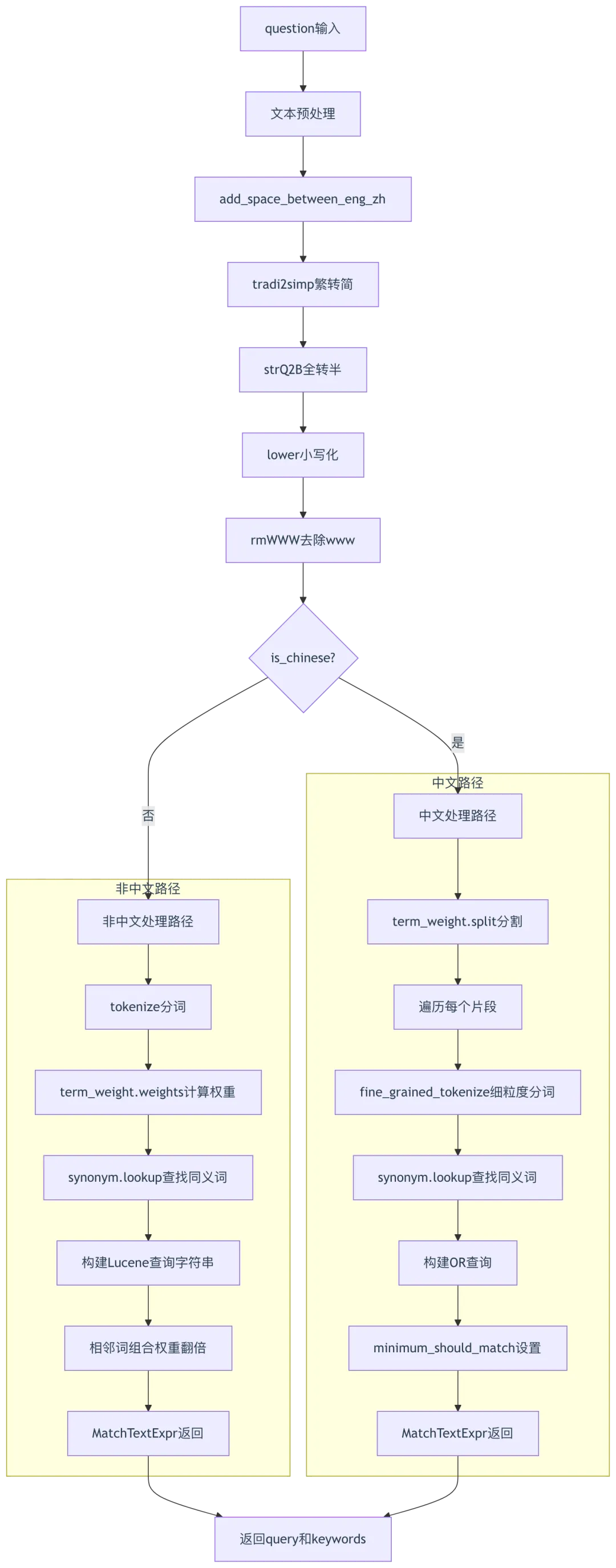
关键技术点:
- 字段权重配置
(第31-39行): title_tks^10表示标题字段权重10,important_kwd^30重要关键词权重最高 - 同义词扩展
(第62、102行): self.syn.lookup(tk)查找同义词并添加到查询,提升召回率 - 相邻词组合
(第69-80行):相邻词组合权重翻倍,如"machine learning"组合权重高于单独的"machine"和"learning" - minimum_should_match
(第170行): min_match参数控制至少匹配的词数比例,防止召回过多无关文档
2.3 Dealer检索器核心
源码位置:rag/nlp/search.py:36-171
class Dealer:def __init__(self, dataStore: DocStoreConnection):self.qryr = query.FulltextQueryer() # 第38行:全文查询构建器self.dataStore = dataStore # 第39行:文档存储连接@dataclassclass SearchResult: # 第41-50行:搜索结果数据类total: intids: list[str]query_vector: list[float] | None = Nonefield: dict | None = Nonehighlight: dict | None = Noneaggregation: list | dict | None = Nonekeywords: list[str] | None = Nonegroup_docs: list[list] | None = Noneasync def get_vector(self, txt, emb_mdl, topk=10, similarity=0.1):qv, _ = await thread_pool_exec(emb_mdl.encode_queries, txt) # 第53行:异步编码查询shape = np.array(qv).shapeif len(shape) > 1:raise Exception(f"Dealer.get_vector returned array's shape {shape} doesn't match expectation.")embedding_data = [get_float(v) for v in qv]vector_column_name = f"q_{len(embedding_data)}_vec" # 第59行:动态向量字段名return MatchDenseExpr(vector_column_name, embedding_data, 'float', 'cosine', topk, {"similarity": similarity})def get_filters(self, req): # 第62-72行:构建过滤条件condition = dict()for key, field in {"kb_ids": "kb_id", "doc_ids": "doc_id"}.items():if key in req and req[key] is not None:condition[field] = req[key]for key in ["knowledge_graph_kwd", "available_int", "entity_kwd", "from_entity_kwd", "to_entity_kwd", "removed_kwd"]:if key in req and req[key] is not None:condition[key] = req[key]return conditionasync def search(self, req, idx_names: str | list[str], kb_ids: list[str], emb_mdl=None, highlight: bool | list | None = None, rank_feature: dict | None = None):if highlight is None:highlight = Falsefilters = self.get_filters(req) # 第83行:获取过滤条件orderBy = OrderByExpr()pg = int(req.get("page", 1)) - 1topk = int(req.get("topk", 1024))ps = int(req.get("size", topk))offset, limit = pg * ps, ps# 第91-95行:设置返回字段src = req.get("fields", ["docnm_kwd", "content_ltks", "kb_id", "img_id", "title_tks", "important_kwd", "position_int","doc_id", "page_num_int", "top_int", "create_timestamp_flt", "knowledge_graph_kwd","question_kwd", "question_tks", "doc_type_kwd", "available_int", "content_with_weight", "mom_id", PAGERANK_FLD, TAG_FLD])kwds = set([])qst = req.get("question", "")q_vec = []if not qst: # 第100-107行:无查询字符串,仅排序if req.get("sort"):orderBy.asc("page_num_int")orderBy.asc("top_int")orderBy.desc("create_timestamp_flt")res = self.dataStore.search(src, [], filters, [], orderBy, offset, limit, idx_names, kb_ids)total = self.dataStore.get_total(res)else:highlightFields = ["content_ltks", "title_tks"]if not highlight:highlightFields = []elif isinstance(highlight, list):highlightFields = highlightmatchText, keywords = self.qryr.question(qst, min_match=0.3) # 第114行:构建全文查询if emb_mdl is None: # 第115-120行:仅全文检索matchExprs = [matchText]res = await thread_pool_exec(self.dataStore.search, src, highlightFields, filters, matchExprs, orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)total = self.dataStore.get_total(res)else: # 第121-147行:混合检索(全文+向量)matchDense = await self.get_vector(qst, emb_mdl, topk, req.get("similarity", 0.1))q_vec = matchDense.embedding_dataif not settings.DOC_ENGINE_INFINITY:src.append(f"q_{len(q_vec)}_vec")fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05,0.95"}) # 第127行:融合权重(全文5%,向量95%)matchExprs = [matchText, matchDense, fusionExpr]res = await thread_pool_exec(self.dataStore.search, src, highlightFields, filters, matchExprs, orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)total = self.dataStore.get_total(res)# 第136-147行:结果为空时降低阈值重试if total == 0:if filters.get("doc_id"):res = await thread_pool_exec(self.dataStore.search, src, [], filters, [], orderBy, offset, limit, idx_names, kb_ids)total = self.dataStore.get_total(res)else:matchText, _ = self.qryr.question(qst, min_match=0.1) # 第141行:降低min_matchmatchDense.extra_options["similarity"] = 0.17 # 第142行:降低similarityres = await thread_pool_exec(self.dataStore.search, src, highlightFields, filters, [matchText, matchDense, fusionExpr], orderBy, offset, limit, idx_names, kb_ids, rank_feature=rank_feature)total = self.dataStore.get_total(res)for k in keywords:kwds.add(k)for kk in rag_tokenizer.fine_grained_tokenize(k).split():if len(kk) < 2:continueif kk in kwds:continuekwds.add(kk)logging.debug(f"TOTAL: {total}")ids = self.dataStore.get_doc_ids(res)keywords = list(kwds)highlight = self.dataStore.get_highlight(res, keywords, "content_with_weight")aggs = self.dataStore.get_aggregation(res, "docnm_kwd")return self.SearchResult(total=total,ids=ids,query_vector=q_vec,aggregation=aggs,highlight=highlight,field=self.dataStore.get_fields(res, src + ["_score"]),keywords=keywords)
