 夜雨聆风
夜雨聆风转载请注明出处:微信公众号 gipcenter

使用大语言模型进行国际工程合同风险识别与合同风险分担判断,需要将招标文件中的合同条件及其要件电子版文本投喂给模型。要想充分发挥大语言模型的能力,投喂给模型的合同文本电子版需要是干净的、符合模型处理要求的文本格式,这直接决定了模型后续处理和输出的准确度。然而,实践中国际工程合同文本电子版常以PDF格式保存和传阅,而且有些PDF格式文件还掺杂其他信息,但大语言模型只能接收纯文本格式,PDF格式文件无法直接作为模型的原始输入。
国际工程合同条件的合同条款是合同风险识别与合同风险分担判断最基本的单元,从合同条件文本中高效提取合同条款内容是国际工程合同风险分析的首要步骤。当合同条件文本的合同条款数量较多时,如果由人工对照PDF格式文件录入所有条款内容既费时又费力,还需要严格、认真的校对工作。因此,需要一套能自动实现合同文本解析与合同条款提取的方案。
2024年上海人工智能实验室OpenDataLab团队推出了智能数据提取工具MinerU。他们提供一整套PDF格式文件解析的开源解决工具,可将混合图片、公式、表格、脚注等在内的复杂多要素 PDF 格式文件转化为可供大语言模型使用的Markdown文本格式。其核心思想是基于多模块的文件解析策略,使用PDF-Extract-Kit库中的优秀开源模型完成各模块的识别任务。凭借快速准确、开源易用的能力特性,MinerU受到广大用户的青睐。截止2026年5月,MinerU在github网站上收获65.7K的点赞量,是目前用户反响很好的PDF格式文件解析工具。
天津大学全球工程经营团队设计了一套“基于MinerU框架的合同文本解析 — 用户校对并修改解析结果 — 基于适配规则的条款提取”的三阶段处理方式,从而实现了从国际工程合同条件PDF格式文件中准确提取合同条款的功能,为大语言模型合同风险识别与合同风险分担判断提供了高质量的合同文本输入。
第一阶段:基于MinerU框架的合同文本解析
MinerU支持网页端、桌面端、应用程序编程接口(API)调用、本地部署等多种使用途径,考虑合同文件的保密性要求,推荐采用本地部署方式。本地部署的解析后端支持三种模式:
1)Pipeline:传统OCR流水线结构,无需加载大模型,可在中央处理器(CPU)上运行,速度较快,精度较低;
2)Vlm-auto-engine:使用视觉语言模型(Vision Language Model,VLM)进行布局检测分析,需要在图形处理器(GPU)上运行,速度较慢,精度较高;
3)Hybrid-auto-engine:OCR技术负责基础文本识别,VLM负责复杂的元素理解和语义分析,其中OCR和VLM的分工是自动完成的,速度和精度理论上均居于上述两种模式之间。
由于Pipeline模式的精度较低,不足以实现对合同条款的有效提取,我们使用多样的合同范本对比Vlm-auto-engine与Hybrid-auto-engine模式的解析效果。考虑项目合同条件长度、PDF格式文件类型的差异,选取的测试合同范本为FIDIC1987版《土木工程施工合同条件》(非扫描件PDF)、FIDIC1999版《简明合同条件》(扫描件PDF)、FIDIC1999版《生产设备与设计—建造合同条件》(非扫描件PDF)、FIDIC2017版《生产设备与设计—建造合同条件》(非扫描件PDF)。以上四个合同范本均测试其合同条件部分。
将测试使用合同条件文本输入MinerU后,其工作流程可分为以下步骤:
1)合同条件文本预处理:过滤无法处理的合同文本,进行语言识别、内容乱码检测、扫描件PDF识别,并提取合同文本元数据;
2)合同内容解析:使用PDF-Extract-Kit库,利用布局检测模型检测出合同页面上不同区域的标题、文本内容、表格等类型要素,然后针对不同的要素使用各自对应的识别器进行单独识别;
3)合同内容后处理:去除无效区域,根据区域定位信息对不同区域进行拼接以确定阅读先后顺序;
4)格式转换:根据后处理的结果,转换成用户友好的阅读格式,如Markdown格式或自定义JSON格式。
测试结果发现Hybrid-auto-engine解析模式下,四个合同范本的解析共性问题包括:
1)条款号或条款标题(一般指二级条款)有可能出现识别遗漏,如图1所示。
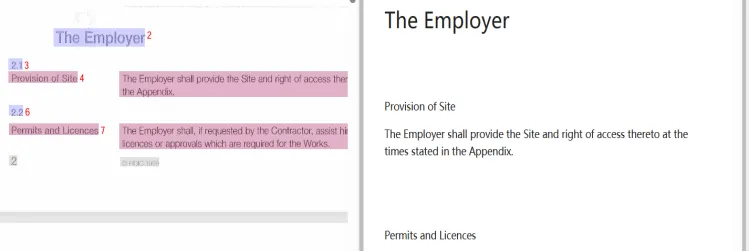
图1 条款信息识别遗漏示例
2)对于页面上的元素,可能出现将文本块识别成表格的不稳定问题,如图2所示。
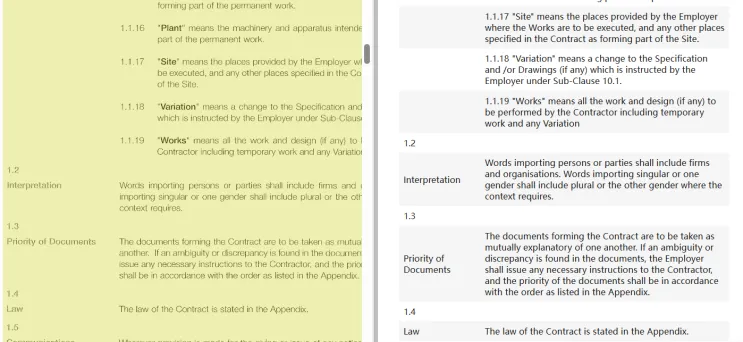
图2 条款文本块识别成表格示例
3)对于条款号、条款标题、条款内容布局顺序的识别错误,可能会错层,如图3所示。

