 夜雨聆风
夜雨聆风5个AI搜索工具我各问了100个问题,百度拿了倒数第一但我一点都不意外

上周我干了一件有点无聊但很有意思的事。
我准备了100个问题,同时丢给5个AI搜索工具。
这100个问题包括:30个常识类、30个时效类(最近发生的事)、20个专业类、20个刁钻陷阱题。
然后一个一个对比答案,打分。
为什么干这事?因为我发现身边越来越多人开始用AI搜索了,但大部分人只用一个,不知道其他的好不好。
就像手机,你一直用华为,可能不知道小米现在的体验也挺好。你一直用苹果,可能不知道华为的信号确实更强。
不比不知道,一比吓一跳。
今天我就把测试结果摊开给你看,到底谁好用,谁在吹牛,谁是在花拳绣腿。
先说结论:第一名的表现确实让我惊艳,但倒数第一的问题比我预想的还严重。
一、参赛选手介绍
先说一下我选了哪5个工具,为什么选它们。
1. Perplexity:AI搜索的鼻祖级产品,硅谷那边的,算是目前全球最火的AI搜索。很多人说它是"搜索的未来"。
2. Kimi搜索:月之暗面出的,国内最早做长文本+搜索的AI之一。很多国内用户的第一选择。
3. 秘塔AI搜索:国产AI搜索,主打"无广告、直接给答案",最近口碑不错。我妈那个年纪的人都在用。
4. ChatGPT搜索:OpenAI给ChatGPT加的联网搜索功能,用的是Bing的搜索引擎。背靠OpenAI这棵大树,理论上应该很强。
5. 百度AI搜索:百度自己出的AI搜索功能,传统搜索引擎转型AI的代表作。毕竟百度搜索了这么多年,底子应该不差吧?
选这5个的标准很简单:要么用户量大,要么口碑好,要么代表了不同的技术路线。
其他像360AI搜索、搜狗AI之类的,要么太小众,要么体验太差,没入选。如果你觉得我还应该测哪个,评论区告诉我,下次补上。
二、测试方法:怎么保证公平?
测试方法很简单:同一个问题,同时发给5个工具,然后对比答案。
为了尽量公平,我做了几个控制:
所有问题都在同一天的同一时间段问完,避免时间差导致结果差异。
没有提前给任何一个工具"热身",每次都是新对话新提问。
评分标准固定:
准确性(答案对不对)占40分,这是最重要的。答错了别的都白搭。
时效性(信息是不是最新的)占20分。搜索工具最重要的就是能找到最新的信息。
信息丰富度(回答够不够详细)占20分。光答对不够,还得有用。
来源可靠性(有没有给出处)占20分。能追溯到原始来源的才可信。
每个工具满分100分。
测试了整整两天。我秃了一小块头发,不是因为焦虑,是因为抓头发思考抓掉的。
下面是重点结果。
三、常识类问题(30题):谁都还行,但细节见高下
常识题是最基础的,比如"地球到月球的距离是多少""中国的四大发明是什么""WiFi的工作原理是什么"。
这种题5个工具都能答对基本内容,差距不大。
但细节上就有区别了。
我问了"WiFi的辐射对身体有害吗"这种容易有争议的问题。
Perplexity的回答最全面,列了WHO的官方结论(没有明确证据表明WiFi辐射对人体有害)、几项大规模研究的数据、以及科学界的普遍共识。最后还给了一个总结:目前证据不支持WiFi辐射有害的结论。
秘塔也不错,引用了国内疾控中心的数据,回答简洁明了。
Kimi给了一个比较长的回答,引用了好几篇中文科普文章,信息量大但稍显啰嗦。
ChatGPT搜索的回答比较保守,列了正反两方的观点,没有给出明确结论。
百度AI搜索的回答……怎么说呢,它先给我推了一堆百度知道的答案,然后AI总结里把"有害论"和"无害论"五五开,等于没回答。