混合检索流程图:
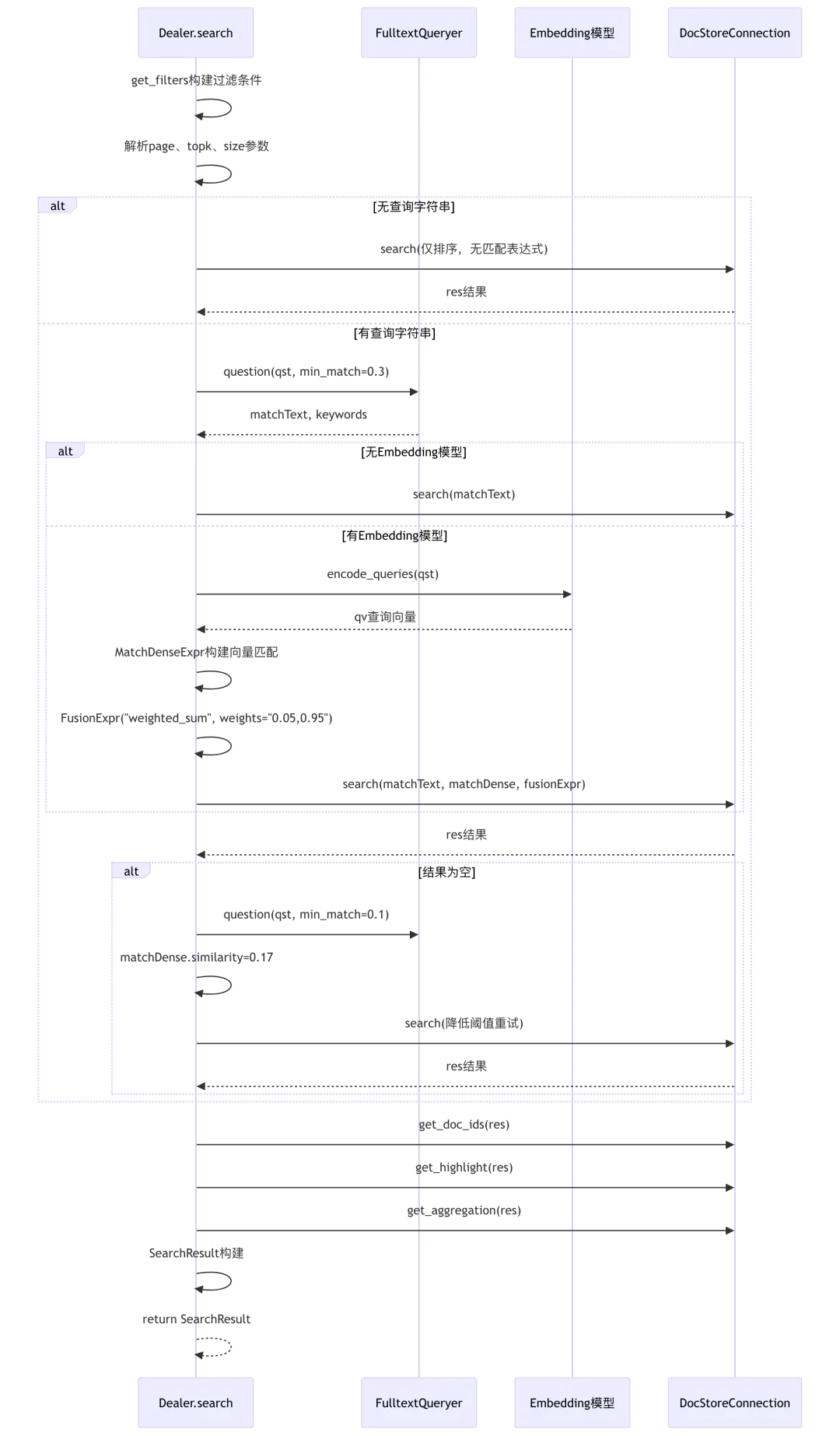
关键技术点:
- 混合检索融合权重
(第127行): "weights": "0.05,0.95"全文检索权重5%,向量检索权重95%,向量检索占主导 - 降级重试机制
(第136-147行):结果为空时降低 min_match从0.3到0.1,降低similarity从0.1到0.17,提升召回率 - 细粒度关键词扩展
(第149-156行):对每个关键词进行细粒度分词,扩展关键词集合 - 动态向量字段
(第59、125行): f"q_{len(embedding_data)}_vec"根据向量维度动态选择字段
2.4 Rerank重排序机制
源码位置:rag/nlp/search.py:294-354
def rerank(self, sres, query, tkweight=0.3, vtweight=0.7, cfield="content_ltks", rank_feature: dict | None = None):_, keywords = self.qryr.question(query)vector_size = len(sres.query_vector)vector_column = f"q_{vector_size}_vec"zero_vector = [0.0] * vector_size# 第302-307行:提取候选文档向量ins_embd = []for chunk_id in sres.ids:vector = sres.field[chunk_id].get(vector_column, zero_vector)if isinstance(vector, str):vector = [get_float(v) for v in vector.split("\t")] # 第306行:字符串向量解析ins_embd.append(vector)if not ins_embd:return [], [], []# 第311-321行:构建token列表(带权重)for i in sres.ids:if isinstance(sres.field[i].get("important_kwd", []), str):sres.field[i]["important_kwd"] = [sres.field[i]["important_kwd"]]ins_tw = []for i in sres.ids:content_ltks = list(OrderedDict.fromkeys(sres.field[i][cfield].split())) # 第316行:去重保持顺序title_tks = [t for t in sres.field[i].get("title_tks", "").split() if t]question_tks = [t for t in sres.field[i].get("question_tks", "").split() if t]important_kwd = sres.field[i].get("important_kwd", [])tks = content_ltks + title_tks * 2 + important_kwd * 5 + question_tks * 6 # 第320行:权重乘法复制ins_tw.append(tks)# 第323-324行:计算rank feature分数rank_fea = self._rank_feature_scores(rank_feature, sres)# 第326-329行:混合相似度计算sim, tksim, vtsim = self.qryr.hybrid_similarity(sres.query_vector, ins_embd, keywords, ins_tw, tkweight, vtweight)return sim + rank_fea, tksim, vtsim # 第331行:相似度加上rank featuredef rerank_by_model(self, rerank_mdl, sres, query, tkweight=0.3, vtweight=0.7, cfield="content_ltks", rank_feature: dict | None = None):_, keywords = self.qryr.question(query)for i in sres.ids:if isinstance(sres.field[i].get("important_kwd", []), str):sres.field[i]["important_kwd"] = [sres.field[i]["important_kwd"]]ins_tw = []for i in sres.ids:content_ltks = sres.field[i][cfield].split()title_tks = [t for t in sres.field[i].get("title_tks", "").split() if t]important_kwd = sres.field[i].get("important_kwd", [])tks = content_ltks + title_tks + important_kwdins_tw.append(tks)tksim = self.qryr.token_similarity(keywords, ins_tw) # 第349行:token相似度vtsim, _ = rerank_mdl.similarity(query, [remove_redundant_spaces(" ".join(tks)) for tks in ins_tw]) # 第350行:模型重排序rank_fea = self._rank_feature_scores(rank_feature, sres)return tkweight * np.array(tksim) + vtweight * vtsim + rank_fea, tksim, vtsim # 第354行:加权融合
Rerank重排序流程图:
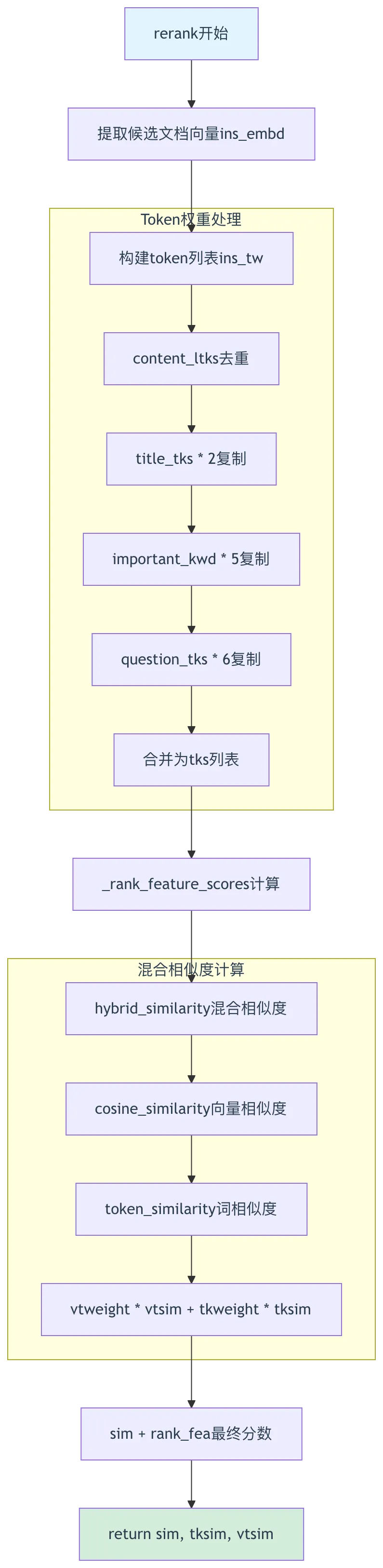
关键技术点:
- Token权重复制
(第320行): title_tks * 2 + important_kwd * 5 + question_tks * 6通过列表乘法实现权重复制 - 混合相似度融合
(第326-329行): hybrid_similarity融合向量相似度和token相似度 - Rank Feature加分
(第324、331行): rank_fea包含PageRank和Tag特征,提升重要文档排名 - 模型重排序
(第350行): rerank_mdl.similarity调用外部重排序模型(如Cohere、Jina)
三、GraphRAG知识图谱构建
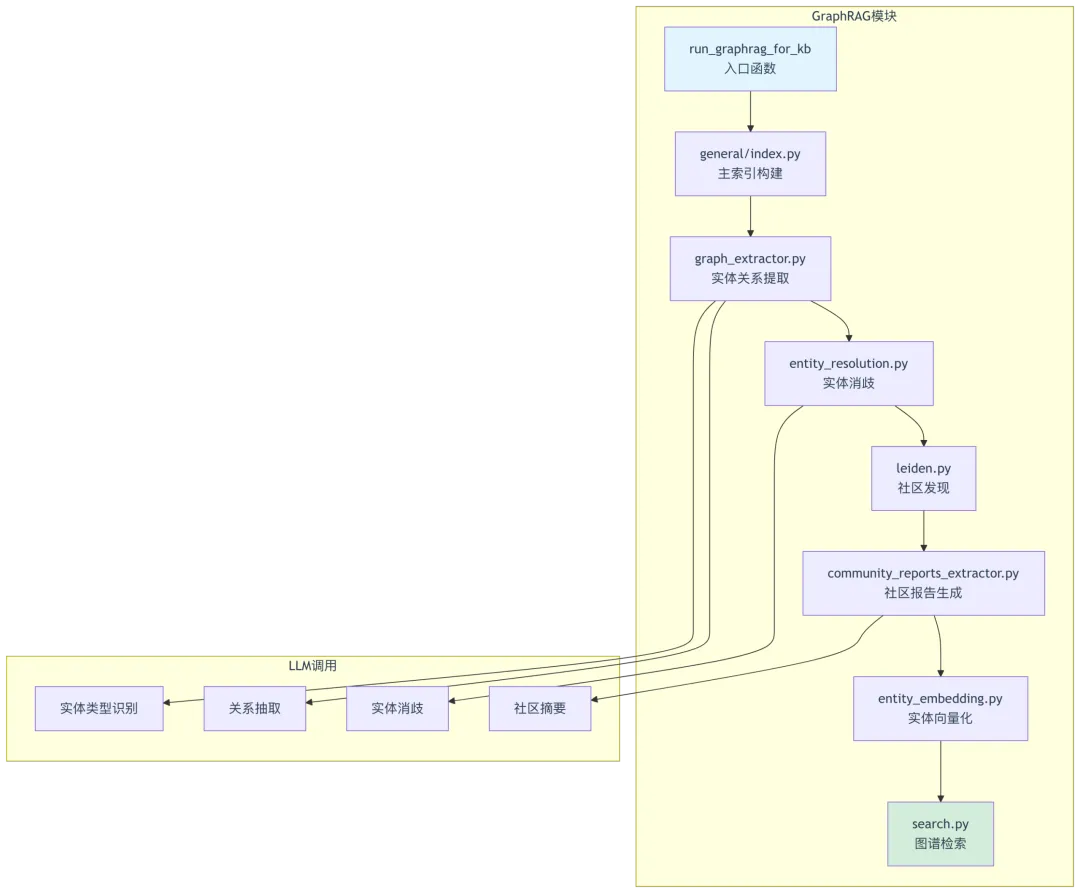
3.1 GraphRAG文件结构
rag/graphrag/├── __init__.py├── entity_resolution.py # 实体消歧├── entity_resolution_prompt.py # 实体消歧提示词├── query_analyze_prompt.py # 查询分析提示词├── search.py # 图谱检索├── utils.py # 工具函数(缓存等)├── light/ # 轻量级图谱方法│ ├── __init__.py│ ├── graph_extractor.py # 图提取器│ ├── graph_prompt.py # 图提取提示词│ └── smoke.py # 测试脚本└── general/ # 通用图谱方法├── __init__.py├── community_reports_extractor.py # 社区报告提取器├── community_report_prompt.py # 社区报告提示词├── entity_embedding.py # 实体向量化├── extractor.py # 基础提取器├── graph_extractor.py # 图提取器├── graph_prompt.py # 图提取提示词├── index.py # 主索引构建入口├── leiden.py # Leiden社区发现算法├── mind_map_extractor.py # 思维导图提取器├── mind_map_prompt.py # 思维导图提示词└── smoke.py # 测试脚本
GraphRAG架构图:
3.2 GraphRAG任务执行流程
源码位置:rag/svr/task_executor.py:1055-1102
elif task_type == "graphrag":ok, kb = KnowledgebaseService.get_by_id(task_dataset_id)if not ok:progress_callback(prog=-1.0, msg="Cannot found valid dataset for GraphRAG task")returnkb_parser_config = kb.parser_config# 第1062-1080行:GraphRAG配置初始化if not kb_parser_config.get("graphrag", {}).get("use_graphrag", False):kb_parser_config.update({"graphrag": {"use_graphrag": True,"entity_types": [ # 第1067-1073行:默认实体类型"organization","person","geo","event","category",],"method": "light", # 第1074行:默认使用light方法}})if not KnowledgebaseService.update_by_id(kb.id, {"parser_config": kb_parser_config}):progress_callback(prog=-1.0, msg="Internal