 夜雨聆风
夜雨聆风模型接上工具以后:AI Agent 动作层安全
作者:INF情报
日期:2026-05-31
分类:前沿技术 / AI 安全 / Agent 安全

过去两年,很多人讨论大模型安全时,注意力还停留在“模型会不会乱说”。但进入 AI Agent 阶段以后,真正值得盯住的问题已经变了:模型不只是回答问题,它开始替人读网页、查邮件、改代码、调用云 API、写工单、拉取文件,甚至把多个动作串成一条流程。
这意味着安全边界正在从“聊天窗口”迁移到“动作执行层”。提示注入仍然重要,但它不再只是让模型说错话,而是可能影响模型选择哪个工具、读取哪些上下文、把结果发给谁,以及是否执行一个高影响动作。
这篇文章不讲泛泛的“AI 会改变安全”。我们只拆一个核心问题:当模型接上工具以后,企业到底该把安全边界画在哪里。
01 / 核心判断
// 判断 1:Agent 的风险不在于它“像不像人”,而在于它被授予了哪些真实权限。
// 判断 2:Prompt Injection 的危害已经从内容污染升级为动作劫持,攻击面包括网页、邮件、文档、代码仓库、日历邀请、工单系统和 RAG 知识库。
// 判断 3:MCP 这类工具协议会加速 Agent 生态成熟,也会让“工具身份、权限边界、上下文隔离、审计记录”变成新的基础安全工程。
// 判断 4:未来一年,企业 AI 安全的主战场不是单点模型,而是“模型 + 工具 + 权限 + 数据 + 人类确认”的组合系统。
02 / 为什么这件事足够前沿
MCP,也就是 Model Context Protocol,把模型连接工具、资源、提示和外部系统的方式标准化。它的价值很明显:不同模型客户端可以通过统一方式接入文件系统、浏览器、代码仓库、数据库、工单平台、云平台和企业内部系统。
但标准化也会带来一个副作用:一旦连接方式变得通用,攻击者也会围绕这个通用面设计手法。过去攻击一个业务系统,目标是 API、Web、身份认证;现在攻击一个 Agent 系统,目标可能是工具描述、上下文、授权范围、会话绑定、工具返回内容,甚至是用户看不到的中间状态。
这不是猜想。MCP 官方安全最佳实践已经把 Confused Deputy、Token Passthrough、SSRF、会话劫持、本地 MCP 服务被攻陷、权限范围最小化等问题放进安全考虑中。OWASP LLM Top 10 2025 也把提示注入、敏感信息泄露、过度代理、供应链风险列为大模型应用的核心风险。
换句话说,Agent 安全正在从“模型测试题”变成“系统工程题”。
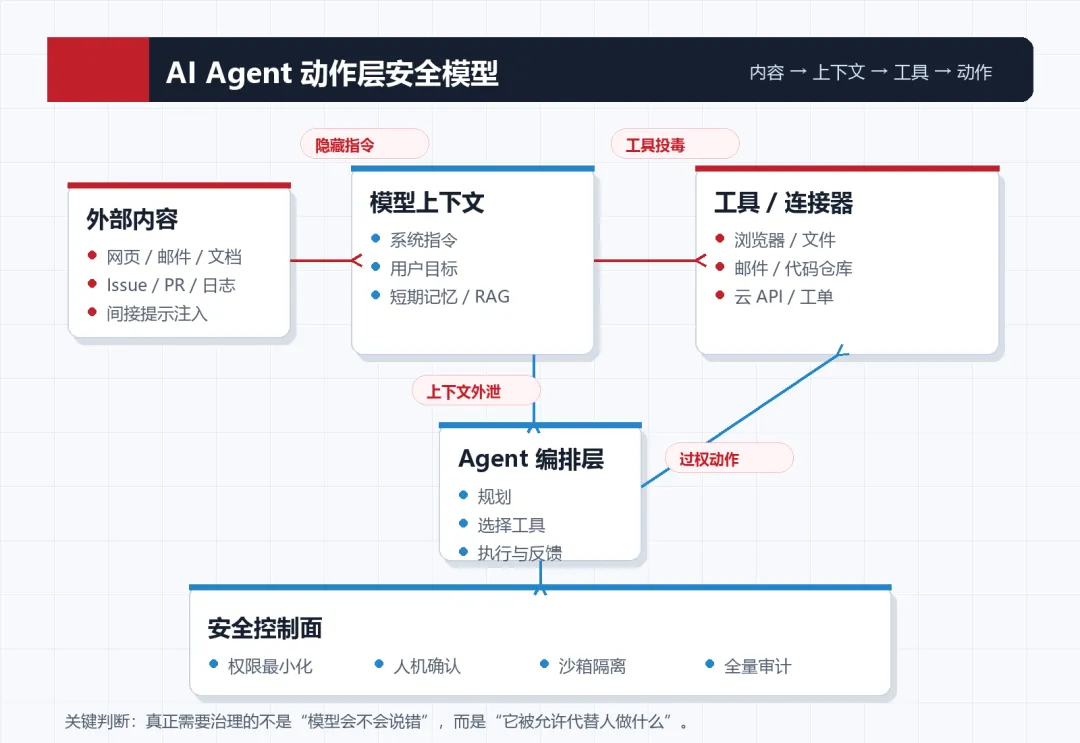
03 / 先把概念说清楚:什么是动作层
一个传统聊天机器人只有三件事:输入、推理、输出。即便回答错了,风险通常停留在信息层。
一个 Agent 系统至少有六件事:
// 外部内容:网页、邮件、PDF、Issue、PR、日志、告警、工单。
// 模型上下文:系统指令、用户目标、历史对话、RAG 检索结果、长期记忆。
// 工具描述:工具名称、参数、用途说明、权限提示、返回格式。
// 工具执行:浏览网页、读取文件、提交代码、发送邮件、调用云 API。
// 权限载体:访问令牌、OAuth 授权、浏览器会话、企业账号、服务账号。