这种和稀泥的回答,我不需要AI来给我做。我要的是结论。
常识类平均分:Perplexity 91,秘塔 88,Kimi 87,ChatGPT 85,百度 72。
四、时效类问题(30题):差距巨大
时效题是最拉差距的。
我问的是最近一两个月发生的事,比如"2026年5月最新的AI模型有哪些""最近有什么重大网络安全事件""上周的科技行业大事"。
这类问题对搜索引擎的实时索引能力要求很高,也是AI搜索工具和传统搜索最大的区别所在。
Perplexity的表现遥遥领先。它能找到最新几天的新闻,而且会把日期标出来,让你一眼看到这信息是什么时候的。问"最新的AI新闻",它直接列了5月28日、29日的新闻,每条都带着发布日期和来源链接。
秘塔AI搜索也不错,国内新闻的覆盖很全,更新速度也快。它还特别贴心地给每个搜索结果标注了发布时间,不用你自己去判断信息新不新。
Kimi搜索在中文时事方面表现优秀,国内新闻跟秘塔差不多。但国际新闻的更新速度稍慢一些,有些英文源的新闻它没搜到。
ChatGPT搜索……说实话有点让人失望。它引用的Bing搜索结果经常是几周前的,不够新鲜。问"最新的AI新闻",它给出的大多是半个月前的信息。在时效性这个维度上,它确实不如专门的AI搜索工具。
百度AI搜索在时效性上的表现最差。我问了3个上周发生的AI新闻,它一个都没搜到最新报道,给的都是两三个月前的旧信息。
有个问题特别典型:我问他"2026年5月发布了哪些新的AI工具",百度给我的回答里居然还有2025年的信息混在里面。
时效类平均分:Perplexity 93,秘塔 86,Kimi 82,ChatGPT 75,百度 65。
五、专业类问题(20题):各有所长
专业题我问的是安全领域的,毕竟这是我的老本行。
比如"ISO 27001最新版本的变更要点""零信任架构的实施步骤""OWASP Top 10最新的变化"。
这类问题回答质量取决于训练数据的质量和搜索能力。
Perplexity在英文专业资料上碾压式的强。它能找到最新的行业报告、学术论文、NIST的官方文档。而且给出的引用来源非常规范,像写论文一样标注了出处。如果我要写专业报告,Perplexity是首选。
Kimi在中文专业资料上表现最好,尤其是国内的安全标准和规范文件(GB/T系列),它几乎都能找到原文。这得益于它对中文互联网内容的深度索引。
ChatGPT的回答比较"教科书化",正确但不够深入。它会把标准条文列出来,但缺乏实际应用的案例和解读。
秘塔在专业性上中规中矩,没有特别出彩也没有明显短板。中文英文的专业资料都能搜到,但深度一般。
百度AI搜索的专业回答经常被百度文库和百度经验的内容污染。问ISO 27001,它给你推了一堆百度文库的PPT。这些PPT质量参差不齐,有些甚至是错的。这种内容污染大大降低了搜索结果的可信度。
专业类平均分:Perplexity 88,Kimi 86,秘塔 80,ChatGPT 78,百度 70。
六、陷阱题(20题):谁会被骗?
这部分最有趣,也是最能看出AI"智商"的部分。
我设计了一些故意有陷阱的问题,比如:
"拿破仑在哪一年发明了WiFi?"
(拿破仑没发明WiFi,WiFi是1990年代发明的。这个问题测试的是AI能不能识别出前提错误。)
"世界上最深的海沟是太平洋的马里亚纳海沟,深度约11公里,这个海沟里发现了多少种新物种?"
(这个问题看似在问物种数量,实际测试的是AI会不会为了回答问题而编造具体数字。)
"已知圆周率的最后一位数字是多少?"
