五月最后一天了,做个全月总结,也想聊聊为什么最近从Agent相关内容全面转向了AI绘画。这篇文章没有像往常一样先在飞书上写好然后用skill自动渲染并推送到公众号草稿箱,而是直接在公众号后台撰写和发布,因此没有什么好看的排版。
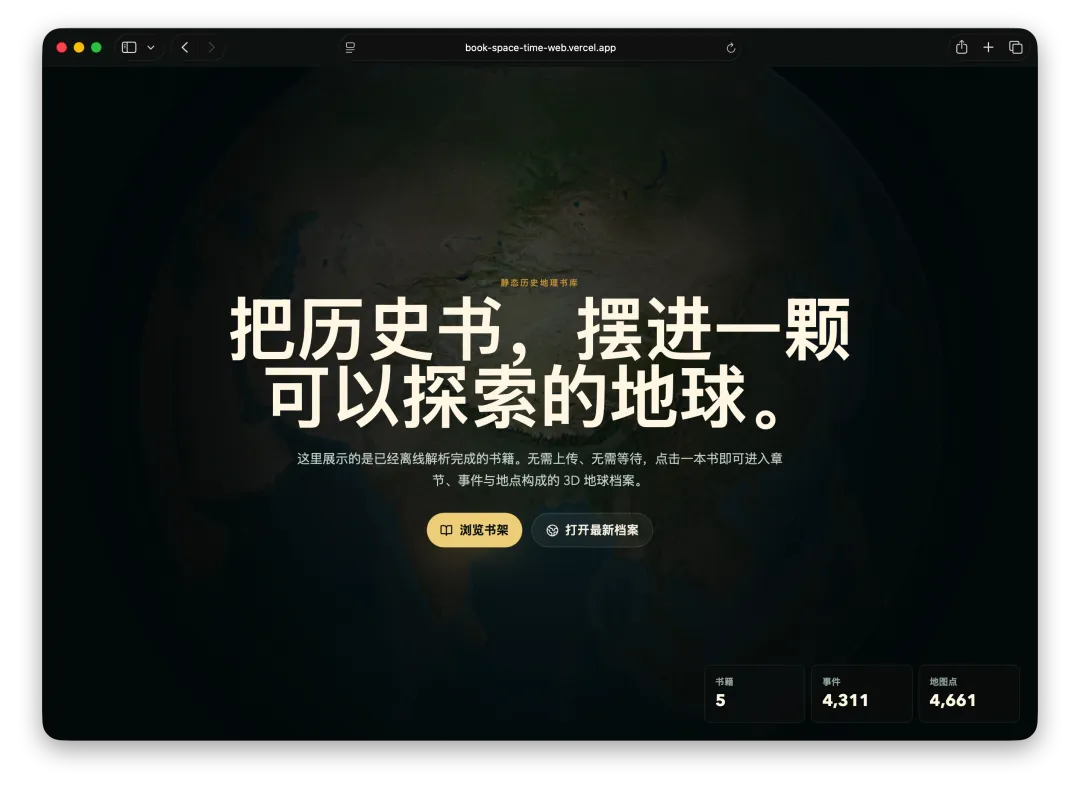
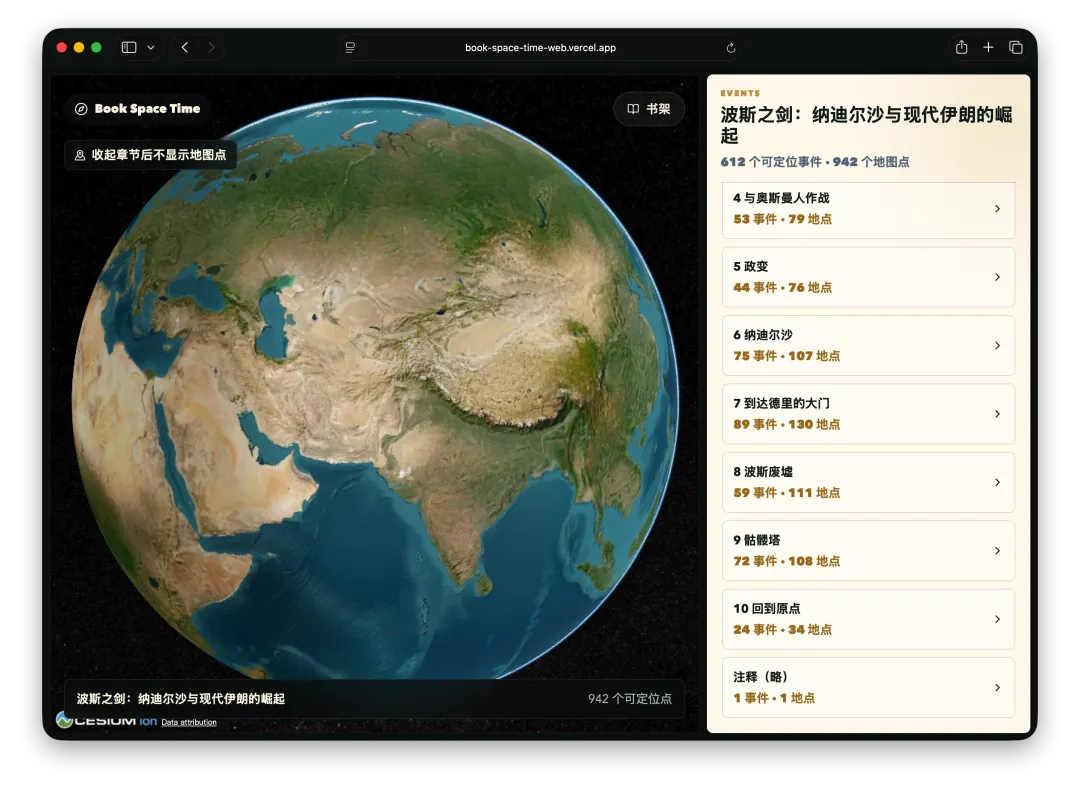
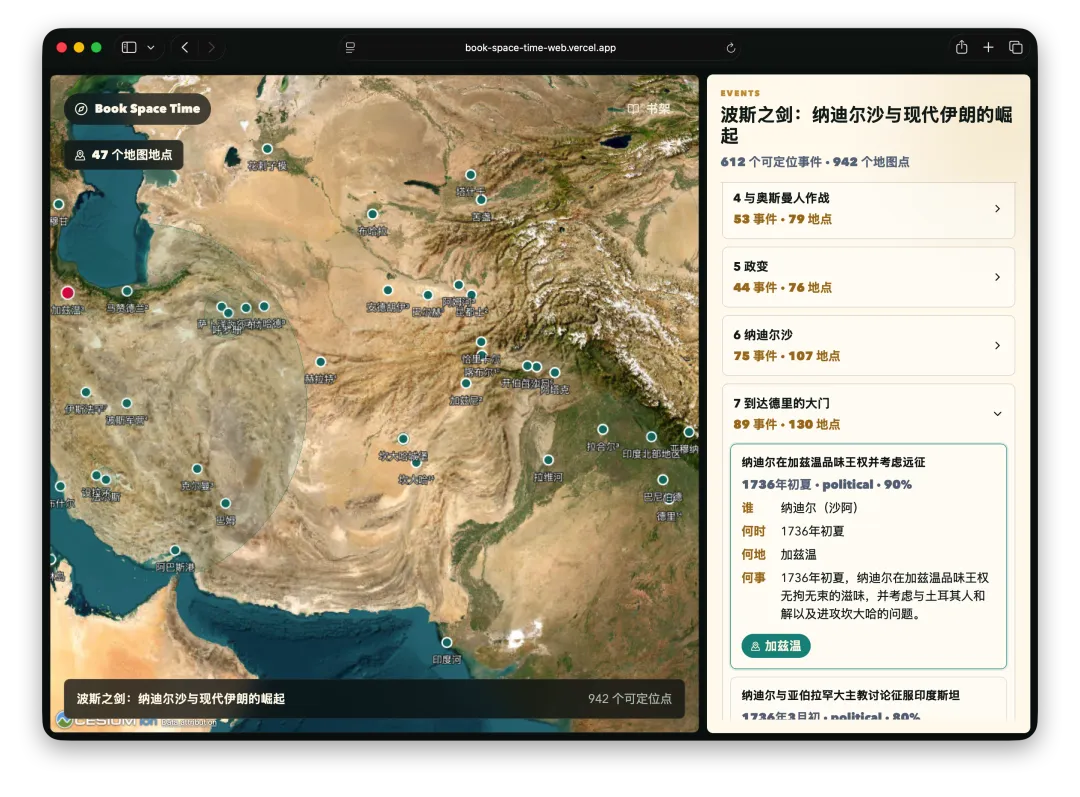
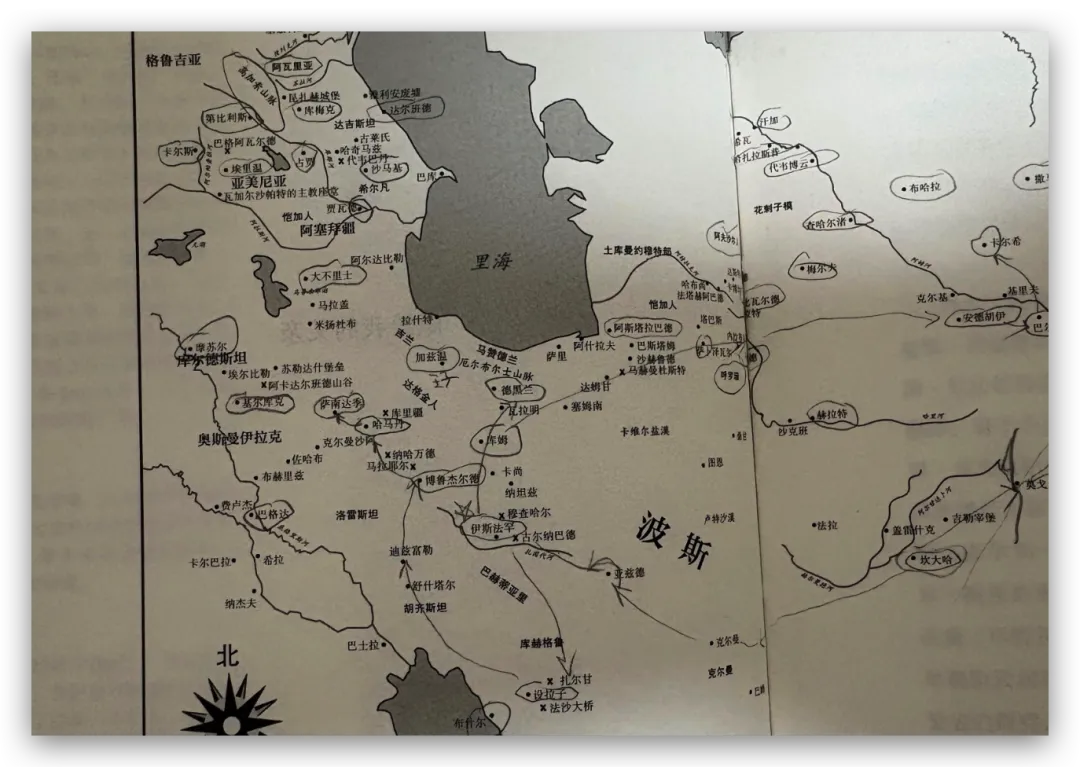
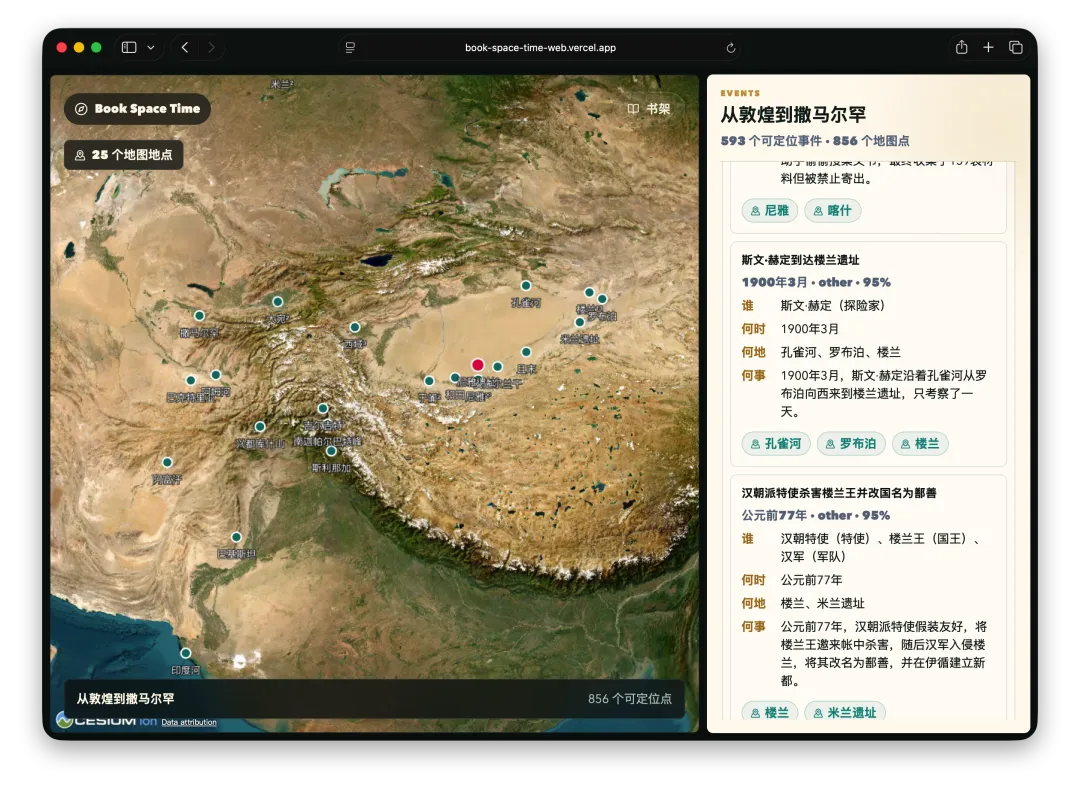
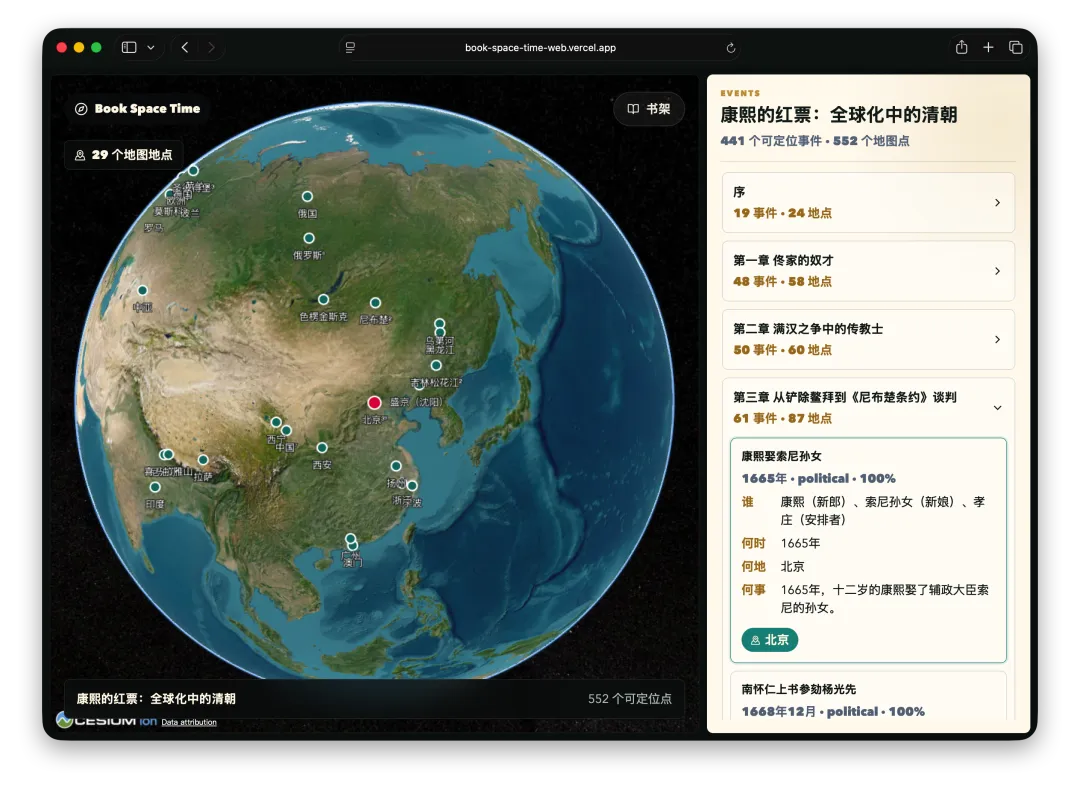
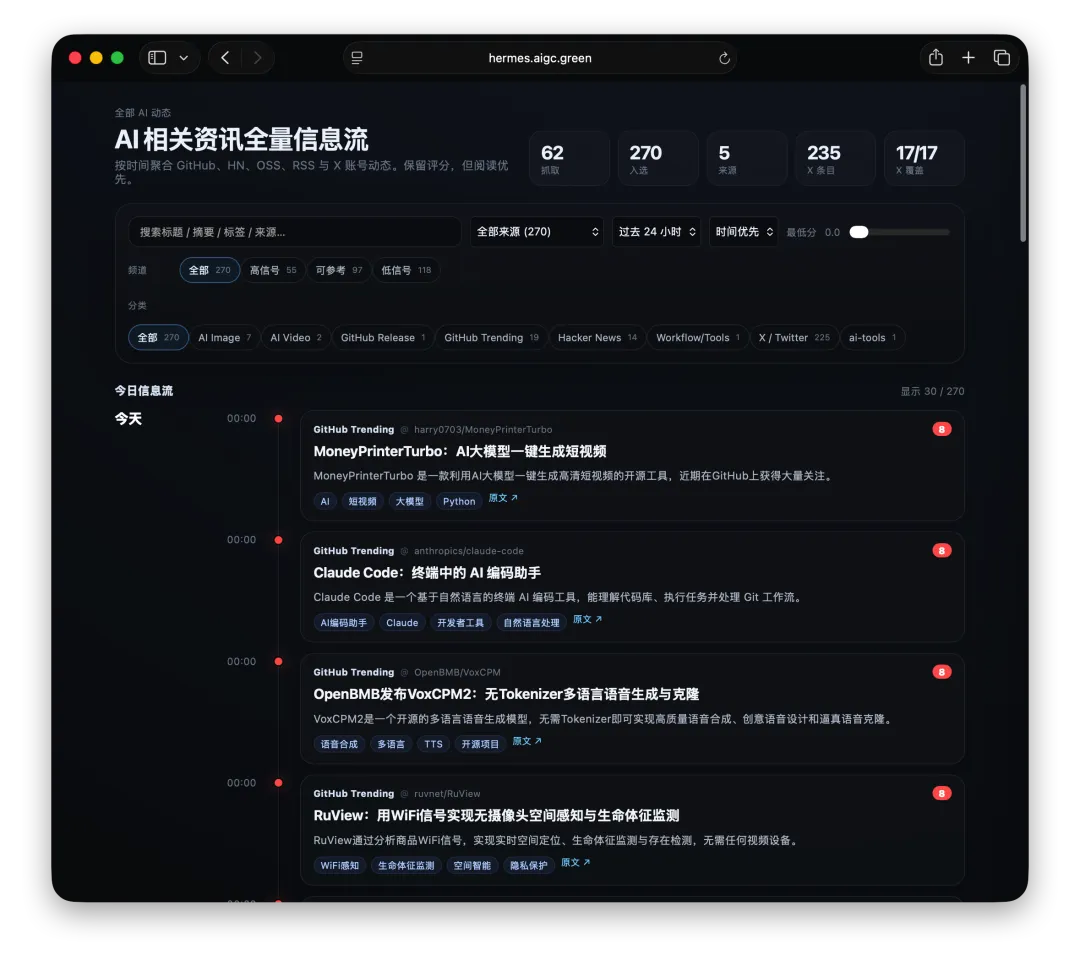
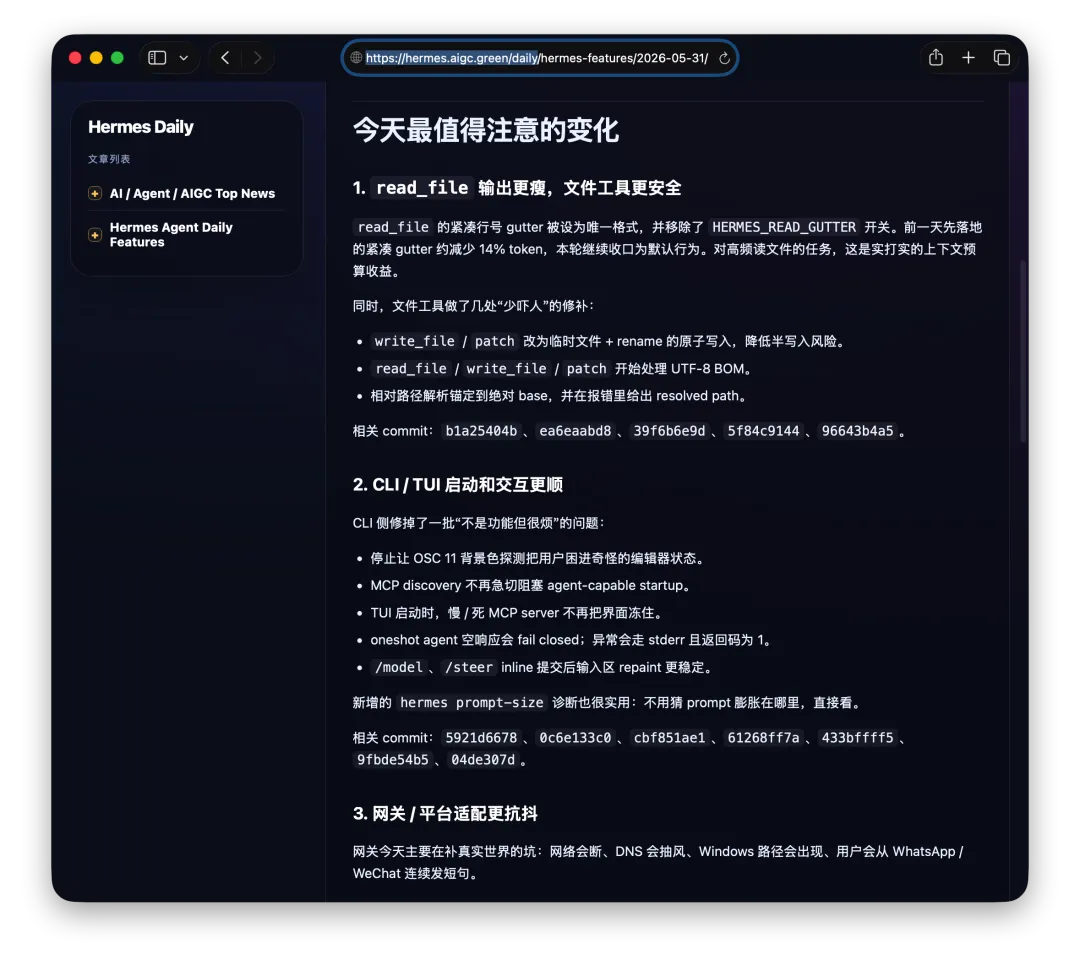
