 夜雨聆风
夜雨聆风云端 AI 要花钱,还担心数据泄露,国产大模型又怕数据泄露。你抽屉里吃灰的树莓派、淘汰的旧电脑,其实都能变成私人 AI 助手——完全免费、完全离线、数据不出门。今天教你一行命令搞定,手机电脑电视都能用。
能跑什么模型?先看硬件
一句话总结:4GB 内存能跑 0.5B-1B 小模型,8GB 能跑 3B 模型,16GB 能跑 7B 模型。 日常聊天、写邮件、翻译、代码补全,3B 模型就够用了。
一、安装 Ollama(一行命令)
方式一:App Store 安装
CasaOS App Store 搜索 「Ollama」 → 安装。如果找不到,用方式二。
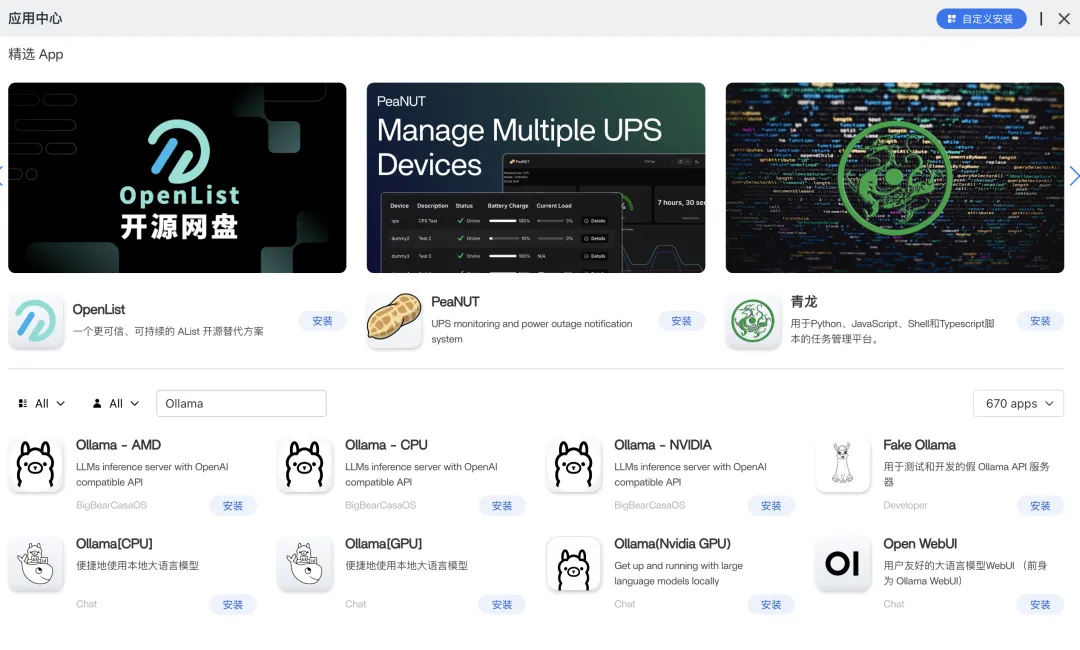
方式二:Docker Compose 部署(推荐)
CasaOS → App Store → 「+」 → Import from Docker Compose:
name: ollamaservices:ollama:image: ollama/ollama:latestcontainer_name: ollamarestart: unless-stoppedports:- "11434:11434"volumes:- /DATA/AppData/ollama:/root/.ollamaenvironment:- OLLAMA_KEEP_ALIVE=5m- OLLAMA_NUM_PARALLEL=1- OLLAMA_ORIGINS=*
部署完成后,Ollama API 地址是 http://你的 CasaOS-IP:11434。
二、下载模型
SSH 登录 CasaOS 设备,拉取模型:
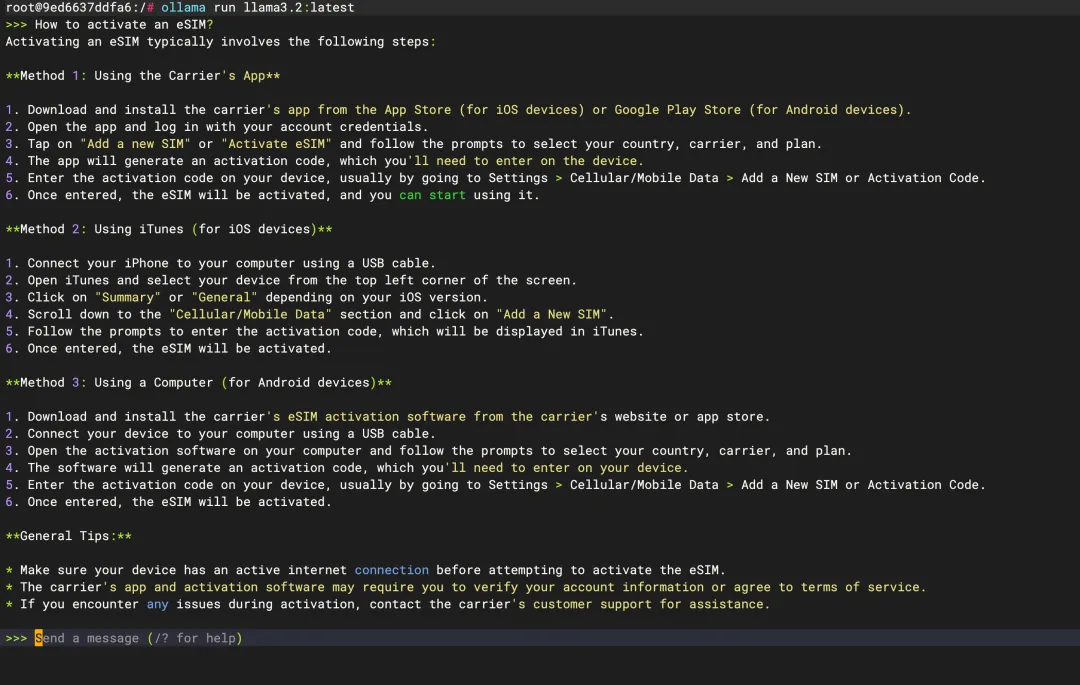