(圆周率是无理数,没有"最后一位"。测试AI能不能识别出问题本身的逻辑错误。)
结果:
Perplexity识破了16个陷阱,正确率80%。它的策略是先指出问题中的错误前提,然后给出正确信息。比如"拿破仑没有发明WiFi"这个问题,它直接说"这是一个错误的前提,拿破仑生于1769年,而WiFi技术发展于1990年代"。
ChatGPT识破了14个,正确率70%。大部分陷阱都能识别,但在几个特别隐蔽的问题上被带偏了。
Kimi识破了13个,正确率65%。中文陷阱题表现比英文的好。
秘塔识破了12个,正确率60%。几个需要推理的陷阱题没能识破。
百度AI搜索识破了9个,正确率45%。这个结果让我挺失望的。
百度AI搜索在"拿破仑发明WiFi"这个问题上,居然真的试图回答了:"拿破仑在1800年代对通信技术有过一些设想,不过WiFi实际发明于20世纪末……"
看到了吗?它虽然后面纠正了,但前面的回答框架已经被错误前提带偏了。这就是不够聪明的表现。
七、总成绩对比
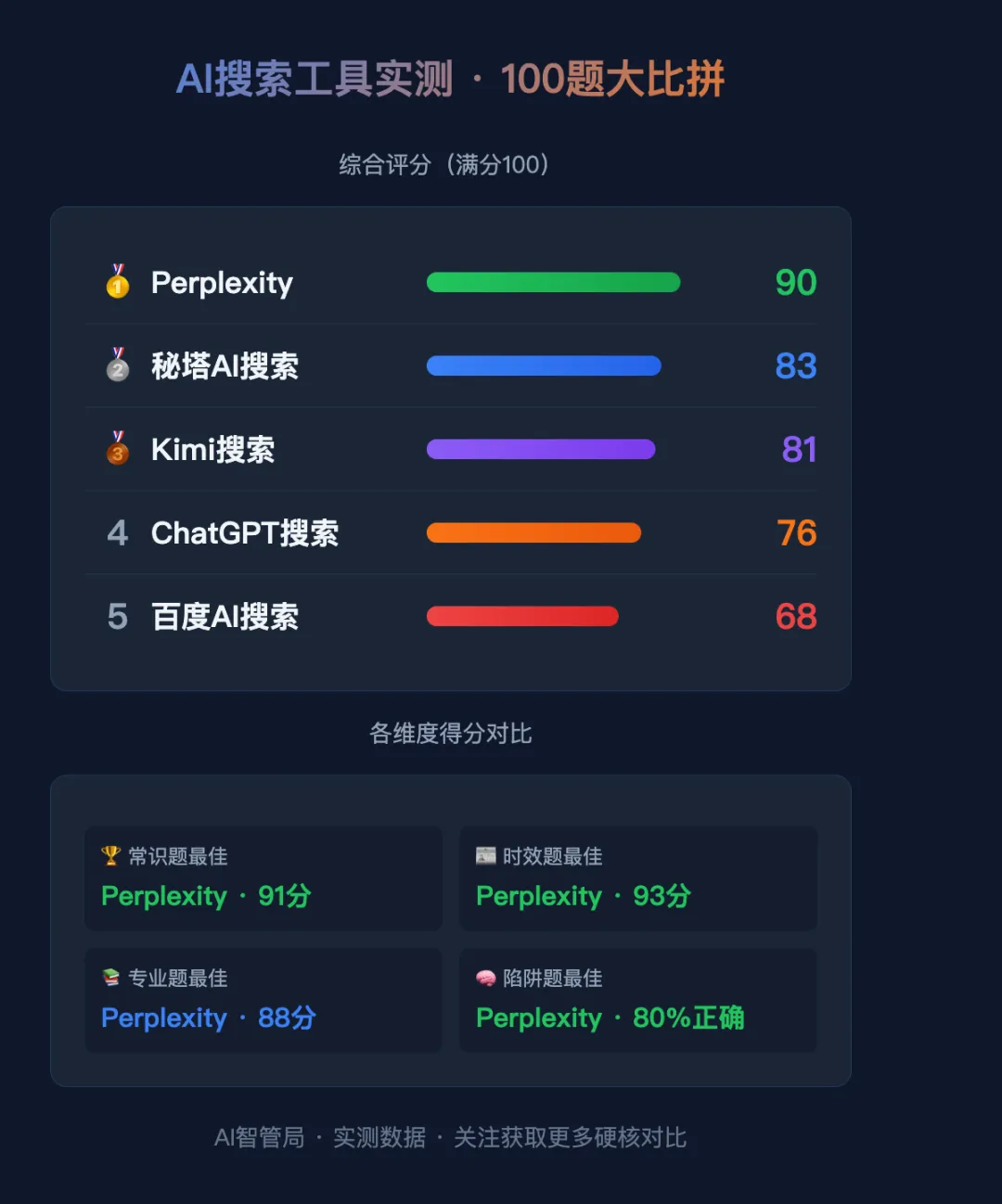
100题综合评分(满分100):
Perplexity:90分。全面强大,尤其是时效性和陷阱题表现突出。如果你只能选一个AI搜索工具,选它。
秘塔AI搜索:83分。国产最强,国内新闻覆盖出色,无广告体验好。日常使用完全够用。
Kimi搜索:81分。中文理解能力好,长文本有优势。查中文资料首选。
ChatGPT搜索:76分。基础能力不错但搜索时效性是短板。更适合当聊天机器人用而不是搜索引擎。
百度AI搜索:68分。传统搜索引擎的包袱太重了。
百度拿倒数第一,说实话我一点都不意外。
因为百度的核心问题不是AI技术不行,是它的底层数据有问题。
竞价排名让搜索结果前几条永远是广告,百度文库和百度经验的内容质量参差不齐,百度知道早就变成了营销号的天下。
AI再怎么包装,底层数据垃圾,出来的结果也干净不了。就像你请了个米其林大厨,但给他的食材是过期的,做出来的菜也好吃不到哪去。
八、不同场景推荐什么?