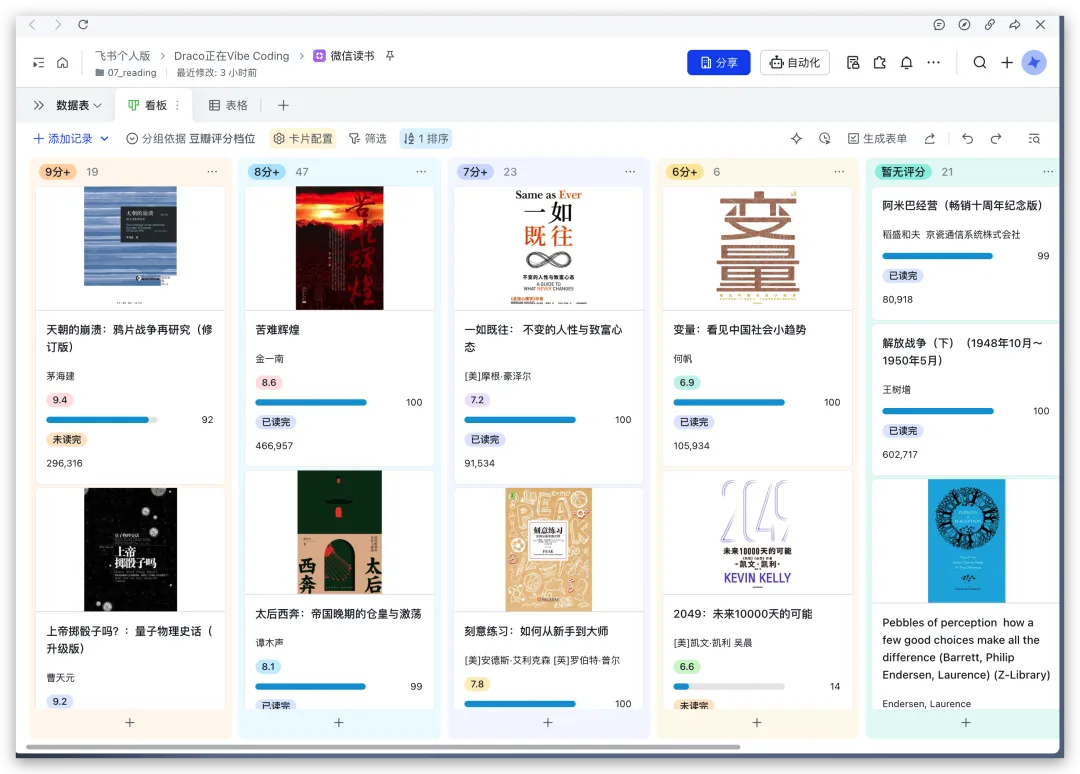
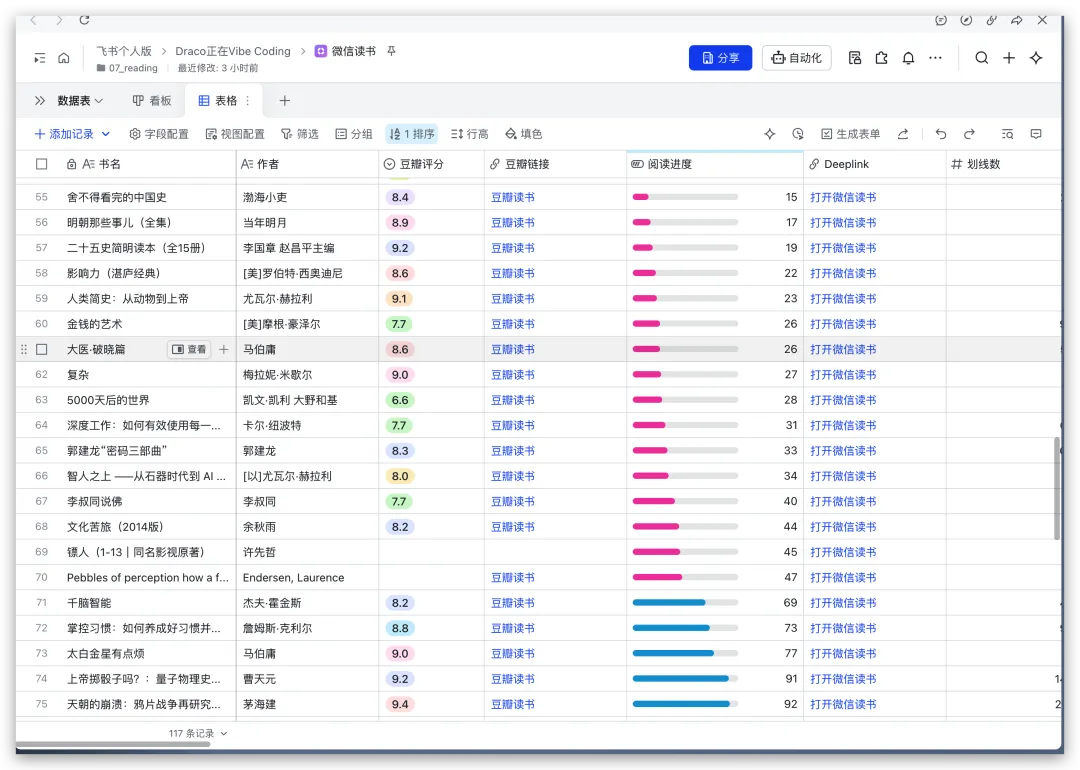
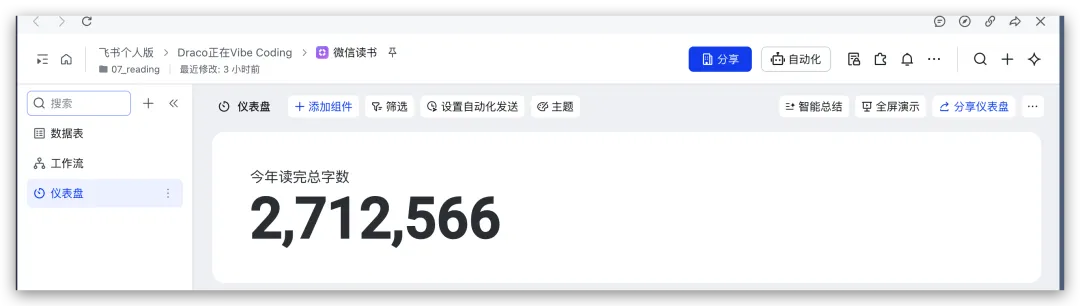
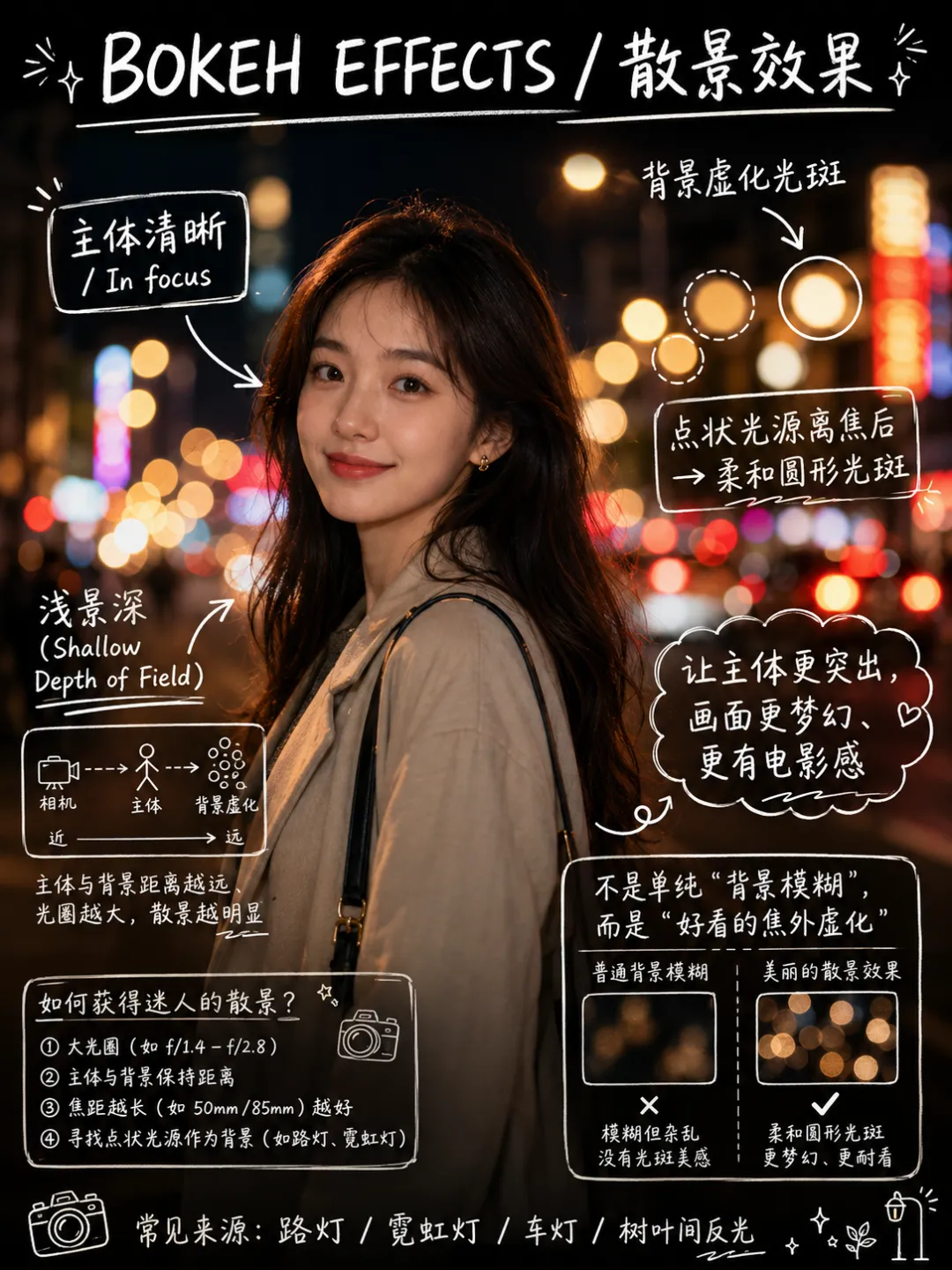
首先,经常看我公众号的朋友最近会经常问为啥写Agent写的少了。原因很简单,我认为目前的大模型和Agent能力都已经足够强了,已经超过了那条“人等Agent”的金线,现在基本上是Agent在等“我”,“我”明显成了瓶颈;现在,几乎无法给自己找到一个责怪Agent的理由,“太笨/太傻”这些词已经很难用得上,如果真要说个“太”,只能问自己:“是不是自己创意太不够用了?”复杂Coding的话,你就用Codex(CC Switch最新版本甚至可以让桌面版的Codex接入任意第三方模型)!如果你喜欢在飞书/钉钉/等IM工具上远程嘴控Agent干活,你就用Hermes!如果你喜欢积累自己的本地知识库,你就用Obsidian配合任何一个称手的Agent就行了。