error: Invalid GraphRAG configuration")returngraphrag_conf = kb_parser_config.get("graphrag", {})start_ts = timer()chat_model = LLMBundle(task_tenant_id, LLMType.CHAT, llm_name=kb_task_llm_id, lang=task_language)with_resolution = graphrag_conf.get("resolution", False) # 第1085行:是否启用实体消歧with_community = graphrag_conf.get("community", False) # 第1086行:是否启用社区发现async with kg_limiter: # 第1087行:知识图谱并发限制result = await run_graphrag_for_kb(row=task,doc_ids=task.get("doc_ids", []),language=task_language,kb_parser_config=kb_parser_config,chat_model=chat_model,embedding_model=embedding_model,callback=progress_callback,with_resolution=with_resolution,with_community=with_community,)logging.info(f"GraphRAG task result for task {task}:\n{result}")progress_callback(prog=1.0, msg="Knowledge Graph done ({:.2f}s)".format(timer() - start_ts))return
GraphRAG执行流程图:
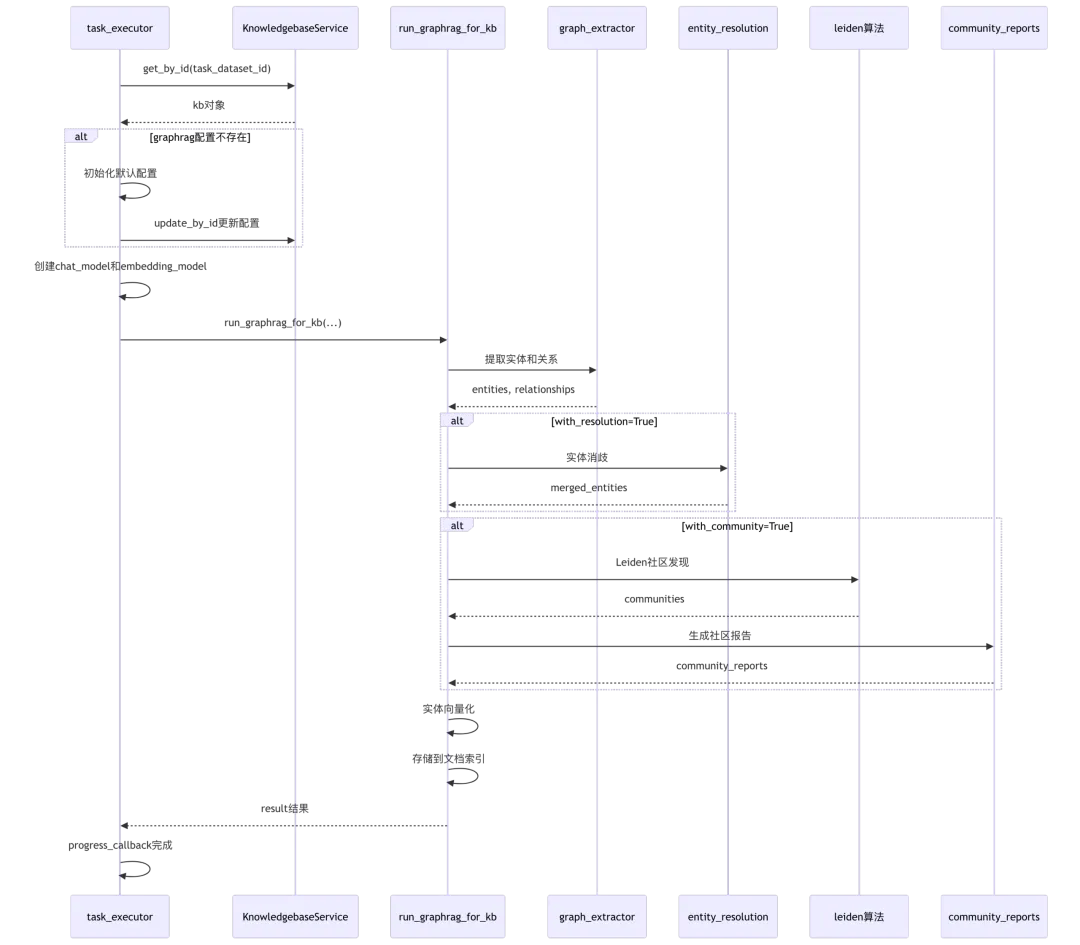
关键技术点:
- 默认实体类型
(第1067-1073行): ["organization", "person", "geo", "event", "category"]覆盖常见实体类型 - 双模式支持
(第1074行): method: "light"轻量级方法,另有"general"通用方法 - 可选高级功能
(第1085-1086行): resolution实体消歧和community社区发现可选启用 - kg_limiter限制
(第1087行):知识图谱任务并发限制为2,防止LLM调用过载
四、Agent组件系统
4.1 Agent组件文件结构
agent/component/├── __init__.py├── base.py # 组件基类├── begin.py # 开始节点├── llm.py # LLM调用组件├── message.py # 消息组件├── categorize.py # 分类组件├── switch.py # 分支组件├── loop.py # 循环组件├── loopitem.py # 循环项├── exit_loop.py # 退出循环├── iteration.py # 迭代组件├── iterationitem.py # 迭代项├── invoke.py # 调用组件├── fillup.py # 填充组件├── string_transform.py # 字符串转换├── data_operations.py # 数据操作├── list_operations.py # 列表操作├── variable_assigner.py # 变量赋值├── varaiable_aggregator.py # 变量聚合├── agent_with_tools.py # 带工具的Agent├── excel_processor.py # Excel处理└── docs_generator.py # 文档生成
Agent组件分类图:

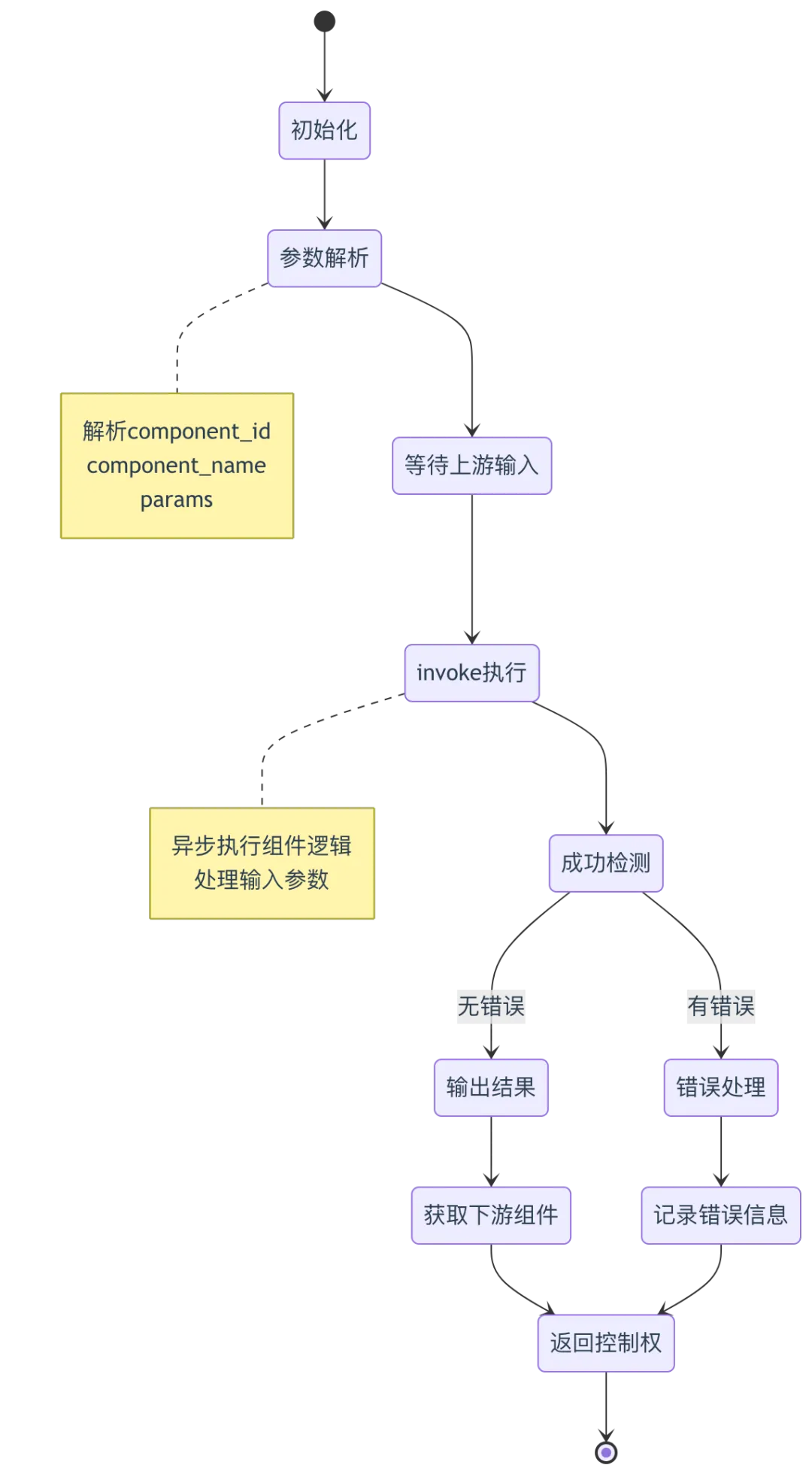
4.2 Agent组件基类设计
源码位置:agent/component/base.py(推测结构)
class ComponentBase:def __init__(self, component_id, component_name, params):self._id = component_idself.component_name = component_nameself.params = paramsself._output = {}self._error = ""async def invoke(self, **kwargs):raise NotImplementedError("Subclasses must implement invoke method")def output(self):return self._outputdef error(self):return self._errordef get_downstream(self):# 返回下游组件ID列表return self.params.get("downstream", [])
