 夜雨聆风
夜雨聆风加入新团队,接手一个十多万行代码的遗留系统,没有文档、逻辑错综复杂。你是选择硬啃源码,还是默默叹气?本文为您揭秘 GitHub 爆火项目 Understand-Anything 的底层架构和工程实现,看它如何以“Tree-sitter + LLM”的混合引擎,重塑开发者的代码探索体验。
混合引擎:Tree-sitter 静态解析与语义增强 |
在现代软件工程中,理解代码往往比编写代码消耗更多的时间。对于新加入团队的开发人员而言,面对庞大且缺乏文档的庞然大物,常常如同在黑夜中摸索。即使是经验丰富的架构师,在评估跨模块重构的影响时,也容易遗漏潜在的依赖链条。
Understand-Anything 的横空出世正是为了解决这一痛点。它是一款集成了静态语法解析与大语言模型(LLM)能力的开源工具,能够扫描整个代码库,将其转换为包含文件、类、函数及相互关系的交互式知识图谱 (Knowledge Graph)。它能无缝嵌入到 Claude Code、Cursor、GitHub Copilot 以及 Gemini CLI 中,为开发者配备一个“上帝视角”的 Dashboard。
单独依靠传统静态解析(AST),我们只能获取语法层面的引用,而无法还原抽象的“业务场景”和“设计意图”。而完全依靠 LLM 逐行读取代码,不仅 Token 成本极度昂贵,生成结果也极不稳定。
Understand-Anything 采用了极为精妙的 Tree-sitter + LLM 混合双轨架构,实现了效率与深度的完美折中:
1. Tree-sitter(确定性静态解析):在本地极速解析源码,构建抽象语法树。提取所有 imports、exports、定义及函数调用链。同一套代码每次生成的结构 100% 相同,保证了图谱骨架的绝对稳定性。2. LLM(语义化高级分析):以 Tree-sitter 提取出的结构及文件上下文为输入,用 LLM 提炼通俗易懂的中文摘要、标记功能标签、推断架构分层(如 API/Service/Data/UI)并自动归纳核心逻辑。
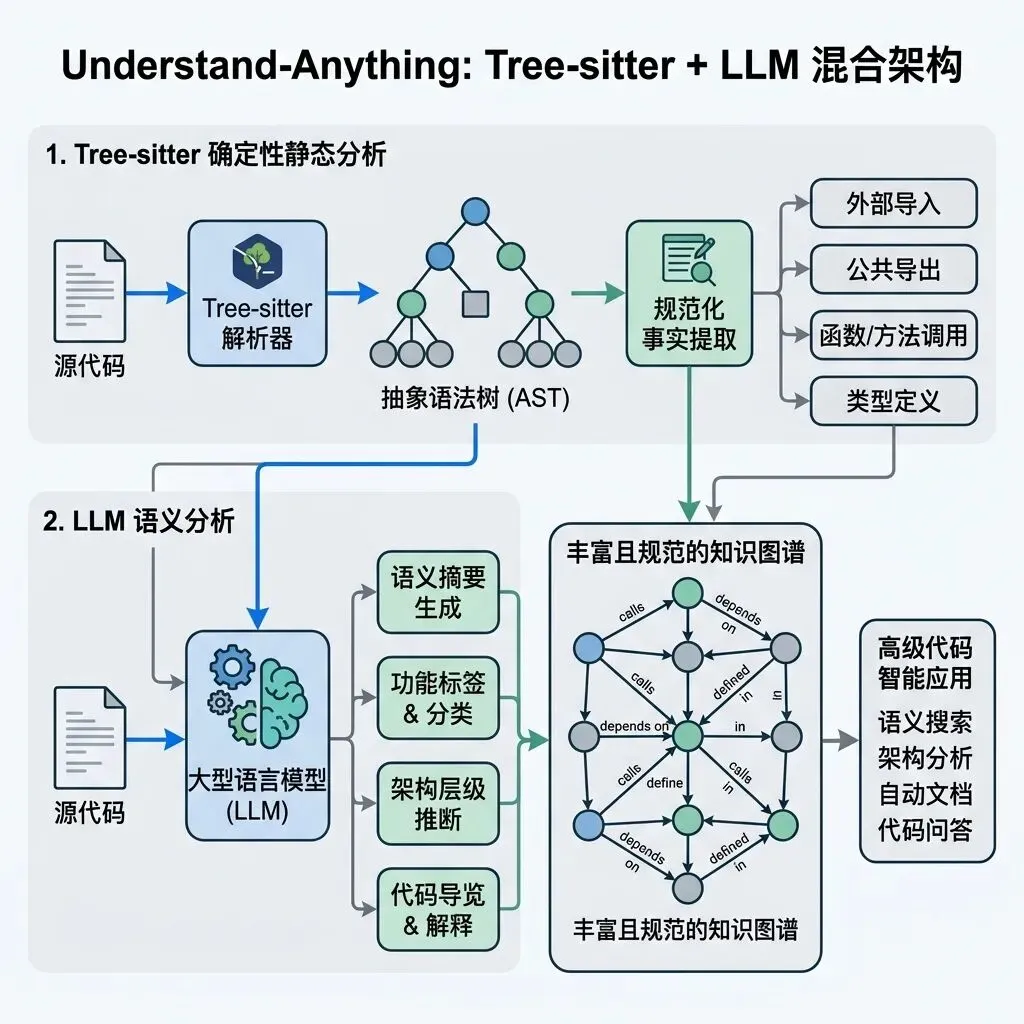
图 1:Tree-sitter 静态提取与 LLM 语义增强的双流协作架构
这种设计将底层关系建立在坚实的 AST 结构之上,极大避免了传统 RAG(检索增强生成)机制中,智能体因为检索顺序缺失或语义切割而产生的幻觉。
分布式协同:多智能体并发分析流水线 |