我不建议同学们再继续过于折腾各种五花八门的Agent了,Agent能力真的已经够用了;而且这些Agent也都是阶段性的,明年这个时候,99%的人大概率是用巨头封装好的和自身平台、生态有更深度融合的Agent(当然,国内巨头可能会掐断第三方Agent的一些关键权限来达到这个目的,就像过去二十多年那样;但这里不论对错只讲可能性),关键是你要用Agent来build什么,关键从来不在工具,而在你使用工具的目的/目标。没有一个八级钳工是因为他能把钳子玩的像武林高手一样,而在于他能解决机械设备的疑难杂症。你的问题从来就不是你能不能让Hermes在一个群里互相@讨论问题,而是即便你能让他们这么做了,然后呢? (其实这是个错误的multi-agnet使用方法,anyways今天不做过多讨论)1. 首先,最令我自己兴奋的是这个项目 Book: Space & Time (链接中试一个demo site) https://book-space-time-web.vercel.app/showcase昨晚读完了近30万字的《波斯之剑:纳迪尔沙与现代伊朗的崛起》,绝对是本神书,写的是18世纪初伊朗/波斯出了这么一位:一生骑行征战2万英里,打遍伊斯兰世界几无敌手,征服了伊朗、阿富汗、印度、中亚,几乎征服奥斯曼土耳其,差点消弭了伊斯兰什叶派和逊尼派之争的天才战神纳迪尔。书真是好书,就是他这2万英里的征程历经中亚/南亚/西亚数十座城市,书里只有一页黑白版没有海拔线的局部地图,你看不到山川河流,看不到海拔高度,看不到这个地区周边毗邻,实在是读的太痛苦了。于是就vibe了这么一个应用:把一本书的电子版输入进去,自动把书中的地名和事件标注在Cesium 3D地球仪上,山川地理海拔高度周边毗邻一目了然~ 读历史书的大杀器!我在demo站还放了《从敦煌到撒马尔罕》、《康熙的红票》等几优秀历史著作的case,有兴趣的同学可以去玩一玩~ 这个应用还在优化,目前最大的问题是有10%左右的false positive,会把同名的地名搞错,等我继续优化,6月份封装一个桌面版应用出来!