组件生命周期图:
五、完整任务处理流程
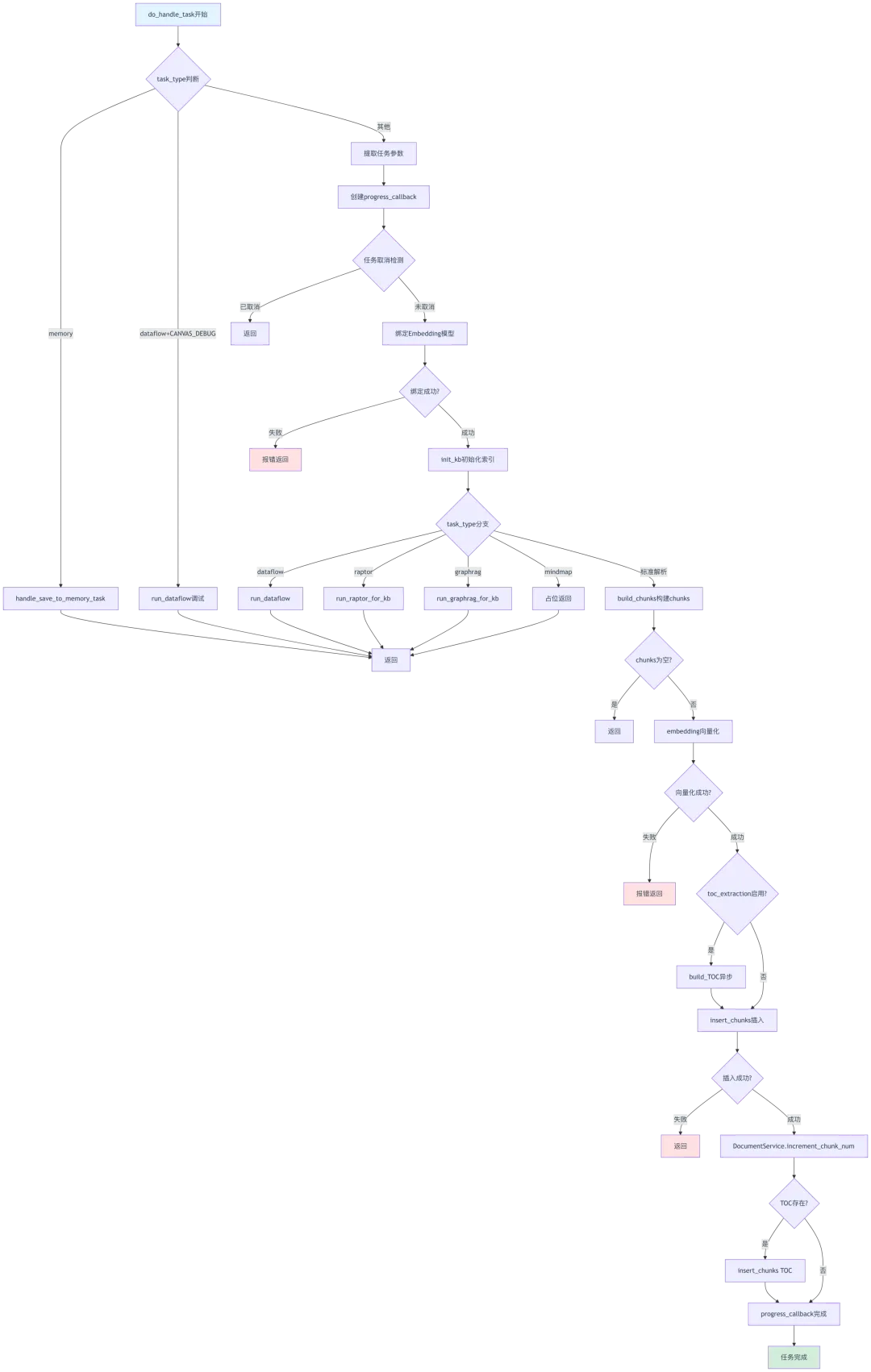
5.1 do_handle_task主处理函数
源码位置:rag/svr/task_executor.py:949-1192
@timeout(60 * 60 * 3, 1) # 第949行:3小时超时async def do_handle_task(task):task_type = task.get("task_type", "")# 第953-955行:memory任务特殊处理if task_type == "memory":await handle_save_to_memory_task(task)return# 第957-959行:Canvas调试任务特殊处理if task_type == "dataflow" and task.get("doc_id", "") == CANVAS_DEBUG_DOC_ID:await run_dataflow(task)return# 第961-979行:提取任务参数task_id = task["id"]task_from_page = task["from_page"]task_to_page = task["to_page"]task_tenant_id = task["tenant_id"]task_embedding_id = task["embd_id"]task_language = task["language"]doc_task_llm_id = task["parser_config"].get("llm_id") or task["llm_id"]kb_task_llm_id = task['kb_parser_config'].get("llm_id") or task["llm_id"]task['llm_id'] = kb_task_llm_idtask_dataset_id = task["kb_id"]task_doc_id = task["doc_id"]task_document_name = task["name"]task_parser_config = task["parser_config"]task_start_ts = timer()toc_thread = Noneexecutor = concurrent.futures.ThreadPoolExecutor()# 第979行:创建进度回调函数progress_callback = partial(set_progress, task_id, task_from_page, task_to_page)# 第981-984行:检测任务取消task_canceled = has_canceled(task_id)if task_canceled:progress_callback(-1, msg="Task has been canceled.")returntry:# 第987-995行:绑定Embedding模型embedding_model = LLMBundle(task_tenant_id, LLMType.EMBEDDING, llm_name=task_embedding_id, lang=task_language)vts, _ = embedding_model.encode(["ok"])vector_size = len(vts[0])except Exception as e:error_message = f'Fail to bind embedding model: {str(e)}'progress_callback(-1, msg=error_message)logging.exception(error_message)raiseinit_kb(task, vector_size) # 第997行:初始化知识库索引# 第999-1001行:dataflow任务处理if task_type[:len("dataflow")] == "dataflow":await run_dataflow(task)return# 第1003-1053行:raptor任务处理(见前文)if task_type == "raptor":# ...RAPTOR处理逻辑...# 第1055-1102行:graphrag任务处理(见前文)elif task_type == "graphrag":# ...GraphRAG处理逻辑...# 第1103-1106行:mindmap任务处理elif task_type == "mindmap":progress_callback(1, "place holder")passreturn# 第1107-1178行:标准文档解析任务else:task['llm_id'] = doc_task_llm_idstart_ts = timer()chunks = await build_chunks(task, progress_callback) # 第1111行:构建chunkslogging.info("Build document {}: {:.2f}s".format(task_document_name, timer() - start_ts))if not