# 推荐:3B 参数,中文能力不错,内存友好docker exec -it ollama ollama pull qwen2.5:3b# 或者:Meta 出品,综合能力最强的 3B 模型docker exec -it ollama ollama pull llama3.2:3b# 或者:Google 出品,2B 参数,质量最高的小模型docker exec -it ollama ollama pull gemma2:2b# 或者:超轻量,1B 参数,4GB 设备也能跑docker exec -it ollama ollama pull gemma3:1b
下载完可以直接测试:
docker exec -it ollama ollama run qwen2.5:3b 「用一句话介绍 CasaOS」三、安装对话界面(Open WebUI)
光有命令行太朴素了。装个 Open WebUI,给你一个和主流 AI 对话工具一样的网页界面:
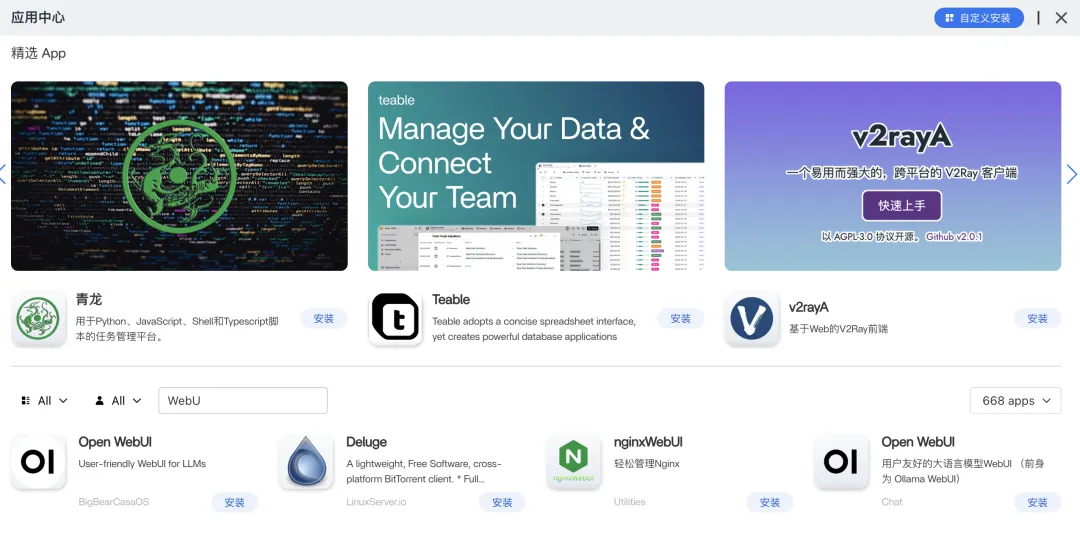
name: open-webuiservices:open-webui:image: ghcr.io/open-webui/open-webui:maincontainer_name: open-webuirestart: unless-stoppedports:- "3000:8080"environment:- OLLAMA_BASE_URL=http://ollama:11434volumes:- /DATA/AppData/open-webui:/app/backend/data
同样通过 CasaOS 的 Docker Compose 导入功能部署。
部署完成后,浏览器打开 http://你的 CasaOS-IP:3000:
第一个访问的人自动成为管理员 创建本地账号(纯本地,不联网) 左上角选择模型(比如 qwen2.5:3b) 开始聊天!