(你基本只需要一个DeepSeek的API KEY就能用起来了)2. AI信源集合站:https://hermes.aigc.green/horizon-openrouter/index.html另外,还有之前用Hermes搭建的Hermes专项及AIGC信源站:https://hermes.aigc.green/daily/hermes-features/2026-05-31/ Hermes会自动总结Hermes Agent在过去24小时的commit/Release,以及AIGC相关信息~ 微信读书官方Skills发布之后,我这个书虫狂喜之余,顺手把自己的读书看板搭在了飞书上,哪些书读完了,进度如何,一目了然;Agent还补上了微信读书一直不给提供的豆瓣评分;架子搭起来了,但坦白讲,目前AI短视频还是太贵,对于我这种需要密集产出的,成本实在太高,我也的确自认还做不出Zombie Scanvenger这种神作,所以就先把AI短剧放在那里,底子有了,保持关注,直到成本再降一个数量级。真的爆肝了太多图了(Codex生图的quota让我烧冒烟了,不看是你的损失,哈哈哈)。2023年就为了Stable Diffusion+ComfyUI 装备了当时最先进的3090显卡,一年时间画了几万张图。另外,最近HTML vs MARKDOWN之争也的确揭露了一个本质:人终究是“多模态”生物,能看到图形图像的就不想只看文字。虽然文字是人类社会信噪比最佳的信息传递方式,但人的大脑只处理文字的比特率实在是太低了(据说前额叶主动处理文字信息的速度只有每秒几十比特...),图形图像就不一样了,一眼扫过去,上亿像素的信息一下就接受进去并且可以快速处理好,即便不是所有细节都get了,但那种通过颜色、形状所带来的‘roughly so’的感受是文字无法实现的。如果图片生成的速度、质量、成本都足够好了,直接生成图片不就好了么?另外,我强烈的直觉是:未来人类社会可能只需要1%甚至0.1%负责处理当前第一产业和第二产业的事就好了,剩下99%或者99.9%的人都是第三产业,是服务业,甚至绝大多数都是‘泛娱乐业’... 