 夜雨聆风
夜雨聆风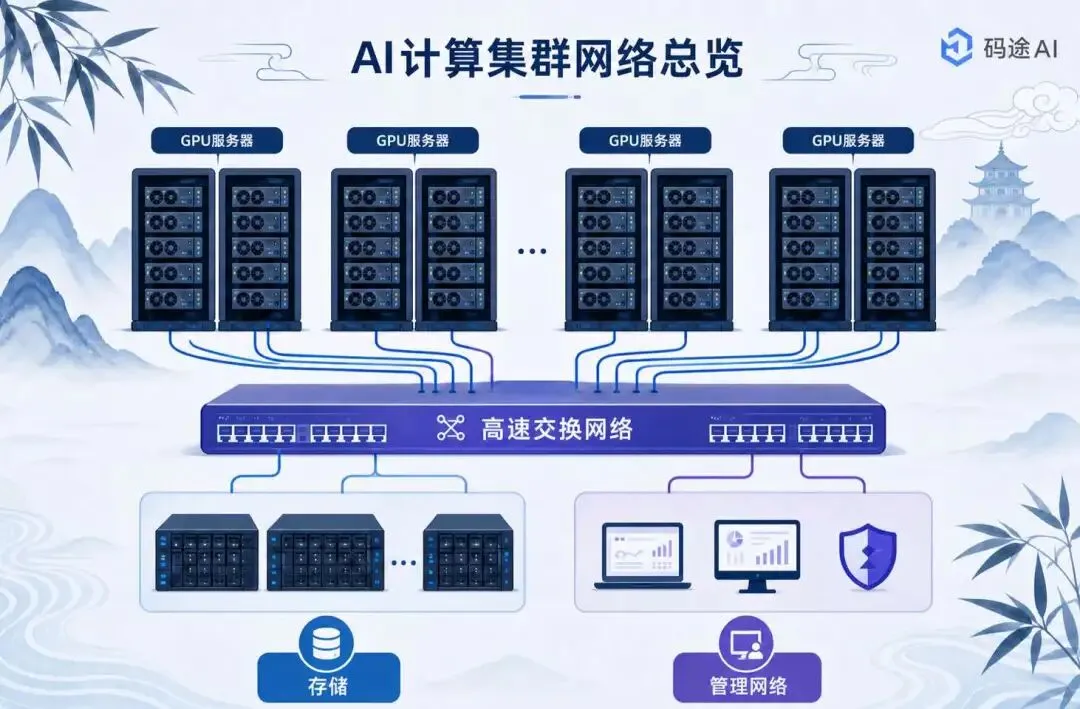
在大模型训练进入千卡、万卡时代后,AI 集群的瓶颈已经不只在 GPU。计算、存储、网络共同决定训练效率,其中网络的影响常常被低估:GPU 算得再快,如果梯度同步、参数交换、数据加载跟不上,昂贵的算力就会在等待中被浪费。
尤其在分布式训练中,AllReduce、AllGather、ReduceScatter 等集体通信会频繁发生。模型越大、GPU 数量越多,通信对整体训练时间的影响越明显。因此,AI 算力网络不再是“把机器连起来”的基础设施,而是决定集群线性扩展能力、训练稳定性和综合成本的核心系统。
这篇文章会从最基础的问题讲起:为什么传统 TCP/IP 不够用?RDMA 解决了什么?InfiniBand 为什么长期占据高性能训练集群?RoCE 又如何把 RDMA 带到以太网上?最后再讨论二者在真实 AI 集群中的取舍。
一、为什么 AI 集群需要 RDMA?