图3 条款内容顺序识别错误示例
4)小概率出现OCR识别乱码,如图4所示。

图4 OCR识别乱码示例
Vlm-auto-engine解析模式下,布局检测效果与Hybrid-auto-engine模式完全一致,表明布局检测的不足依然存在,如纯文本识别成表格,条款内容、条款号或条款标题顺序出错。VLM模式带来的效果提升主要在文本识别方面,能显著降低文本遗漏、文本识别乱码的问题,且代码运行时长并没有显著增加,仍能在秒级范围内给出结果。因此,将选择Vlm-auto-engine模式对PDF格式文件进行解析。
第二阶段:用户校对并修改解析结果
根据对MinerU的PDF格式的合同文件解析测试结果分析,条款号、条款标题、条款内容的遗漏是有可能发生的,且文本内容提取有小概率出现乱码。如果不对这两类问题进行校对,后续输入大语言模型的合同条款内容在一定程度上会偏离原合同表述,从而干扰合同风险识别与合同风险分担判断。因此,需要设计MinerU解析结果的校对与修改功能。该功能必须由人工进行校对而非计算机程序判断,程序无法衡量PDF格式的合同文件的原有表述是否与当前解析结果冲突。需有对合同文件解析结果的用户校对与修改功能,类似如图5给出的界面示例。
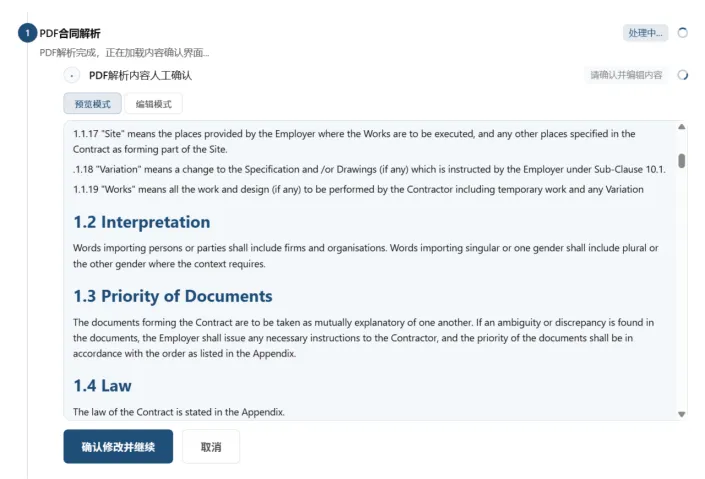
图5 合同文件解析结果的用户校对与修改功能界面示例
第三阶段:基于适配规则的条款提取
合同文件经MinerU解析和用户校对后的Markdown结果包含了丰富的合同条款信息,但也存在噪声内容与其他非结构化元素,难以直接用于后续大语言模型合同风险识别与合同风险分担判断。我们设计了基于适配规则的条款提取方案,用于对Markdown结果进行清洗、转换与重构,提取出结构化的合同条款,为大语言模型的合同风险分析提供规范的输入数据。Markdown处理和条款提取步骤包括:
1)图片内容过滤:通过正则表达式匹配并删除Markdown中的图片嵌入语句;
2)超文本标记语言(HTML)表格转换:采用正则表达式,将纯文本合同条款错误解析为带“<table>标签”的HTML表格形式转换为纯文本;
3)标题标识符清理:移除每行开头的Markdown标题符号,使标题内容回归纯文本形式,便于后续统一处理;
4)合同条款号识别与合并:通过正则表达式识别合同条款号行,并采用贪婪合并策略,将条款号行之后的内容按行依次合并,直到遇到新的条款号行、标点结尾或长文本(>9个单词)为止。合并后的完整合同条款内容前自动添加“#”标识符,用于后续文本块切分;
5)文本块切分:将处理后的Markdown文件按“#”开头的行作为分隔符,切分出若干独立的文本块。每个文本块对应一个二级合同条款,相比于一级条款和三级条款,二级条款在文本长度与信息量上较为适中,因此将二级合同条款作为后续合同风险分析的基本单元;
6)多文件格式输出:将切分出的二级合同条款导出为Excel文件,便于后续人工复核或大语言模型输入。提取后的合同条款示例见图6。

图6 国际工程合同条款自动化提取结果示例
这套三阶段国际工程合同条件的合同条款自动化提取方案兼顾了解析效率与结果准确性,通过规则驱动的后处理逻辑有效适应了国际工程合同条件结构和条款编号特点,可为后续基于大语言模型的合同风险识别与合同风险分担判断提供高质量的合同条款输入。
国际工程承包企业在使用MinerU这类文本清洗和处理工具时,要特别注意数据的保密性和数据使用的合规性问题,因此我们再次建议采用本地化部署的方式使用这些软件工具。
下期预告
往期推荐



(点击标题跳转)
内容来源 /甘一鸿、麻佩、张明宇
责任编辑 / 高颖
图文编辑 / 任玉莹