chunks:progress_callback(1., msg=f"No chunk built from {task_document_name}")returnprogress_callback(msg="Generate {} chunks".format(len(chunks)))start_ts = timer()try:token_count, vector_size = await embedding(chunks, embedding_model, task_parser_config, progress_callback) # 第1119行:向量化except TaskCanceledException:raiseexcept Exception as e:error_message = "Generate embedding error:{}".format(str(e))progress_callback(-1, error_message)logging.exception(error_message)token_count = 0raiseprogress_message = "Embedding chunks ({:.2f}s)".format(timer() - start_ts)logging.info(progress_message)progress_callback(msg=progress_message)# 第1131-1132行:TOC提取(可选)if task["parser_id"].lower() == "naive" and task["parser_config"].get("toc_extraction", False):toc_thread = executor.submit(build_TOC, task, chunks, progress_callback)chunk_count = len(set([chunk["id"] for chunk in chunks]))start_ts = timer()# 第1137-1142行:插入chunks辅助函数async def _maybe_insert_chunks(_chunks):if has_canceled(task_id):progress_callback(-1, msg="Task has been canceled.")return Falseinsert_result = await insert_chunks(task_id, task_tenant_id, task_dataset_id, _chunks, progress_callback)return bool(insert_result)try:if not await _maybe_insert_chunks(chunks): # 第1145行:插入chunksreturnif has_canceled(task_id):progress_callback(-1, msg="Task has been canceled.")returnlogging.info("Indexing doc({}), page({}-{}), chunks({}), elapsed: {:.2f}".format(task_document_name, task_from_page, task_to_page, len(chunks), timer() - start_ts))DocumentService.increment_chunk_num(task_doc_id, task_dataset_id, token_count, chunk_count, 0) # 第1157行:更新文档统计progress_callback(msg="Indexing done ({:.2f}s).".format(timer() - start_ts))# 第1161-1166行:TOC插入if toc_thread:d = toc_thread.result()if d:if not await _maybe_insert_chunks([d]):returnDocumentService.increment_chunk_num(task_doc_id, task_dataset_id, 0, 1, 0)if has_canceled(task_id):progress_callback(-1, msg="Task has been canceled.")returntask_time_cost = timer() - task_start_tsprogress_callback(prog=1.0, msg="Task done ({:.2f}s)".format(task_time_cost))logging.info("Chunk doc({}), page({}-{}), chunks({}), token({}), elapsed:{:.2f}".format(task_document_name, task_from_page, task_to_page, len(chunks), token_count, task_time_cost))finally:# 第1180-1192行:清理逻辑(取消时删除已插入chunks)if has_canceled(task_id):# ...删除逻辑...