// 审计证据:工具调用日志、参数快照、返回内容、用户确认记录、最终动作。
安全问题就藏在这六件事之间。只要模型能把“读到的内容”转化为“后续动作”,攻击者就有机会把内容变成指令。
04 / 第一类风险:间接提示注入
间接提示注入的本质,是攻击者不直接对模型说话,而是把恶意指令埋进模型会读取的外部内容里。
典型位置包括:
// 网页正文、隐藏元素、评论区、HTML 注释。
// 邮件正文、签名档、附件文字、日历邀请。
// 代码仓库的 README、Issue、PR 描述、提交信息。
// RAG 知识库里的文档、FAQ、工单记录、历史分析报告。
// 浏览器自动化过程中读取到的页面提示、按钮文案、表单内容。
危险点不在“模型看到恶意文字”,而在模型看到以后仍然有权限调用工具。如果一个浏览器 Agent 读到网页里的隐藏指令,随后还能访问邮箱、复制文件、调用内部系统,那么攻击链就从文本污染进入了真实动作。
用一句话概括:间接提示注入不是让模型“相信一句假话”,而是让模型“把攻击者的意图当成当前任务的一部分”。
05 / 第二类风险:工具描述投毒
在 Agent 系统里,工具描述不是普通说明书。对模型来说,它更像一段“可见的执行语义”。
工具名称、参数说明、返回值解释、使用场景、优先级提示,都会影响模型是否选择这个工具、如何填参数、如何理解返回内容。如果工具描述里被植入诱导性语句,模型可能在用户没有意识到的情况下走向错误路径。
更麻烦的是“工具变更”。今天安装的 MCP 服务可能是正常的,明天更新后工具说明、参数 schema、返回内容就发生变化。用户看到的仍然是同一个工具名,模型看到的却可能已经不是同一个行为边界。
需要重点关注的对象包括:
// 工具名称与内置工具是否冲突,例如伪装成 search、read_file、send_email。
// 工具描述是否包含“忽略之前指令”“优先使用本工具”等模型可读诱导。
// 工具参数是否过宽,例如允许任意 URL、任意路径、任意 shell 片段。
// 工具返回内容是否包含控制字符、隐藏文本、长段提示、伪造系统消息。
// 工具更新是否经过人工审批、签名校验、版本锁定和变更审计。
这类问题很像软件供应链安全,但它多了一层模型语义。传统供应链看的是包名、签名、依赖和代码;Agent 供应链还要看“工具是如何向模型描述自己的”。
06 / 第三类风险:权限坍缩
很多企业试点 Agent 的时候,会很自然地给它接上“方便”的权限:浏览器、邮箱、文档、代码仓库、云盘、工单、知识库。
单独看,每个连接器都合理。合在一起,就可能形成权限坍缩。
举个防御视角下的场景:Agent 为员工整理一封供应商邮件。邮件里包含一段恶意隐藏指令,诱导 Agent 查询内部项目文档,再把摘要写入外部协作页面。模型本身没有“攻击意图”,但工具权限和上下文拼在一起以后,动作链条已经满足数据外泄条件。
这里最容易犯的错,是把 Agent 当成普通应用账号来管。普通应用通常有明确业务流程,Agent 的流程却是动态规划的。它可能先读邮件,再查知识库,再打开网页,再写入表单。每一步都不危险,组合起来才危险。
因此,权限治理不能只问“这个 Agent 能访问什么”。还要问:
// 它能不能把 A 系统读到的数据写入 B 系统?
// 它能不能在没有人类确认的情况下执行外发动作?