当你在控制台输入 /understand 指令时,Understand-Anything 内部会启动一个由 4 个专属智能体构成的分析流水线。每个 Agent 各司其职,保证了整套工作流能处理超大型项目。
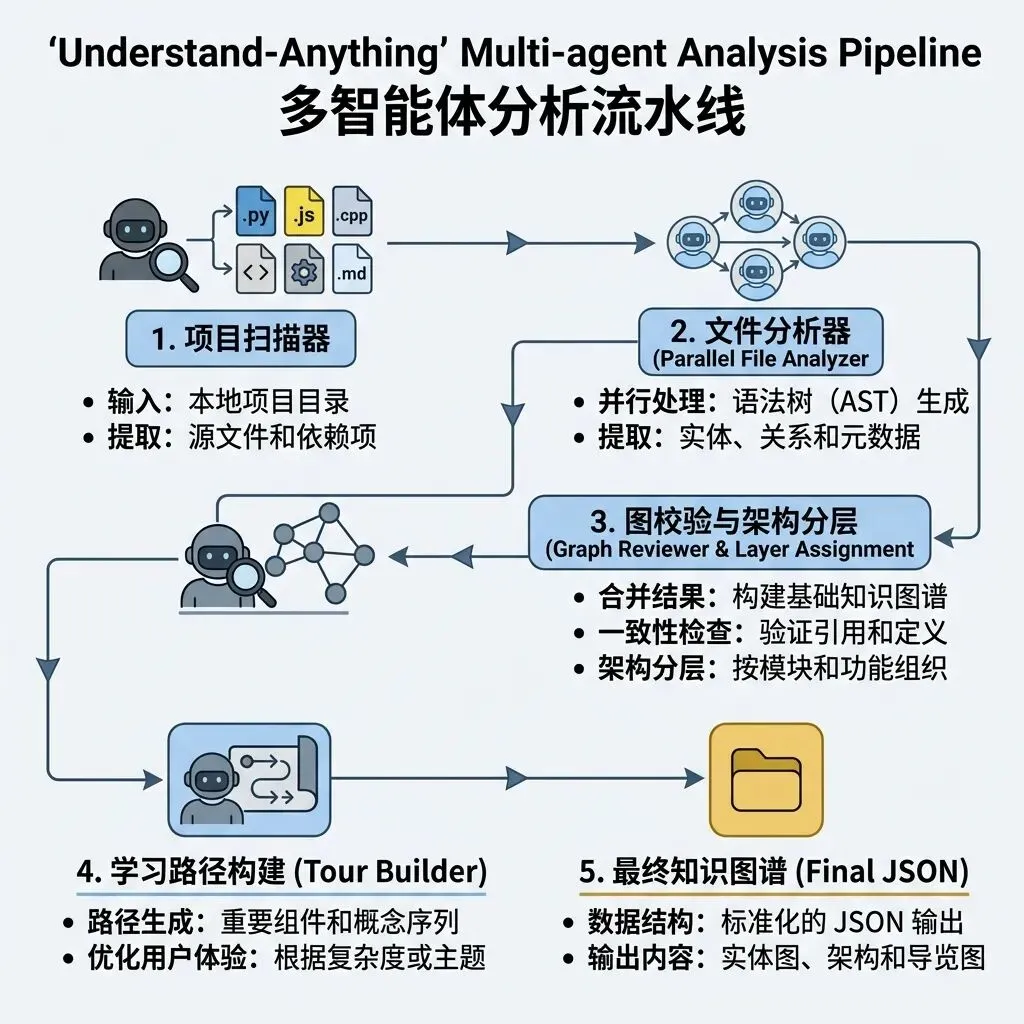
图 2:多 Agent 流水线处理模型与各阶段输出资产
| 1 |
| 2 |
| 3 |
| 4 |
为了避免每次修改都重新扫描整个库,Understand-Anything 引入了基于 Git Commit Diff 和文件 SHA-256 哈希的两级增量校验机制。当再次运行时,系统会先通过 Git 识别变更文件,计算结构指纹(Structural Fingerprint)。如果修改仅为注释或空格(COSMETIC 变更),则完全跳过分析;仅当核心代码逻辑、方法签名被修改时(STRUCTURAL 变更),才会按批次唤醒 LLM 文件分析器进行局部重析并动态合并图谱。
触手可及:交互图谱、影响分析与多维搜索 |
一旦通过 /understand 生成了 .understand-anything/knowledge-graph.json,您就能解锁一整套极具爆发力的辅助功能:
| + | 交互式图谱探索 (Interactive Dashboard):/understand-dashboard 即可在本地唤醒一个 React + ELK 引擎渲染的拓扑网络。您可以拖拽、缩放、聚焦某个关键函数节点,直观查看调用链路与被调用链路。 |
| + | 变更影响范围评估 (Diff Impact Analysis):/understand-diff,智能体可以在你 commit 之前,评估当前工作区所做修改可能影响到的其他不相干业务模块,杜绝“改一处,垮全站”的灾难。 |
| + | 多维语义搜索 (Fuzzy & Semantic Search): |
| + | 自动构建学习向导 (Guided Onboarding Tours): |
由于知识图谱完全是可读的 JSON 结构,团队成员只需提交一次 .understand-anything/knowledge-graph.json 到 Git 仓库中,其他队友拉取代码后即可直接运行可视化 Dashboard 探索,无须重复消耗昂贵的 LLM Token。系统提供了 --auto-update 挂钩(Git Post-commit hook),在每次提交时增量追加图谱变更,保持团队图谱时刻新鲜。
快速落地:三步解锁代码库全局视角 |
在各大 AI IDE / 命令行终端上部署十分简单:
同类对比:与 Graphify 及 code-review-graph 的核心差异 |
在代码库理解、知识提取和智能代码评审领域,本专题此前已深度解读过 Graphify(专注于知识归类与社区聚类)以及 code-review-graph(专注于精准增量评审)。我们来对比一下这三者之间的核心定位,方便您根据开发场景进行技术选型:
• Understand-Anything:专注于全库业务/代码依赖的双向可视化与团队/新人 Onboarding 教学导览。通过 Tree-sitter + 多智能体分析流水线,将庞大的源码库编译成包含 Domain/架构视图的 Web Dashboard。
• Graphify:专注于非代码知识库归纳、多源文本(白板、设计文档、截图、学术论文等)实体提取与社区聚类。通过 NetworkX 图拓扑和 Leiden 聚类算法分析知识点,归纳出核心主题列表。
• code-review-graph:专注于精准的增量代码变更(Diff)依赖分析与 AI 智能代码审查(PR Review)。作为 MCP Server 提供后台服务,在用户提交时过滤变更文件,在 IDE 内为智能体提供精准上下文以降低大模型 Token 账单。
总结来说:如果您需要快速熟悉庞大系统的业务逻辑和代码骨架,或者做团队 Onboarding,首选带 Web 可视化的 Understand-Anything;如果您的重点是整理和提炼跨领域的技术文档、截图、学术论文和非结构化知识,Graphify 的社区聚类将给您惊喜;而如果您希望在日常提交和代码评审(PR Review)时最大限度降低 AI 助手的 Token 账单,code-review-graph 则是极致提效 of MCP 后台利器。
Understand-Anything 成功将确定性的 AST 解析器与具备推理能力的 LLM 结合,给极客开发圈带来了代码探索的降维打击。
在 AI 仅作为离线代码生成器时,它只是一件出色的个人效率工具。但当 AI 能与静态解析双轨并进,并与主流智能体(Agent)生态严丝合缝重组时,它已悄然将庞大的代码黑盒转化为直观可见的交互底牌。当代码能以可视化网络跃然于屏幕,开发与重构也将不再是盲盒。
项目地址:• GitHub Repository: https://github.com/Lum1104/Understand-Anything• CodeWiki Details: https://codewiki.google/github.com/lum1104/understand-anything