我甚至认为在未来的“学习”在本质上都应该是“泛娱乐”化的!给你们看一个我最近在研究AI绘画关键词时的case:我遇到了一个词汇‘bokeh effects’,于是让Agent用gpt-image-2生成了一张图解,呃...这个效果不要太好啊!不是一段话的解释,人家Agent直接把你关于这个概念需要了解的知识一次性拍到脸上了!你说这是学习还是娱乐呢?(关键是gpt-image-2的东方审美还不错,哈哈哈)总之,能用多模态方式呈现的,就不要用文字去呈现。如果你从娱乐的角度去看这个事,就不会觉得有什么难以理解的。只不过前文提过,视频现在成本太高了,所以图片可能是目前最好的balance point;并且,视频也是一秒24帧图构成的嘛(当然,H.264/265算法实现上肯定不是图片x24,要不视频体积就炸了,但不影响你这么理解)目前的AI绘画大模型在人类自然语言和图像之间搭建了一条快车道,如果你无法用准确的词汇去表达自己脑中的意象,你就无法得到你希望得到的图,就这么简单。但是,我的天,日常生活中,普通人的词汇是如何贫乏啊(我也是)!当你看到一张视觉冲击力强的图片时,你是能说得出它的风格呢,还是能讲地清楚它的构图呢?当你脑中出现一个人物形象时,你是能用准确的词汇描述ta的服饰、发型、姿态呢,还是能用概括清楚ta周围的环境呢,还是能精准约束镜头的角度、焦段、景别呢?你再把以上的这些要素组合在一起,那是近乎无穷的组合,不是么?我无法接受和面对脑海中存在意象但却无法把ta带到现实中的深深的无力感,因此爆肝了上文已经列出的各种和AI绘画的关键词百科(其实我手里还有几套,未来逐步释出)。经过这将近一个月的刻意练习,我似乎已经渐渐能够在看到一张图片时就知道还通过什么样的方式拆解并描述这张图了,对脑海中的意象也是类似的。哪些know-how可以交付给Agent,哪些必须放在自己的大脑中(也是个大模型)其实是个在Agent时代需要时刻谨慎对待的问题。我认为,最少AI绘画能力必须是要放在自己大脑中的。我强烈建议大家从现在开始在AI绘画上多下点功夫,多做做刻意练习,多积累和封装点词汇,为下个可视化、多模态的10年,多攒点基本功。
 夜雨聆风
夜雨聆风