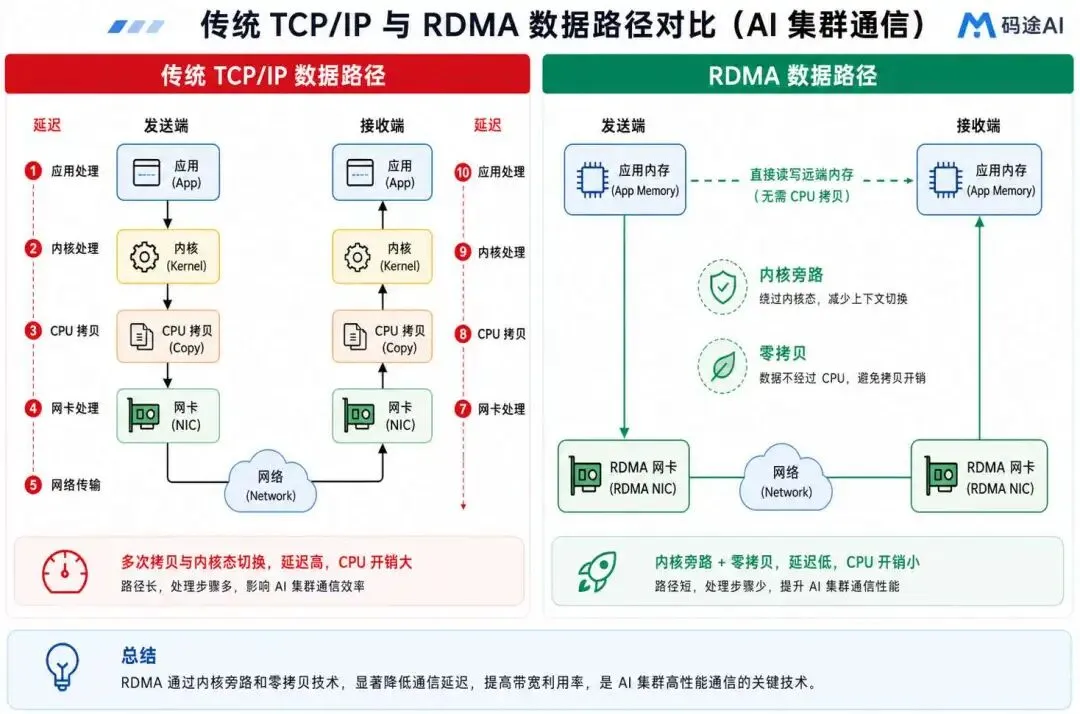
传统网络通信通常要经过 TCP/IP 协议栈:应用程序把数据交给操作系统内核,内核完成协议处理、拷贝、排队、网卡收发,中间还伴随上下文切换和中断处理。这个模式通用、可靠,也非常成熟,但在高性能 AI 训练场景下会暴露三个明显问题。
第一是延迟偏高。分布式训练中的通信不是偶尔发生,而是每一轮迭代都会发生。一次通信多几十微秒,看似不大,但在大规模集群中会被反复放大。
第二是 CPU 开销高。传统协议栈需要 CPU 参与大量协议处理和内存拷贝,网络越忙,CPU 越容易成为隐性瓶颈。对于 GPU 训练节点来说,CPU 更应该服务于数据预处理、任务调度和系统管理,而不是被网络收发消耗掉。
第三是内存拷贝多。数据从应用缓冲区到内核缓冲区,再到网卡 DMA 区域,路径越长,消耗越大。对于大规模梯度同步而言,这些额外拷贝会直接影响吞吐。
RDMA(Remote Direct Memory Access,远程直接内存访问)正是为了解决这些问题而出现的。它允许一台主机的网卡在权限受控的前提下,直接读写另一台主机的内存,从而绕开传统内核协议栈中的大量开销。
RDMA 的核心价值可以概括为三点:
内核旁路(Kernel Bypass):应用程序通过用户态队列与 RDMA 网卡交互,数据路径不再频繁进入内核协议栈。 零拷贝(Zero-copy):数据可以在应用缓冲区之间直接传输,减少中间缓冲区拷贝。 硬件卸载(Offload):可靠传输、队列管理、部分拥塞处理由网卡完成,显著降低 CPU 参与度。
从 AI 训练的角度看,RDMA 的意义不是单纯“更快”,而是让 GPU 之间的数据交换更接近硬件级直连,减少通信对计算流水线的打断。
目前主流 RDMA 实现主要有三类:InfiniBand、RoCE 和 iWARP。其中,AI 集群最常讨论的是 InfiniBand 与 RoCE v2。
二、InfiniBand:为高性能而生的专用网络
InfiniBand(IB)诞生于高性能计算领域,从设计之初就不是“通用办公网络”,而是面向低延迟、高吞吐、可预测通信的系统级互联技术。它拥有独立于以太网的协议体系,从物理层、链路层、传输层到管理机制都为高性能场景服务。
可以把 InfiniBand 理解为一条为 AI/HPC 集群修建的“专用高速公路”:规则统一、路径可控、拥塞处理机制清晰,车辆类型也相对统一。因此它的性能上限和稳定性都非常突出。
InfiniBand 的关键能力包括:
原生 RDMA:InfiniBand 天然支持 RDMA,不需要在传统以太网之上额外模拟低损耗环境。 信用式流控(Credit-based Flow Control):发送端只有确认接收端具备足够缓冲资源时才会发送数据,从机制上降低丢包风险。 集中式子网管理:Subnet Manager 负责发现拓扑、分配 LID、计算路径和维护路由,网络行为更具确定性。 低延迟与高带宽利用率:在训练通信密集场景下,IB 往往能提供更稳定的尾延迟和更高的有效吞吐。 网络内计算卸载:例如 NVIDIA SHARP 可以在交换网络中完成部分聚合/归约操作,减少端节点之间的数据往返。
在大模型训练中,AllReduce 是典型的通信热点。传统做法需要 GPU 节点之间多轮交换和聚合数据,而 SHARP 这类网络内计算能力可以把部分规约操作下沉到交换机中完成,从而降低通信时延并提升集群效率。
目前 NVIDIA Quantum-2 InfiniBand 平台已经支持 NDR 400Gb/s 级别端口速率,并继续向更高速率演进。对于追求极致训练效率、预算充足且希望降低网络调优复杂度的万卡级集群,InfiniBand 仍然是非常强势的选择。
但它也有明显代价:硬件成本高,生态相对集中,运维人员需要理解 IB 特有的地址、路由、分区、子网管理等体系。它不是简单替换一台以太网交换机就能完成的方案。
三、RoCE:把 RDMA 带到以太网上
RoCE(RDMA over Converged Ethernet)试图回答另一个问题:既然以太网生态成熟、成本更低、人才储备更丰富,能不能在以太网上也跑 RDMA?
答案是可以,但需要付出工程复杂度。
RoCE 主要有两个版本:
RoCE v1:基于以太网二层封装,只能在同一二层网络内传输,扩展能力有限。 RoCE v2:在 UDP/IP 之上封装 RDMA,具备三层路由能力,是当前 AI 和云数据中心更常见的部署形态。
RoCE v2 的优势很清晰:它继承了以太网生态,可以利用成熟的交换芯片、光模块、布线体系、监控系统和运维经验,也更容易引入多厂商设备。对于云厂商和大规模企业数据中心来说,这意味着更好的供应链弹性和更低的综合成本。
但 RoCE 最大的挑战在于:以太网本质上是“尽力而为”的有损网络,而 RDMA 对丢包非常敏感。一旦出现丢包,重传和拥塞恢复可能让尾延迟急剧上升,集体通信性能也会明显抖动。因此,RoCE 需要通过一系列数据中心桥接与拥塞控制机制,尽量把以太网调成“近似无损”的环境。
常见关键技术包括:
PFC(Priority Flow Control,优先级流控):按优先级暂停特定流量,避免接收端缓冲区溢出。它可以减少丢包,但配置不当可能引发头阻塞、拥塞扩散甚至 PFC 风暴。 ECN(Explicit Congestion Notification,显式拥塞通知):交换机在队列拥塞时标记报文,由接收端反馈拥塞信息,让发送端提前降速。 DCQCN(Data Center Quantized Congestion Notification):RoCE v2 常用拥塞控制算法,结合 ECN 反馈动态调节发送速率,是大规模部署中的核心机制之一。 QoS 与队列规划:通过 DSCP/PCP、队列映射、缓存水线和流量隔离,避免训练流量、存储流量和管理流量互相干扰。
因此,RoCE 的本质不是“便宜版 InfiniBand”,而是“用以太网工程能力换取接近 RDMA 专用网络的性能”。它的上限很高,但对交换机配置、网卡参数、拥塞控制、拓扑设计和观测能力都有更高要求。
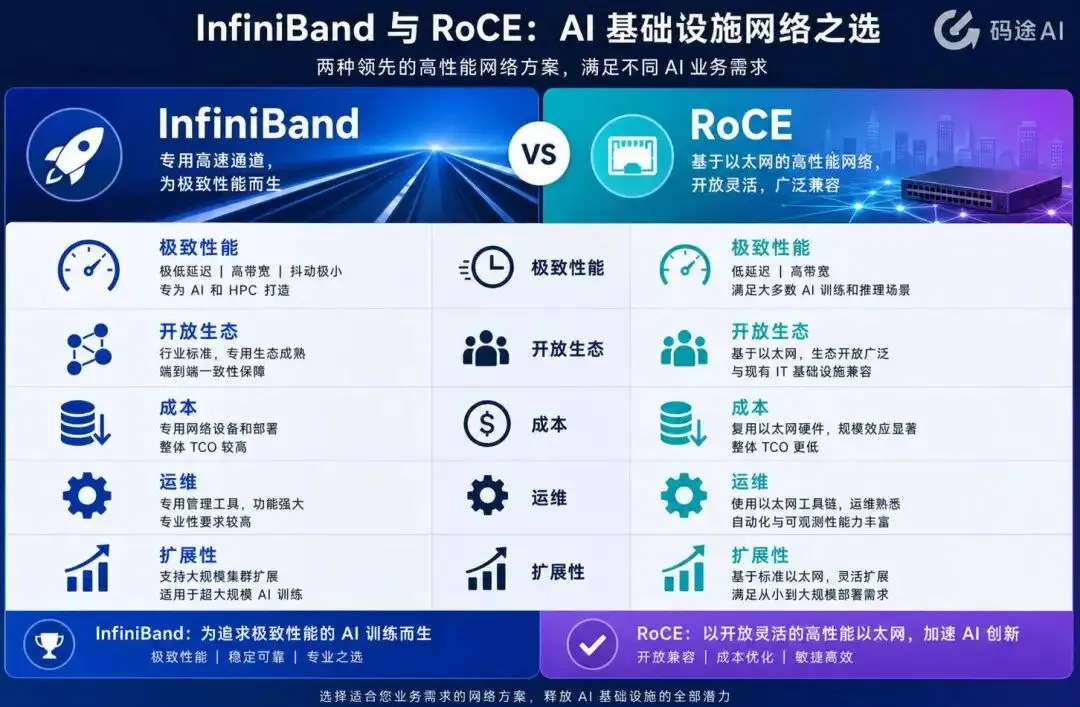
四、InfiniBand 与 RoCE 的核心差异
简单说,InfiniBand 更像“性能确定性优先”的路线,RoCE 更像“生态和成本优先,同时通过工程调优逼近高性能”的路线。
近几年,Meta 等大规模实践也证明,经过精细设计和调优的 RoCE v2 网络可以支撑非常大规模的 GPU 集群训练,并在特定场景下接近 InfiniBand 的训练效率。这说明以太网路线不是低端替代,而是一条正在快速成熟的高性能网络路线。
不过也要看到,RoCE 的成功并不只取决于买了支持 RDMA 的网卡和交换机。真正影响结果的是端到端工程:拓扑是否合理、PFC/ECN 阈值是否匹配、是否有足够遥测能力定位拥塞、故障域是否可控、业务流量是否隔离、NCCL 参数是否与网络能力匹配。
五、典型组网示例
理论上的协议差异,最终都会落到数据中心的真实组网里。下面用两个简化示例说明 InfiniBand 和 RoCE 在 AI 训练集群中的常见部署方式。
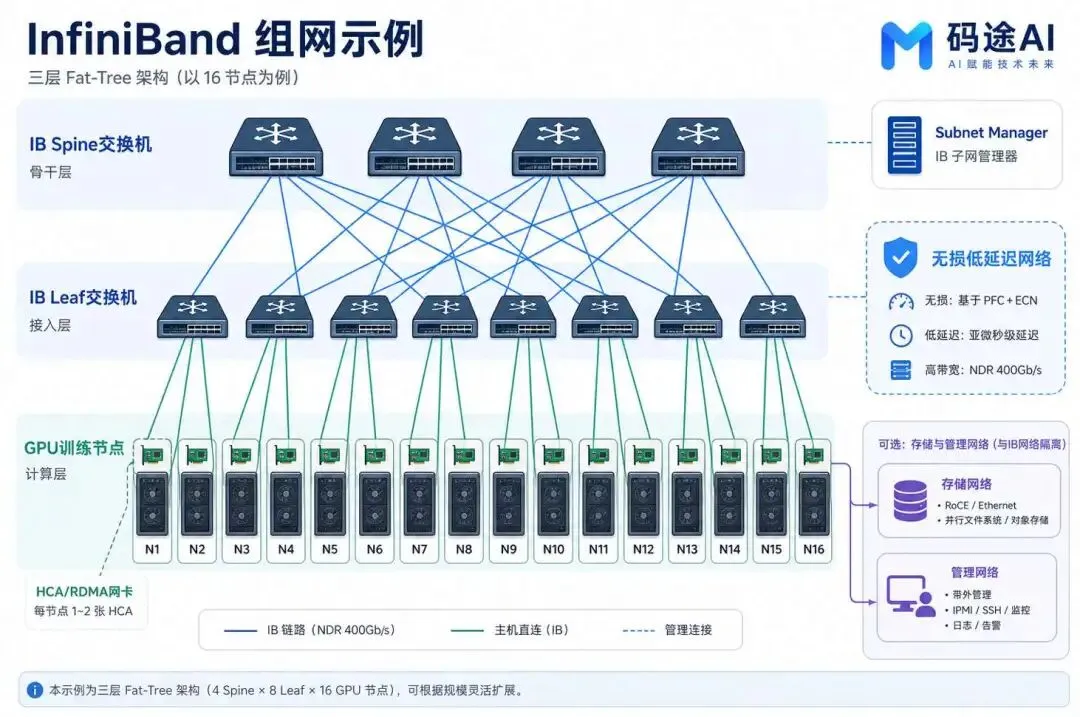
1. InfiniBand 组网示例:面向训练集群的 Fat-Tree
InfiniBand 集群通常采用 Fat-Tree 或类似 Clos 的多级拓扑。GPU 服务器通过 HCA/RDMA 网卡接入 IB Leaf 交换机,Leaf 再上联到 IB Spine/Core 交换机。Subnet Manager 负责发现拓扑、分配地址、计算路径和维护路由,训练流量在 IB 网络中保持低延迟、高带宽和强确定性。