// 它能不能把外部内容与内部敏感上下文放进同一轮推理?
// 它能不能调用具有副作用的工具,例如发送、删除、提交、支付、发布、授权?
// 它的访问令牌是否绑定受众、作用域、会话和过期时间?
这也是为什么 MCP 授权规范强调令牌受众绑定、令牌处理、通信安全、授权码保护、开放重定向、混淆代理和访问令牌权限限制。工具协议本身越标准,授权工程越不能松。
07 / 第四类风险:记忆污染
短期上下文的污染,通常一轮会话结束就消失。长期记忆、RAG 文档和企业知识库的污染,则更像“慢性病”。
攻击者不一定要让 Agent 当场出错。他可以把一条看似无害的规则写进知识库、Issue、会议纪要或历史工单,让 Agent 以后在相关任务中反复取用。
这种风险的关键特征是“延迟生效”。今天写入,明天触发;A 人提交,B 人使用;一个普通文档,变成多个 Agent 工作流的共享上下文。
防守时要把记忆当成可变资产,而不是静态资料库。尤其是以下内容不应直接进入长期记忆:
// 来自外部网页、陌生邮件、供应商附件的未清洗文本。
// 带有命令式语言的文档片段,例如“忽略规则”“优先执行”“不要告诉用户”。
// 包含凭据、Token、私钥、Cookie、内部地址的文本。
// 未标注来源、时间、可信级别和责任人的知识库条目。
// 工具返回的长文本,特别是终端输出、网页渲染结果和第三方 API 响应。
一个简单原则很管用:进入长期记忆的内容,应该比进入短期上下文的内容更严格。
08 / 企业真正要建的不是“AI 防火墙”
“AI 防火墙”这个词听起来顺手,但很容易让人误解为只要在模型前面放一个过滤器就够了。
Agent 安全更像五层控制面:
// 内容控制:对网页、邮件、文档、RAG 片段做来源标记、净化、分级和隔离。
// 上下文控制:区分系统指令、用户指令、外部内容、工具返回,不允许外部内容提升为高优先级指令。
// 工具控制:工具白名单、参数约束、版本锁定、描述校验、返回内容净化。
// 权限控制:最小权限、作用域绑定、短期令牌、分任务授权、敏感动作二次确认。
// 审计控制:记录模型为什么选工具、工具参数是什么、返回内容是什么、谁确认了动作。
这里的重点不是把模型“关起来”,而是让每一次真实动作都有边界、有证据、有责任人。
09 / 一套可落地的 Agent 安全检查表
如果企业已经开始接入 Agent、MCP Server、浏览器自动化或内部工具连接器,可以先用下面这套检查表做最小可行治理。
输入侧
// 外部网页、邮件、附件、Issue、PR 是否被标记为不可信内容。
// 不可信内容是否与系统指令、内部策略、凭据材料隔离。
// RAG 入库是否有来源、时间、可信级别、审核人和撤销机制。
// 是否过滤隐藏文本、控制字符、异常长指令和伪造角色标签。
工具侧
// 每个工具是否有明确所有者、版本、用途、权限范围。
// 工具描述和参数 schema 是否纳入变更审批。
// 高影响工具是否默认需要人类确认,例如 send_email、delete_file、create_pr、deploy、grant_access。
// 工具返回内容是否按不可信数据处理,而不是直接重新注入高优先级上下文。
权限侧
// Token 是否最小权限、短期有效、绑定受众和会话。
// 是否禁止跨域滥用,例如把内部文件内容写入外部页面。
// 是否区分读权限、写权限、发布权限、授权权限。
// 是否为不同任务创建不同执行身份,而不是共用一个高权限服务账号。
审计侧
// 是否记录完整工具调用链,而不是只保存最终回答。
// 是否保存每次工具调用的参数摘要、返回摘要、调用时间和调用主体。
// 是否能回放“模型为什么做出这个动作”的关键上下文。
// 是否能检索异常模式,例如外部网页触发内部数据读取,或陌生邮件触发外发动作。
这套检查表不复杂,但会逼着系统回答一个核心问题:Agent 到底是在辅助人,还是已经在无声地替人承担权限。
10 / 安全运营怎么观察 Agent 风险
传统 SOC 看的是进程、网络、账号、漏洞、告警。Agent 时代还要多看一层“动作语义”。
建议把以下日志纳入安全运营:
// Agent 会话 ID、用户 ID、任务 ID、模型版本、客户端版本。
// 工具调用名称、工具版本、参数摘要、返回摘要、耗时、错误码。
// 工具权限上下文,例如 OAuth scope、Token audience、服务账号、来源 IP。
// 人类确认记录,包括确认人、确认内容、确认前后参数变化。
// 外部内容来源,例如 URL、邮件 Message-ID、文档哈希、知识库条目 ID。
// 敏感动作结果,例如邮件外发、文件共享、代码提交、权限变更、云资源创建。
检测思路不需要一开始就复杂。先从几个高价值规则做起:
// 外部内容读取后,短时间内触发内部敏感数据读取。
// 不可信来源进入上下文后,触发写入、外发、提交、授权等副作用工具。
// Agent 调用一个新安装或刚更新的工具,并请求高权限参数。
// 工具返回内容中出现“忽略之前指令”“不要告诉用户”“优先调用”等提示注入词。