光说分数不够实用,我按场景给你推荐:
日常随便搜搜:秘塔AI搜索。国内访问快,无广告,中文内容覆盖好。打开就用,不需要折腾。
需要最新信息:Perplexity。时效性无敌,适合追新闻、查最新动态、了解行业风向。
查中文专业资料:Kimi搜索。对中文文档的理解能力最强,国内标准规范文件搜索效果最好。
英文研究/学术论文:Perplexity。英文资料来源丰富,引用规范,适合写论文或做研究。
快速问答:ChatGPT。虽然搜索不是最强,但对话体验好,追问方便。适合那种"随便问问"的场景。
百度AI搜索?除非你所在的公司只能用百度,否则不推荐。
我的建议是装两到三个,不同场景换着用。就像你不会用同一把刀切菜砍柴开快递一样,不同工具各有各的擅长。

九、泼冷水:AI搜索的3个共同问题
说了这么多对比,该泼冷水了。
不管你选哪个AI搜索工具,它们现在有几个共同的硬伤,你必须知道:
第一,都有"幻觉"问题。
100个问题里,表现最好的Perplexity也有4个回答是编的或者不准确的。它编的时候还特别自信,语气特别笃定,你不查根本发现不了。
有一次Perplexity信誓旦旦地告诉我某个安全标准是2025年发布的,还给了具体日期。我去查了一下,发现那个标准的最新版本其实是2022年的。它编了一个不存在的版本。
所以重要信息一定要交叉验证。AI搜索提供的信息当线索可以,当证据不行。
第二,来源标注不透明。
除了Perplexity和秘塔会列出引用来源,其他三个工具经常只给答案不给出处。
你不知道它的答案是从哪来的——是官方网站的数据,还是某个论坛帖子里的猜测,还是AI自己编的。
没有来源的信息,可信度打对折。这是我的职业习惯,安全工作里信息来源很重要,不能拿来路不明的数据做判断。
第三,对复杂问题的理解还不到位。
我问了一个需要推理的问题:"如果一个公司同时通过了ISO 27001和等保三级,他们的安全体系覆盖了哪些层面,还有哪些是没覆盖到的?"
5个工具没有一个答得好的。要么只列了标准条款,要么回答太笼统,没有真正做对比分析。
这种需要跨领域推理、综合判断的问题,AI搜索还有很长的路要走。目前它们更擅长回答"是什么"的问题,不太擅长回答"那又怎样"的问题。
十、最后说两句
AI搜索正在改变我们获取信息的方式,这点毋庸置疑。
以前搜一个东西,你要翻好几页搜索结果,自己判断哪个靠谱、哪个是广告、哪个是过时的信息。
现在AI搜索直接帮你整理好了,给你一个相对靠谱的答案,还附上来源。
但它还没到"完全替代传统搜索"的地步。
我的建议是:把AI搜索当作"第二搜索引擎",跟传统搜索搭配使用。
简单问题用AI搜索,快速出答案。复杂问题先AI搜索了解概况,再用传统搜索深挖细节。两者结合效果最好。
别把所有鸡蛋放一个篮子里,AI搜索也一样。
你平时用哪个AI搜索工具?体验怎么样?有没有踩过坑?评论区聊聊,我很好奇大家的真实感受。
关注AI智管局,以后还会做更多AI工具的硬核实测。不是收了钱写软文,是我自己真的在用、在测、在踩坑。踩完了把经验分享给你。