在这个示例中,管理网络和存储网络可以与 IB 训练网络隔离,避免控制面、日志、存储访问等流量干扰 GPU 间通信。对于大规模预训练集群,这种隔离非常重要,因为训练网络需要尽量服务于 NCCL 等集体通信负载。
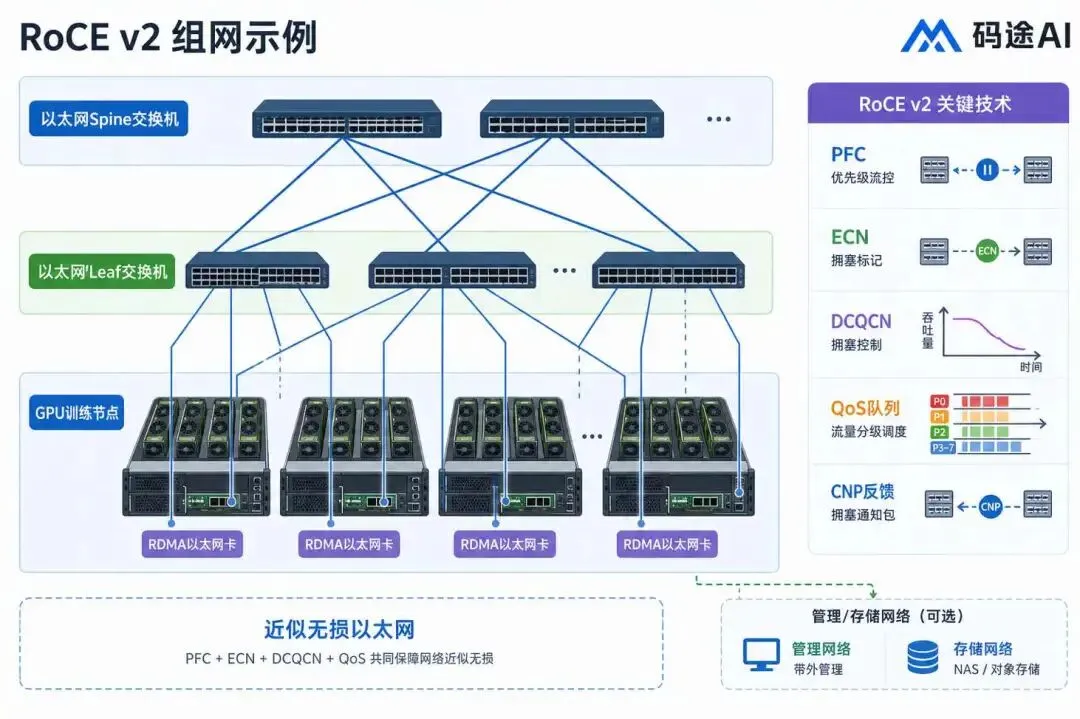
2. RoCE v2 组网示例:基于以太网的 Leaf-Spine
RoCE v2 集群通常基于标准以太网 Leaf-Spine 架构构建。GPU 服务器通过支持 RDMA 的以太网网卡接入 Leaf 交换机,Leaf 上联到 Spine 交换机,整体通过三层 IP 网络扩展。与 InfiniBand 不同,RoCE 需要依赖 PFC、ECN、DCQCN、QoS 队列等机制,把传统以太网调优成“近似无损”的高性能网络。
这种架构的优势是生态开放、设备选择多、容易与现有数据中心网络体系融合;挑战是参数调优和故障定位更复杂。实际部署时,通常会把训练流量、存储流量和管理流量分队列或分网络承载,并通过遥测系统持续观察队列水位、ECN 标记、PFC 暂停帧和丢包情况。
六、AI 网络中的几个关键补充技术
除了 InfiniBand 和 RoCE,理解 AI 算力网络还需要关注几个相关概念。
1. GPUDirect RDMA
普通跨节点通信中,GPU 数据往往需要经过 GPU 显存、主机内存、CPU、网卡等多个环节。GPUDirect RDMA 允许 RDMA 网卡在 PCIe 拓扑允许的情况下直接访问 GPU 显存,减少 CPU 和主机内存中转。
这对分布式训练非常关键,因为梯度和参数本来就在 GPU 显存中。如果每次都先搬到 CPU 内存再发送,会增加额外延迟和带宽消耗。GPUDirect RDMA 让“GPU 到 GPU”的跨节点通信路径更短,是现代 AI 集群的重要能力。
2. NCCL 与集体通信
NCCL 是 NVIDIA GPU 集群中最常见的通信库之一,负责高效实现 AllReduce、Broadcast、AllGather 等操作。它会结合 GPU 拓扑、NVLink、PCIe、网卡和网络路径选择通信算法。
网络能力越强,NCCL 越容易发挥多机多卡的整体效率。反过来,如果网络拥塞、丢包或拓扑不合理,NCCL 的集体通信会直接变慢,表现为 GPU 利用率下降、训练 step time 抖动、扩展效率变差。
3. iWARP