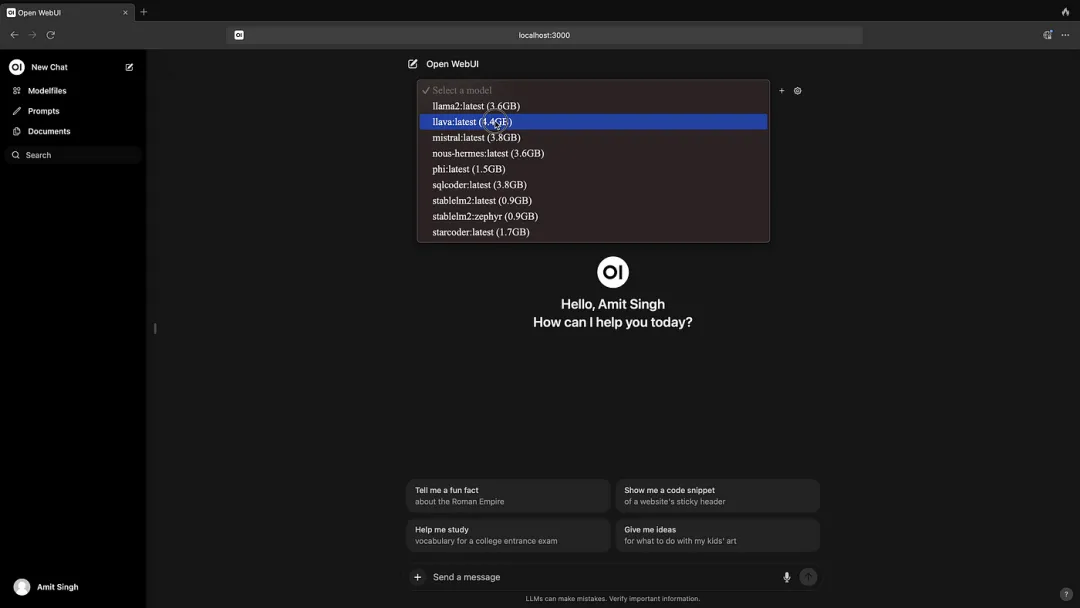
体验亮点:
界面简洁好看,体验丝滑 支持多轮对话、上下文记忆 支持 Markdown 渲染、代码高亮 可以上传文件让它分析 支持语音输入(浏览器端) 多用户管理,给家人也开个账号
四、推荐模型搭配
通用聊天(最推荐)
docker exec -it ollama ollama pull qwen2.5:3b中文能力最强的 3B 模型,聊天、翻译、写文案都行。
代码助手
docker exec -it ollama ollama pull qwen2.5:3bQwen2.5 的代码能力在 3B 级别也是最强的,支持 Python/JS/Go 等。
超轻量(4GB 设备)
docker exec -it ollama ollama pull gemma3:1b只有 0.7GB 下载体积,1B 参数,4GB 内存的设备也能流畅跑。
高质量(16GB 设备)
docker exec -it ollama ollama pull qwen2.5:7b7B 参数,质量接近主流云端AI,需要 8GB 以上内存。
五、手机也能用
Open WebUI 是网页版,手机浏览器直接访问 http://你的 CasaOS-IP:3000 就能用。
外网访问: 搭配 Tailscale(参考之前的教程),在外面也能用家里的 AI:
http://100.x.x.x:3000 ← Tailscale IP加到手机主屏幕,就是一个「APP」:
更多玩法:
接入微信机器人(wechat-bot + Ollama API) 接入 Home Assistant 语音助手 接入 Obsidian 做 AI 笔记助手 用 API 自己写应用: http://你的IP:11434/v1/chat/completions
六、ARM 设备性能实测
树莓派 5(8GB)实测数据:
3B 模型在树莓派 5 上约 4 token/s,大概每秒生成 2-3 个字,对话体验基本流畅。7B 模型就比较慢了,回复需要等一会儿。
七、常见问题
Q:Open WebUI 连不上 Ollama? A:确保 OLLAMA_BASE_URL 用的是容器名 http://ollama:11434,不是 localhost。如果 Ollama 和 Open WebUI 不在同一个 Docker Compose 文件里,用实际 IP 地址。
Q:模型下载特别慢? A:Ollama 模型托管在海外,国内下载可能很慢。可以切换网络环境,或者用 Ollama 镜像源。也可以先下载到本地再导入容器。
Q:跑模型时设备很卡? A:模型推理会占满 CPU 和内存。建议在 CasaOS 里给 Ollama 容器设置 CPU 和内存限制,避免影响其他服务。或者只在需要时启动,用完停止。
Q:数据安全吗? A:完全本地运行,不联网,数据不出你家局域网。Open WebUI 的账号、对话记录全部存在本地。这是本地 AI 最大的优势。
Q:和云端 AI 比怎么样? A:7B 模型大约是主流云端AI的水平,3B 模型日常够用但复杂推理能力弱。优势是免费、无限制、离线、隐私。如果你需要 更高级别的能力,还是得用云端服务。
AI 不是大厂的专利。一台吃灰的旧设备,就能跑一个完全属于你自己的 AI 助手——免费、离线、隐私安全,还能给全家人都开个账号。省下的会员费,一年就是一两千块。
💬 互动时间
你有什么吃灰的设备打算复活?树莓派、旧手机、还是淘汰的笔记本?评论区聊聊你的计划!
👉 觉得有用的话,点个「在看」转发给对 AI 感兴趣的朋友,告诉他们不用花钱也能用 AI。
📌 关注「飘落的数码折腾日记」,后续更新:废旧主机变影视墙、全家自动去广告、NAS 外网访问终极方案,一个都不少。