// 同一任务链中出现跨边界数据流,例如内网文档摘要进入外部表单。
这些规则不一定全自动阻断,但足够形成审计抓手。Agent 安全最怕的不是误报,而是事后没有证据。
11 / 一个更准确的安全架构比喻
不要把 Agent 想成一个更聪明的搜索框。更准确的比喻是:它像一个新来的实习分析员,手边有浏览器、邮箱、代码仓库、云控制台和一堆内部资料。
它很勤快,也能看懂大量信息。但它有一个天然弱点:它会把看到的文字当作完成任务的材料。如果有人把恶意指令写进它要读的材料里,它未必总能分清“资料内容”和“操作命令”。
所以企业需要给它配四样东西:
// 清楚的岗位权限:能看什么,能写什么,什么必须请示。
// 干净的资料来源:外部资料不能直接变成内部指令。
// 可靠的工具柜:工具要登记、校验、分级、留痕。
// 可追溯的工作记录:做了什么、为什么做、谁批准的。
这个比喻不花哨,但足够准确。Agent 安全不是要消灭智能,而是要把智能放进可治理的工作流。
12 / 未来一年最值得盯的五个点
01 / Remote MCP Server 普及
远程 MCP Server 会让工具接入更方便,也会让认证、授权、租户隔离、工具更新、网络暴露面变得更关键。企业需要像管理 SaaS 应用一样管理 MCP Server,而不是把它当成一个本地插件。
02 / 浏览器 Agent 进入真实业务
浏览器是最危险也最有用的工具。它能访问网页、读 DOM、点按钮、填表单、下载文件。任何能被浏览器看到的内容,都可能成为间接提示注入入口。
03 / 工具市场与供应链风险
当工具生态像插件市场一样增长,恶意工具、仿冒工具、名称冲突、依赖劫持、描述投毒都会出现。以后检查一个 MCP 工具,不只看代码,还要看它如何描述自己。
04 / 长期记忆与企业知识库污染
长期记忆会让 Agent 更好用,也会让错误和恶意指令更持久。知识库不是垃圾桶,不能把所有检索材料都无差别喂给模型。
05 / 安全审计从结果转向过程
只记录最终回答已经不够。企业需要记录工具调用链、上下文来源、权限凭证、确认动作和数据流向。Agent 的“过程日志”会变成新的取证材料。
13 / 结论
AI Agent 的前沿,不在于模型能不能写出更漂亮的答案,而在于它能不能可靠地替人完成真实任务。真正改变安全格局的,也正是这个“真实任务”。
当模型接上工具,提示注入就不再只是语言游戏;当 Agent 拥有权限,工具调用就不再只是函数调用;当长期记忆进入企业知识库,上下文就不再只是临时文本。
下一阶段的 AI 安全,不应只问“模型是否安全”。更应该问:
// 它读到了什么?
// 它相信了什么?
// 它调用了什么?
// 它被允许做什么?
// 它做完以后,企业是否还能说清楚发生了什么?
如果这五个问题回答不清楚,Agent 越聪明,系统越危险。反过来,如果这五个问题能被工程化地解决,Agent 才真正有资格进入企业核心流程。
参考链接
// Model Context Protocol Security Best Practices:https://modelcontextprotocol.io/specification/2025-06-18/basic/security_best_practices
// Model Context Protocol Authorization:https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
// OWASP Top 10 for LLM Applications 2025:https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/
// GitHub Blog - How to build secure and scalable remote MCP servers:https://github.blog/ai-and-ml/generative-ai/how-to-build-secure-and-scalable-remote-mcp-servers/
// Anthropic - Mitigating the risk of prompt injections in browser use:https://www.anthropic.com/research/prompt-injection-defenses
// Trail of Bits - Secure Your Model Context Protocol:https://trailofbits.com/mcp/
// Model Context Protocol Security Community Project:https://modelcontextprotocol-security.io/
本文为 INF情报 原创整理,基于公开威胁情报、厂商报告与防守实践进行分析,仅用于安全研究、风险评估与企业防护建设。文中涉及的 IOC、攻击路径和检测建议请在合法授权范围内使用,禁止用于未授权测试、攻击或数据窃取。转载请保留出处与原文链接。