iWARP 是基于 TCP 的 RDMA 实现,优点是可以利用 TCP 的可靠传输能力,对传统 IP 网络更友好。但由于协议栈复杂、延迟和生态表现不如 InfiniBand/RoCE,在 AI 训练集群中存在感较弱。
4. Ultra Ethernet
Ultra Ethernet Consortium(UEC)由多家芯片、云和系统厂商推动,目标是构建更适合 AI/HPC 的下一代以太网能力,包括更好的拥塞控制、传输层机制、遥测和软件接口。它反映了一个趋势:以太网正在主动吸收高性能计算网络的能力,试图在开放生态中解决大规模 AI 通信问题。
5. 线缆与光互联
AI 集群网络不仅是协议问题,也离不开物理连接。常见连接方式包括:
DAC 铜缆:成本低、功耗低,适合机柜内短距离连接,常见距离通常在数米以内。 AOC 有源光缆:重量更轻、距离更长,适合跨机柜互联。 光模块 + 光纤跳线:适合更长距离、更大规模的数据中心布线,但成本和运维复杂度更高。
在高速网络中,线缆、光模块、连接器质量都会影响误码率和稳定性。对于 AI 集群来说,物理层小问题也可能被放大成训练任务的性能抖动。
七、如何选择:InfiniBand 还是 RoCE?
如果追求极致性能、低抖动和更强确定性,尤其是面向超大规模预训练、HPC 或万卡级集群,InfiniBand 仍然是最稳妥的高端路线。它的优势在于体系完整、性能可预测、与 NVIDIA GPU 生态结合紧密,适合“训练效率优先于网络成本”的场景。
如果更关注成本、开放生态、多厂商供应和与现有数据中心体系融合,RoCE v2 是非常有吸引力的选择。它适合云服务商、大型互联网公司、企业级训练集群,以及训练和推理混合部署的场景。但前提是团队具备足够强的网络工程和观测调优能力。
可以用一句话总结二者差异:
InfiniBand 用专用体系换确定性,RoCE 用开放生态换灵活性。
未来的 AI 网络很可能不是单一路线胜出。NVIDIA Spectrum-X、UEC、可编程交换芯片、端网协同拥塞控制、网络内计算等技术都在推动以太网继续进化;而 InfiniBand 也会在极致性能场景中继续保持竞争力。
对 AI 基础设施团队来说,真正重要的不是站队某一种协议,而是理解训练负载的通信模式、集群规模、成本约束和运维能力,然后选择最匹配的网络架构。
#AI算力网络#AI集群网络#GPU集群#分布式训练#RDMA#InfiniBand#RoCE#RoCEv2#以太网RDMA#NCCL#GPUDirectRDMA#PFC#ECN#DCQCN#LeafSpine#FatTree#HPC网络#万卡集群#大模型训练#数据中心网络