完整任务处理流程图:
六、设计模式与技术决策总结
6.1 核心设计模式统计表
| 工厂模式 | |||
| 装饰器模式 | |||
| 信号量模式 | |||
| 回调模式 | |||
| 策略模式 | |||
| 模板方法 | |||
| 数据类 |
6.2 技术决策对比表
| 任务队列 | |||
| 并发控制 | |||
| 超时机制 | |||
| 向量融合权重 | |||
| ID生成 | |||
| 分词引擎 | |||
| GraphRAG方法 |
6.3 性能优化关键点
Task Executor优化:
- 多级并发限制
(第126-130行):不同资源使用不同信号量,精细化控制并发 - 异步任务收集
(第176-237行): collect函数异步获取任务,避免阻塞主线程 - 批量Embedding
(第596-605行): EMBEDDING_BATCH_SIZE批量向量化,减少API调用次数 - LLM缓存
(第348、381、413行): get_llm_cache避免重复调用LLM,节省成本和时间
NLP检索优化:
- 同义词扩展
(第62、102行):扩展查询词,提升召回率 - 降级重试
(第136-147行):结果为空时降低阈值重试,平衡召回率和准确率 - Token权重复制
(第320行): title_tks * 2通过列表乘法实现权重,简单高效 - 细粒度分词
(第109、151行):细粒度分词扩展关键词,提升匹配精度
GraphRAG优化:
- kg_limiter限制
(第1087行):知识图谱任务并发限制为2,防止LLM过载 - 可选高级功能
(第1085-1086行): resolution和community可选启用,节省计算成本 - 实体类型预设
(第1067-1073行):预设常见实体类型,减少LLM识别难度
七、源码行号索引表
7.1 Task Executor核心函数
signal_handler | ||
set_progress | ||
collect | ||
build_chunks | ||
embedding | ||
run_raptor_for_kb | ||
insert_chunks | ||
do_handle_task |
7.2 NLP检索关键函数
RagTokenizer.tokenize | ||
FulltextQueryer.question | ||
Dealer.get_vector | ||
Dealer.search | ||
Dealer.rerank | ||
Dealer.rerank_by_model |
八、学习建议与实践路径
8.1 理论学习顺序
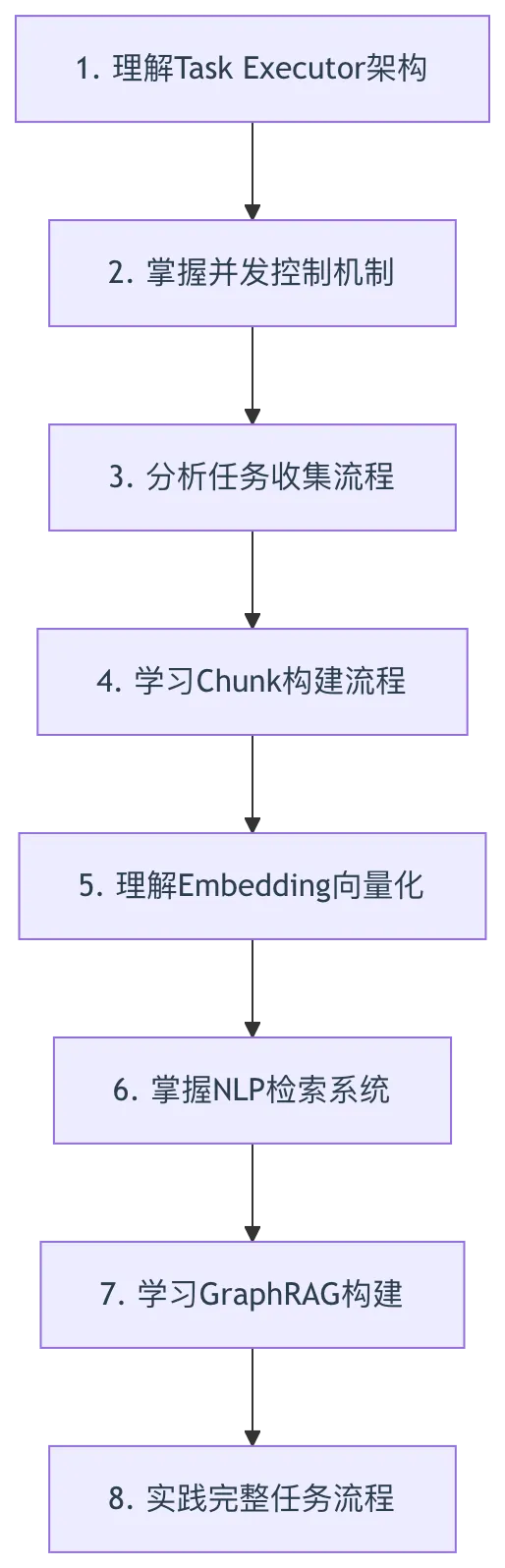
8.2 实践调试建议
调试Task Executor:
# 在rag/svr/task_executor.py:176添加日志async def collect():print(f"[DEBUG] collect开始,UNACKED_ITERATOR={UNACKED_ITERATOR}")svr_queue_names = settings.get_svr_queue_names()print(f"[DEBUG] svr_queue_names={svr_queue_names}")# ...
调试混合检索:
# 在rag/nlp/search.py:127添加日志fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05,0.95"})print(f"[DEBUG] 混合检索:matchText={matchText}, matchDense shape={len(q_vec)}, weights=0.05,0.95")
调试GraphRAG:
# 在rag/svr/task_executor.py:1089添加日志result = await run_graphrag_for_kb(...)print(f"[DEBUG] GraphRAG结果:实体数={len(result.get('entities', []))}, 关系数={len(result.get('relationships', []))}")
九、常见问题与解决方案
9.1 Task Executor错误诊断
问题1:任务卡在"Processing"状态
原因:chunk_limiter或embed_limiter信号量耗尽,任务等待资源
解决方案:
# 检查并发限制配置docker exec ragflow-container printenv MAX_CONCURRENT_CHUNK_BUILDERS# 建议值:1-2(根据CPU核心数调整)# 检查当前任务数docker exec ragflow-container redis-cli LLEN ragflow_svr_queue
问题2:Embedding超时
原因:@timeout(60)装饰器超时,Embedding API响应慢
解决方案:
# 在task_executor.py:590增加超时时间@timeout(120) # 从60秒增加到120秒def batch_encode(txts):# ...
9.2 NLP检索问题
问题1:检索结果为空
原因:min_match阈值过高,查询词匹配不足
解决方案:
# 在search.py:114降低min_matchmatchText, keywords = self.qryr.question(qst, min_match=0.1) # 从0.3降低到0.1
问题2:向量相似度分数异常
原因:向量维度不匹配,不同Embedding模型混用
解决方案:
# 在search.py:304添加维度检查vector = sres.field[chunk_id].get(vector_column, zero_vector)if len(vector) != vector_size:logging.warning(f"向量维度不匹配:期望{vector_size},实际{len(vector)}")vector = zero_vector
9.3 GraphRAG问题
问题1:实体提取不完整
原因:entity_types配置不匹配文档内容
解决方案:
# 在task_executor.py:1067扩展实体类型"entity_types": ["organization","person","geo","event","category","product", # 新增产品类型"technology", # 新增技术类型"date", # 新增日期类型],
问题2:社区发现耗时过长
原因:文档数量过多,Leiden算法计算复杂
解决方案:
# 减少GraphRAG并发数export MAX_CONCURRENT_GRAPH_RAG=1 # 从默认2降低到1# 或禁用社区发现# 在知识库配置中设置:graphrag.community=false
十、扩展阅读与参考资源
10.1 官方文档
- RAPTOR论文
: https://arxiv.org/abs/2401.18059 - GraphRAG
: https://microsoft.github.io/graphrag/ - Leiden算法
: https://arxiv.org/abs/1810.08482 - Redis Stream
: https://redis.io/docs/data-types/streams/
10.2 源码关联文件
rag/app/*.py | |
rag/raptor.py | |
rag/graphrag/general/index.py | |
agent/canvas.py | |
common/doc_store/doc_store_base.py | |
common/constants.py |
